







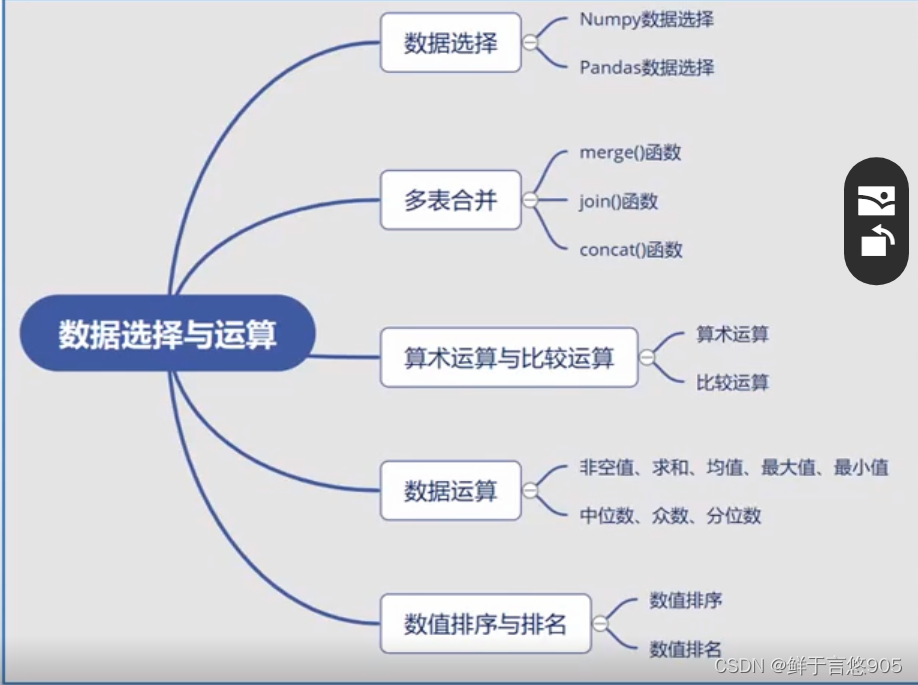
数据的选择和运算
前言
在数据分析中,数据的选择和运算是非常重要的步骤。数据选择和运算是数据分析中的基础工作,正确和高效的选择和运算方法对于数据分析结果的准确性和速度至关重要。
在数据分析的领域中,Python以其灵活易用的特性和丰富的库资源,成为了众多数据科学家的首选工具。在Python的数据分析流程中,数据的选择和运算是两个至关重要的步骤。它们能够帮助我们从海量的数据中提取出有价值的信息,并通过适当的运算处理,得出有指导意义的结论。
数据的选择,是指在原始数据集中筛选出符合特定条件的数据子集。这通常涉及到对数据的筛选、排序和分组等操作。Python的Pandas库为我们提供了强大的数据选择工具。通过DataFrame的结构化数据存储方式,我们可以轻松地按照行或列进行数据的选择。例如,使用.loc和.iloc可以根据行标签和行号来选取数据,而.query方法则允许我们根据条件表达式来筛选数据。
在数据选择的基础上,数据运算则是进一步挖掘数据内在规律的重要手段。Python中的NumPy库提供了高效的多维数组对象及其上的运算功能,使得大规模的数值计算变得简单快捷。通过NumPy,我们可以进行向量化运算,避免了Python原生循环的低效性。此外,Pandas库也提供了丰富的数据处理和运算功能,如数据合并、数据转换、数据重塑等,使得数据运算更加灵活多样。
除了基本的数值运算外,数据分析中还经常涉及到统计运算和机器学习算法的应用。Python的SciPy库提供了大量的统计函数和算法,可以帮助我们进行数据的统计分析。同时,像Scikit-learn这样的机器学习库,则提供了丰富的机器学习算法,可以帮助我们构建预测模型,从数据中提取出更深层次的信息。
综上所述,Python在数据分析中的数据选择和运算方面展现出了强大的能力。通过合理的数据选择和恰当的运算处理,我们可以从数据中获取到宝贵的信息和洞见,为决策提供有力的支持。未来,随着Python的不断发展和更多优质库的出现,相信数据分析领域将会迎来更加广阔的发展前景。
一、数据选择
1.NumPy的数据选择
NumPy数组索引所包含的内容非常丰富,有很多种方式选中数据中的子集或者某个元素。主要有以下四种方式:
| 索引方式 | 使用场景 |
|---|---|
| 基础索引 | 获取单个元素 |
| 切片 | 获取子数组 |
| 布尔索引 | 根据比较操作,获取数组元素 |
| 数组索引 | 传递索引数组,更加快速,灵活的获取子数据集 |
数组的索引主要用来获得数组中的数据。在NumPy中数组的索引可以分为两大类:
- 一是一维数组的索引;
- 二是二维数组的索引。
一维数组的索引和列表的索引几乎是相同的,二维数组的索引则有很大不同。
一维数组元素提取
沿着单个轴,整数做下标用于选择单个元素,切片做下标用于选择元素的范围和序列。正整数用于从数组的开头开始索引元素(索引从0开始),而负整数用于从数组的结尾开始索引元素,其中最后一个元素的索引是-1,第二个到最后一个元素的索引是-2,以此类推。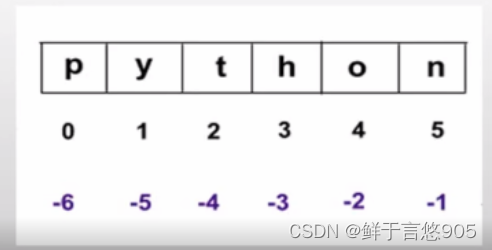
关于NumPy数组的索引和切片操作的总结,如下表:
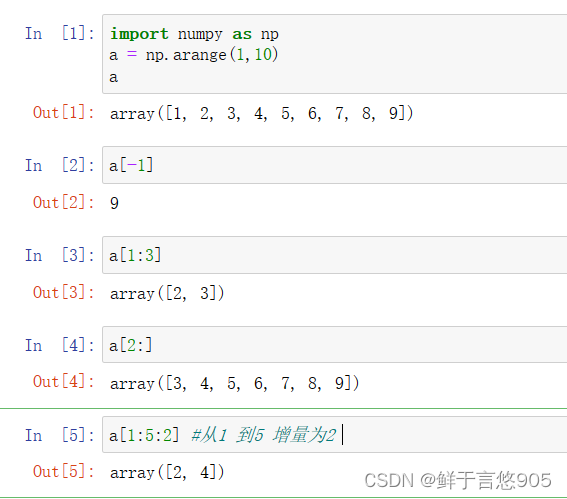
【例】利用Python的Numpy创建一维数组,并通过索引提取单个或多个元素。
关键技术: NumPy数组的索引和切片,一维数组切片的语法为: [start:stop:step]。程序代
码如下所示:
import numpy as np
a = np.arange(1,10)
a
a[-1]
a[1:3]
a[2:]
a[1:5:2] #从1 到5 增量为2
多维数组行列选择、区域选择
二维数组的索引格式是[a:b,m:n],逗号前选择行,逗号后选择列。而在选择行和列的时候可以传入列表,或者使用冒号来进行切片索引。
关键技术:
二维数组索引语法总结如下:
[对行进行切片,对列的切片]
对行的切片:可以有start:stop:step
对列的切片:可以有start:stop:step

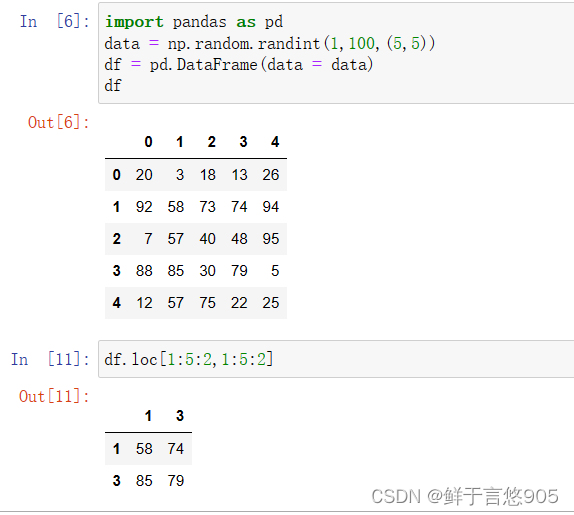
import pandas as pd
data = np.random.randint(1,100,(5,5))
df = pd.DataFrame(data = data)
df
df.loc[1:5:2,1:5:2]
print(data)
data[1:5:2,1:5:2]
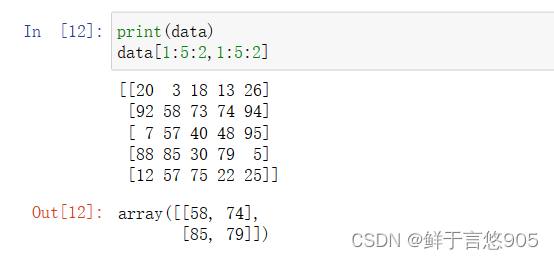
【例】请使用Python对如下的二维数组进行提取,选择第一行第二列的数据元素并输出。
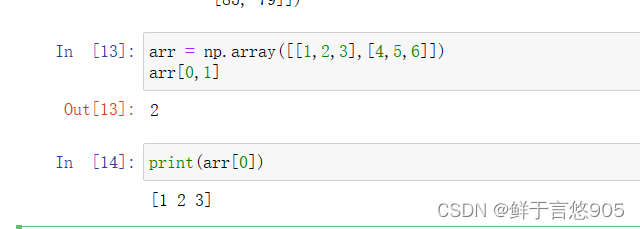
关键技术:多维数组的索引与一维数组的索引相似,但索引语言更为自然,只需要使用[ ]运算符和逗号分隔符即可,具体程序代码如下所示:
arr = np.array([[1,2,3],[4,5,6]])
arr[0,1]

【例3】请使用Python对如下的二维数组进行提取,选择第一行的数据元素并输出。
关键技术:多维数组中对行的选择,使用[ ]运算符只对行号选择即可,具体程序代码如下所示:
花式索引与布尔值索引
①布尔索引
我们可以通过一个布尔数组来索引目标数组,以此找出与布尔数组中值为True的对应的目标数组中的数据。需要注意的是,布尔数组的长度必须与目标数组对应白轴的长度一致。
【例】一维数组的布尔索引。
关键技术:假设我们有一个长度为7的字符串数组,然后对这个字符串数组进行逻辑运算,进而把元素的结果(布尔数组)作为索引的条件传递给目标数组。具体程序代码如下所示:
【例】二维数组的布尔索引。
关键技术:布尔数组中,下标为0,3,4的位置是True,因此将会取出目标数组中第0,3,4行。具体程序代码如下所示:
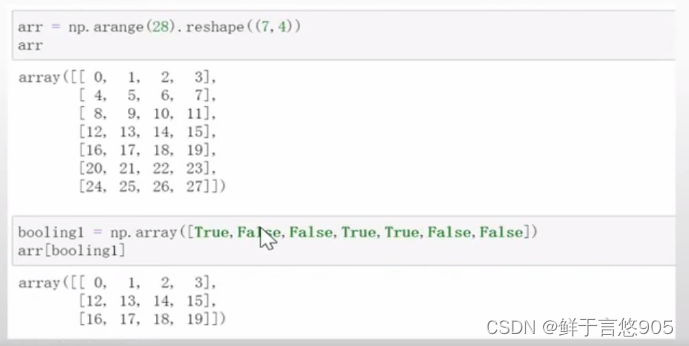
②花式索引
【例】找出数组arr中大于15的元素。
关键技术:与上面的例子不一样,这个例子返回的结果是一个一维数组。具体程序代码如下所示:
【例10】根据上面的例子引申,把上述数组中,小于或等于15的数归零。
关键技术:该例类似于数据清洗,那么可以通过下面的方式。可以采用arr<=15得到的布尔值作为索引,将小于或者等于15的数归零。具体程序代码如下所示: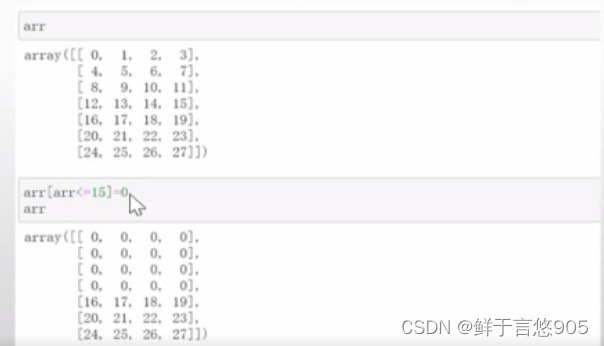
2. Pandas数据选择
Series数据获取

s = pd.Series(data = [1,2,3,4,5,6],index = ['a','c','b','a','b','b'])
s['a']
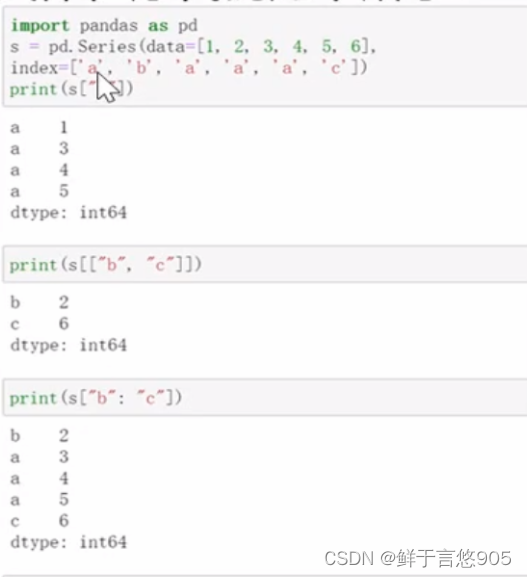
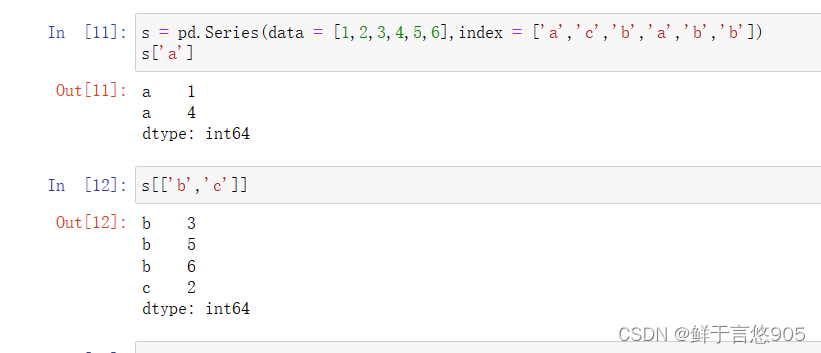
DataFrame数据获取
①列索引取值
使用单个值或序列,可以从DataFrame中索引出一个或多个列。
DataFrame()数据结构,这里用df代表pd.DataFrame(数据),如下表: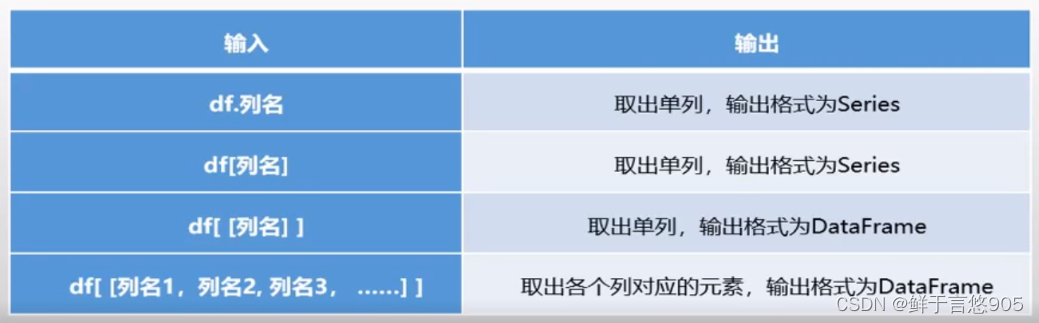

df = pd.DataFrame(data = [[22,'北京','律师'],[26,'四川成都','工程师'],[24,'江苏南京','研究员'],[11,'山东青岛','医生']],
index = pd.Index(['张某','李某','赵某','段某'],name = 'Name'),columns = ['age','籍贯','职业'])
df
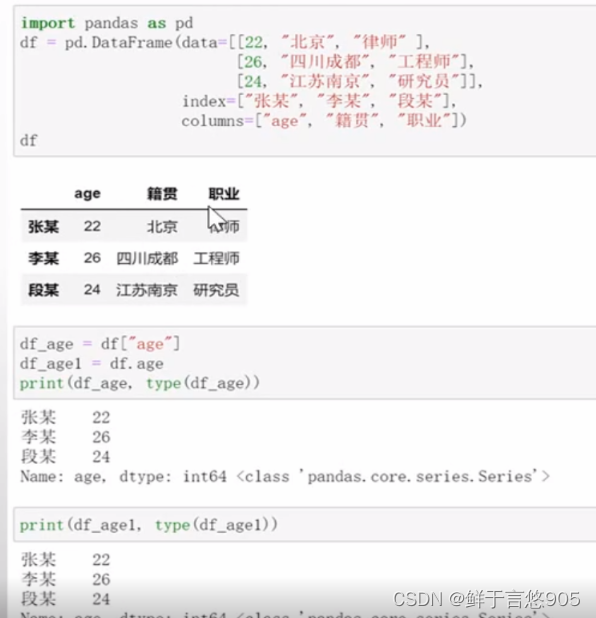
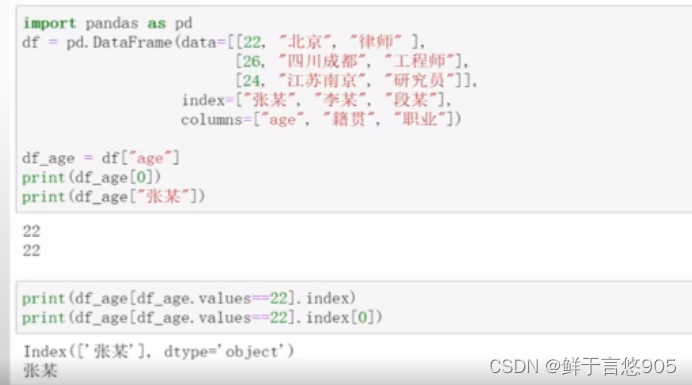
【例】当我们转换成Series结构后,通过下标和值均可以相互获取。
关键技术:可以通过对应的下标或行索引来获取值,也可以通过值获取对应的索引对象以及索引值。
具体程序代码如下所示:
②取行方式
【例】通过切片方式选取多行。
关键技术:注意这里使用的是一个中括号,这里的2代表步长: [“张某” : “段某” :2] =[下界:上界:步长]。
具体程序代码如下所示: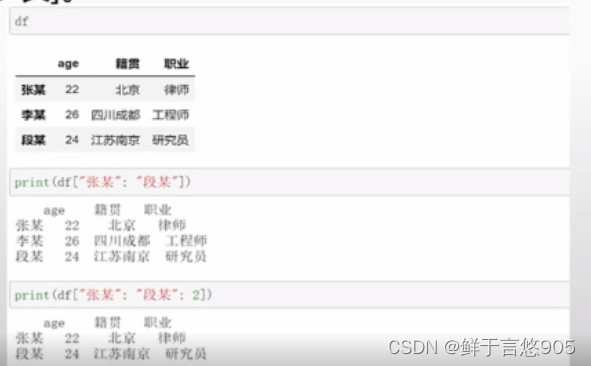
loc() 方法
(1)直接使用法

横向(行索引index)是必备的。
【例17】使用loc()方法选取行。
df = pd.DataFrame(data = [[22,'北京','律师'],[26,'四川成都','工程师'],[24,'江苏南京','研究员'],[11,'山东青岛','医生']],
index = pd.Index(['张某','李某','赵某','段某'],name = 'Name'),columns = ['age','籍贯','职业'])
df
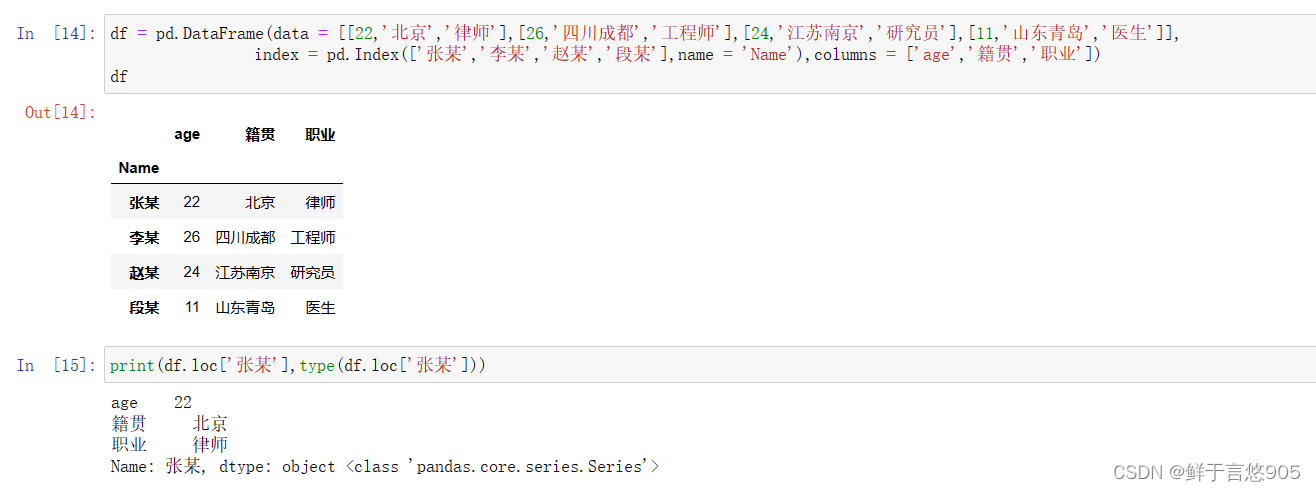
下面代码执行的结果都是相同的,方法可以通用
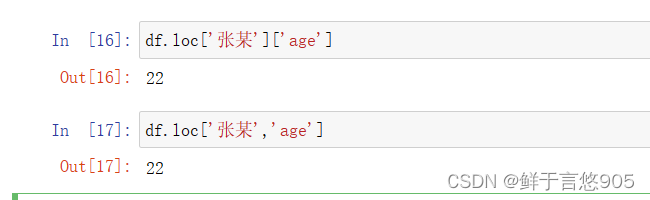
选取多行的语法为:变量名.loc[[行index1 行index2,……]]

iloc()方法
iloc的使用与loc完全类似,只不过是针对“位置(=第几个)"进行筛选。函数语法为: .iloc[整数、整数列表、整数切片、布尔列表以及函数]。[ ]里面的使用方法同.loc[ ]方法。
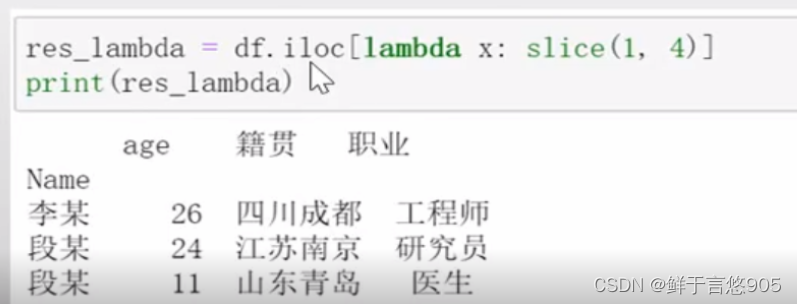
【例】采用上面例题的dataFrame,用iloc()函数结合lambda函数获取行数据。
关键技术:这里介绍一下.iloc[函数]中的函数使用方法:
①函数 =自定义函数(函数的返回值需要是合法对象(= 整数、整数列表、整数切片、布
列表))
②匿名函数lambda :使用方法
语法: lambda自变量: slice(start =下界, stop =上界, step =步长)。具体程序代码如下所
示:
二、多表合并
有的时候,我们需要将一些数据片段进行组合拼接,形成更加丰富的数据集。Python的Pandas库为数据合并操作提供了多种合并方法,如merge()、join()和concat()等方法。
1.使用merge()方法合并数据集
Pandas提供了一个函数merge,作为DataFrame对象之间所有标准数据库连接操作的入口点。merge()是Python最常用的函数之一,类似于Excel中的vlookup函数,它的作用是可以根据一个或多个键将不同的数据集链接起来。我们来看一下函数的语法:
merge的参数如下:
pd.merge( left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None,)
参数释义:
left:关联的其中一个表。
right:关联的另外一个表。
how:值有{‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, 默认‘inner’。类似于sql的 left join、right join、outer join、inner join、cross join。
on:指定主键。用于关联2个表的字段,必须同时存在于2个表中。类似于sql中的on用法。可以不指定,默认以2表中共同字段进行关联。
left_on和right_on:两个表里没有完全一致的列名,但是有信息一致的列,需要指定以哪个表中的字段作为主键。
left_index和right_index:除了指定字段作为主键以外,还可以考虑用索引作为拼接的主键,leftindex和rightindex默认为False,就是不以索引作为主键。若合并的表含有相同字段/索引,可以同时设定left_index = True和right_index = True。
sort:是否按连结主键进行排序,默认是False,指不排序。True表示按连结主键(on 对应的列名)进行升序排列。
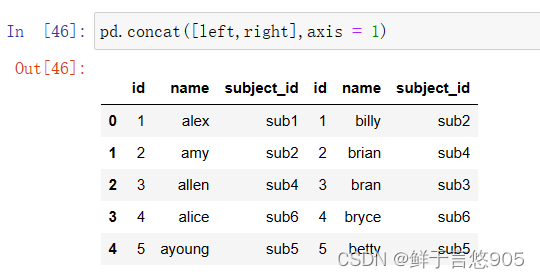
【例】创建两个不同的数据帧,并使用merge()对其执行合并操作。
关键技术:merge()函数
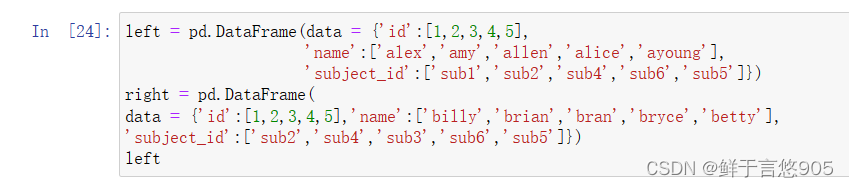
首先创建两个DataFrame对象。
left = pd.DataFrame(data = {'id':[1,2,3,4,5],
'name':['alex','amy','allen','alice','ayoung'],
'subject_id':['sub1','sub2','sub4','sub6','sub5']})
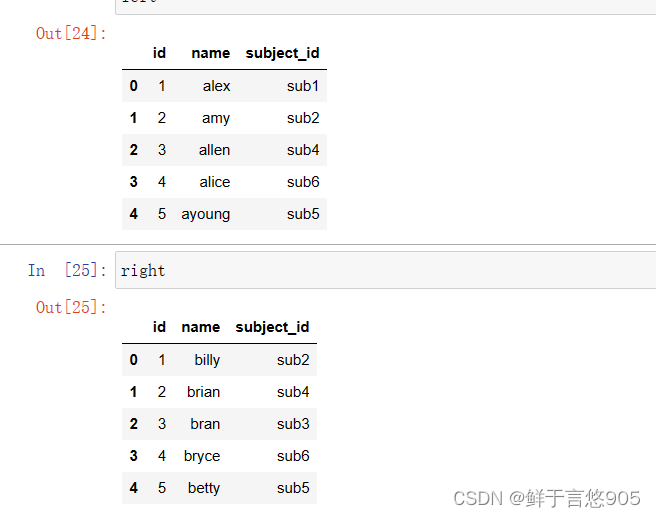
right = pd.DataFrame(
data = {'id':[1,2,3,4,5],'name':['billy','brian','bran','bryce','betty'],
'subject_id':['sub2','sub4','sub3','sub6','sub5']})
left
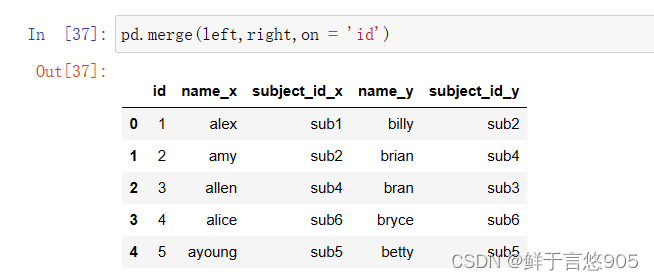
(1)使用一个键合并两个数据帧
关键技术:使用’ id’键合并两个数据帧,并使用merge()对其执行合并操作。代码和输出结果如下所示:
(2)使用多个键合并两个数据帧:
关键技术:使用’ id’键及’subject_id’键合并两个数据帧,并使用merge()对其执行合并操作。代码和输出结果如下所示:
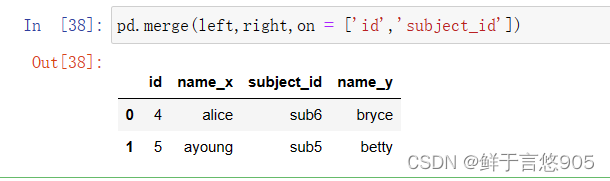
(3)使用“how”参数合并
关键技术:how参数指定如何确定结果表中包含哪些键。如果左表或右表中都没有出现组合键,则联接表中的值将为NA。

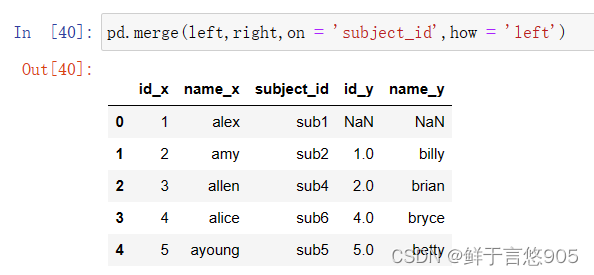
【例21】采用上面例题的dataframe,使用Left Join左连接方式合并数据帧。
关键技术:请注意on=‘subject id’, how=‘left’。代码如下:
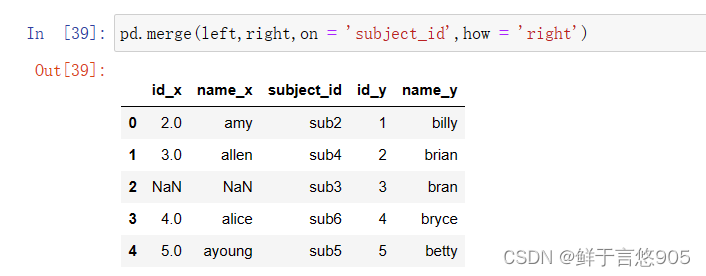
【例22】使用Right Join右连接方式合并数据帧。
关键技术:请注意on=‘subject_id’, how=‘right’。代码如下:
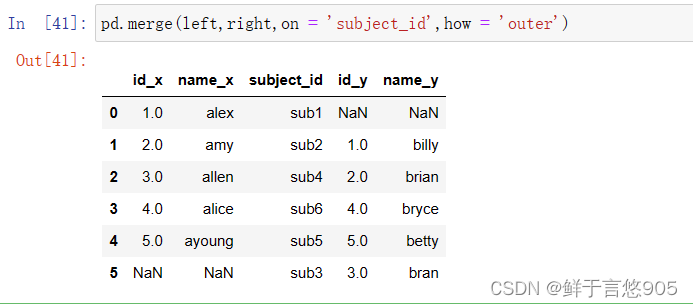
【例23】使用outer Join外连接方式合并数据帧。
关键技术:请注意on=‘subject_id’, how=’ outer’。代码如下:
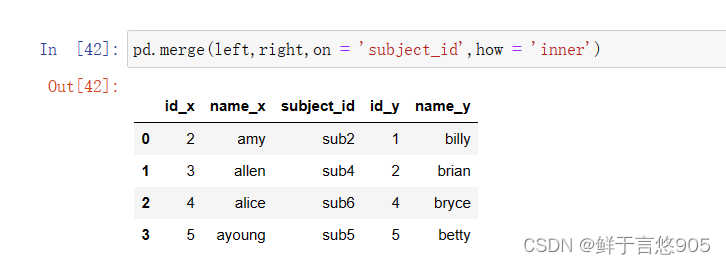
【例24】使用inner Join合并数据帧。
关键技术:请注意on=‘subject_id’, how=’ inner’ 。代码如下:
2.使用join()方法合并数据集
join()是最常用的函数之一, join()方法用于将序列中的元素以指定的字符连接生成一个新的字符串。join()数据帧的语法和参数如下:
DataFrame.join(other,on = None , how = 'left' , lsuffix = '' , rsuffix = ' ' ,sort = False )
join()方法参数详解
| 参数 | 描述 |
|---|---|
| Self | 表示的是join必须发生在同一数据帧上 |
| Other | 提到需要连接的另一个数据帧 |
| On | 指定必须在其上进行连接的键 |
| How | 提到了连接的类型 |
| left_suffix | 要从左框架的重叠列中使用的后缀 |
| right_suffix | 要从右框架的重叠列中使用的后缀 |
| sort | 对输出进行排序 |
【例】对于存储在本地的销售数据集"sales.csv" ,使用Python的join()方法,将两个数据表切片数据进行合并。
关键技术: join()函数。具体程序代码如下所示:

3使用concat()方法合并数据集
concat()是最数据处理中最为强大的函数之一,可用于横向和纵向合并拼接数据。标准格式及参数解释如下:
pd.concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False)
objs-这是序列、数据帧或面板对象的序列或映射.
axis-{0, 1, },默认值为0。这是要连接的轴。
join-{'inner', 'outer'},默认为’outer’。如何处理其他轴上的索引。外部表示联合,内部表示交叉。
ignore_index-布尔值,默认为False。如果为True,则不要使用连接轴上的索引值。生成的轴将标记为0…, n-1。
join_axes-这是索引对象的列表。用于其他(n-1)轴的特定索引,而不是执行内部/外部设置逻辑。
【例】使用Concat连接对象。
关键技术: concat函数执行沿轴执行连接操作的所有工作,可以让我们创建不同的对象并进行连接。axis表示选择哪一个方向的堆叠,0为纵向(默认),1为横向

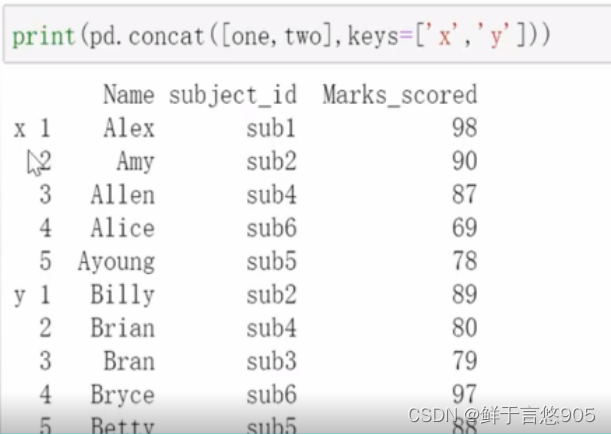
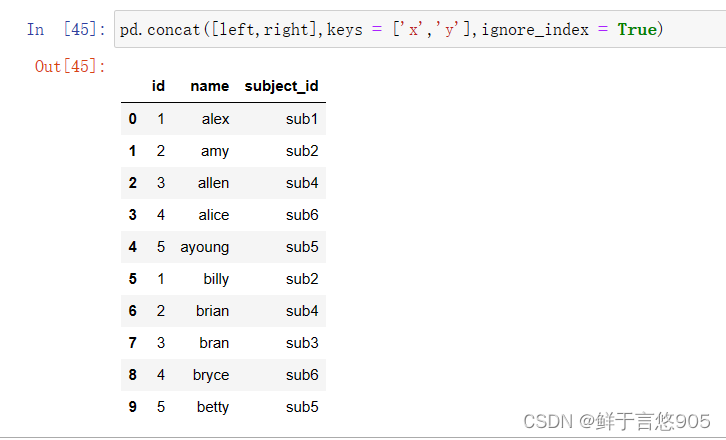
【例】实现将特定的键与被切碎的数据帧的每一部分相关联。
关键技术:假设你想在连接轴上创建一个层次化索引来区分片段,使用keys参数民可达到这个目的。代码如下:
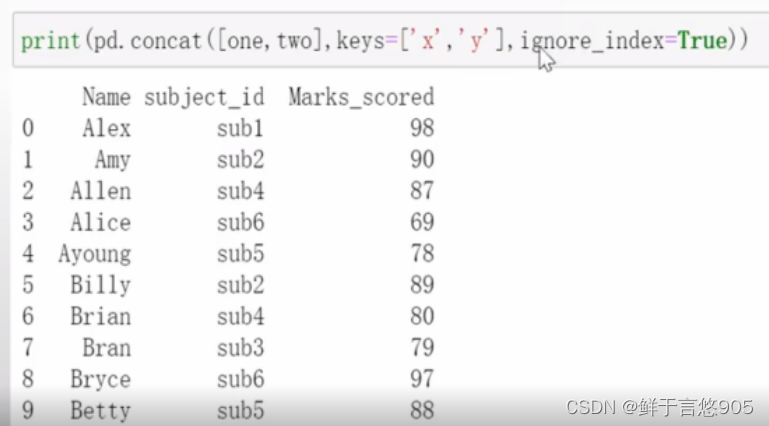
【例】输出结果不展示行索引。
关键技术:如果DataFrame行索引和当前分析工作无关且不需要展示,需要将ignore_index设置为True。请注意,索引会完全更改,键也会被覆盖。
【例】按列合并对象。
关键技术:如果需要沿axis=1合并两个对象,则会追加新列到原对象右侧。
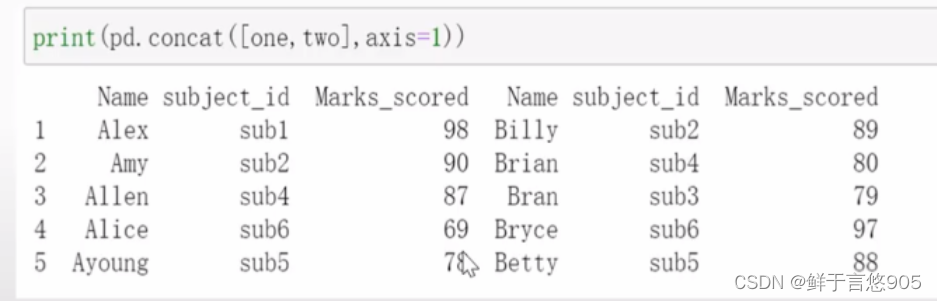
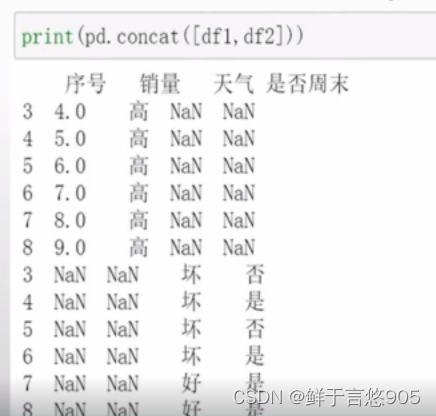
【例】对于存储在本地的销售数据集"sales.csv" ,使用Python将两个数据表切片数据进行合并
关键技术:注意未选择数据的属性用NaN填充。程序代码如下所示:
三、算术运算与比较运算
通过一些实例操作来介绍常用的运算函数,包括一个数组内的求和运算、求积运算,以及多个
数组间的四则运算。
【例】使用Python对给定的数组元素进行求和运算。
关键技术:可以使用Python的sum()函数,程序代码如下所示:
【例】使用Python对给定的数组元素的求乘积运算。
关键技术:可以使用Python的prod()函数, prod(a, axis=None, dtype=None, out=None, keepdims=<class 'numpy._globals._NoValue'>)返回给定轴上的数组元素的乘积。程序代码
如下所示:

【例】请使用Python对多个数组进行求和运算操作。
关键技术:采用运算符号’+'可以对数组进行求和运算操作,但需要各个数组的维度相同,
程序如下所示:
【例】请使用Python对数值和数组进行求积运算操作。
关键技术:可以使用乘法运算符*,程序如下所示:
【例】请使用Python对多个数组间进行求积运算操作。
关键技术:可以使用乘法运算符*,程序如下所示:
【例】请使用Python对给定数组的元素进行以e为底的对数函数(log)的操作。
关键技术: np.log()函数实现的是In运算,程序代码如下所示:

【例】请使用Python对给定数组的元素进行以10为底的对数函数(log10)的操作。
关键技术:np.log100函数是实现以10为底的对数运算,程序代码如下所示:
【例】请使用Python对给定数组的元素进行指数函数(exp)的操作。
关键技术: np.e表示以e为底,1为指数的数, np.e**2表示e为底数, 2为指数的数。程序
代码如下所示:

其中np.pi代表圆周率π,输出结果如下:

【例】请使用Python对给定数组的元素进行正弦函数的操作。
关键技术:可以使用sin()函数,程序代码如下所示: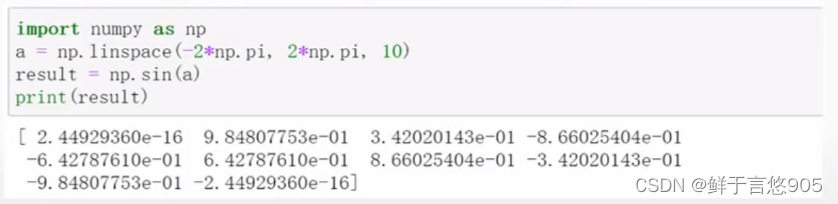
【例】请使用Python对给定数组的元素进行正切函数的操作。
关键技术:可以利用Python的正切函数tan()进行计算,程序代码如下所示:
【例43】利用Python的比较运算符判断如下输出结果。
- 98是否大于100
2)25*4是否于等于76 - 56.8是否等于56.8
- 35是否等于35.0
- False是否小于True
关键技术:可以利用Python的比较运算符<、>、==进行判断,程序代码如下所示:

四、数据运算
pandas中具有大量的数据计算函数,比如求计数、求和、求平均值、求最大值、最小值、中位数、众数、方差、标准差等。
非空值计数
【例】对于存储在该Python文件同目录下的某电商平台销售数据product_sales.csv,形式如下所示,请利用Python对数据读取,并计算数据集每列非空值个数情况。
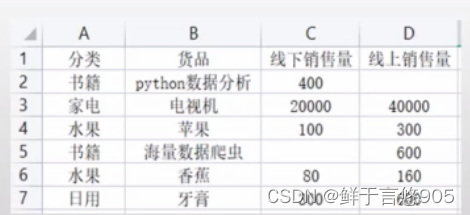
关键技术:可以使用count()方法进行计算非空个数。程序代码如下所示:
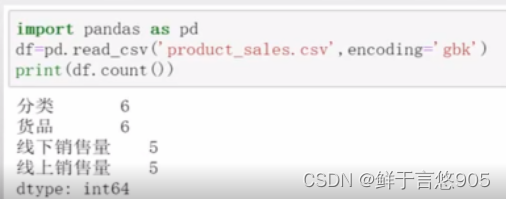
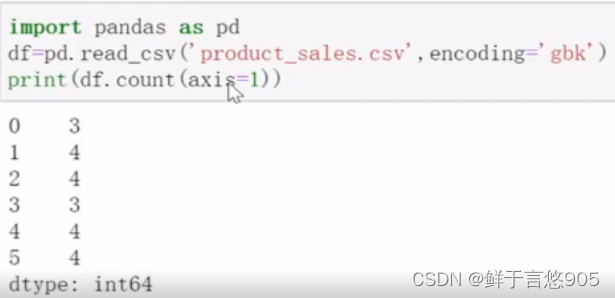
【例】同样对于存储在该Python文件同目录下的某电商平台销售数据product_sales.csv,请利用Python对数据读取,并计算数据集每行非空值个数情况。
关键技术:可以利用count()方法进行计算非空个数,并利用参数axis来控制行列的计算,程序代码如下所示:
【例】对于上述数据集product_sales.csv,若需要特定的列“线上销售量"进行非空值计数,此时应该如何处理?
关键技术:可以利用标签索引和count()方法来进行计数,程序代码如下所示:

【例】对于上述数据集product_sales.csv,若需要特定的行进行非空值计数,应该如何处理?
关键技术:可以利用行号索引和count()方法来进行计数,程序代码如下所示:
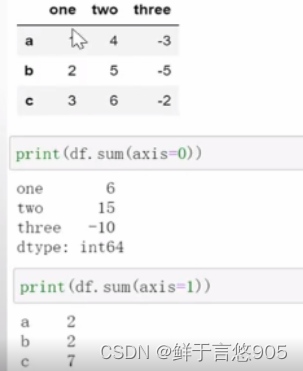
【例】对于给定的DataFrame数据,按索引值进行求和并输出结果。
关键技术:对于例子给定的DataFrame数据,按行进行求和并输出结果。
可以采用求和函数sum(),设置参数axis为0,则表示按纵轴元素求和,设置参数axis为1,则表示按横轴元素求和,程序代码如下所示:

均值运算
在Python中通过调用DataFrame对象的mean()函数实现行/列数据均值计算,语法如下:
mean(axis=None, skipna=None, level=None, numeric_only=None, **kwargs)
相关参数定义与sum()函数相同。
【例】对于例48给定的DataFrame数据,统计数据的算数平均值并输出结果。
关键技术: mean()函数能够对对数据的元素求算术平均值并返回,程序代码如下所示:
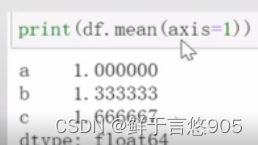
中位数运算
中位数又叫作中值,按顺序排列的一组数据中位于中间位置的数,其不受异常值的影响。语法如下:
median(axis=None, skipna=None, level=None, numeric_only=None, **kwargs)
相关参数定义与sum()函数相同。
【例】对于如下二维数组,形式如下,利用Python计算其中位数。
关键技术:利用median()函数可以计算中位数,若为偶数个数值,则中位数为中间两个数的均值。
程序代码如下所示:
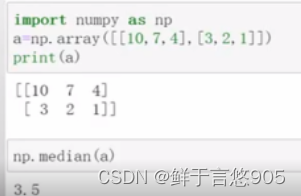
众数运算
众数就是一组数据中出现最多的数,代表了数据的一般水平。在Python中通过调用DataFrame对象的mode()函数实现行/列数据均值计算,语法如下:语法如下:
mode(axis=0, numeric_only=False, dropna=True)
【例54】计算学生各科成绩的众数。
关键技术: mode()函数实现行/列数据均值计算。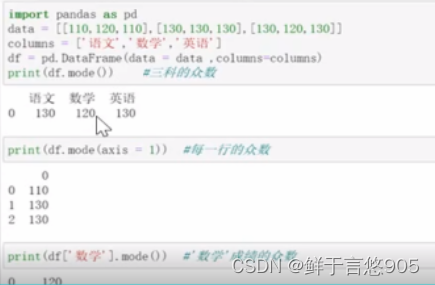
分位数运算
分位数是以概率依据将数据分割为几个等分,常用的有中位数(即二分位数)、四分位数、百分位数等。分位数是数据分析中常用的一个统计量,经过抽样得到一个样本值。
例如,经常会听老师说: "这次考试竟然有20%的同学不及格! " ,那么这句话就体现了分位数的应用。在Python中通过调用DataFrame对象的quantile()函数实现行/列数据均值计算,语法如下:
quantile(q=0.5, axis=0, numeric_only=True, interpolation=‘linear’ )
参数说明:
q:浮点型或数组,默认为0.5 (50%分位数),其值为0~1
axis: axis = 1表示行,axis = 0表示列,默认为None(无)
numeric_only:仅数字,布尔型,默认值为True
interpolation:内插值,可选参数,用于指定要使用的插值方法,当期望的分位数为数据点i~j时。
线性: i+(j-i)*分数,其中分数是指数被i和j包围的小数部分。
较低:i
较高:j
最近:i或j二者以最近者为准
中点:(i+j)/2
返回值.返回Series对象或DataFrame对象。
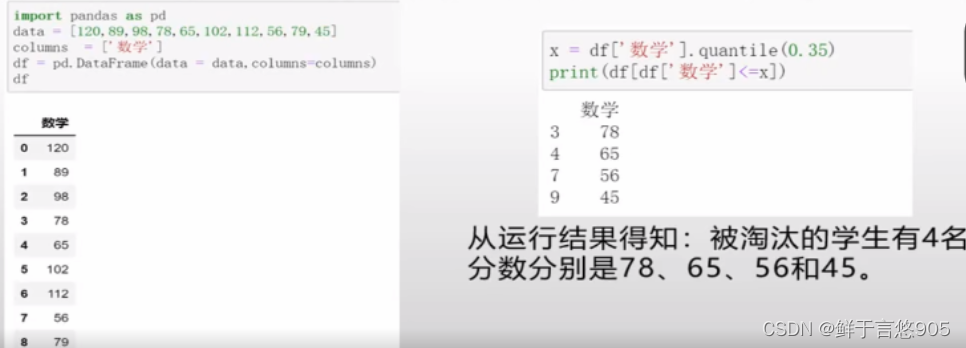
【例55】通过分位数确定被淘汰的35%的学生。
关键技术:以学生成绩为例,数学成绩分别为120、89、98、78、65、102、112、56、
79、45的10名同学,现根据分数淘汰35%的学生,该如何处理?首先使用quantile()函
数计算35%的分位数,然后将学生成绩与分位数比较,筛选小于等于分位数的学生,程
序代码如下:
五、数值排序与排名
Pandas也为Dataframe实例提供了排序功能。Dataframe的排序可以按照列或行的名字进行排序,也可以按照数值进行排序。
DataFrame数据排序主要使用sort_values()方法,该方法类似于sql中的order by。 sort_values()方法可以根据指定行/列进行排序。
语法如下:
sort_values(by, axis=0, ascending=True, inplace=False, kind=‘quicksort’, na_position=‘last’,l
ignore_indexFalse, key: ‘ValueKeyFunc’ = None)
参数说明:
by:要排序的名称列表
axis:轴,0代表行,1代表列,默认是0
ascending:升序或者降序,布尔值,指定多个排序就可以使用布尔值列表,默认是True
inplace:布尔值,默认是False,如果值为True,则就地排序
kind:指定排序算法,值为quicksort(快速排序)、mergesort(混合排序)或heapsort(堆排),默认值为quicksort
na_position:空值(NaN)的位置,值为first空值在数据开头,值为last空值在数据最后,默认为last
ignore_index:布尔值,是否忽略索引,值为True标记索引(从0开始按顺序的整数值),值为False则忽略索引。
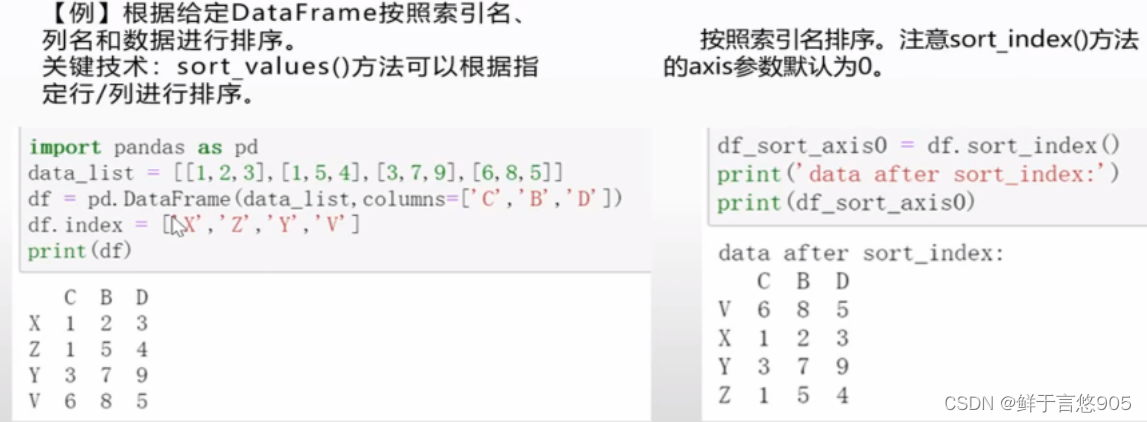
按照column列名排序

axis表示按照行或者列,asceding表=True升序,False为降序,by表示排序的列名。

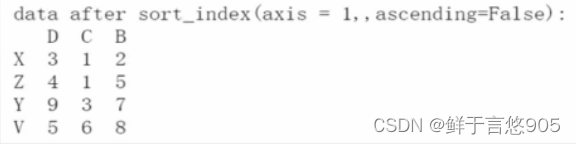
按照数据进行排序,首先按照D列进行升序排列。
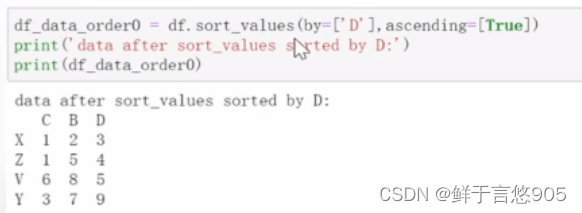
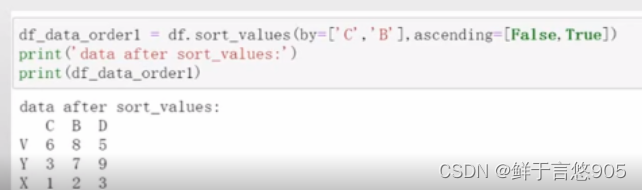
按照数据进行排序,首先按照C列进行降序排序,在C列相同的情况下,按照B列进行升序排序。
总结
数据选择和运算是数据处理和分析过程中不可或缺的基础工作,正确和高效的选择和运算方法对于数据分析结果的准确性和速度至关重要。















 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











