







这里写目录标题
- 总览
- 4.1 xxx
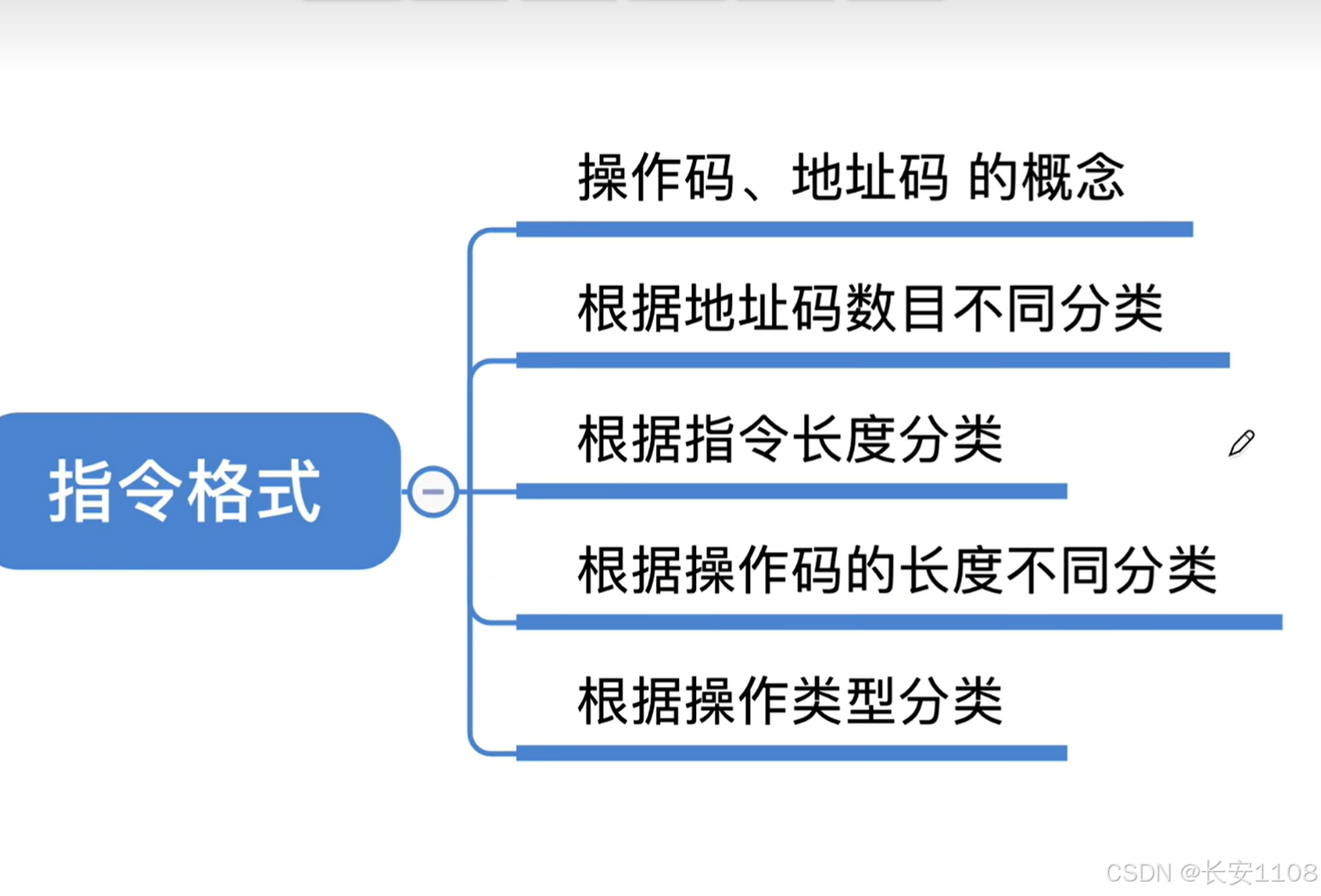
- 4.1.1 指令格式
- 总览
- 指令定义
- 操作码和地址码的概念
- 根据地址码的数目分类
- 零地址码指令
- 一地址指令
- 二地址指令与三地址指令与四地址指令
- 根据指令长度分类
- 指令字长
- 根据操作码长度分类
- 按照操作码功能分类
- 总结
- 4.1.2 扩展操作码 指令格式
- 总览
- 举例
- 设计准则
- “不同的地址数,且是不同范围个数的操作码”的机器代码设计
- 对比“不定长操作码”和“定长操作码”
- 4.2 xxx
- 4.2.1 指令寻址(寻找“指令代码”所在主存的位置)
- 总览
- 顺序寻址
- 跳跃寻址
- 总结
- 4.2.2 数据寻址(寻找“地址码”所想要表示的在主存中的真实地址)
- 总览
- 十种数据寻址方式总览
- 直接寻址
- 间接寻址
- 寄存器寻址
- 寄存器间接寻址
- 隐含寻址
- 立即数寻址
- 阶段小结
- 4.2.3 数据寻址--偏移寻址
- 总览
- 基址寻址
- 变址寻址
- 基址变址复合
- 相对寻址
- 总结
- 4.2.4 数据寻址--堆栈寻址
- 总览
- 简介
- 注意
- 总结
- 4.3
- 4.3.1 高级语言与机器代码之间的对应
- 总览
- 4.3.2 常用的x86汇编指令
- 4.3.3 AT&T格式和Inter格式
- 4.3.4 几个语句的机器级表示
- 选择语句
- 循环语句
- 4.3.5 函数调用的机器级表示
- Call 和 ret指令
- 如何访问栈帧
- 如何切换栈帧
- 如何传递参数和返回值
- 一级目录
- 二级目录
- 二级目录
- 二级目录
- 一级目录
- 二级目录
- 二级目录
- 二级目录
总览
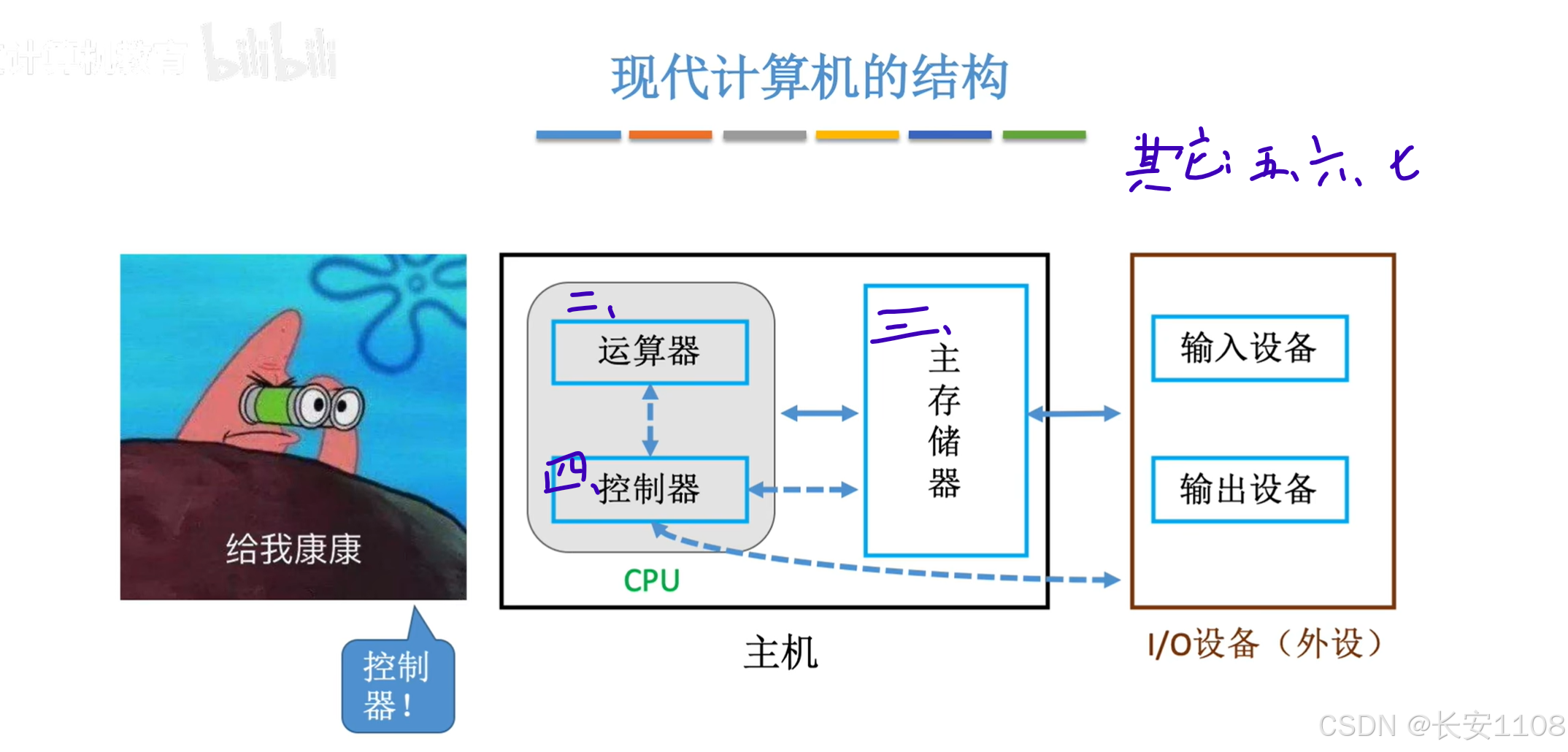
运算器部分的知识,是第二章的内容
存储器部分的知识,是第三章的内容
接下来,第四章,就是控制器部分的内容了(主要看那些能够被控制器所识别并执行的指令)
4.1 xxx
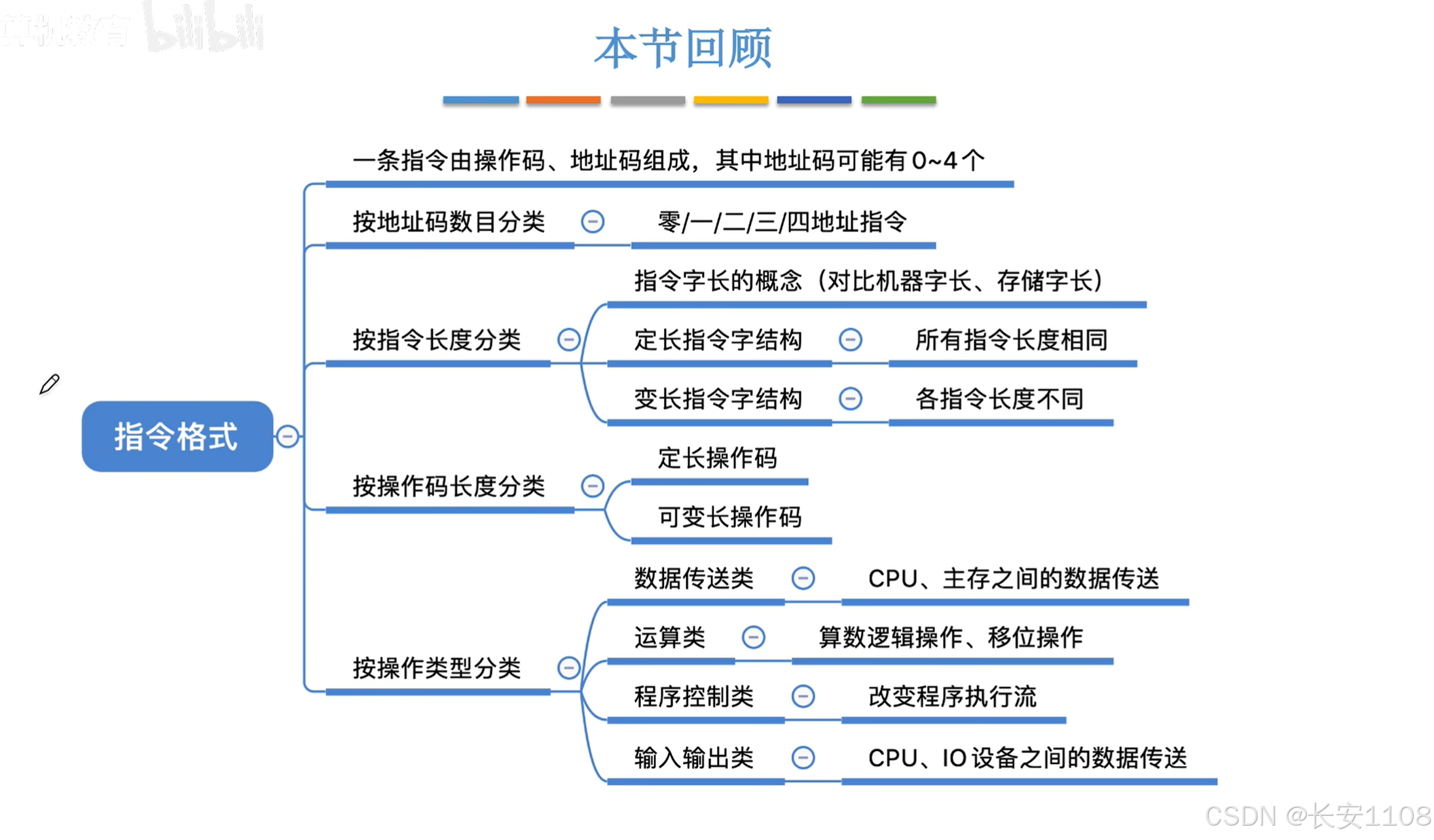
4.1.1 指令格式
总览
指令定义
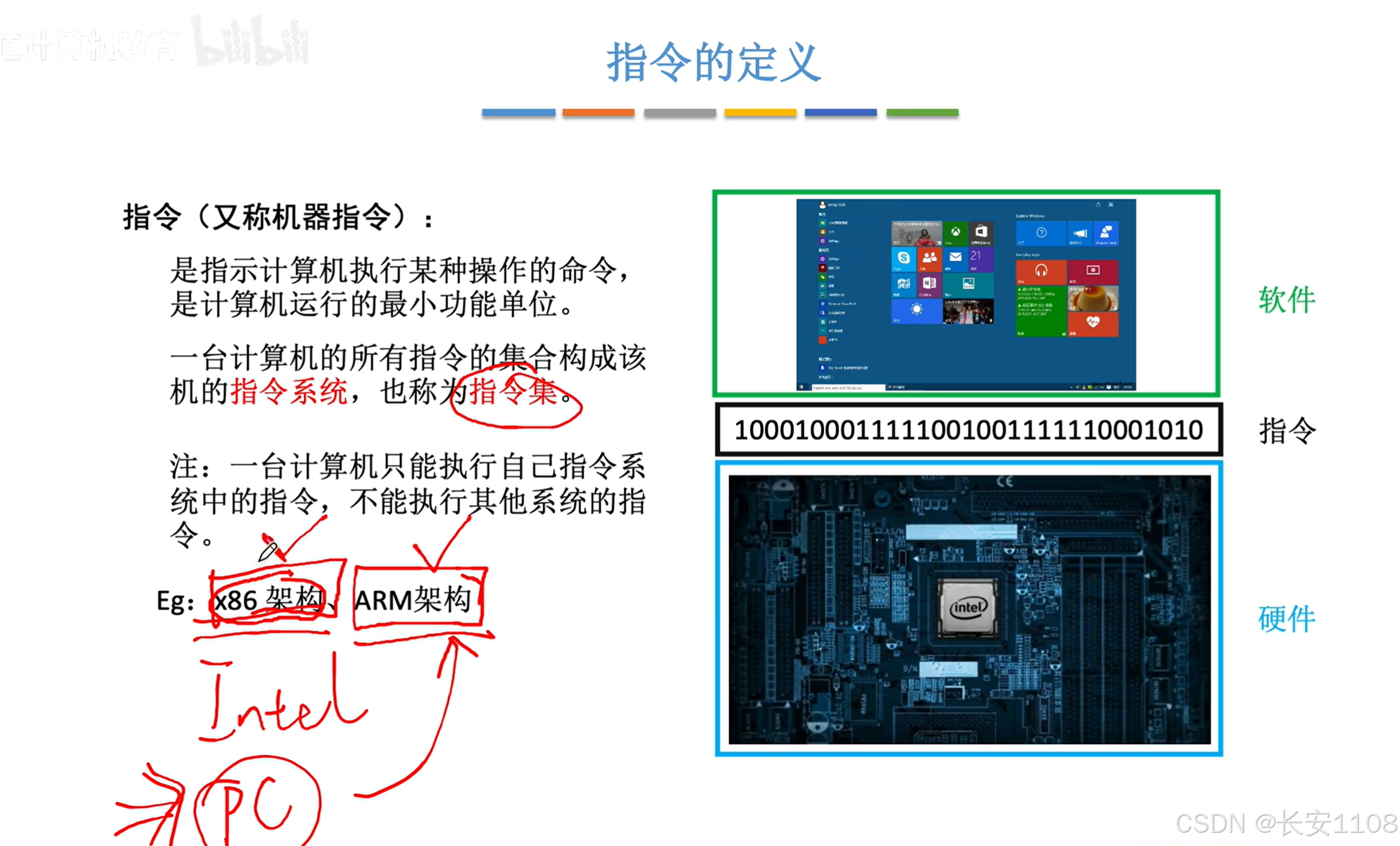
注意,不同的架构设计的芯片,支持的指令集不同,所以,在x86架构上的软件,在ARM架构下是无法直接运行的
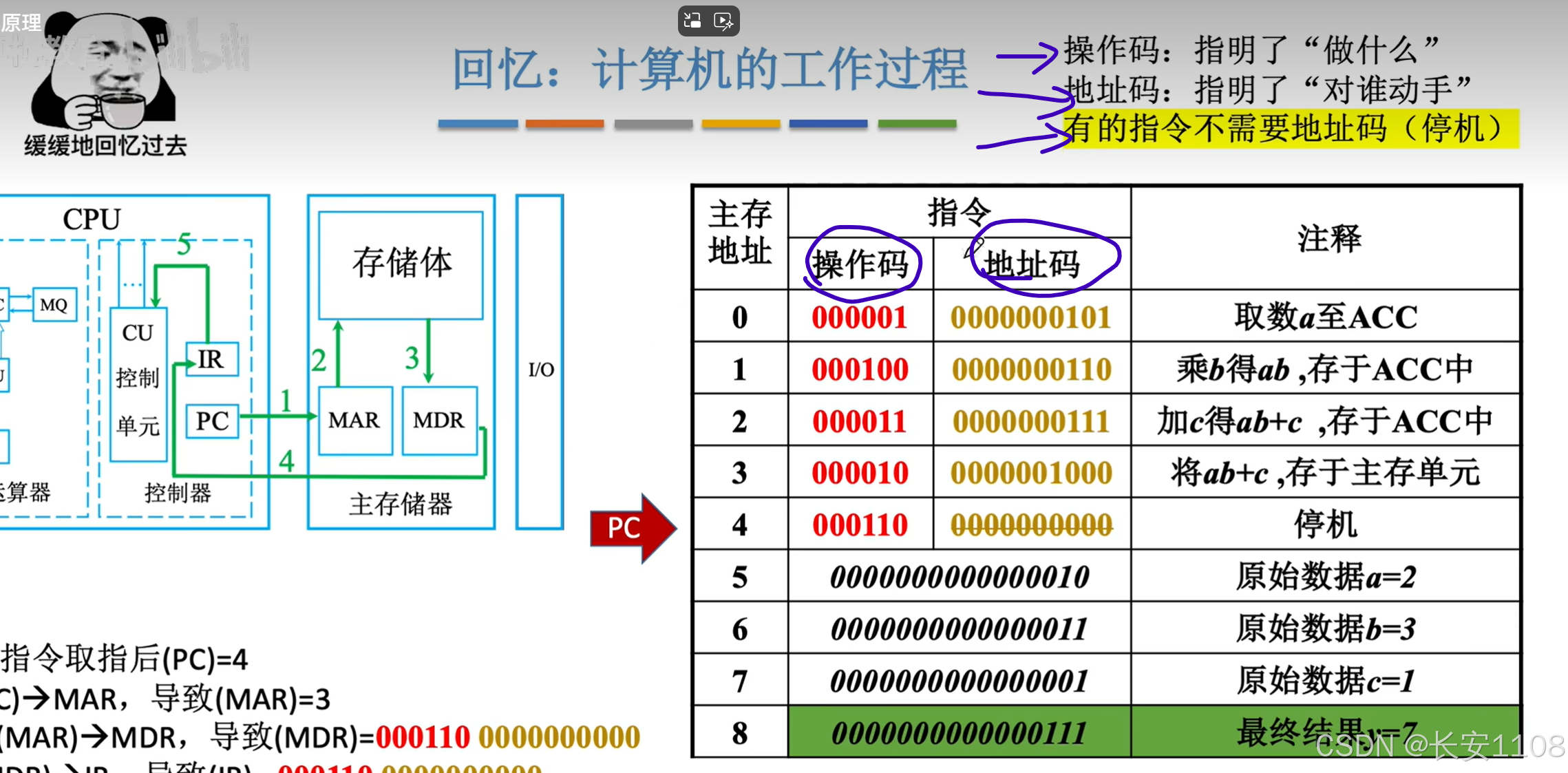
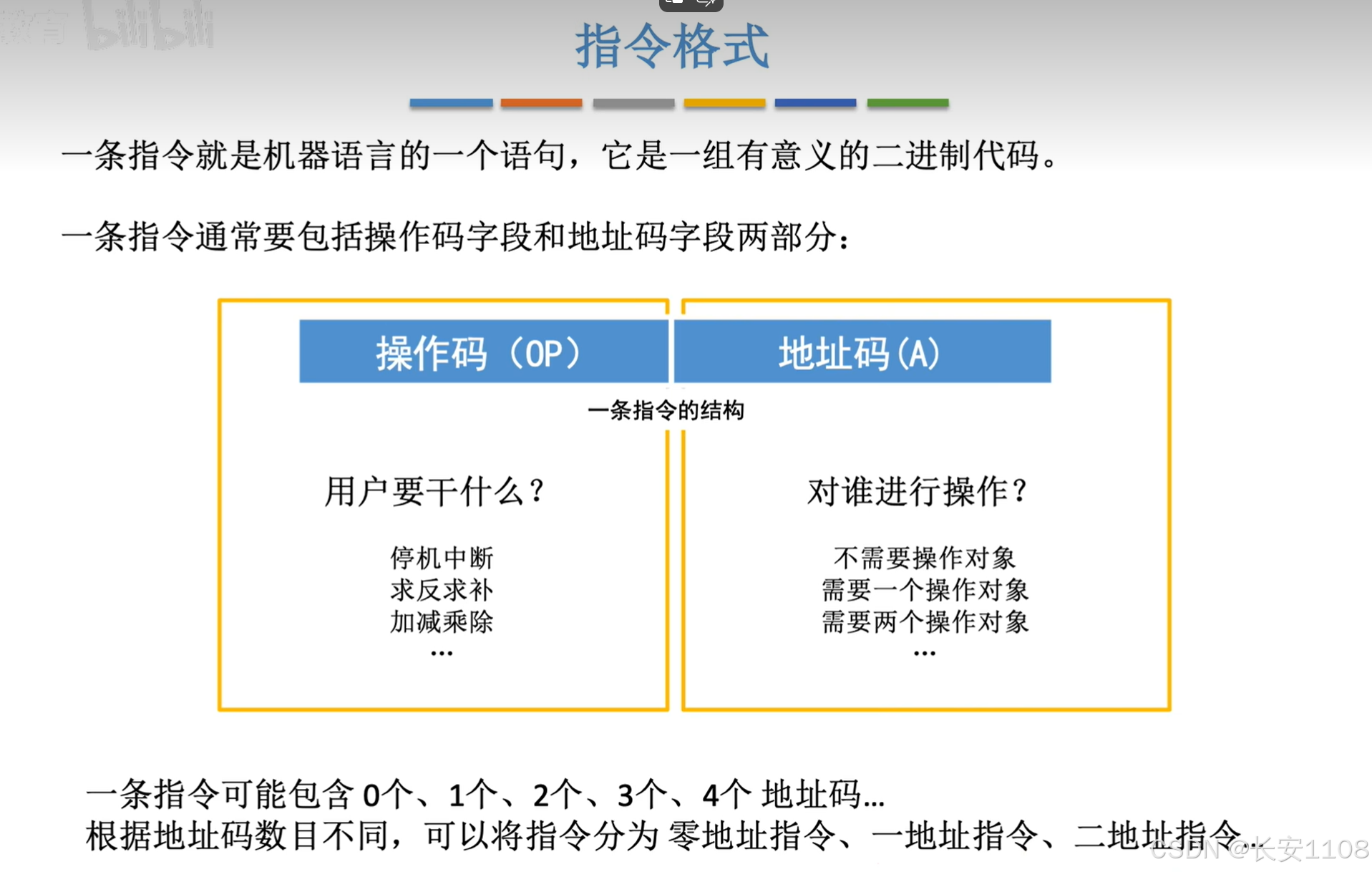
操作码和地址码的概念
根据地址码的数目分类
零地址码指令
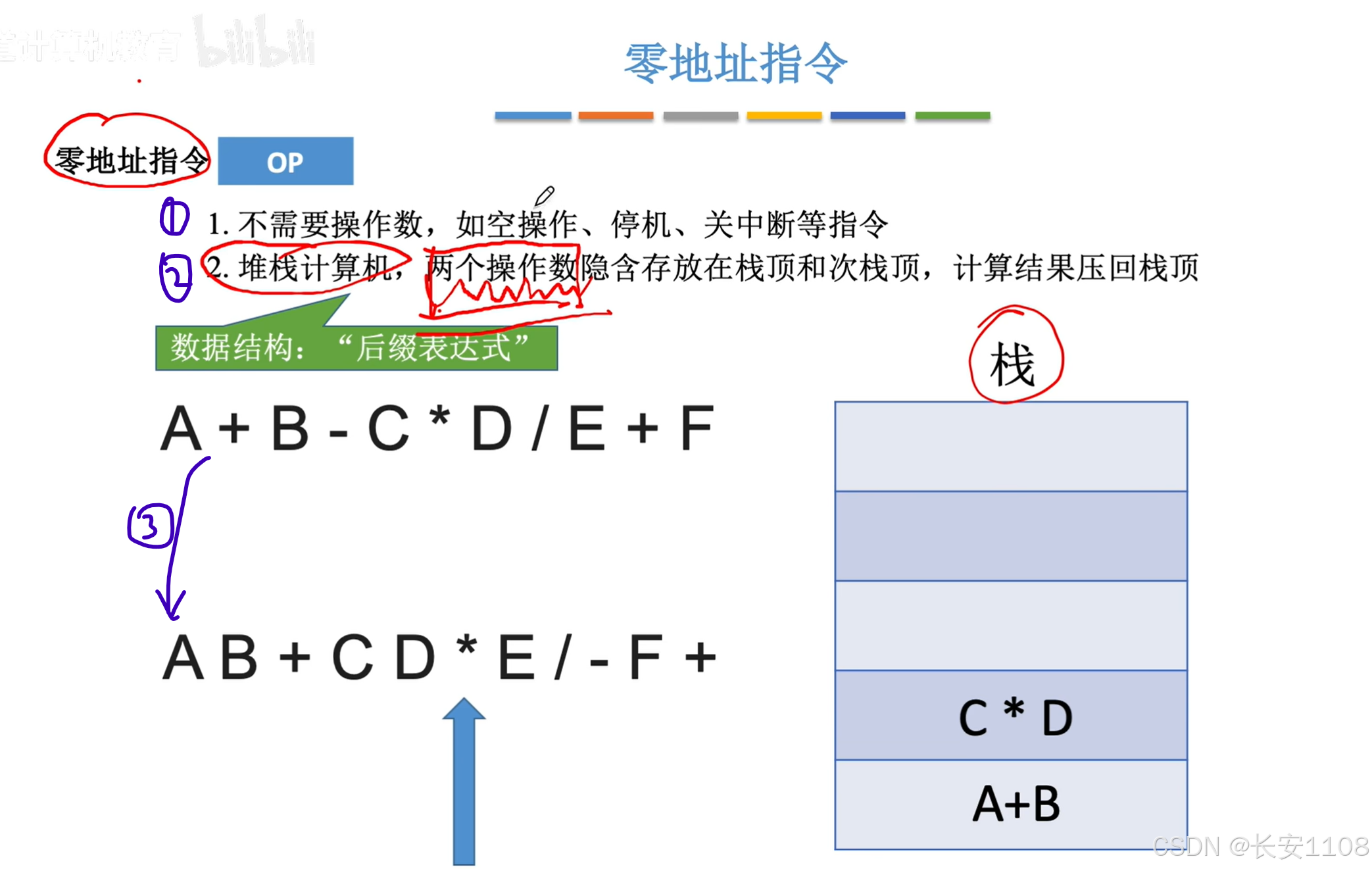
3、是将一个正常的人能看懂的表达式,转为等效的,方便堆栈操作的表达式,符合第二条说的,两个操作数隐含在栈顶和次栈顶,之后使用操作码操作
一地址指令
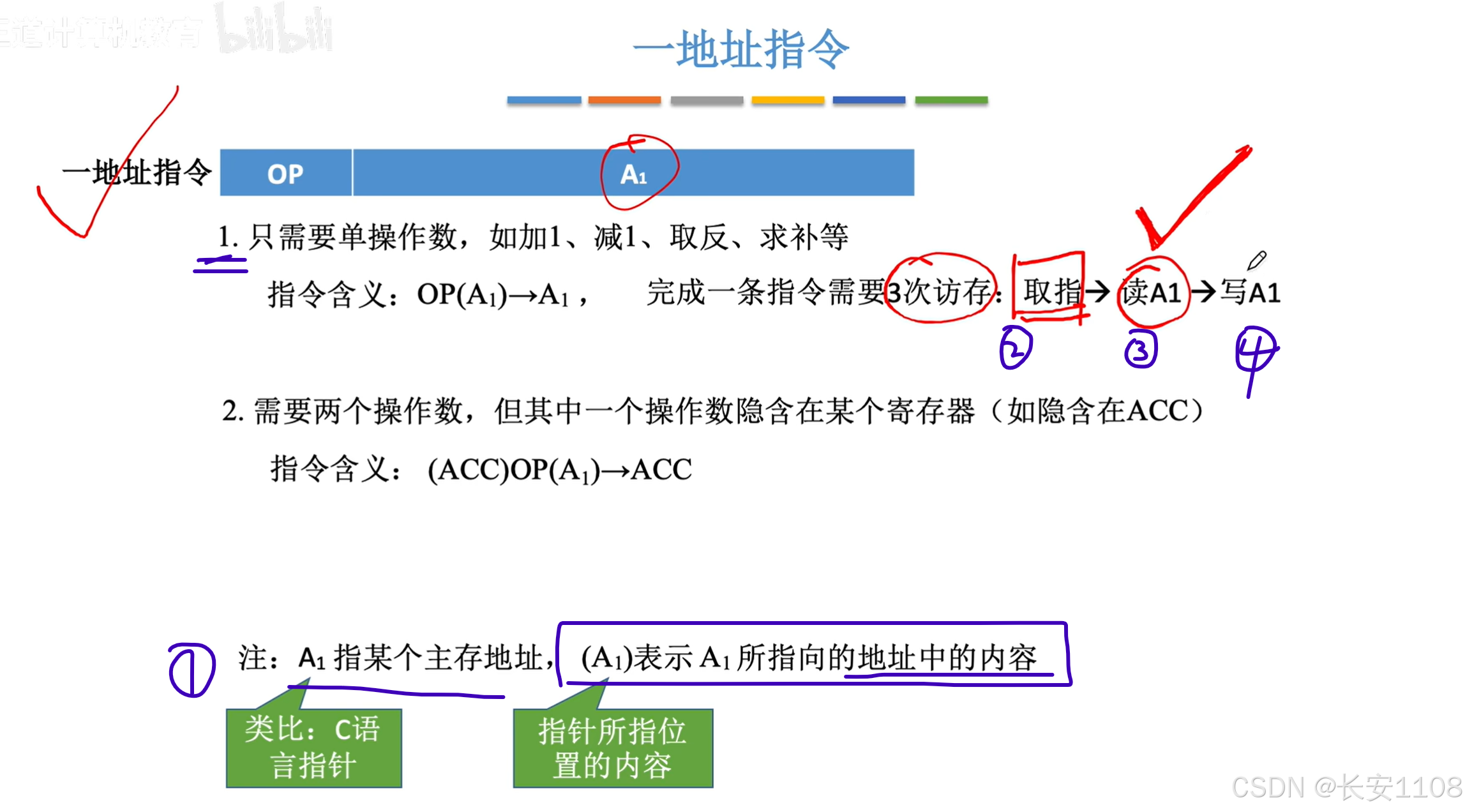
1、首先要知道,我们规定,(A1),若A1存的是地址,则(A1)表示的是A1所存储的地址,对应的内存单元上的内容
之后,要知道该指令执行要经历3次访存:
2、取指,就是将OP 和 A1这条指令拿到
3、然后根据第二步拿到的指令内容,去读取A1所指示的内存单元的内容
4、计算完毕之后,将最终结果写回A1
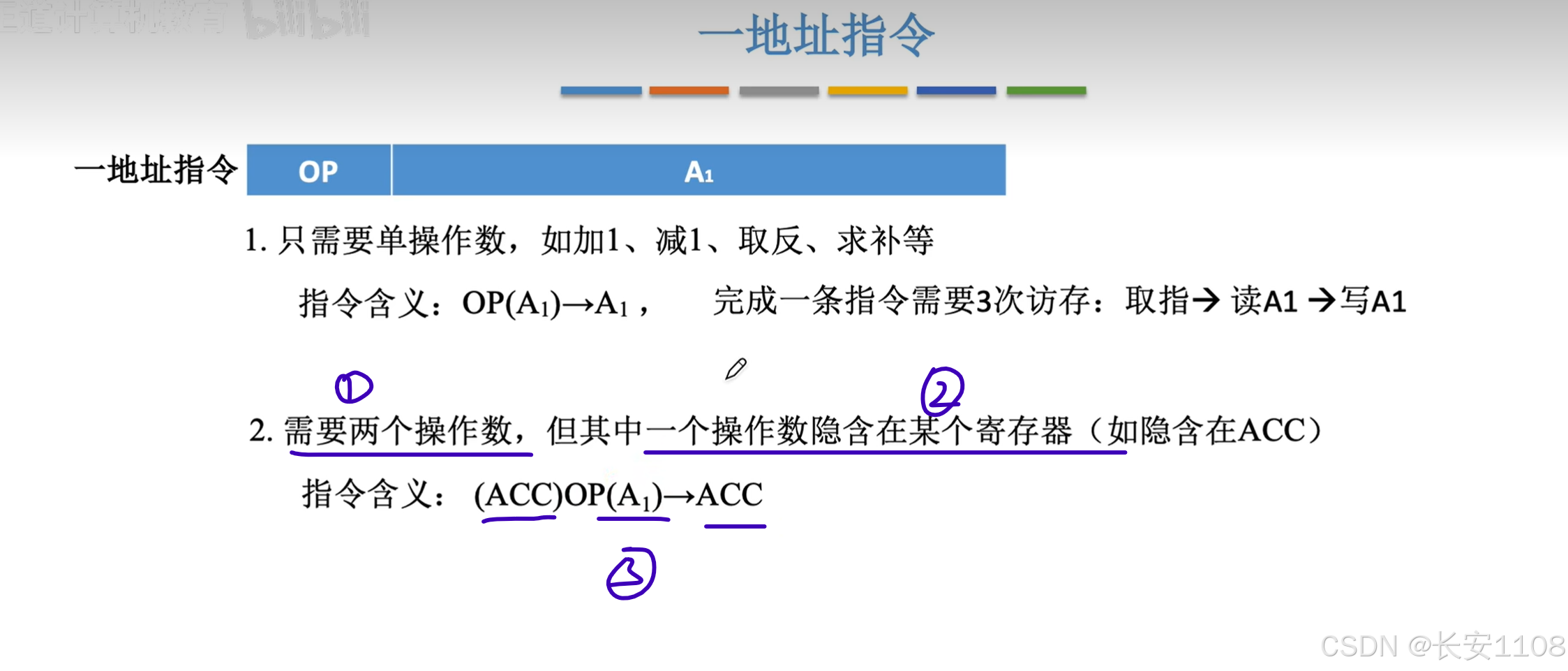
1、有些操作其底层的运算需要两个操作数
2、但是其中一个操作数已经规定好了在哪里存放,所以,整个指令显性地只需要指明一个操作数
3、比如,将A1地址上的数据 与 ACC寄存器所存储的数据 进行运算,结果放回ACC寄存器

只需要两次访存,取指令、读A1、最后将结果放入ACC,ACC是寄存器,不需要访存
PS:
(寄存器),就是拿到寄存器所存储的数据
(直接一个地址编号),就是拿到地址编号上内存单元的数据
二地址指令与三地址指令与四地址指令
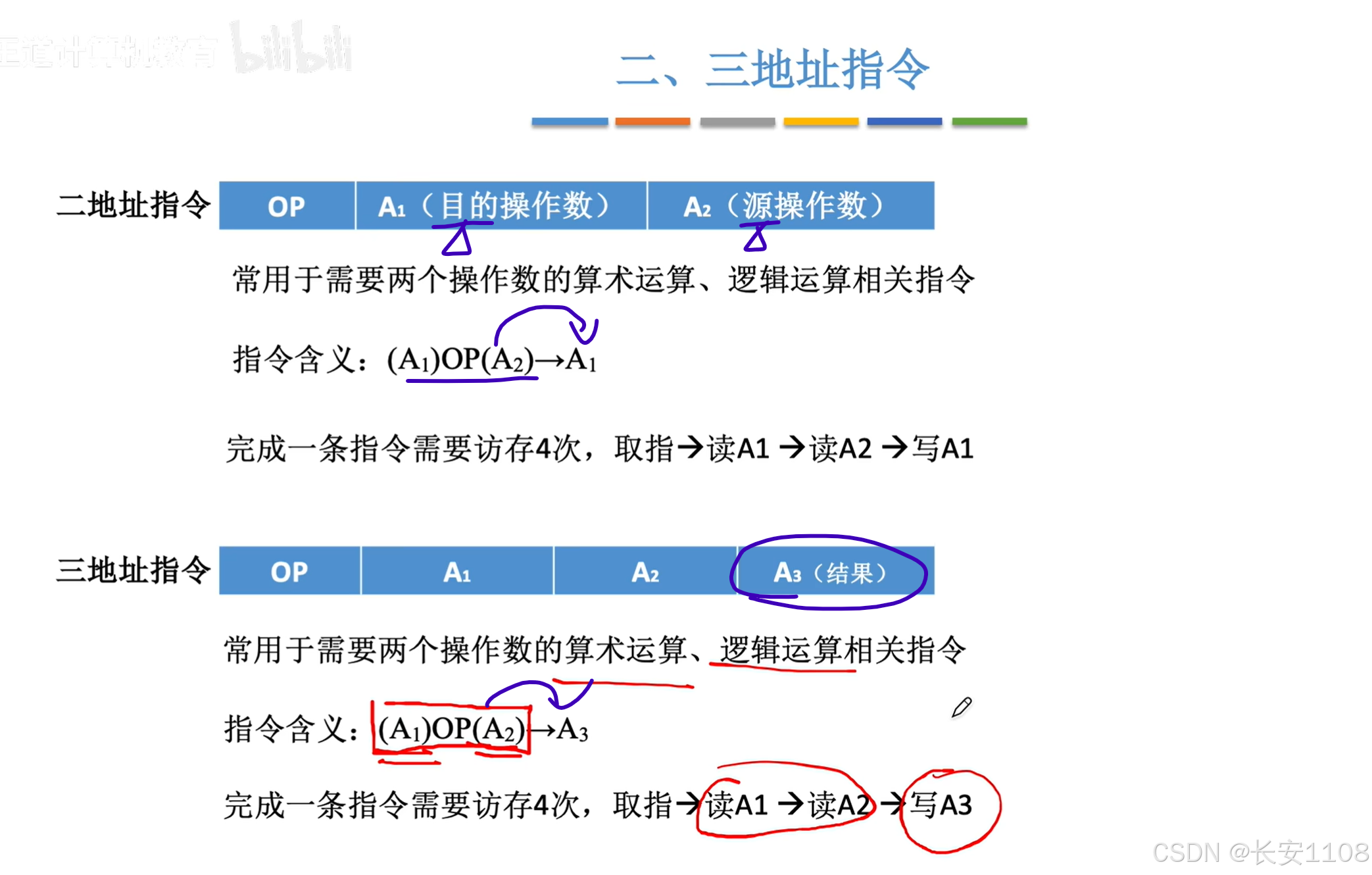
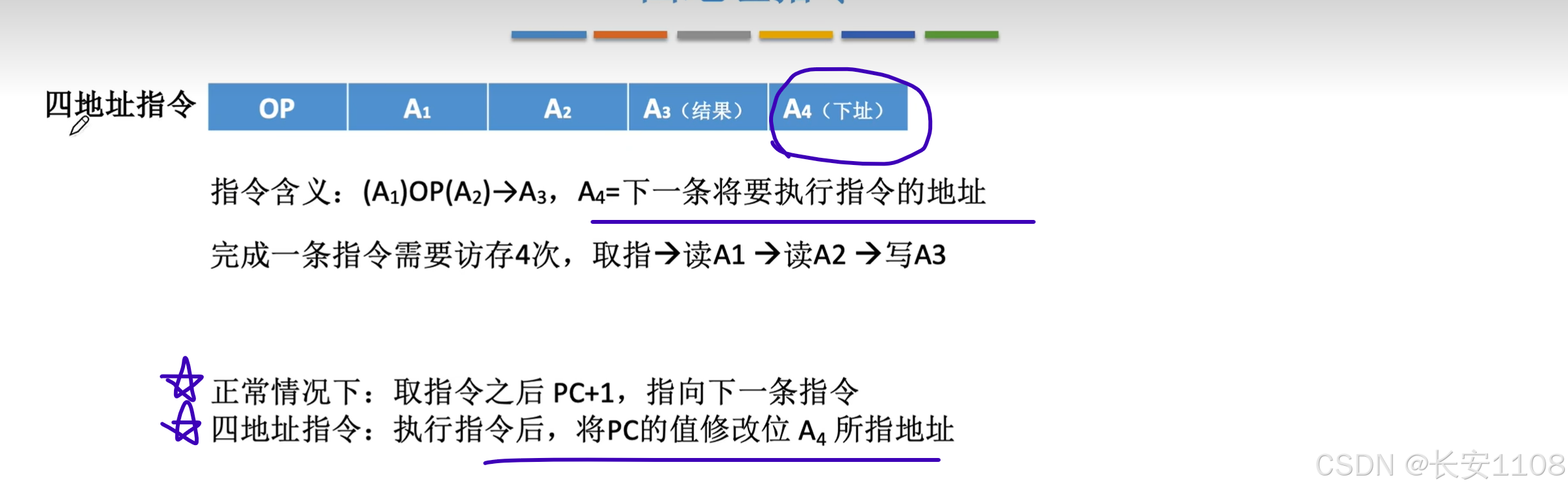
四地址指令与三指令地址差不多,多出来的第四个地址,存放的是下一条想要执行的指令的整个指令语句所在的地址,具体实现是将PC的值不进行下移,而是需改为A4所存的地址
根据指令长度分类
指令字长

1、存储字长,指的是一个存储单元中的二进制长度(一般为一字节,即8位,但也不排除可能是其他的)
2、机器字长,与运算有关
3、指令字长,是一个指令代码,在主存中所占的二进制长度
(单字节指令、双字节指令,是指指令长度是机器字长的多少倍)
4、例,存储字长等于机器字长,都是16bit,那么一条双字节指令,就会占两个存储字长,单单取出该指令代码,就需要两次访存(由于机器字长等于存储字长,所以,双字节指令 -> 本来指双机器字长,现在可以计算得到:双存储字长,所以,占两个基本单元)

注意上图是对“指令系统”的分类
根据操作码长度分类
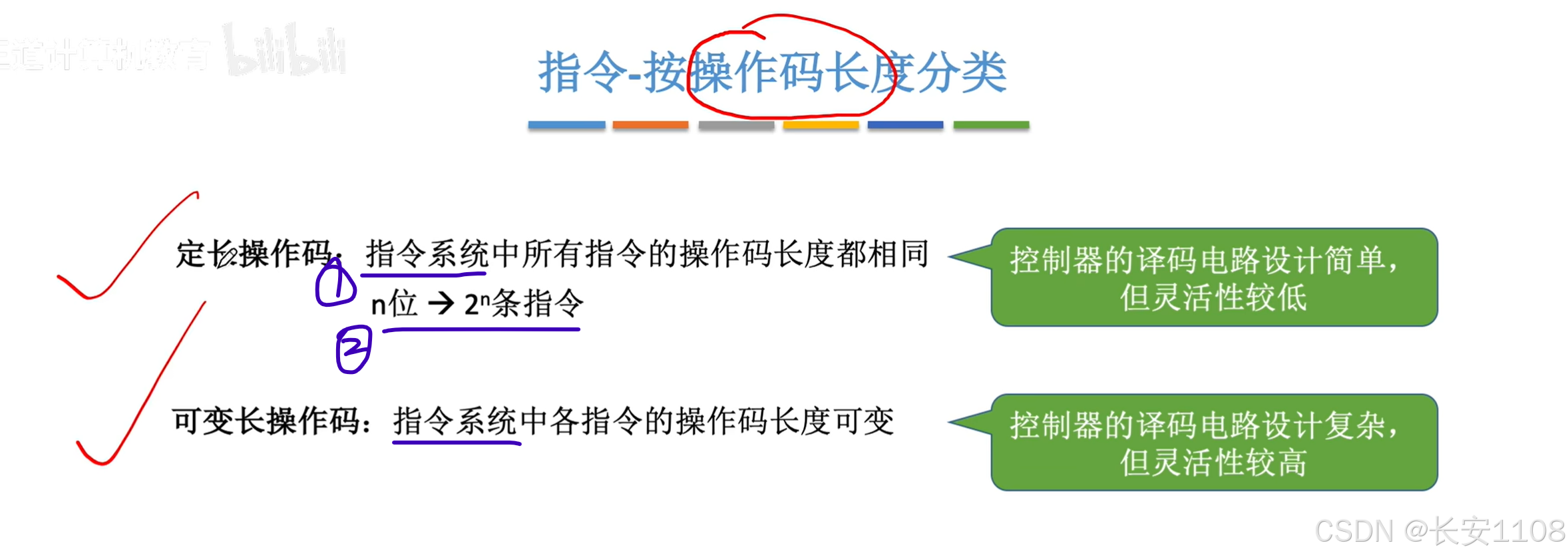
1、这里所区分的是“指令系统”
2、操作码的长度,决定了其能设置的指令的数量
按照操作码功能分类

总结
4.1.2 扩展操作码 指令格式
总览
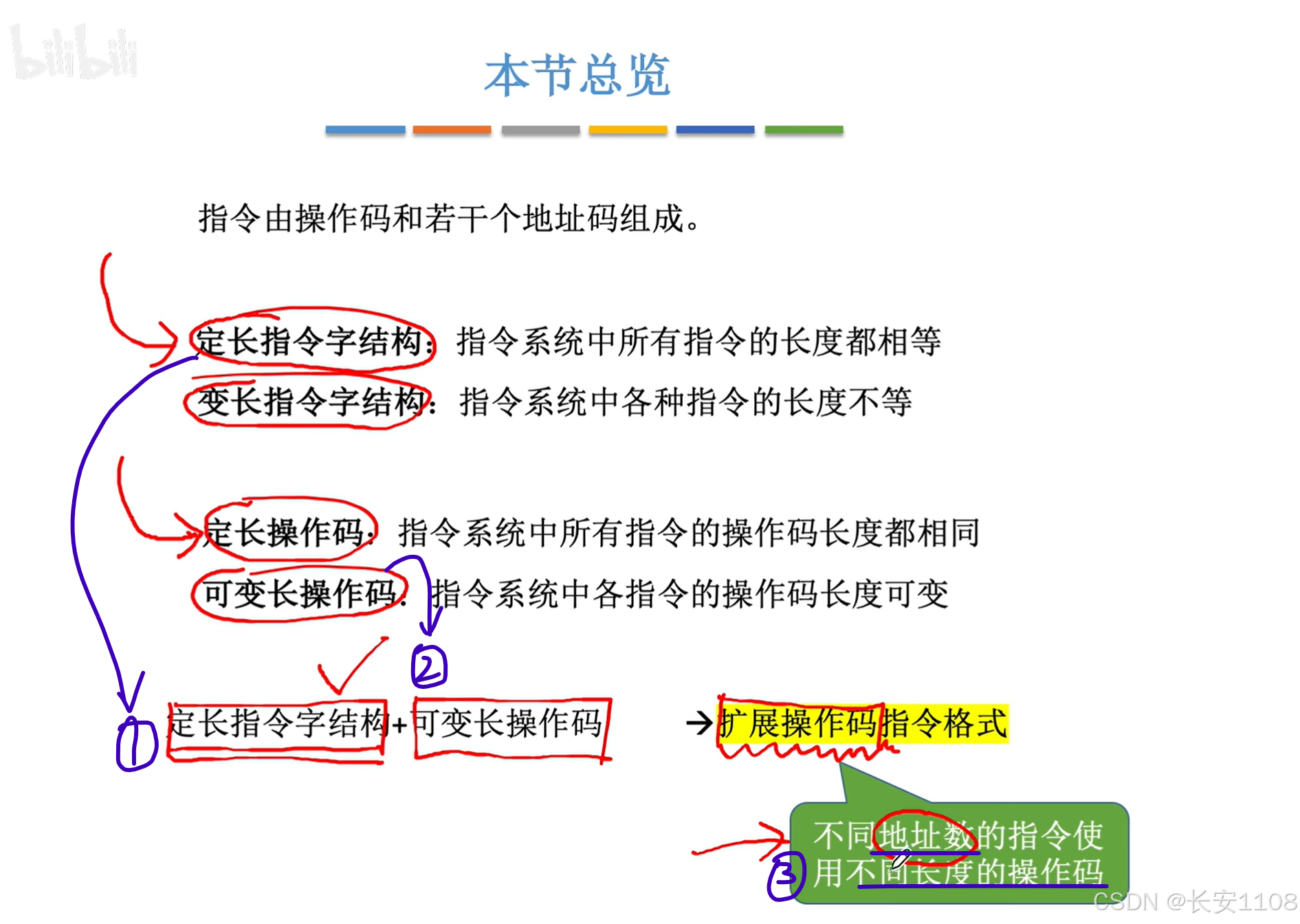
扩展操作码也是一种指令格式,首先我们知道,一条指令,由“操作码” + “操作数”(或者叫“地址码”)组成
而这种格式就是,
1、指令的总长度不变
2、操作码的长度可以变
3、优点是,可以根据“地址数”,也就是地址码的数量,来使用不同长度的操作码
举例

假如我们的总长度固定为16位,单个地址码固定为4位
我们从3地址指令开始设计,那么对于3地址指令,操作码的设置只有4位可用
1、所以,操作码就有0000 到 1111,一共16个可用,但是我们不使用1111,下面第2条解释了为什么不使用1111
2、而我们如果想在此基础上再设计二地址指令,那么,最高四位的1111可以用上了(与三地址指令区分),次高位的四位,就是二地址操作码能使用的4位二进制,同样保留1111 1111,用于下面设计一地址指令
依次类推
4、最后零地址指令,无需再为下面保留了,因为后面没有了,所有,零地址指令可以设置16条
设计准则

这两点都是参考“哈夫曼编码”来规定的
“不同的地址数,且是不同范围个数的操作码”的机器代码设计
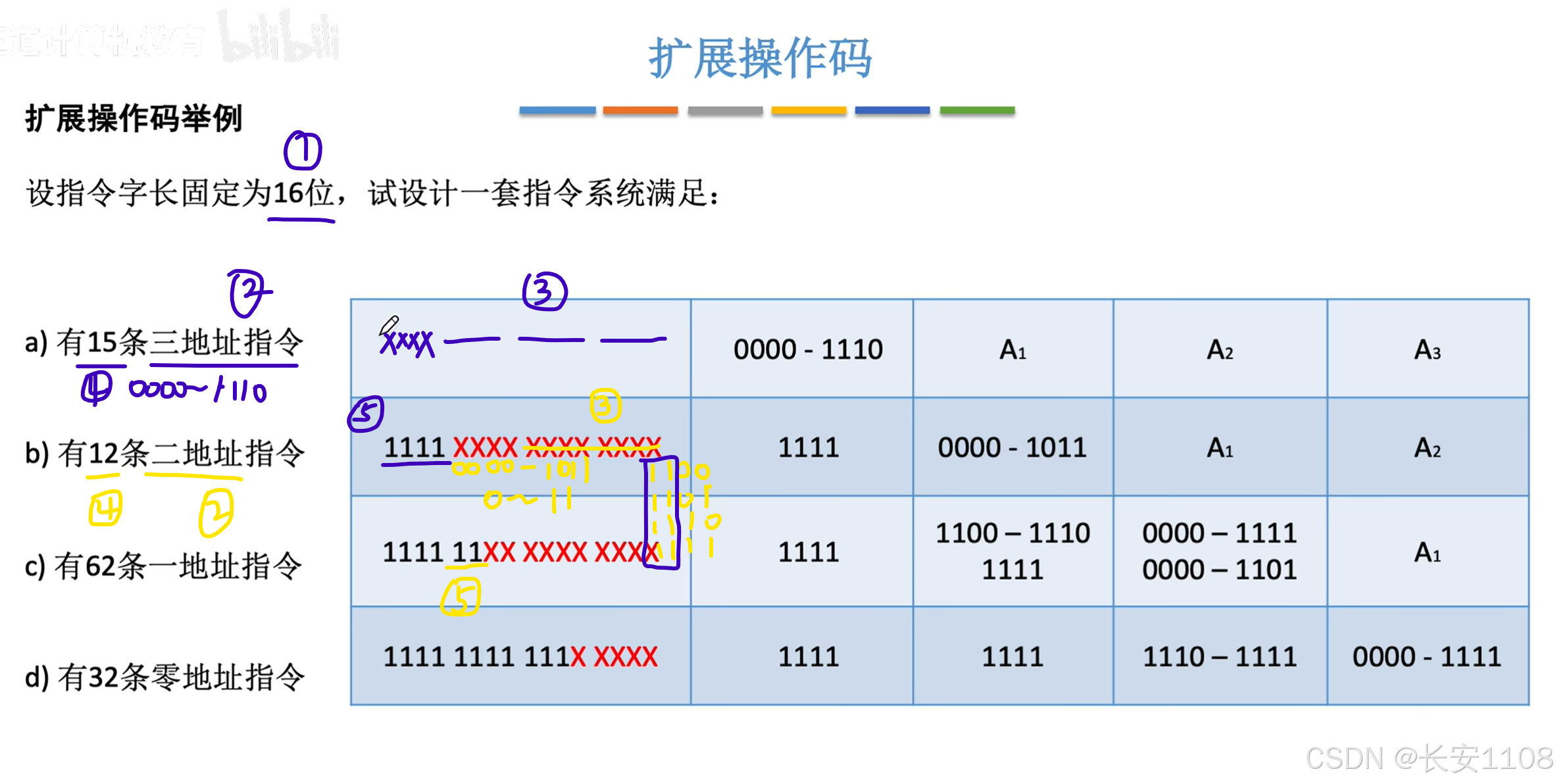
步骤:
1、先确定整个指令的总长度
对于a:
2、确定地址码的个数:有三个,且单个地址码长度为4位(题目未说明的话按4为处理)
3、16位,划掉右边的三个4位
4、还剩一个4位,根据规定的指令个数,为15条,所以,有效的指令为0000~1110
5、看后续指令的二进制特征,后续只有一个1111,所以,接下来更少的地址码个数的指令,其特征就是前四个为1111
对于b:
2、确定地址码的个数:两个
3、12位,划掉右边的两个4位
4、还剩中间一个4位,根据指令个数,为12条,所以,有效指令为0000~1011
5、看后续指令的二进制特征,后续为1100、1101、1110、1111,特征是前两位均为11
所以,更少的地址数的指令的特征就是1111 11xx xxxx xxxx
CPU区分不同地址码的指令:
1、前四位不是1111:三地址码指令
2、前四位是1111,但接下来两位不是11:二地址指令
3、前六位是1111 11,但接下来5位不是11111:单地址指令
4、前11位是1111 1111 111
数目的计算:
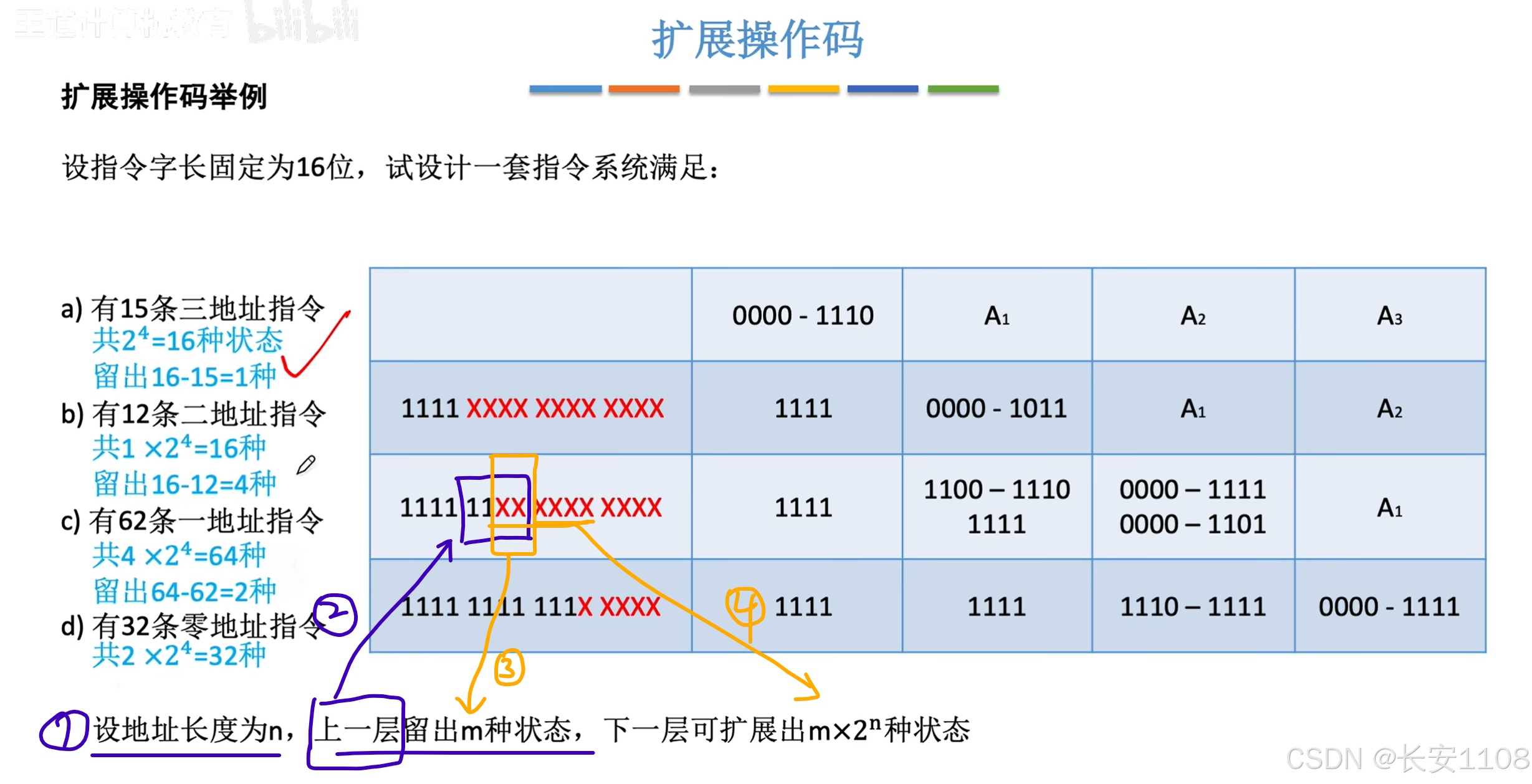
1、首先要确定单个地址码的长度,n
2、之后,“每一层”指的是,将所有的二进制位,分为多个地址码,每一层就是指每个n位二进制
3、每一层留出的状态数量:根据上一层没有填满的二进制位,例如上一层留下的他那一层还有t个二进制位没有填满,则留出的状态数量就是2的t次方
4、最后就是2的t次方 * 2的n次方,就是下一层可以拓展的状态数(即下一层可以拓展的最多的状态数,但不一定全用上),其实就是2的(t+n)次方
对比“不定长操作码”和“定长操作码”

4.2 xxx
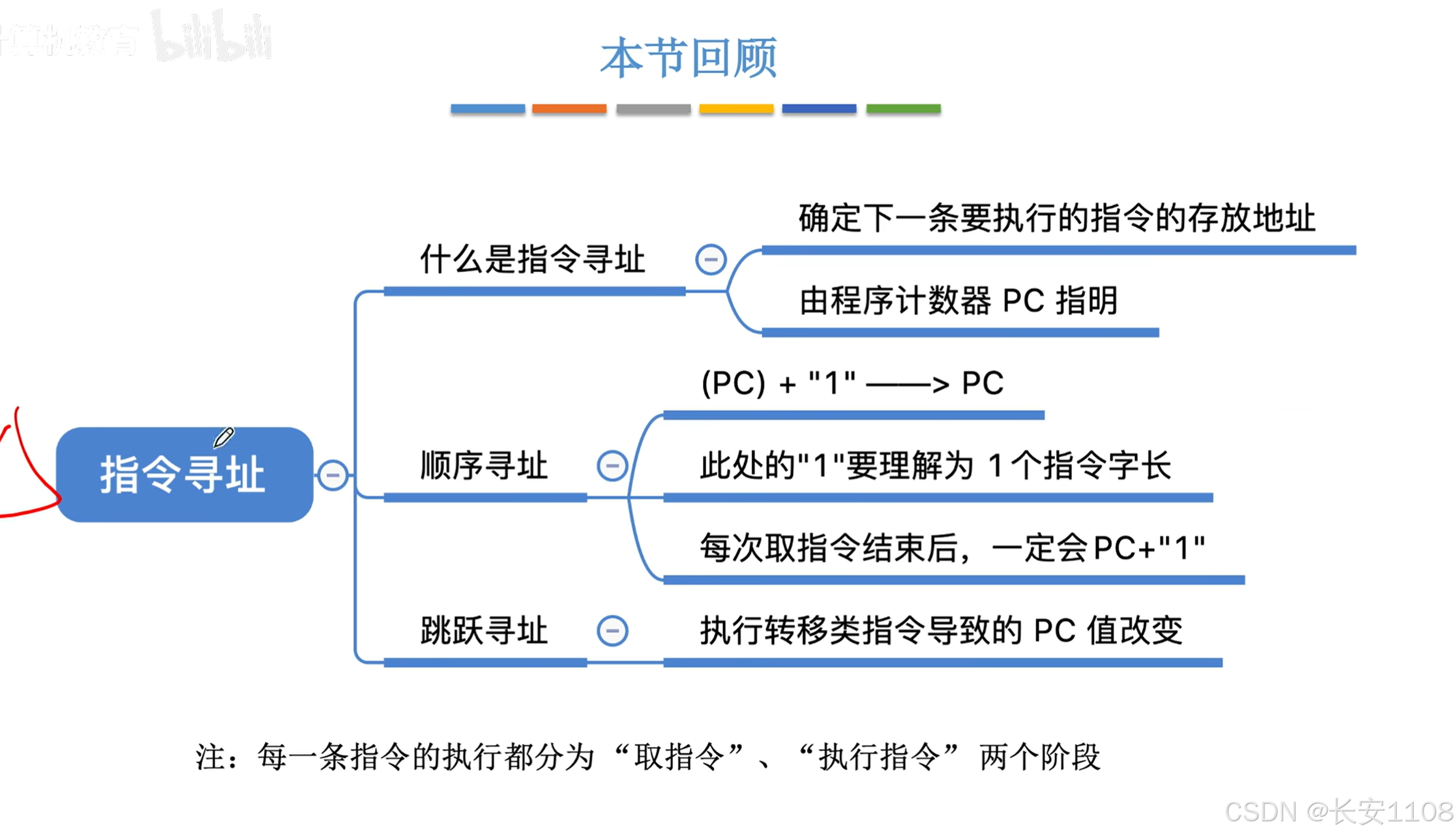
4.2.1 指令寻址(寻找“指令代码”所在主存的位置)
总览
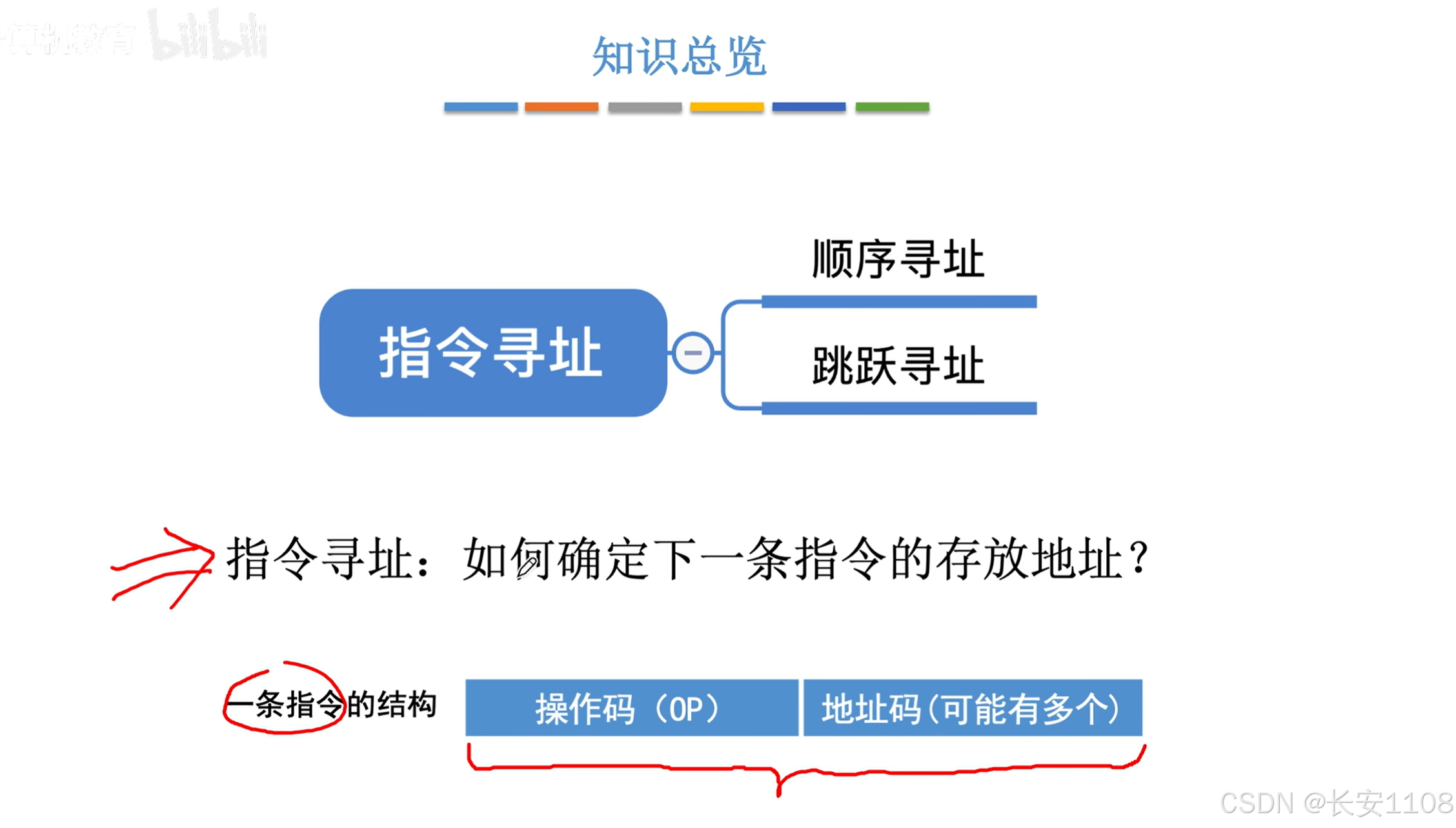
顺序寻址
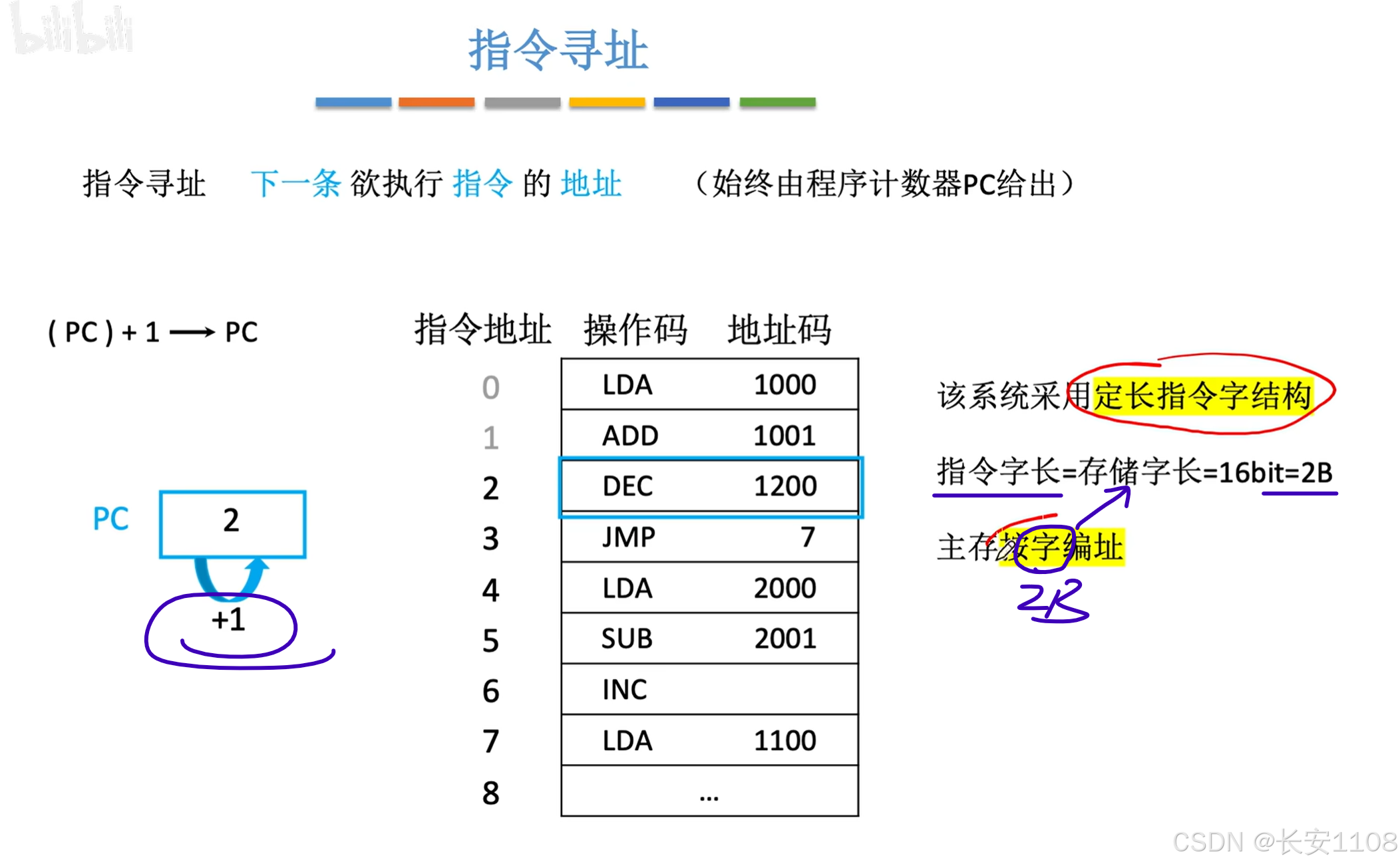
当一条指令,正好占了一个内存单元的大小时,PC的值不断+1即可
(PS:这里(pc)指的就是pc寄存器所存储的数据,而PC所存储的数据就是指令的地址)
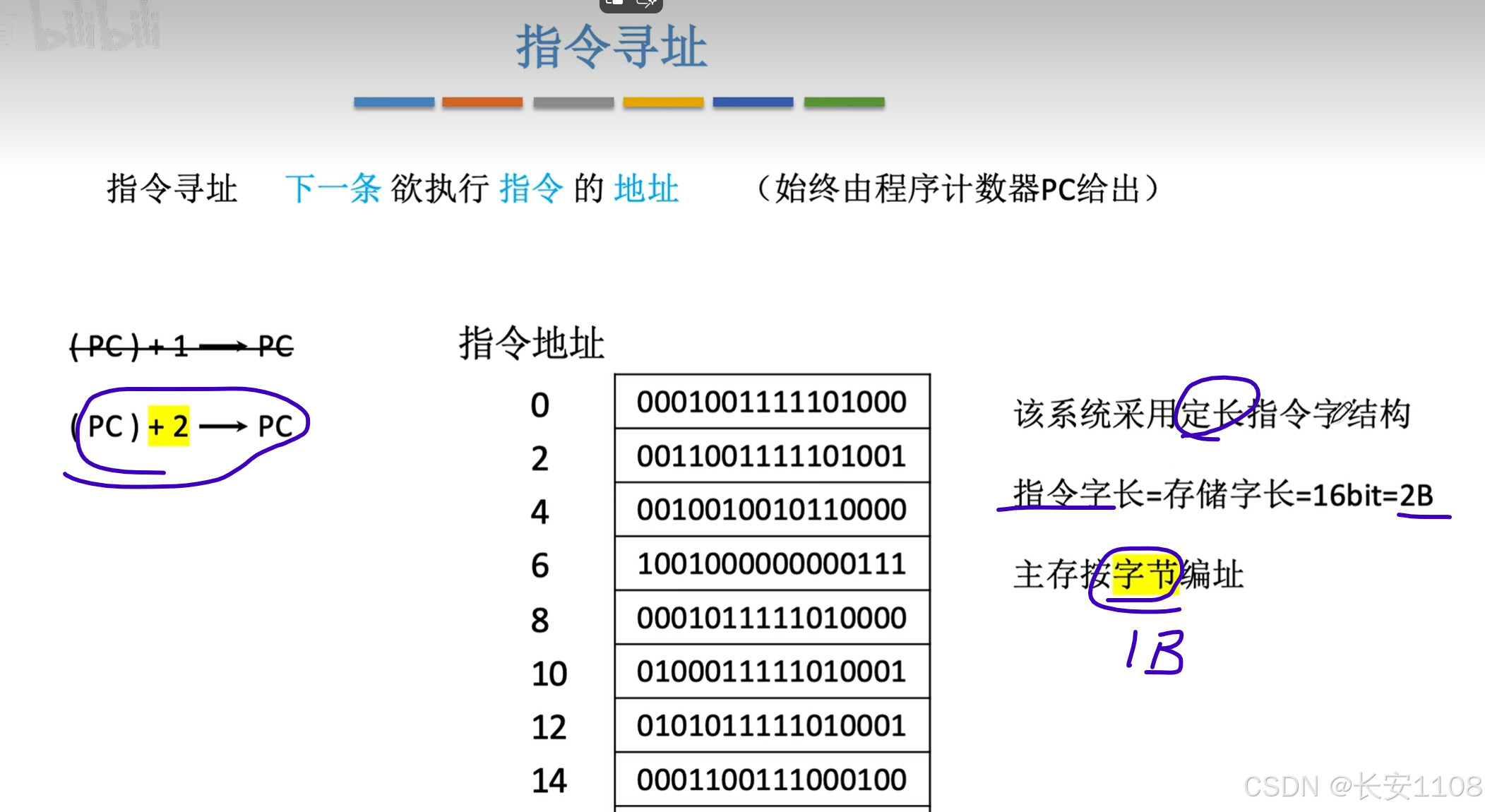

1、!!!注意:这里与前面的“拓展操作码”格式是不一样的,这里是变长,说的是指令的总长度会变,我们还没有详细介绍过这种格式
这种格式同样可以根据其指令的二进制机器代码,有一些特征,可以得出其占多少个字节数
由于是按字节编址,所以,pc+字节数,就是下一条指令的机器代码所存储在的主存的首地址编号
(但是CPU需要多次访存,即,例如对于第一条指令,读取PC、PC+1,处的单元的内容,才能把第一条指令的机器代码拿到)
跳跃寻址
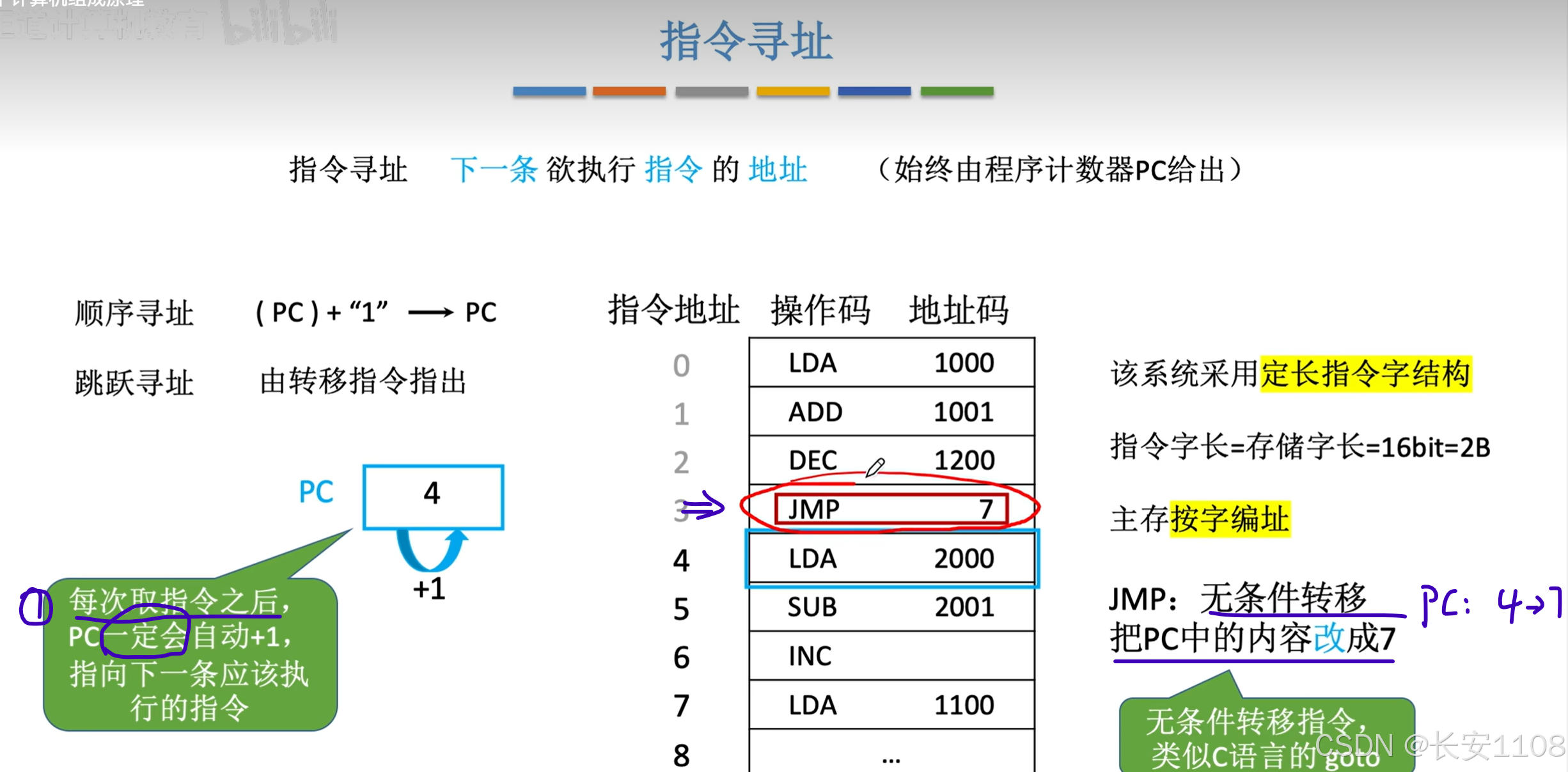
1、每次执行当前指令时,PC一定会自动+1,在指向下一条要执行的指令,也就是当PC执行4号地址时,当前还在执行3号地址的内容
当执行到JMP后,将PC的值从4改为了7
具体的:CPU执行一个指令分为两步:“取出指令”+“执行指令”
而CPU“取出指令”后,PC就去指向下一个指令了,之后CPU再去“执行刚刚取出的指令”
总结
4.2.2 数据寻址(寻找“地址码”所想要表示的在主存中的真实地址)
总览

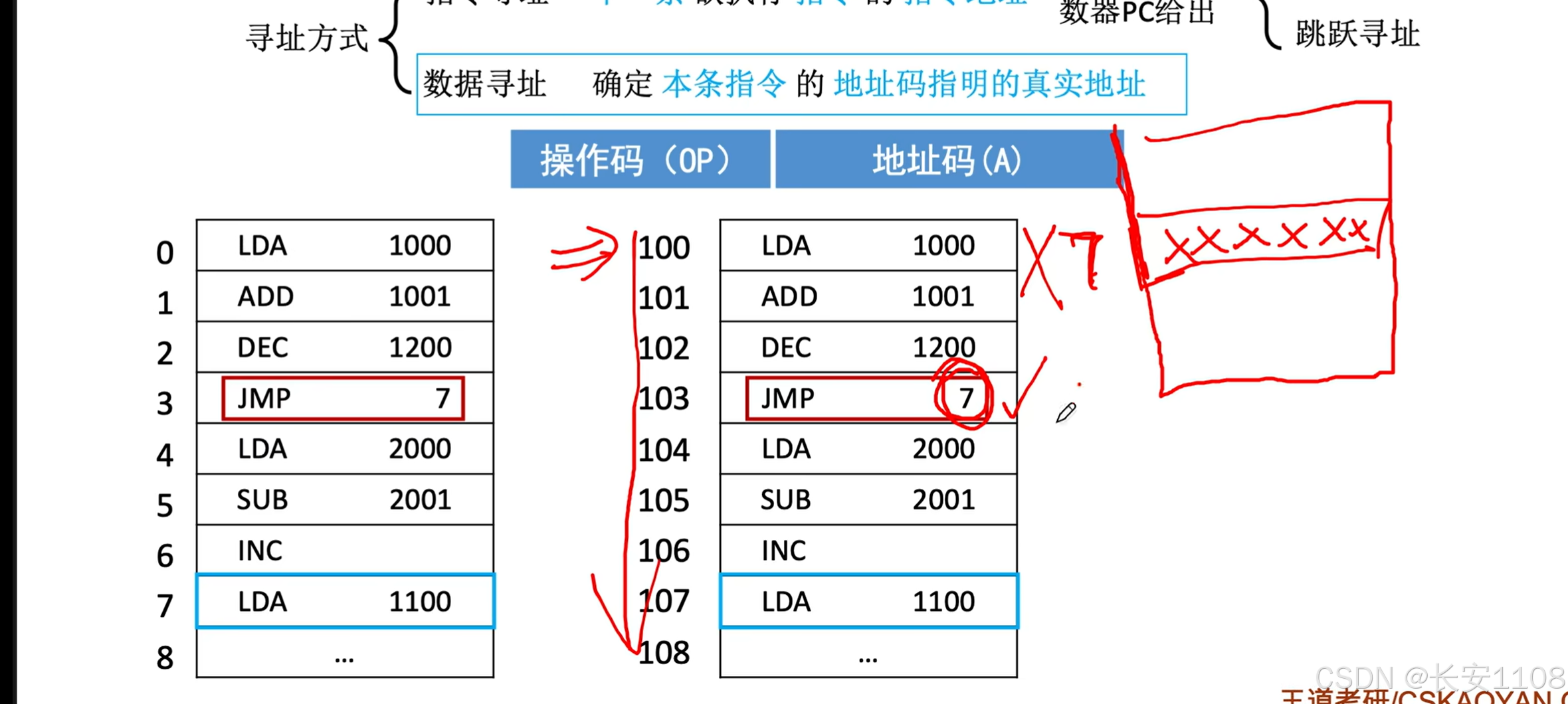
有可能,程序代码中写死了要跳转到地址编号为7的单元,但是,主存在存储这系列代码时,不一定从主存的0号地址开始存,所以,会造成错误
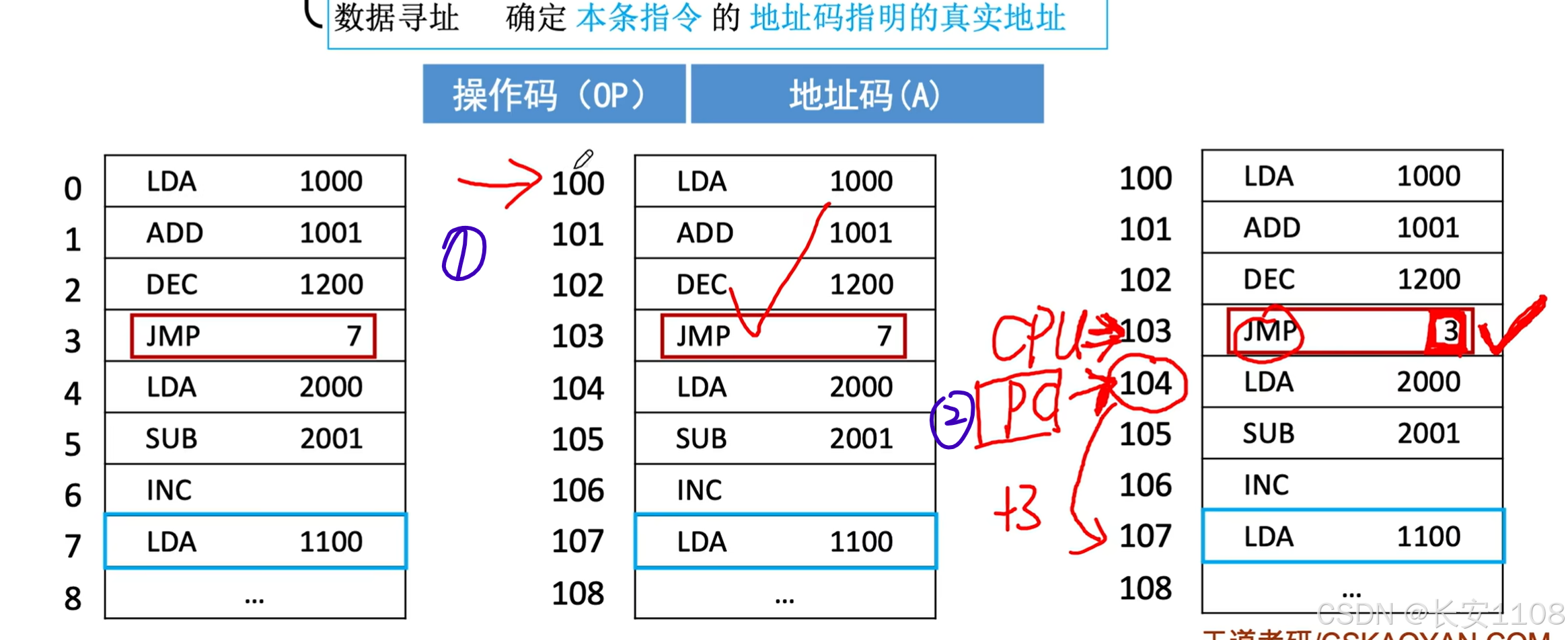
且,哪怕是一模一样的代码,其具体想表达的逻辑可能也不同,如上图:
1、想表达从程序第一个代码开始偏移7个单元
2、表达从当前PC开始,偏移3个单元
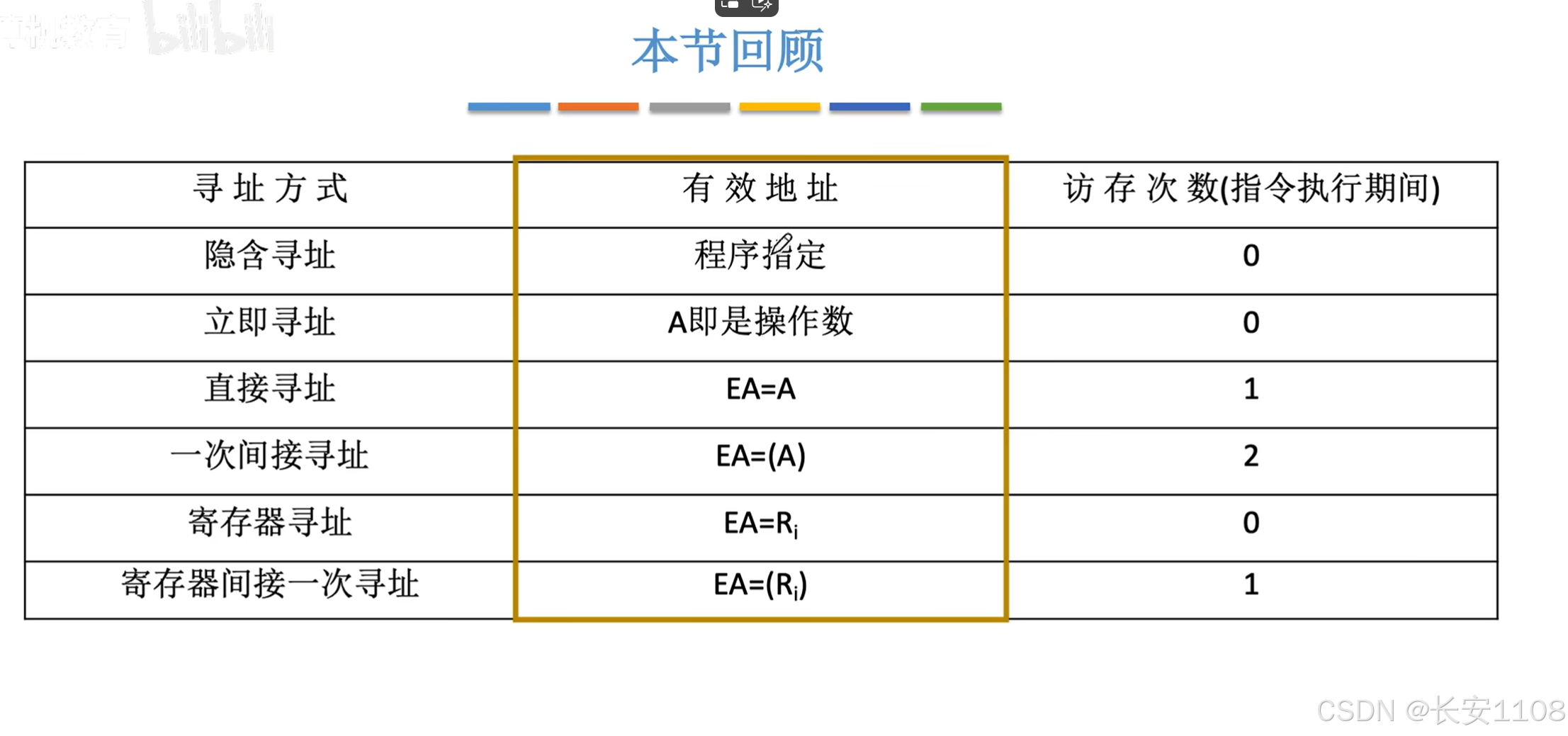
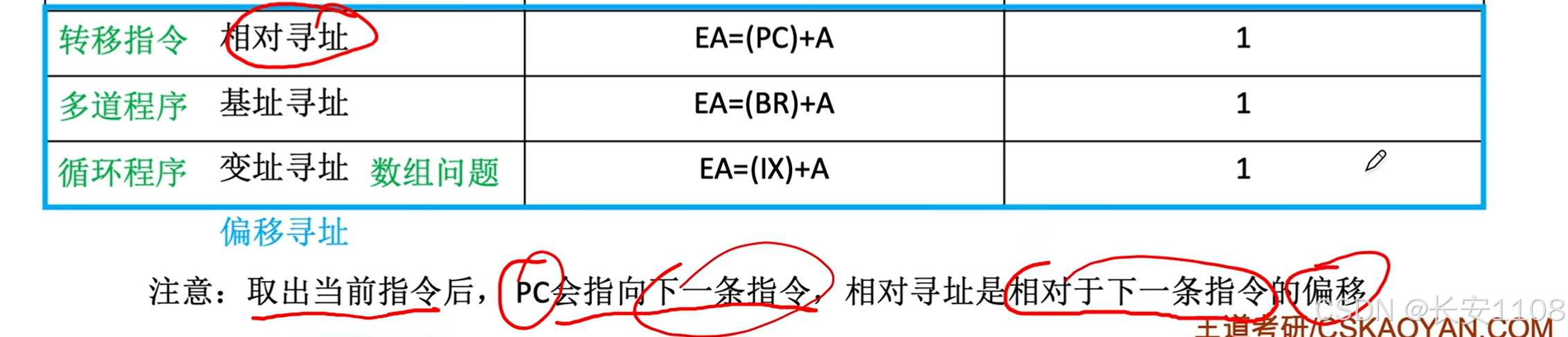
十种数据寻址方式总览
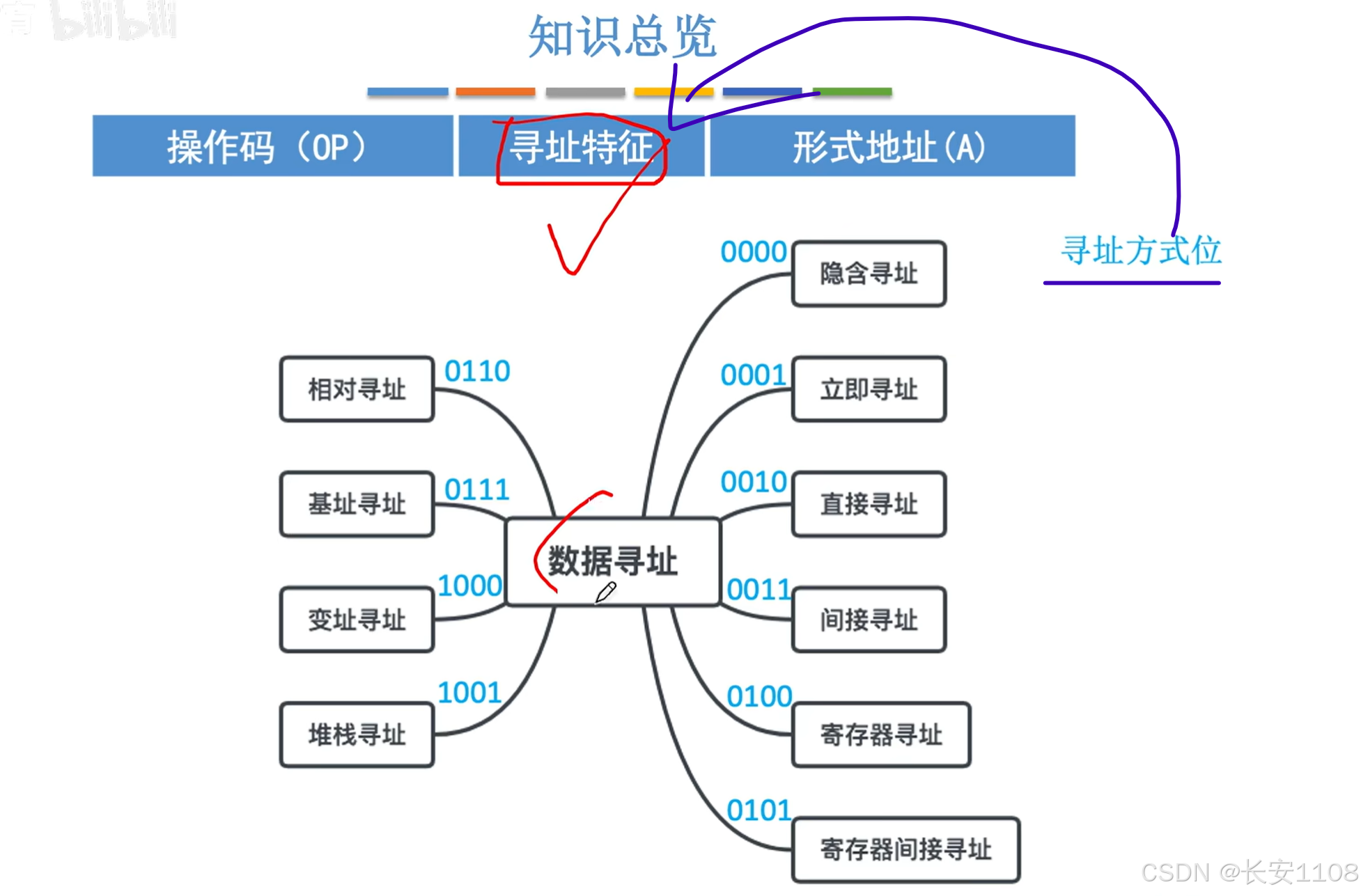

其他地址码数量的格式类似:
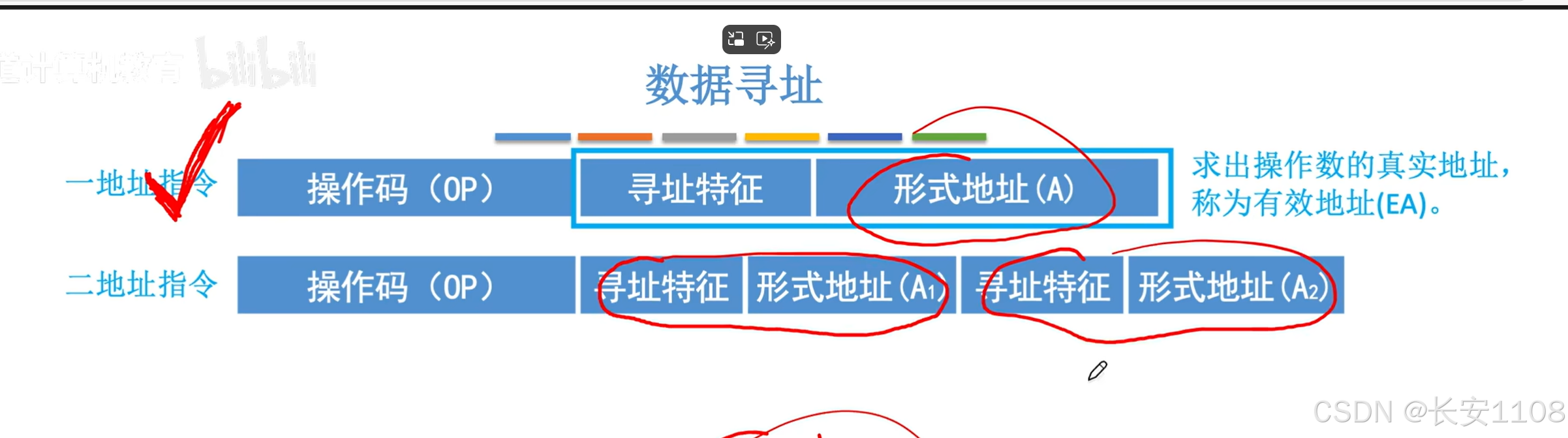
同时,为了方便理解,我们做出如下假设:

直接寻址
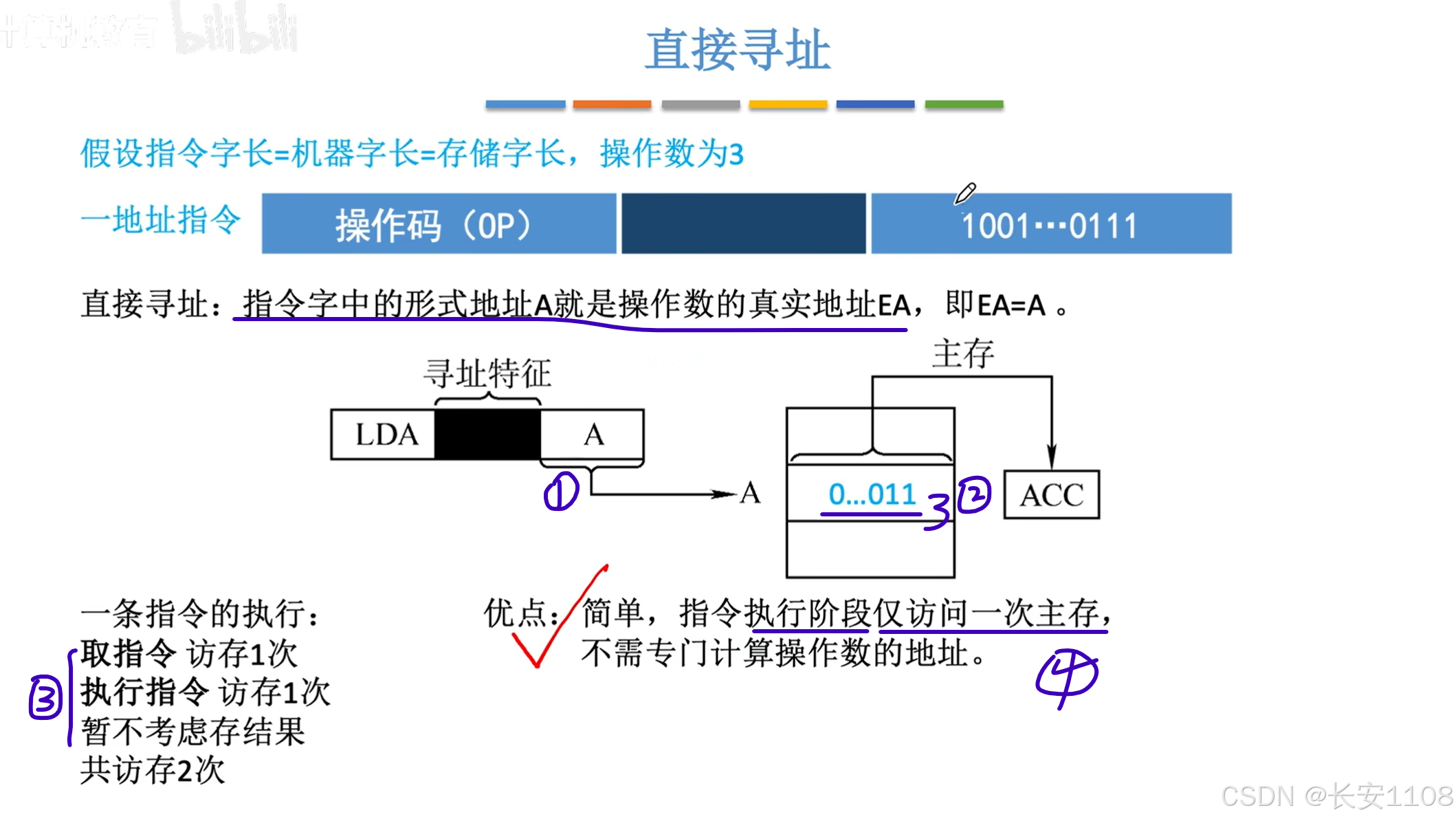
1、直接寻址,其地址码就是真实的EA
2、A地址上的内容是“3”
3、该方式总共会访存两次,第一次取指令机器代码;第二次访问A地址上的数据;结果存到了ACC寄存器,不进行访存
4、优点是简单,且在“执行指令”阶段,仅访问一次主存

1、由于A直接存储操作数的EA,所以,A的位数,决定了其能指示的EA的范围
2、不易修改是指,当数据“3”不在A所指示的地址上了,则该代码就失效了
间接寻址
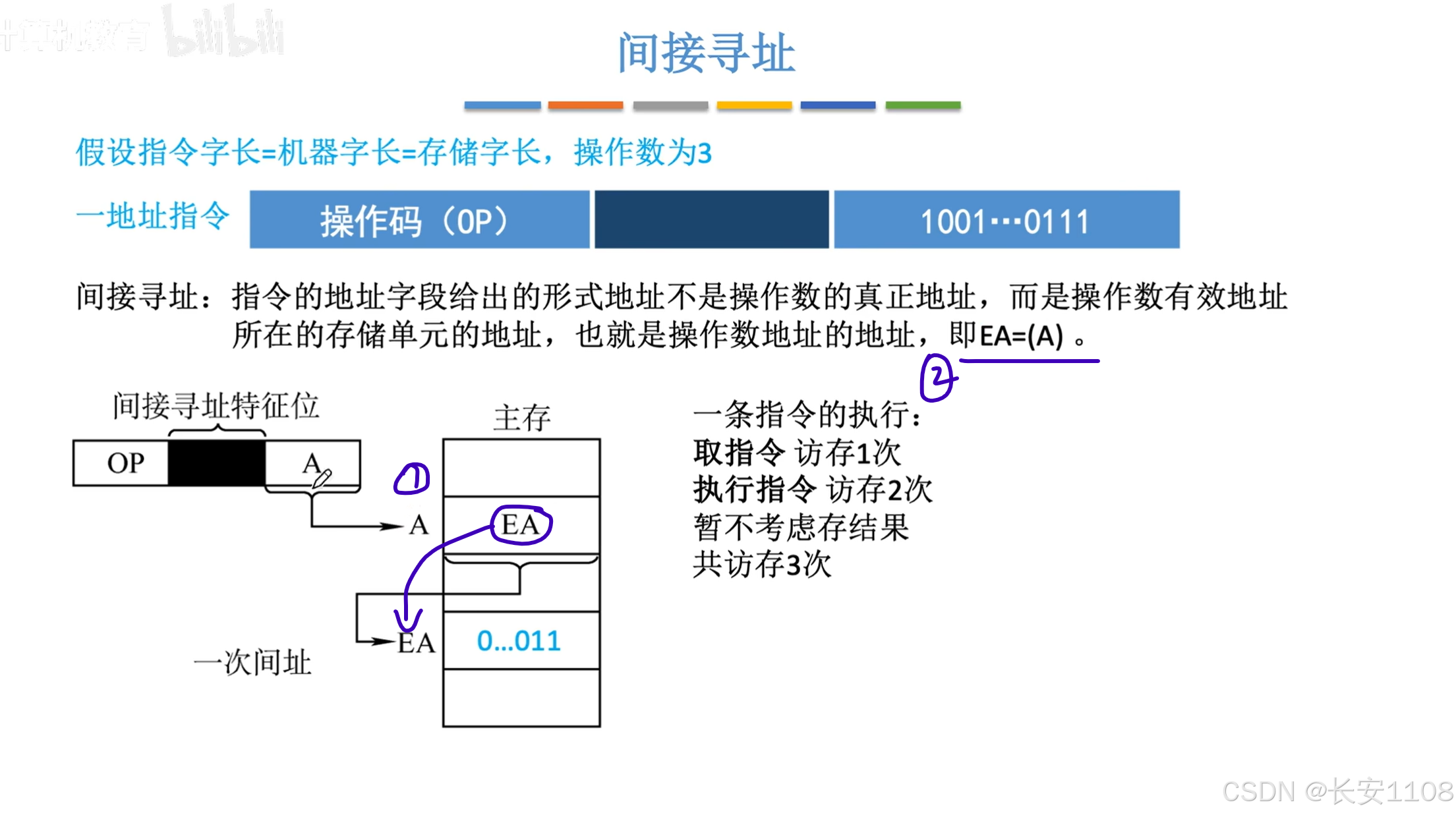
1、指令中还是直接的一个地址,只不过这个地址指向的单元的数据不是我们最终想要的数据,这个“数据”是我们的目标数据所在的地址
相当于,A是一个指针的地址,那个指针是主存的一块内存单元,存储了最终我们想要的数据的地址
2、即(A) = EA
优点:
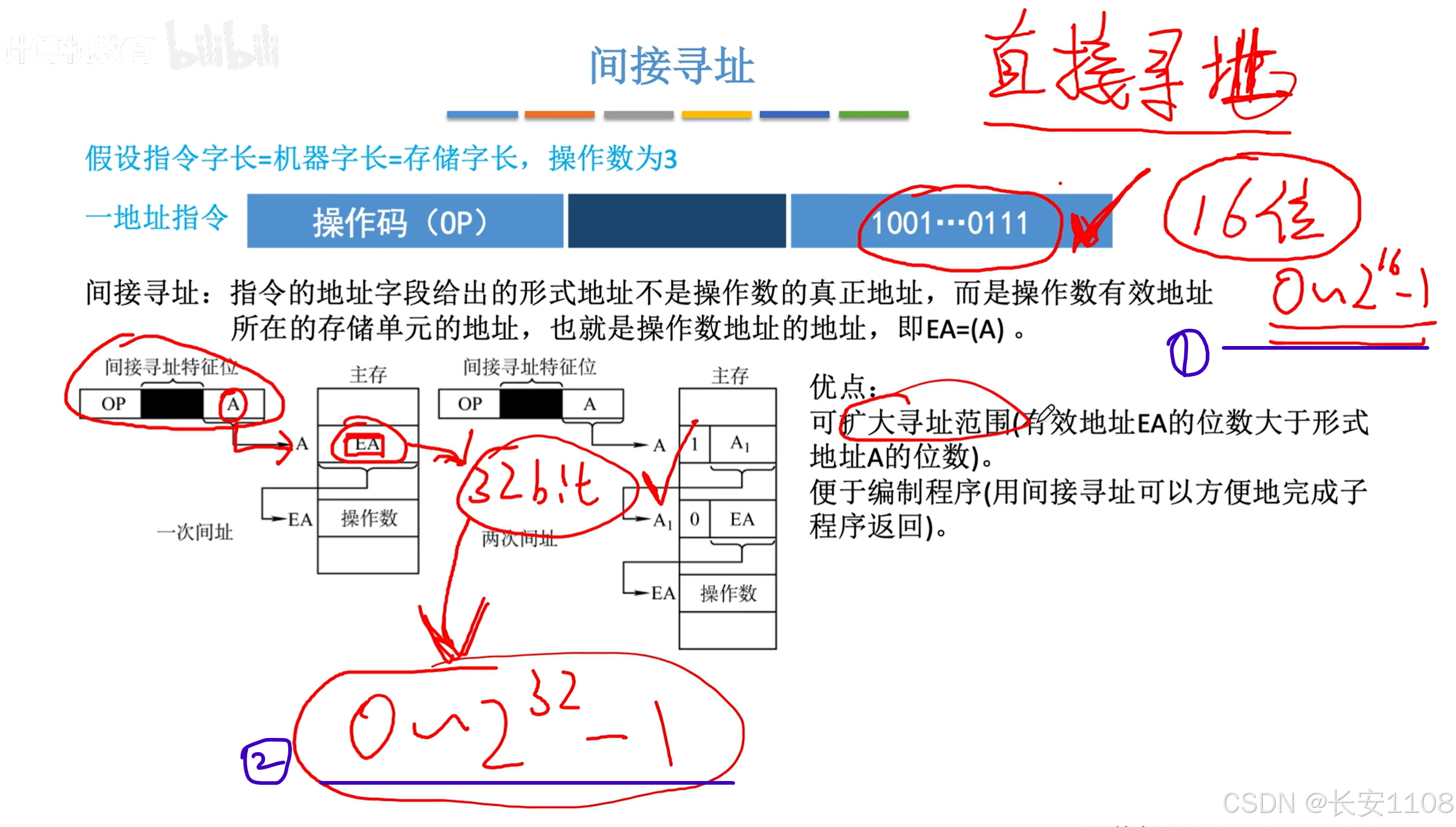
1、直接寻址中,由于指令长度的限制,我们能寻址的范围是0到2的16次方-1,或者说数据的地址必须在0到2的16次方-1,这个地址编号范围内
2、而使用了间接寻址,我们最终的数据的地址是存在了一个主存单元上,所以,寻址范围就依赖于一个内存单元的大小,假如说一个内存单元有32bit,那么数据的地址范围可以在0到2的32次方-1,数据可以存放的范围被大大扩大了,而我们只需要保证,指针单元的地址编号,在0到2的16次方-1的范围内即可
多级间接寻址的优点:

使用多级间接寻址,其实就是多层函数调用的等效
假如说我们有a b c 三个函数,
b函数的语句中有调用c函数,即上图的A1存储“0-EA”的地址,而如果我们在a内调b,则是A存储“1-A1”的地址
间接寻址的缺点:

效率也会变低
寄存器寻址
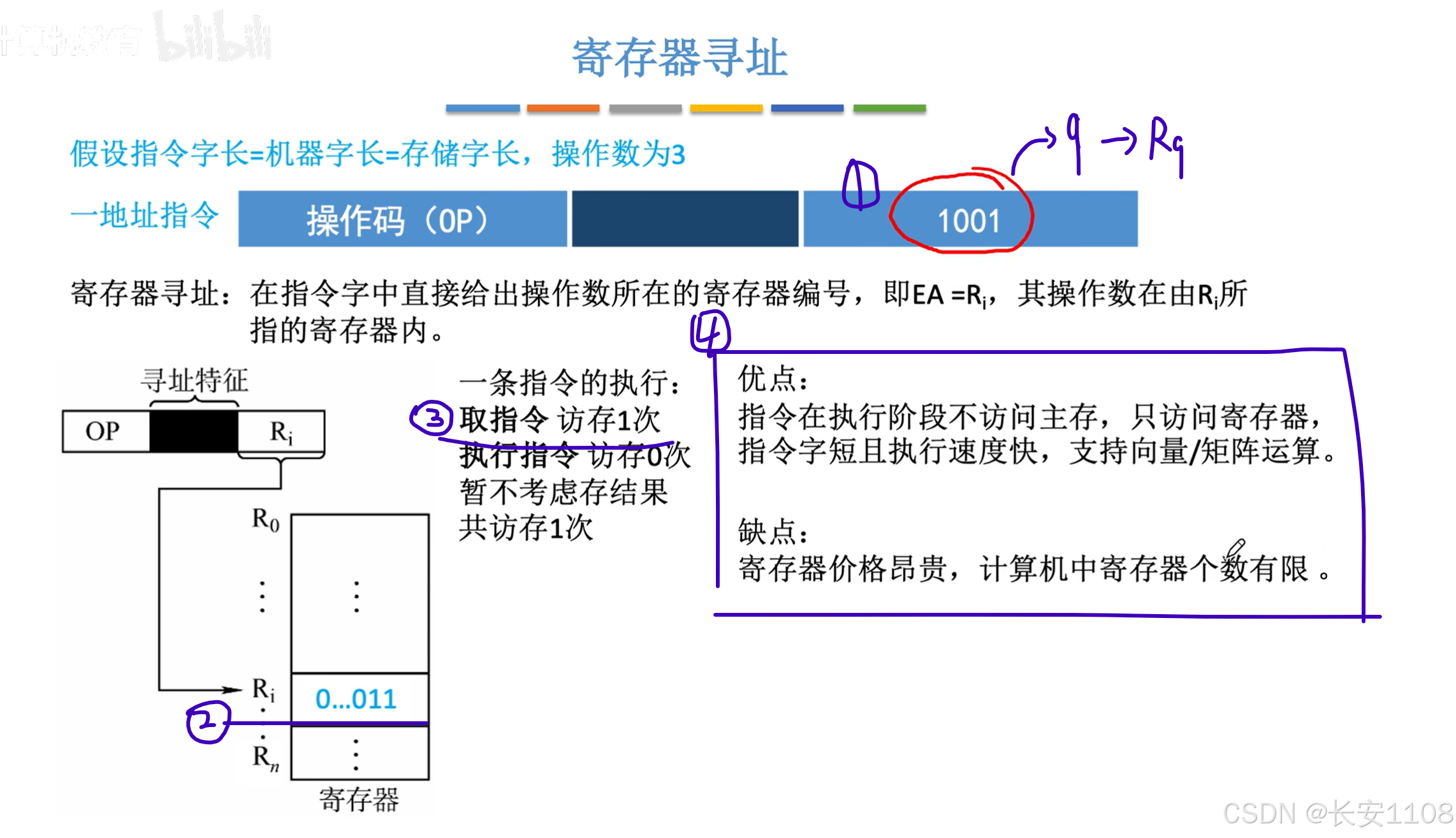
1、首先,寄存器寻址指令中,其二进制翻译为十进制,就是寄存器对应的编号,如上图,对应寄存器R9
2、这里虽然是内存图的形式,但是,他实际上就是想表达,Ri中存的数据是3,跟地址没有关系
3、整个过程只访存一次,因为只有取指令这个操作需要访存(拿到存储在主存中的“指令机器代码”)
4、优缺点
寄存器间接寻址
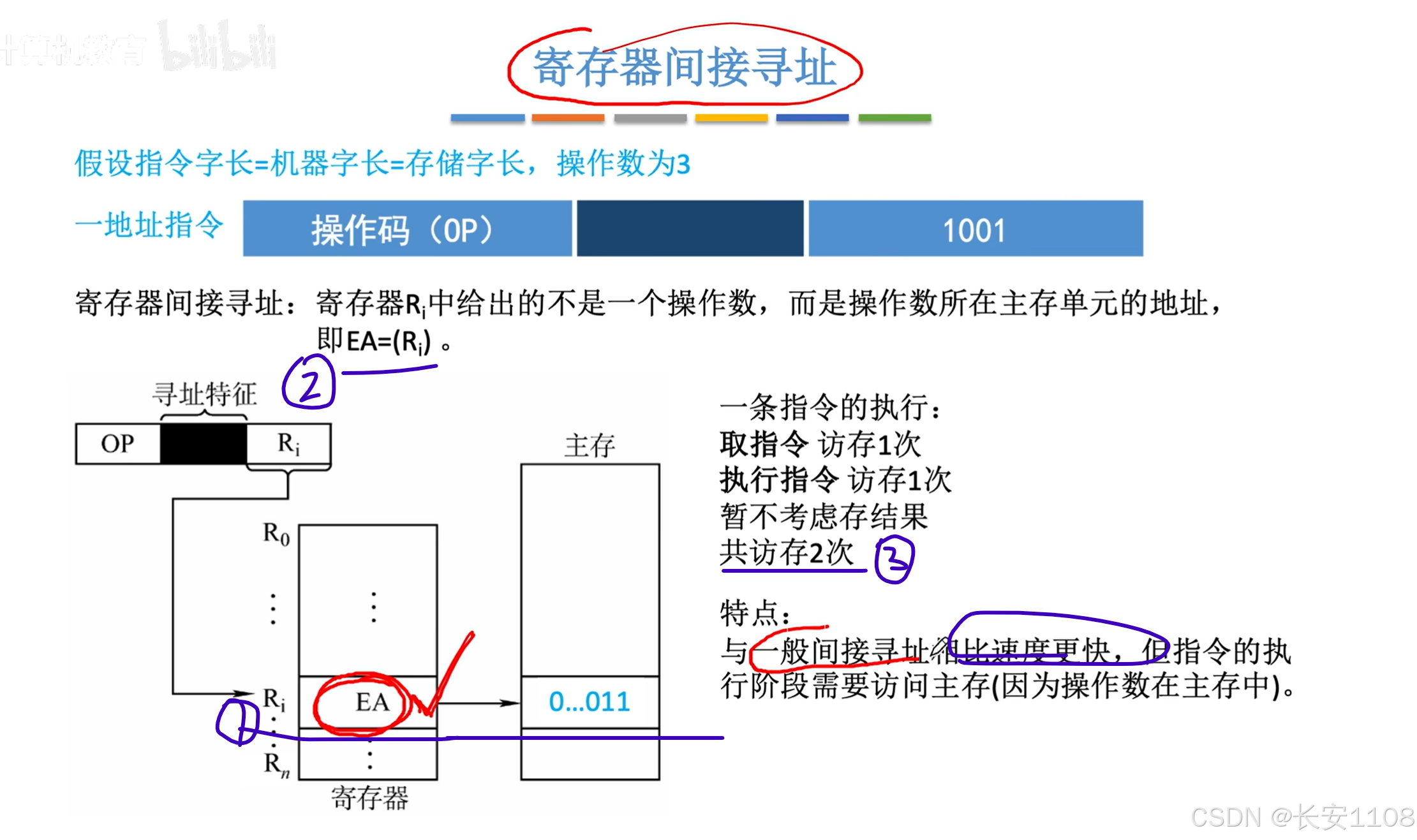
1、即寄存器中存放的数据,就是EA
2、再次强调:
(直接地址编号):地址编号对应单元上的数据
(寄存器):寄存器内的数据
所以,EA = (Ri)
3、一共访存两次,而直接使用地址来间接寻址最少要访存3次
(其实使用寄存器将EA保存中,其底层与直接寻址一样,只不过地址用寄存器保存了而已,但是外层确实是间接寻址,所以,肯定比地址编号间接寻址要少一次访存)
隐含寻址
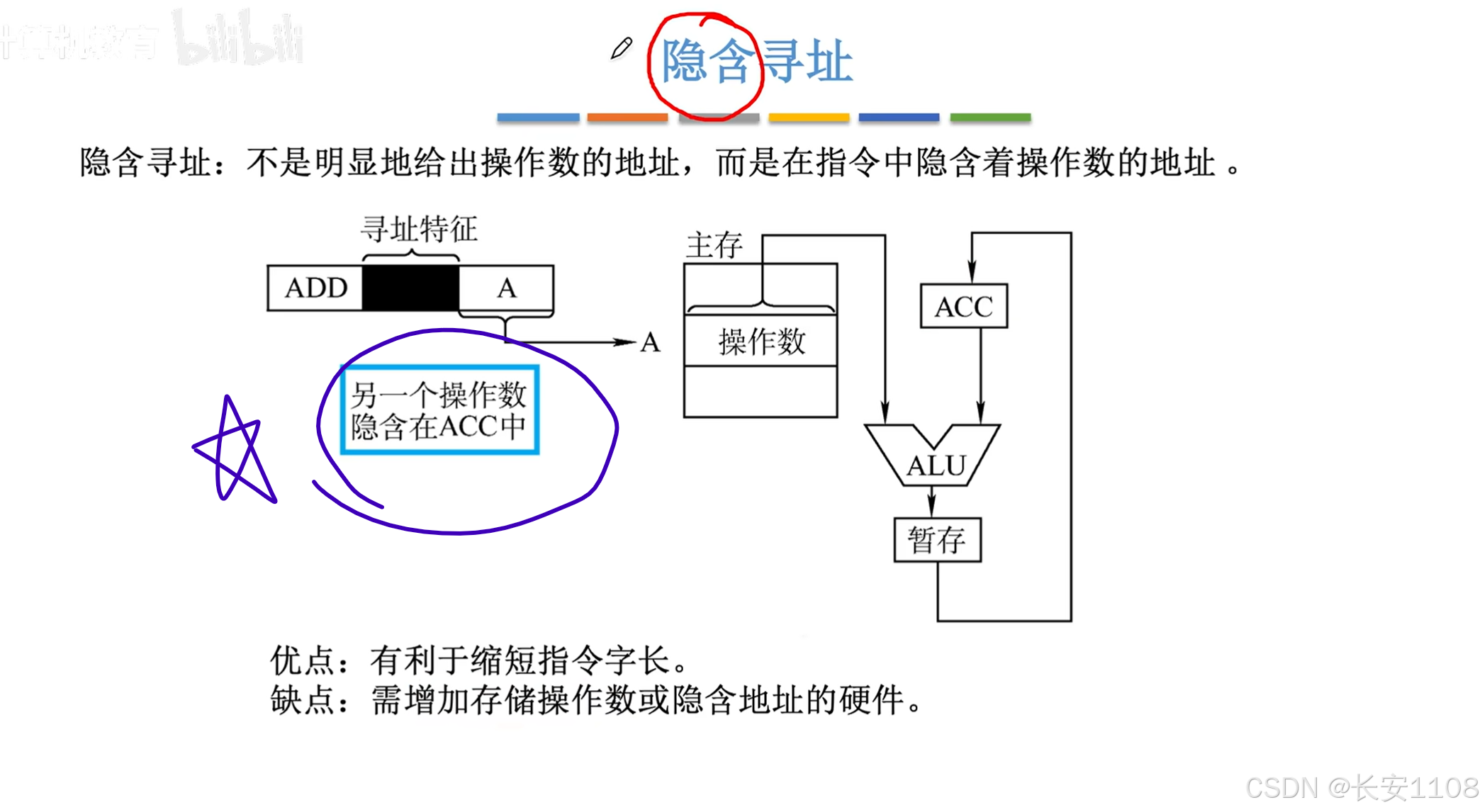
也就是其中一个操作数,有其固定的存放位置
立即数寻址
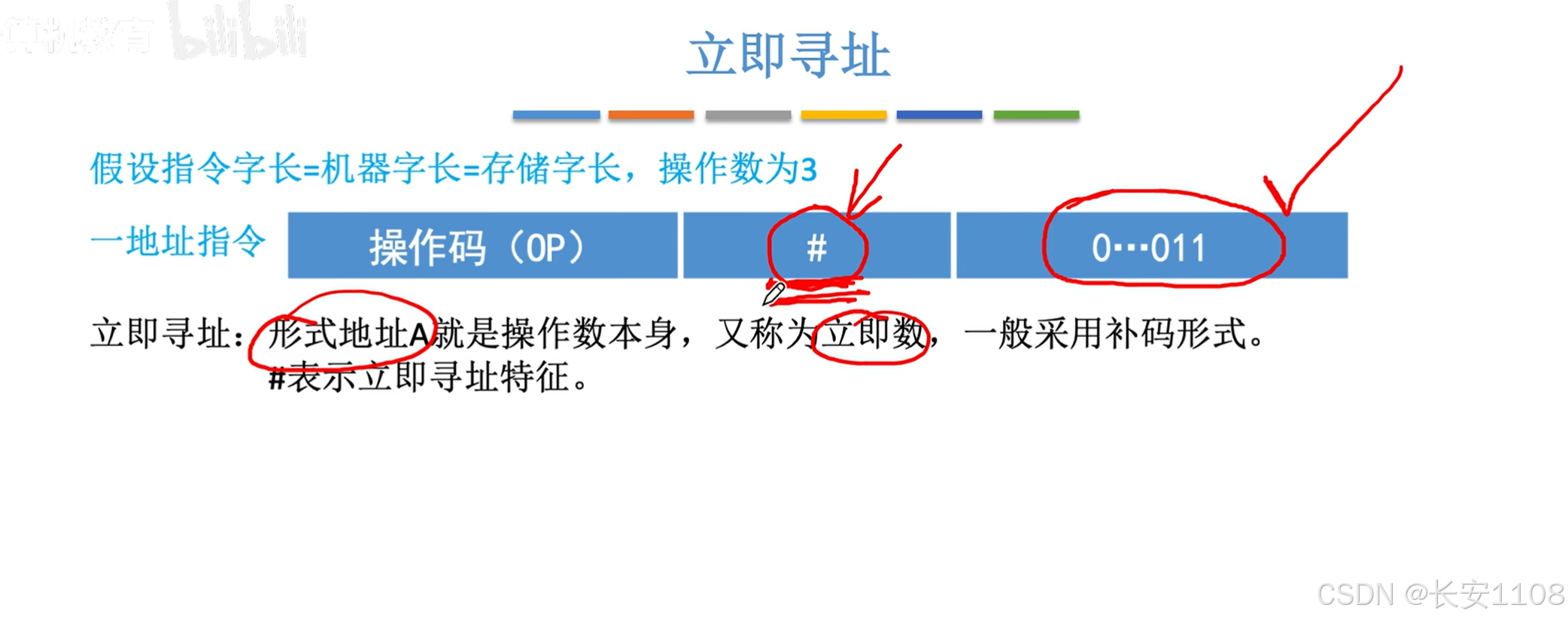
即,地址码就是我们的数据–“3”,一般使用补码形式
其特征用一个“#”号描述
优缺点:

阶段小结
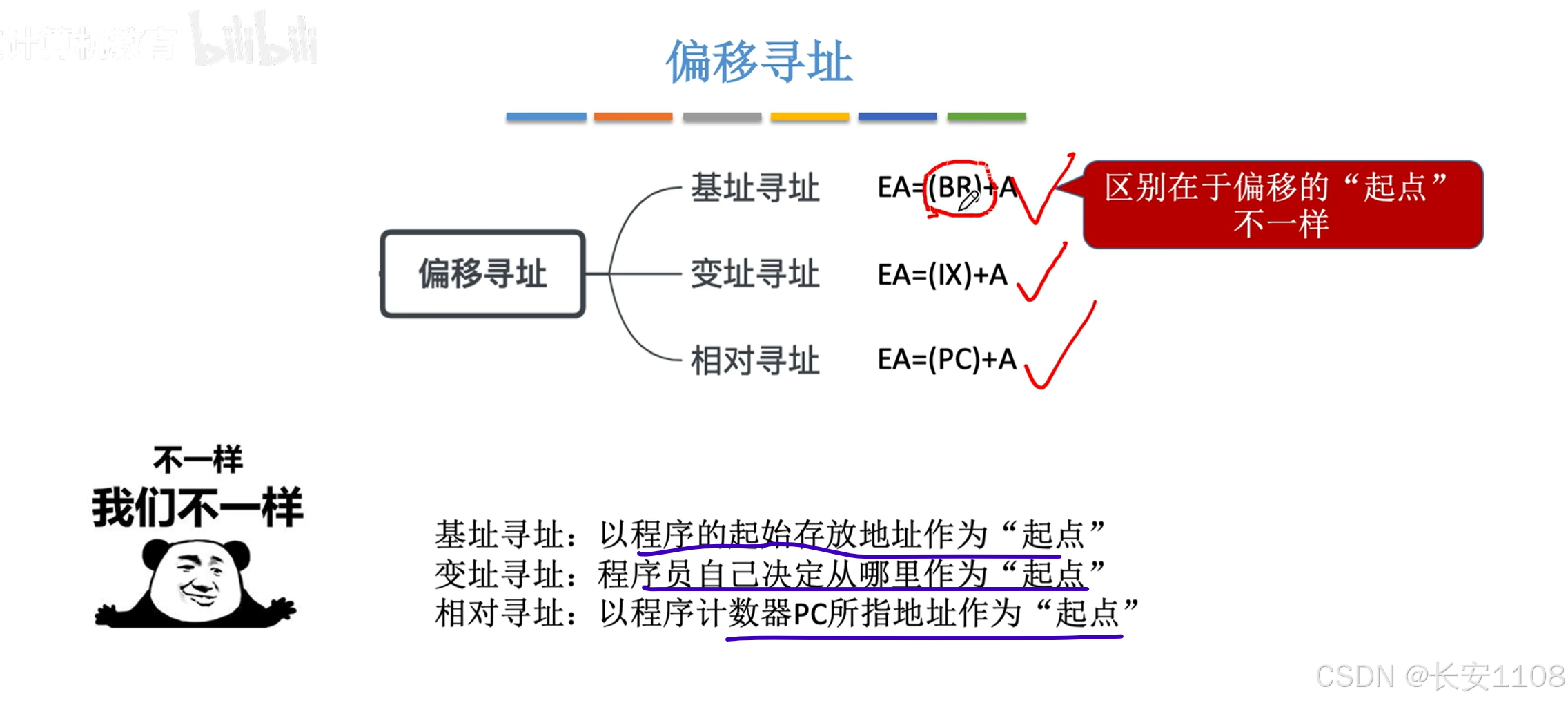
4.2.3 数据寻址–偏移寻址
总览

基址寻址
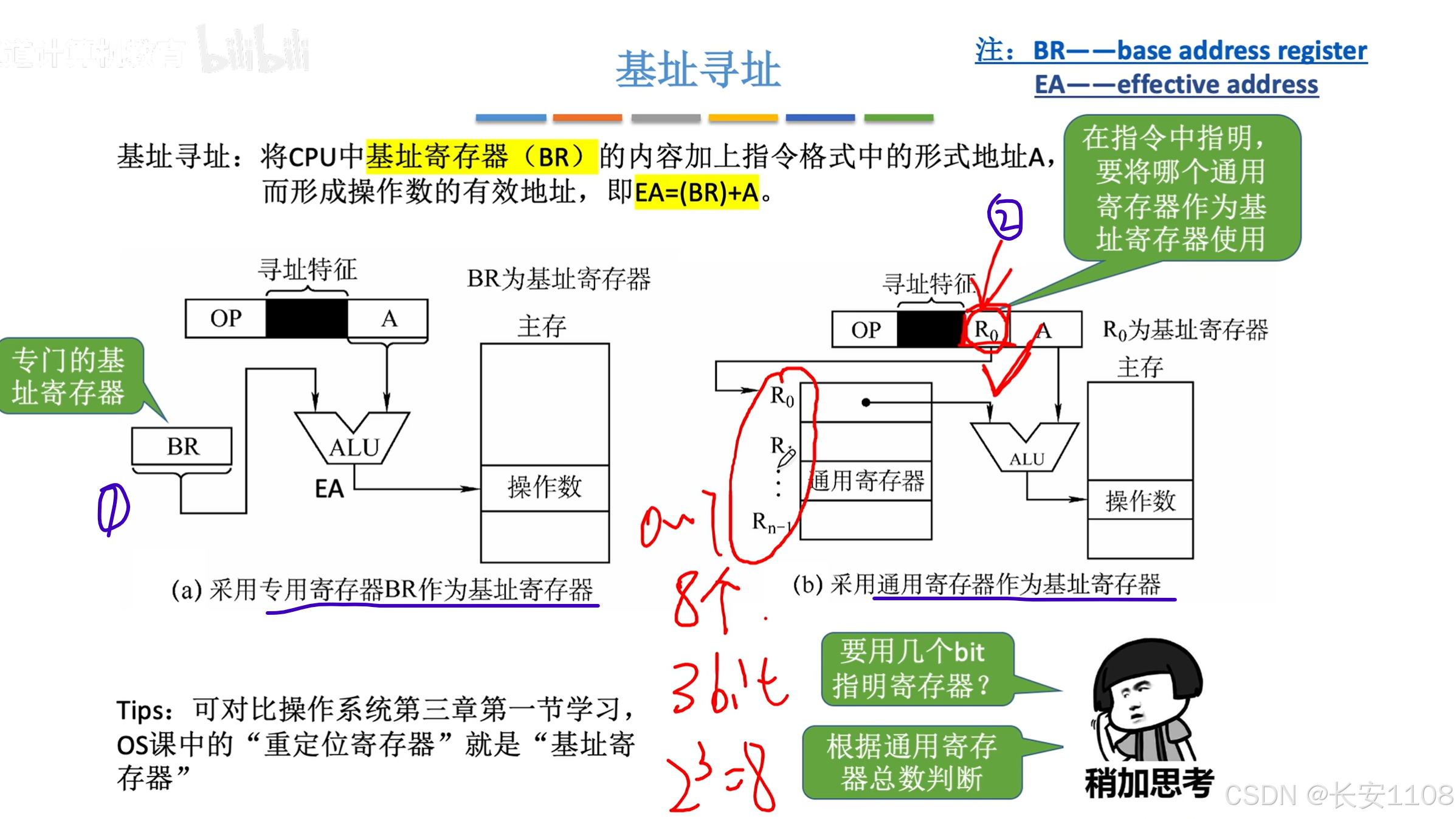
1、有的CPU会有专门的基址寄存器BR,来存放基址(也就是程序的起始地址)
2、也有的CPU会使用通用寄存器来存放基址
首先,寻址特征会变为基址寻址的特征
之后,先指示使用哪个编号的寄存器,具体使用几个bit来指示寄存器的编号,要看寄存器的范围,如果寄存器只有8个,那么3bit就够了
基址寻址,即EA = (BR)+ A
作用:
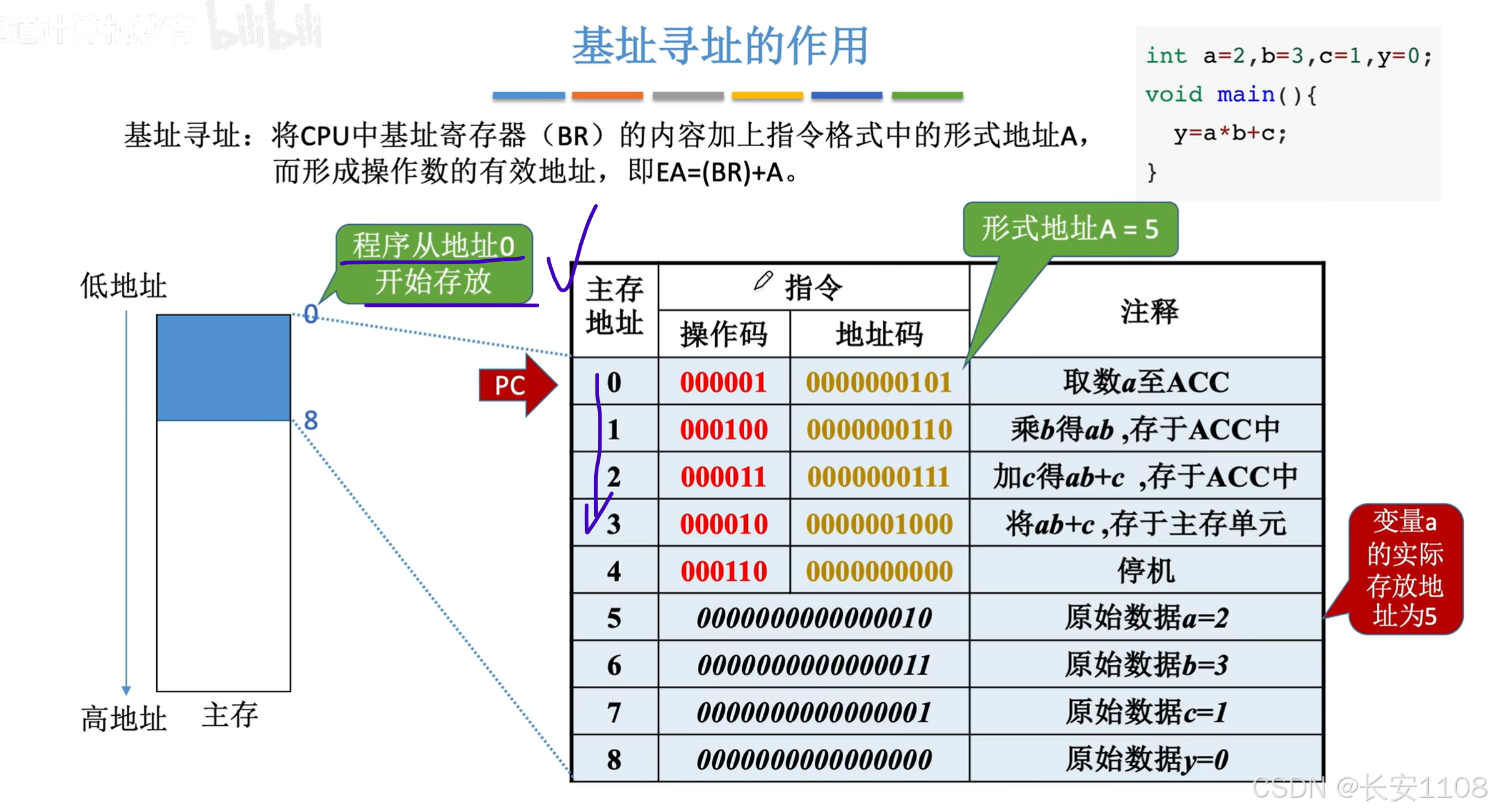
首先,我们知道,第一条指令是直接寻址,找到5号地址,这段代码要是在主存的0号地址开始的话,是符合我们的预期的
但是如果程序代码不是从0号地址开始,而是其他的位置,代码就无法执行了:
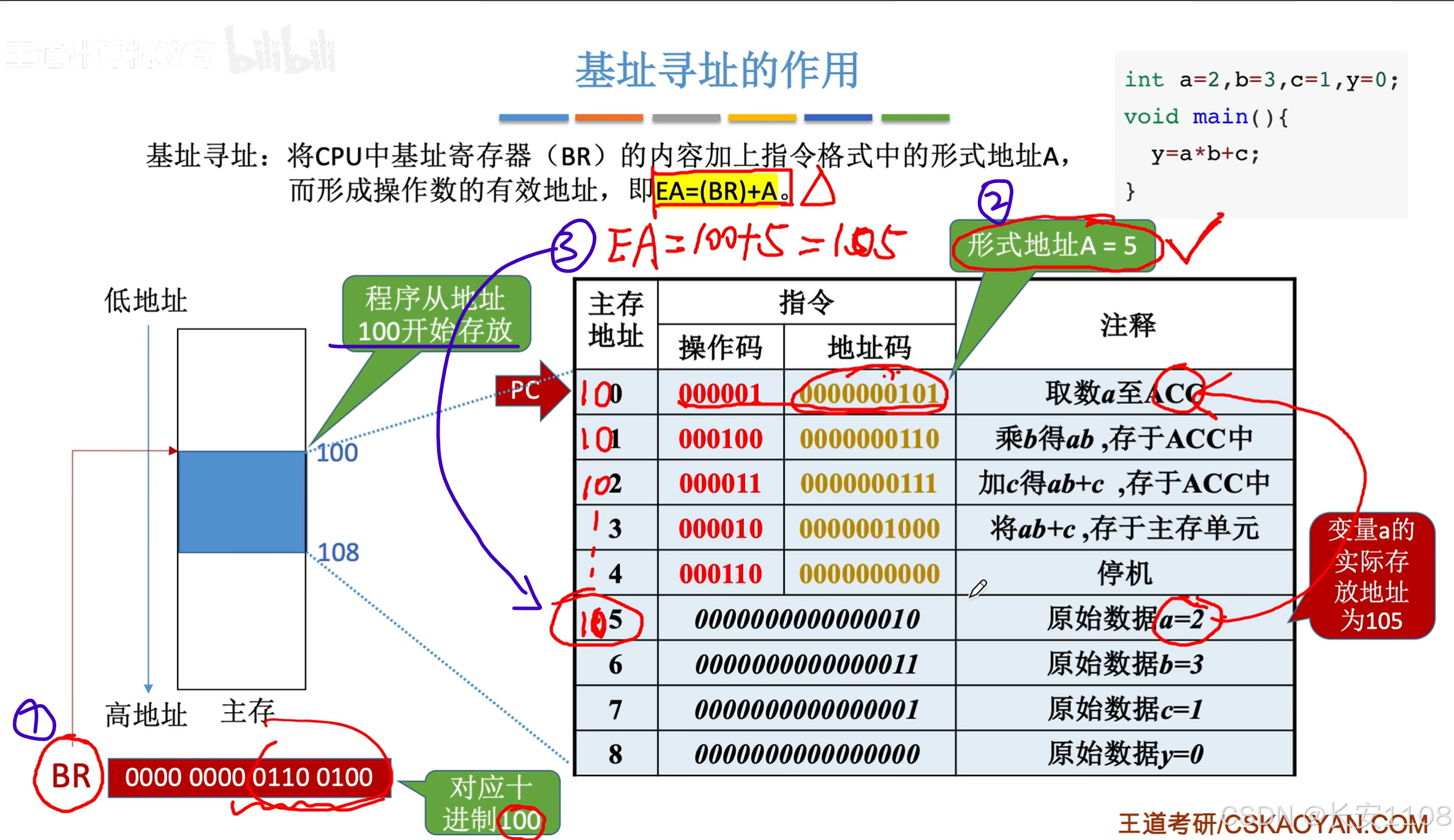
如果还是想正常执行我们的代码,第一条指令的“直接寻址”,改为“基址寻址”
这样,每个地址的偏移量都是以“程序第一条代码所在内存”为基础的,这样的话,无论程序是不是从0开始,都无关紧要了
如上图,1、基址寄存器存程序第一条指令的地址,为100
2、形式地址(偏移量)是5
3、所以,最终的有效地址EA = (BR) + A,也就是105,符合我们预期

注意:
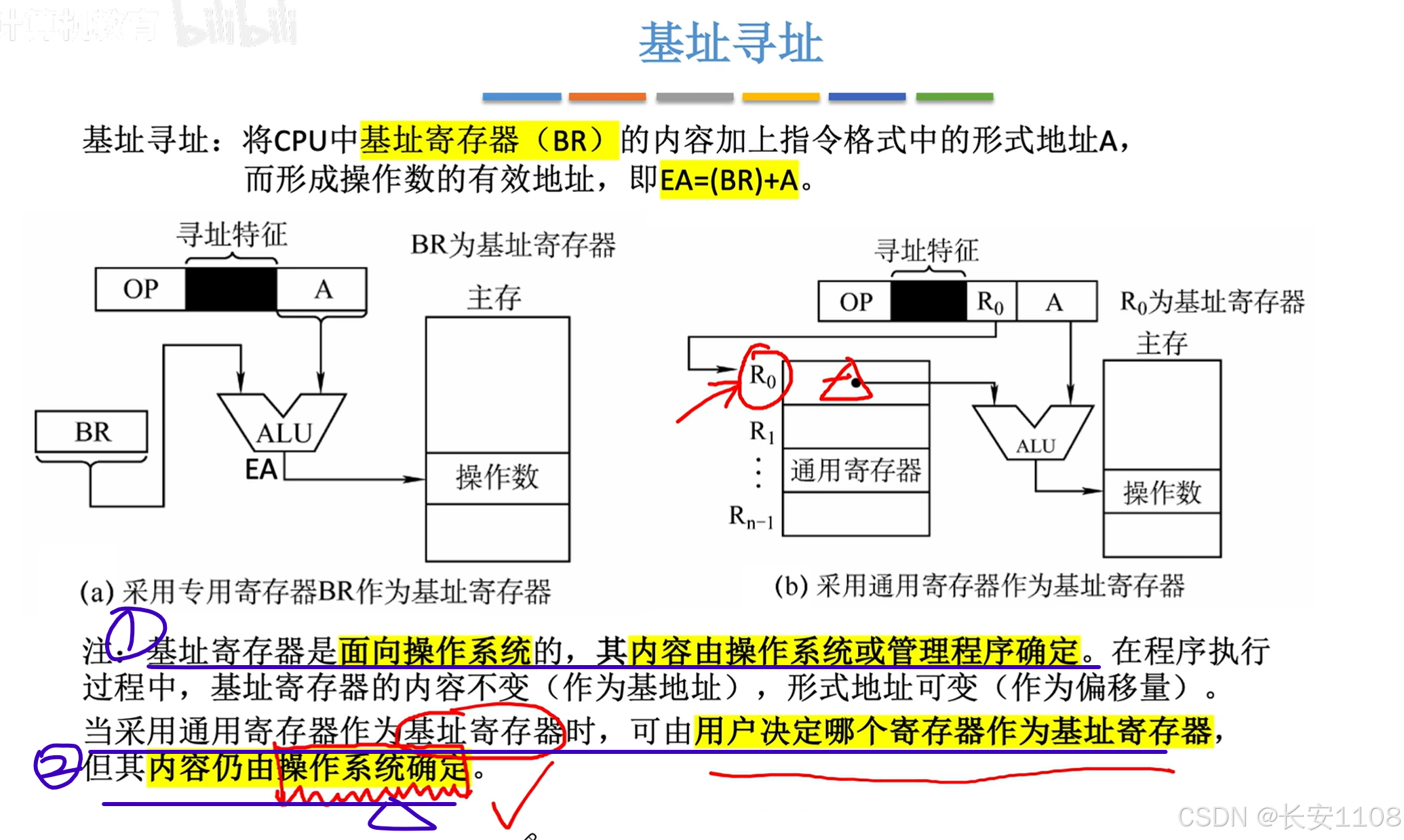
BR的内容是由操作系统来管理的,程序员无法修改
而且,哪怕使用通用寄存器充当BR,其“寻址特征”改为“基址寻址”后,对应的通用寄存器的内容我们通用无法修改,还是由操作系统管理
优点:
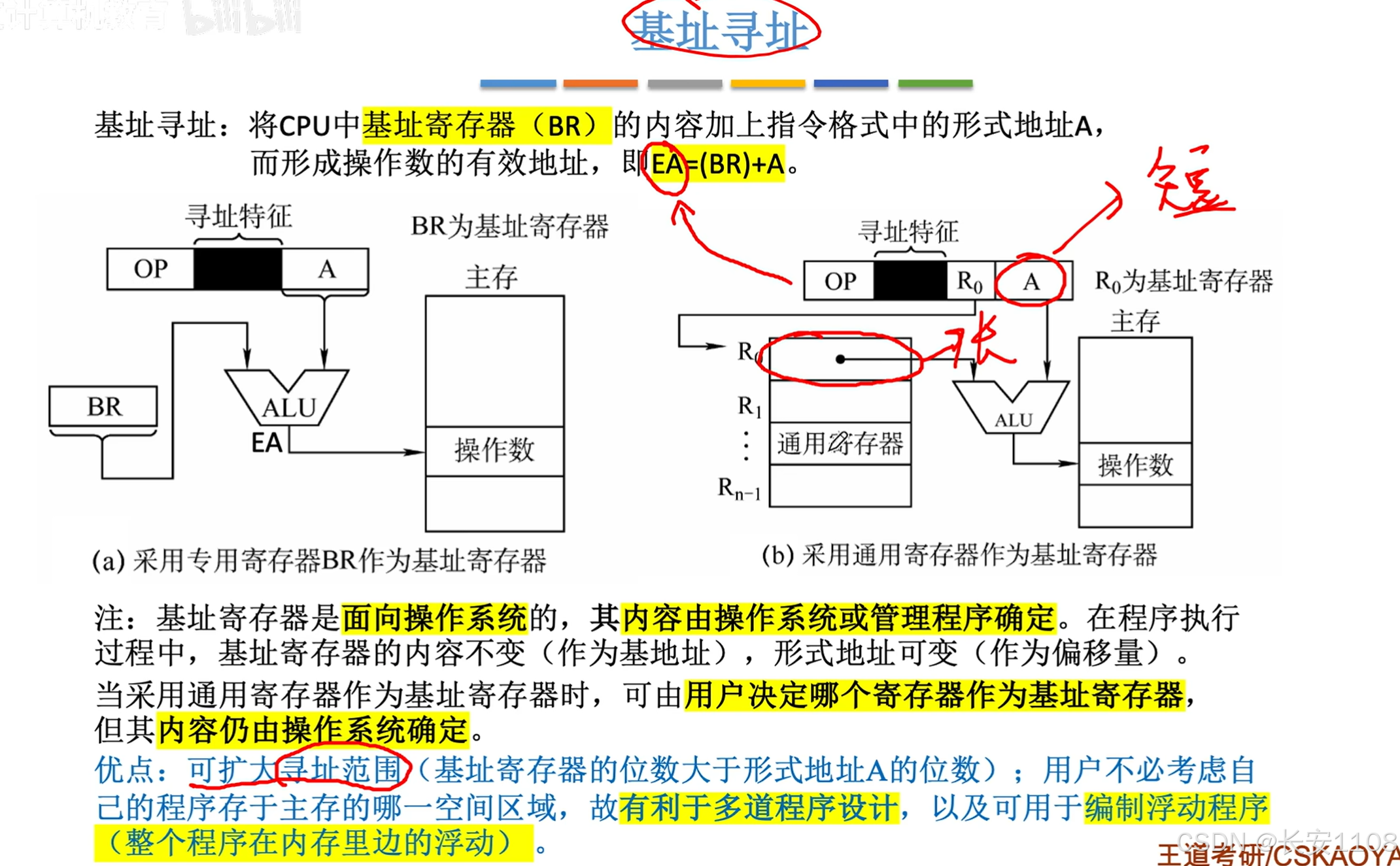
变址寻址
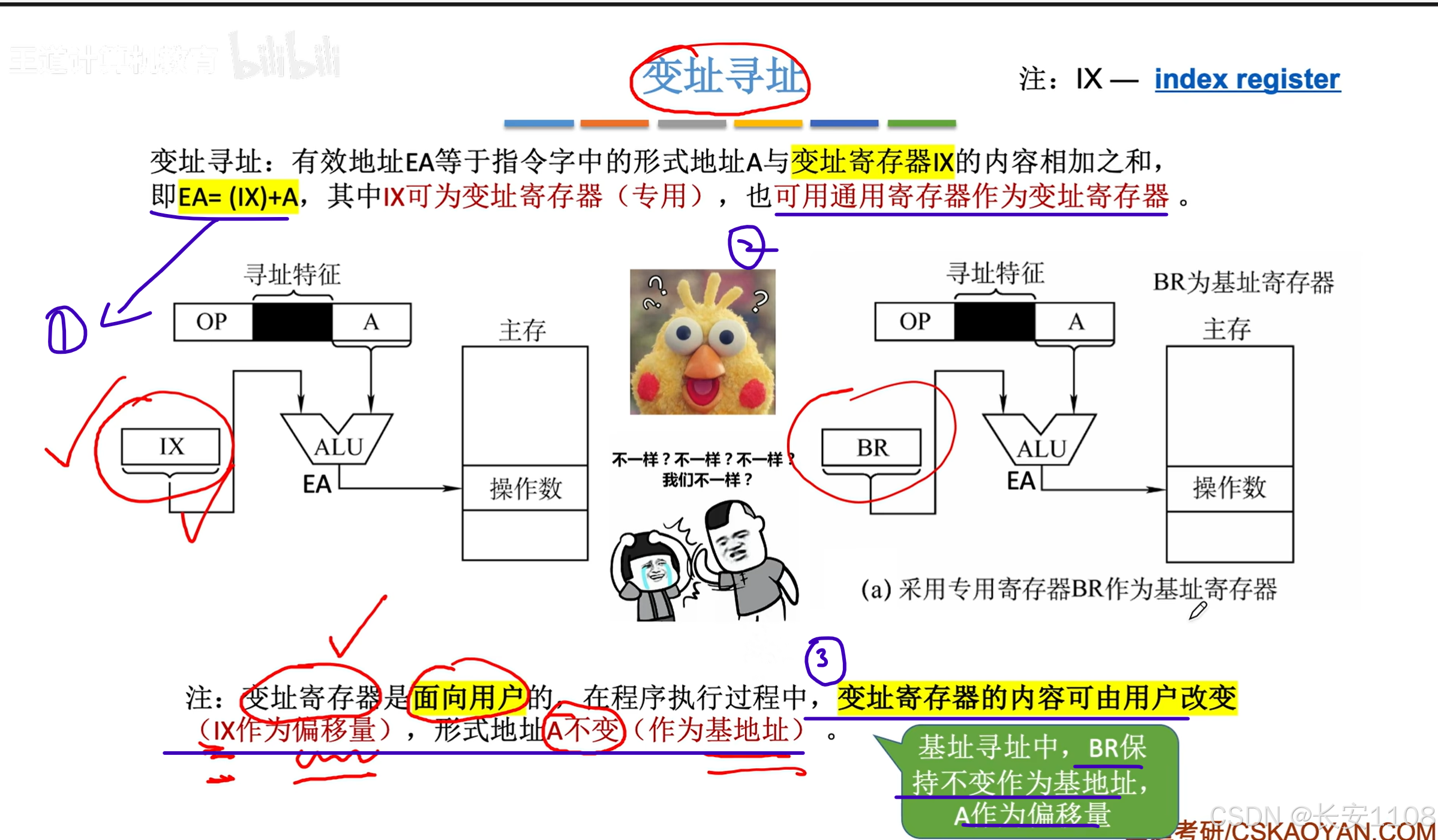
1、变址寻址,与基址寻址类似的是,变址寻址用的是IX寄存器的内容,这个也是一个专门的寄存器
2、同样的,变址寻址也可以使用通用寄存器来作为变址寄存器
3、变址寄存器在程序运行过程中,其寄存器的内容可以由用户改变,基于这种特性,一般变址寄存器IX存放偏移量,而形式地址A作为基地址(这一点与BR相反)
作用:
首先来看:
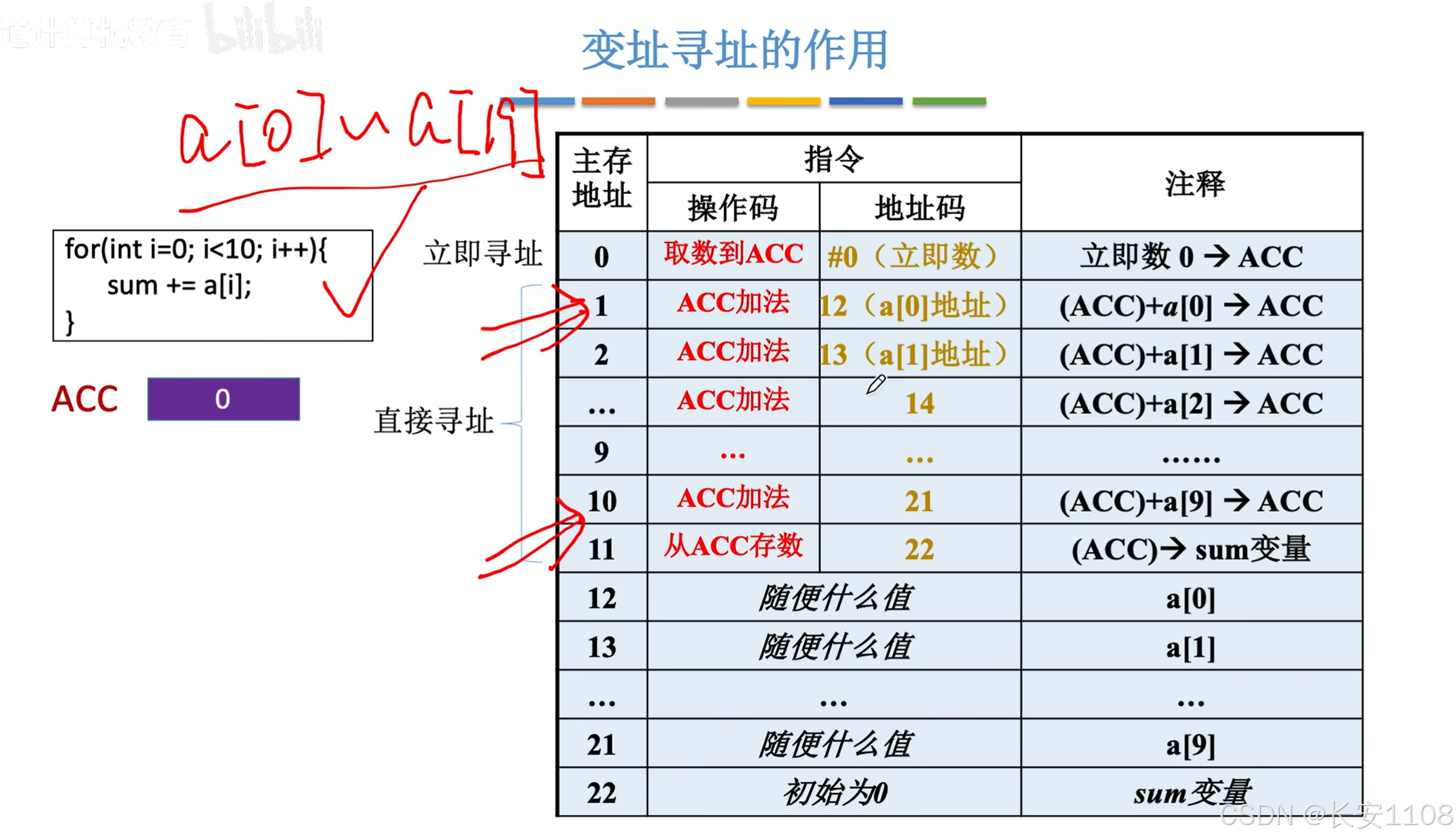
我们使用大量的“直接寻址”,实现0 ~ 19元素的累加
我们此次暂时不考虑程序代码的起始位置,我们先认为其就是在0号地址
我们主要关注的是:如果我们想要计算0到 100、10000、甚至更多的累加时,我们要给每一个元素都写一个ACC加法指令,我们就要写100000条指令,所以,十分的不灵活
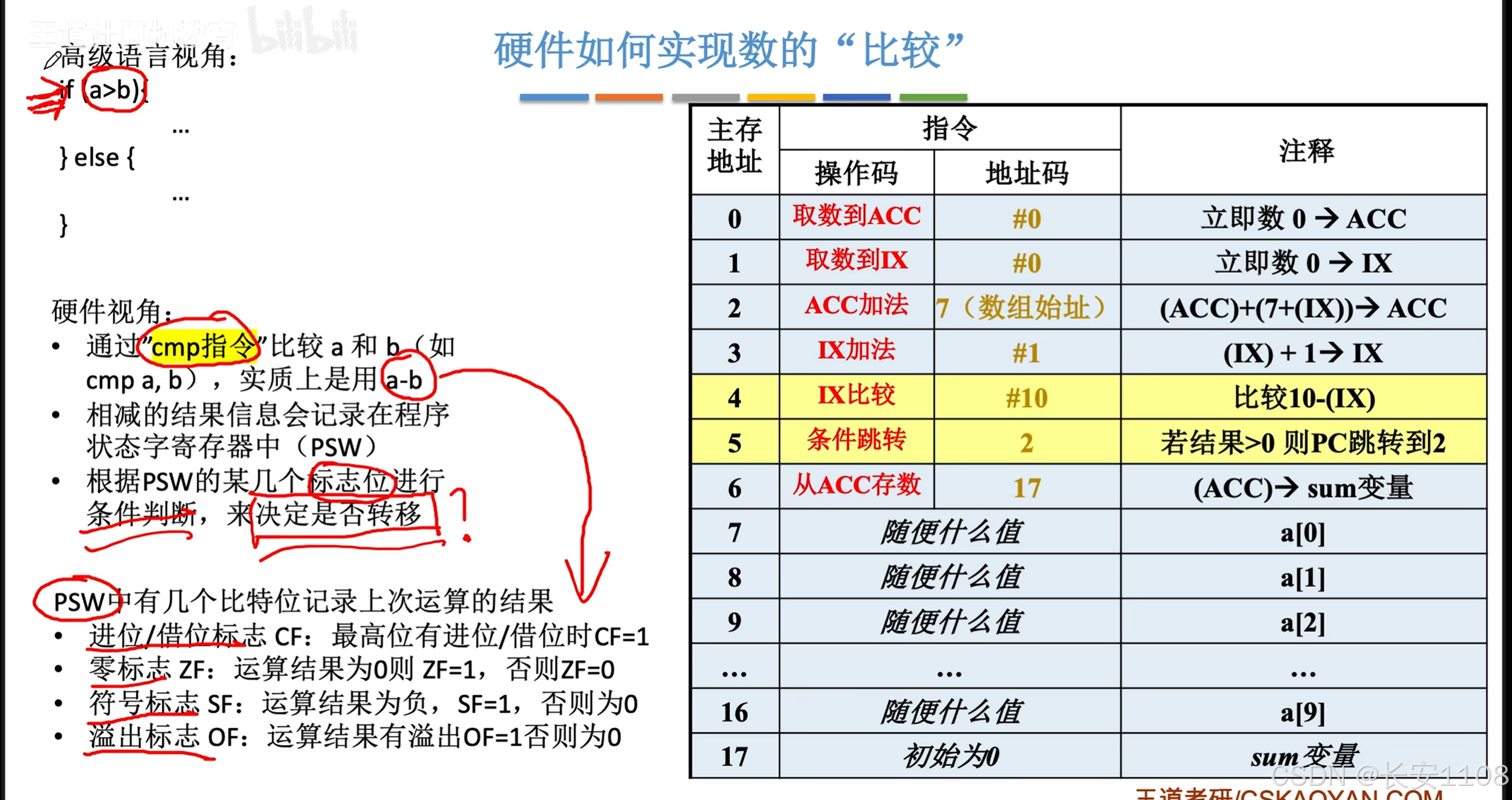
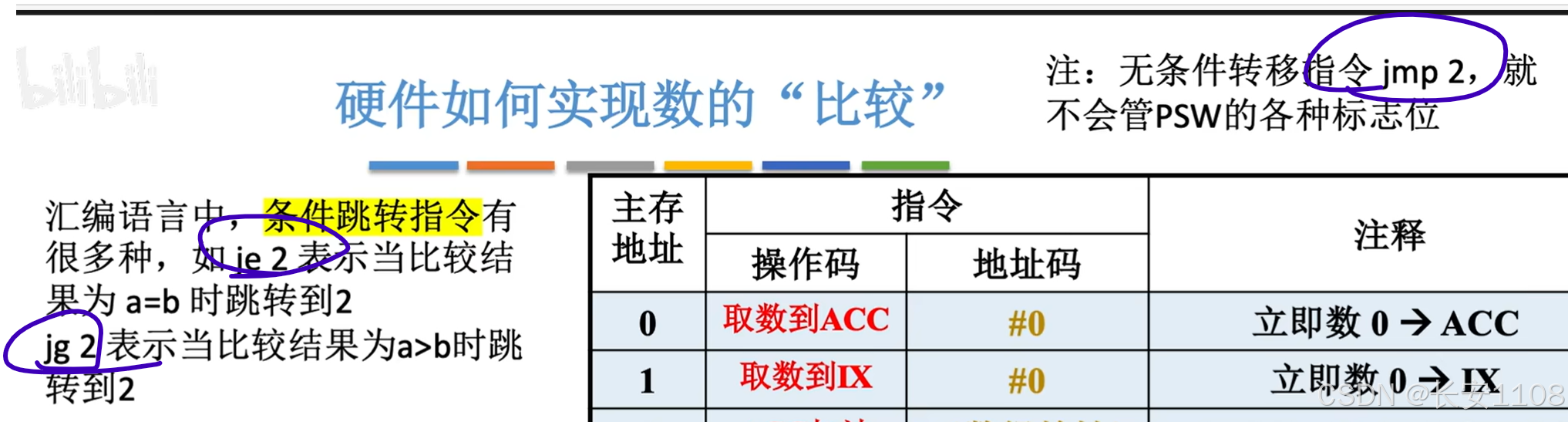
采用变址寻址来优化:
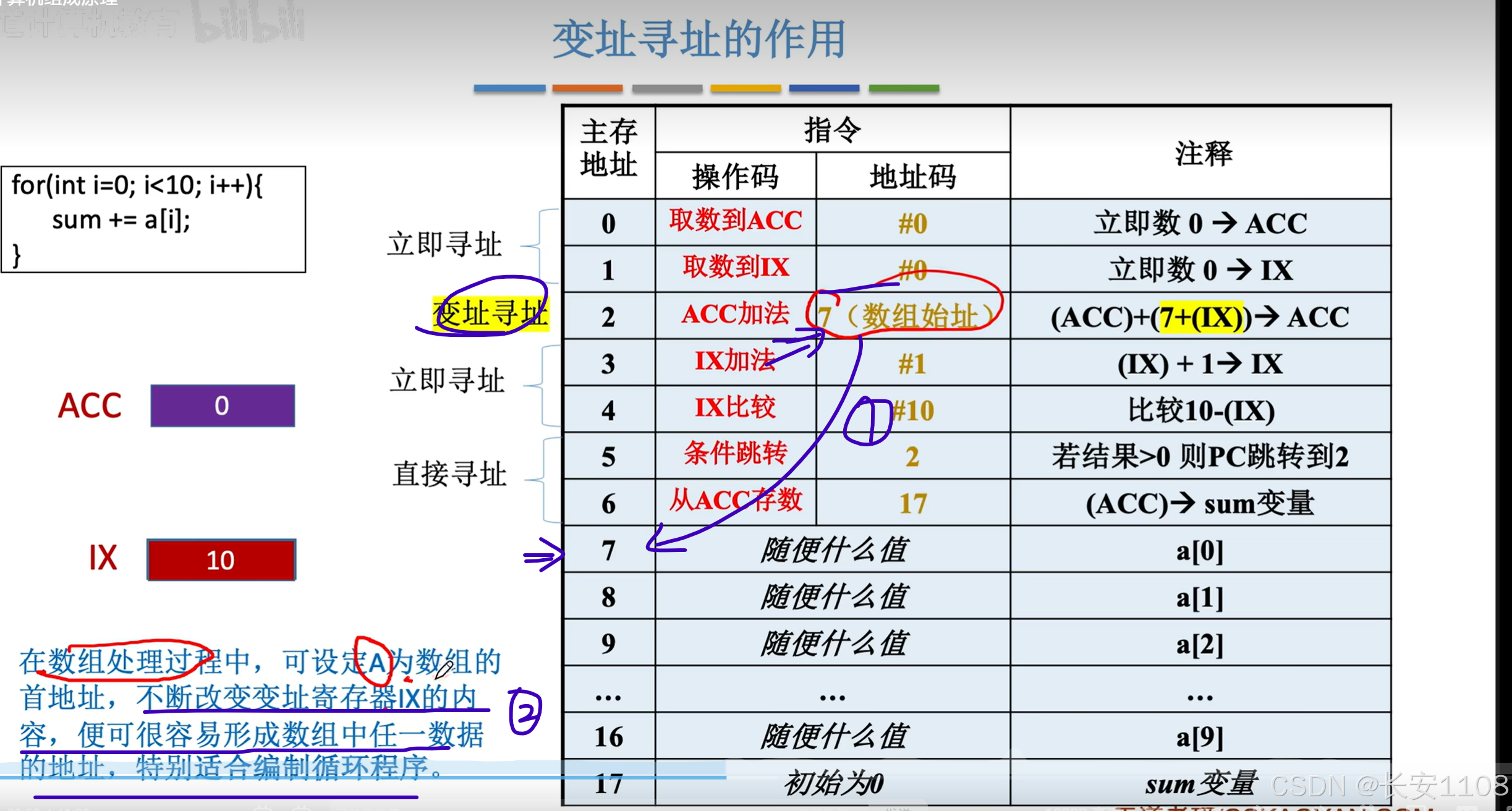
首先,将所有的数据都放到程序代码段的下面,这样方便进行数据的拓展,不会影响代码
1、我们使用变址寻址,来处理累加的过程,
ACC加法,后面是7,7是数据区,或者说一个数组的首地址
2、之后,IX从0开始不断自增,从而使得EA从7开始,不断累加,从而实现遍历数组的操作
(最后使用比较指令进行跳转以及跳出)
优点:

基址变址复合
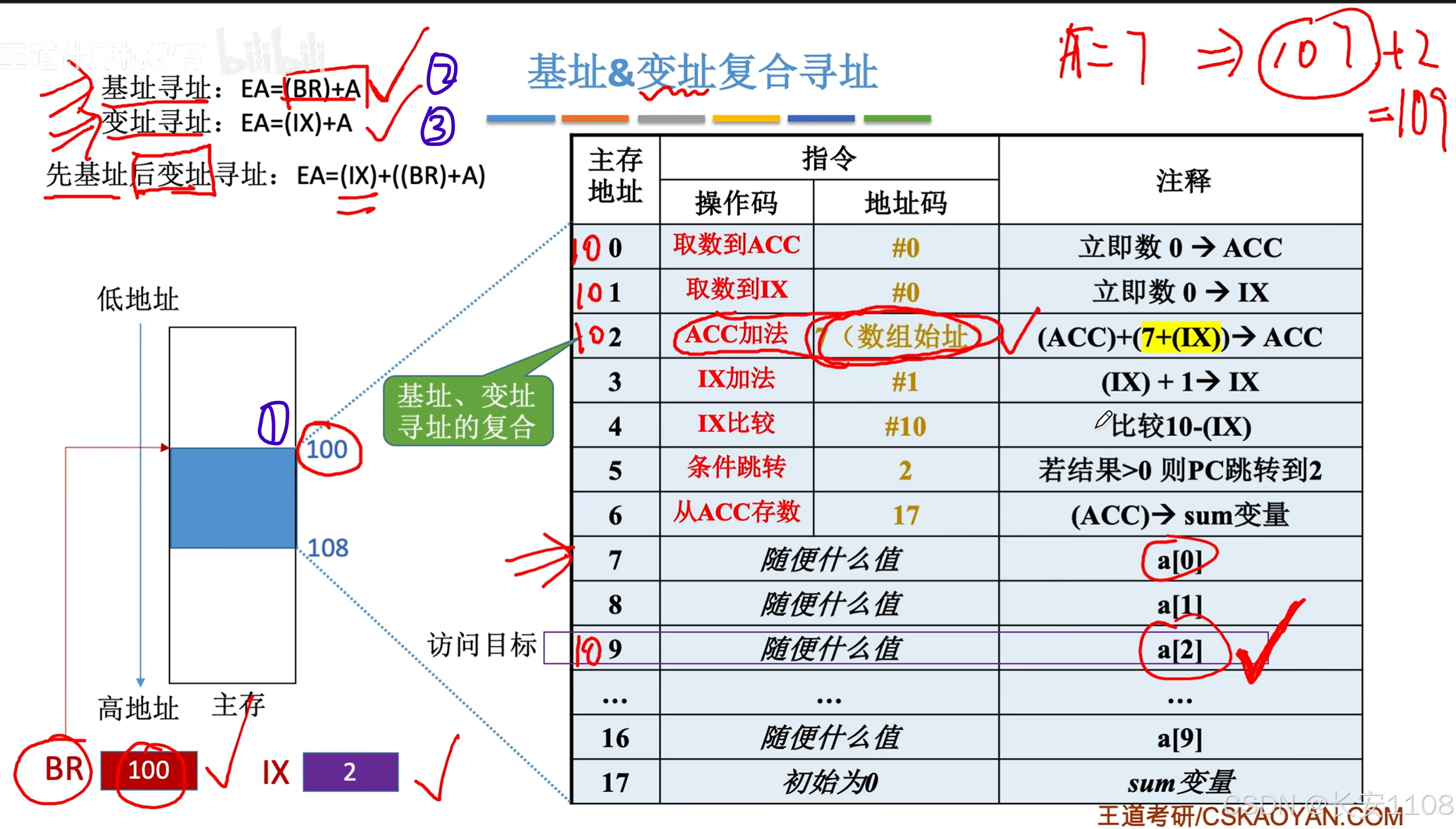
前面我们在探讨时,暂时避开了“程序的首代码”的位置问题,我们默认其就存放在0号地址开始
现在,我们来解决这个问题,
2、 即先使用“基址寻址”,拿到根据程序首代码地址获取到的数组首地址的真实地址
3、然后再去使用IX变址寻址就好了
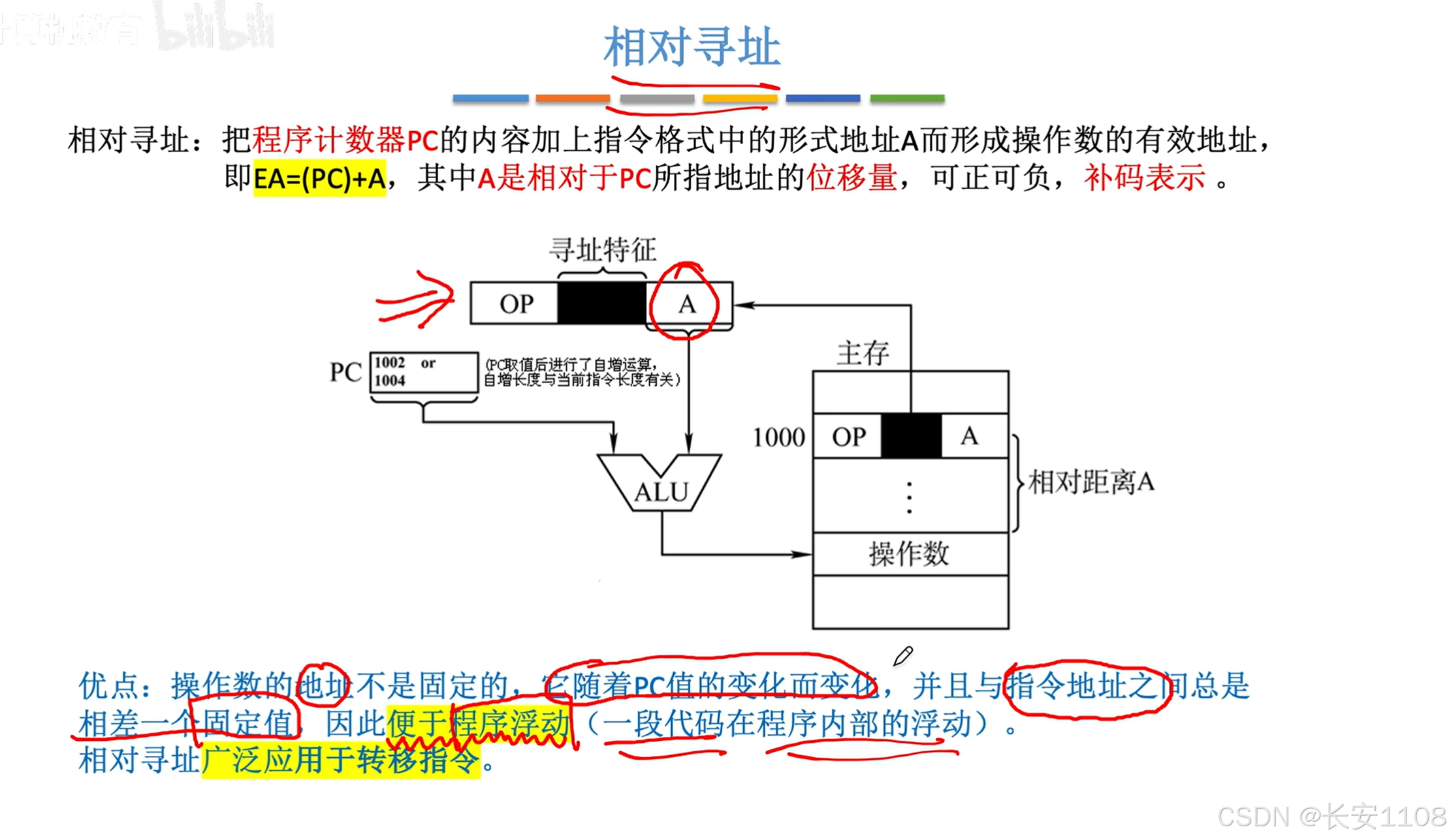
相对寻址
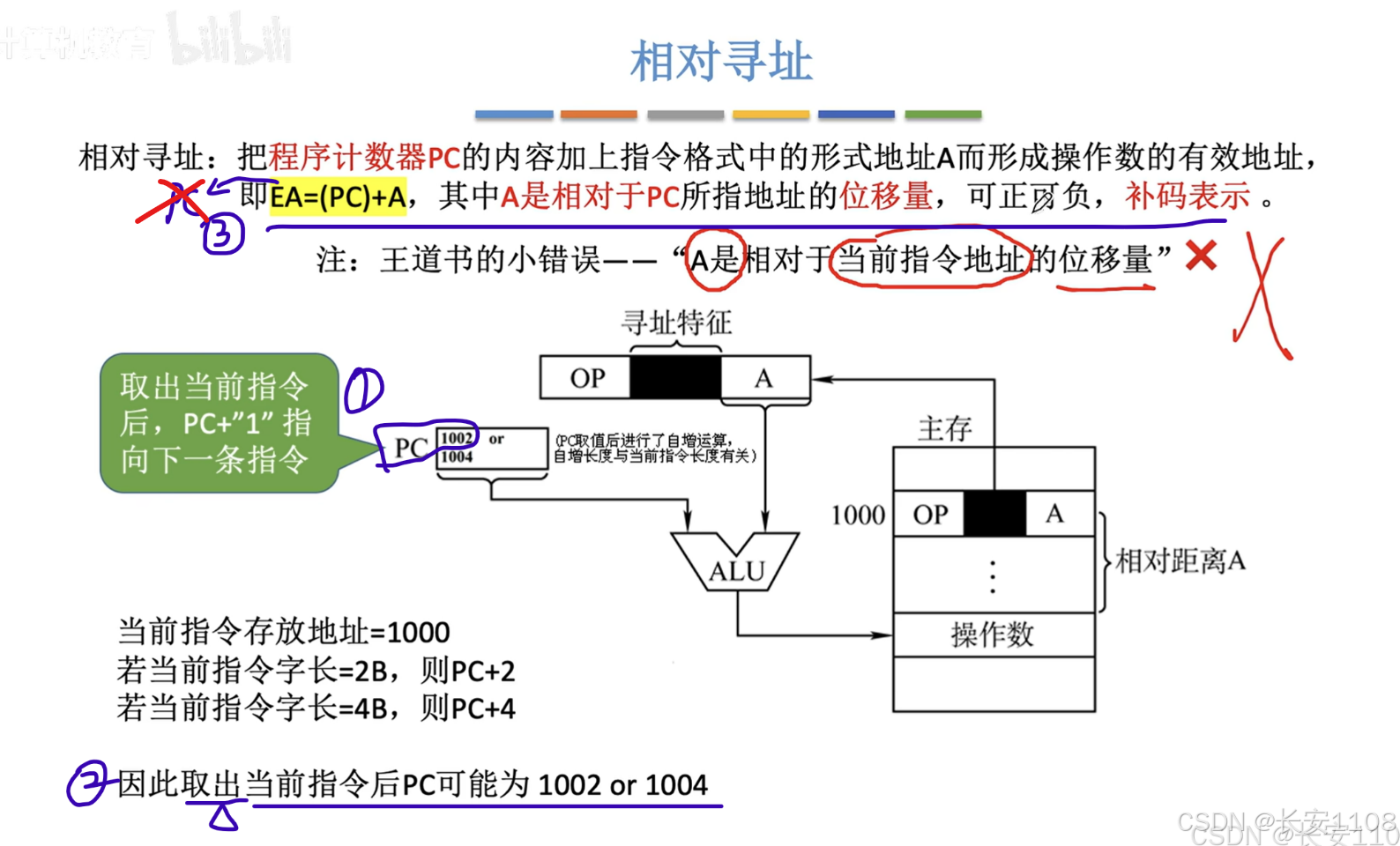
1、PC一定会先执行“自增”来移向下一条指令,具体自增多少,取决于指令的长度
2、其PC移动,是在“取出指令”就移动了
3、而取出指令后,就要执行指令了,在执行指令时,如果该指令是相对寻址,那么就是将(pc)+ A,A可以是正也可以是负,通常使用补码表示,注意,相对寻址只是以PC为基础,并不会去修改PC,更不会将(PC)+A的结果赋值回PC,这些都是其他指令的操作,这里仅仅是根据当前PC的位置,进行偏移,最后拿到的是一个EA
作用:
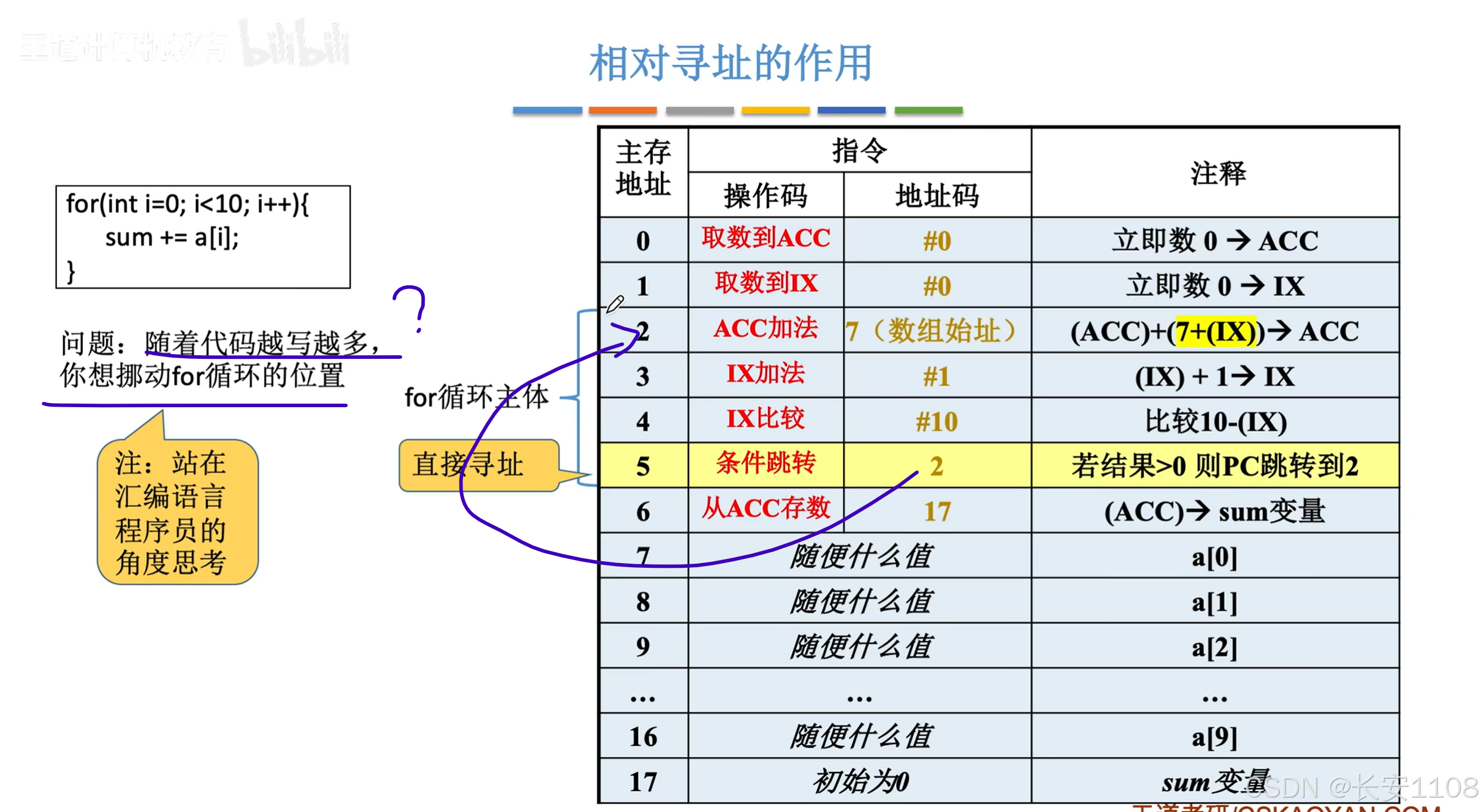
假如说,我们想要挪动一个for循环的位置,让其放在程序代码段靠后的位置
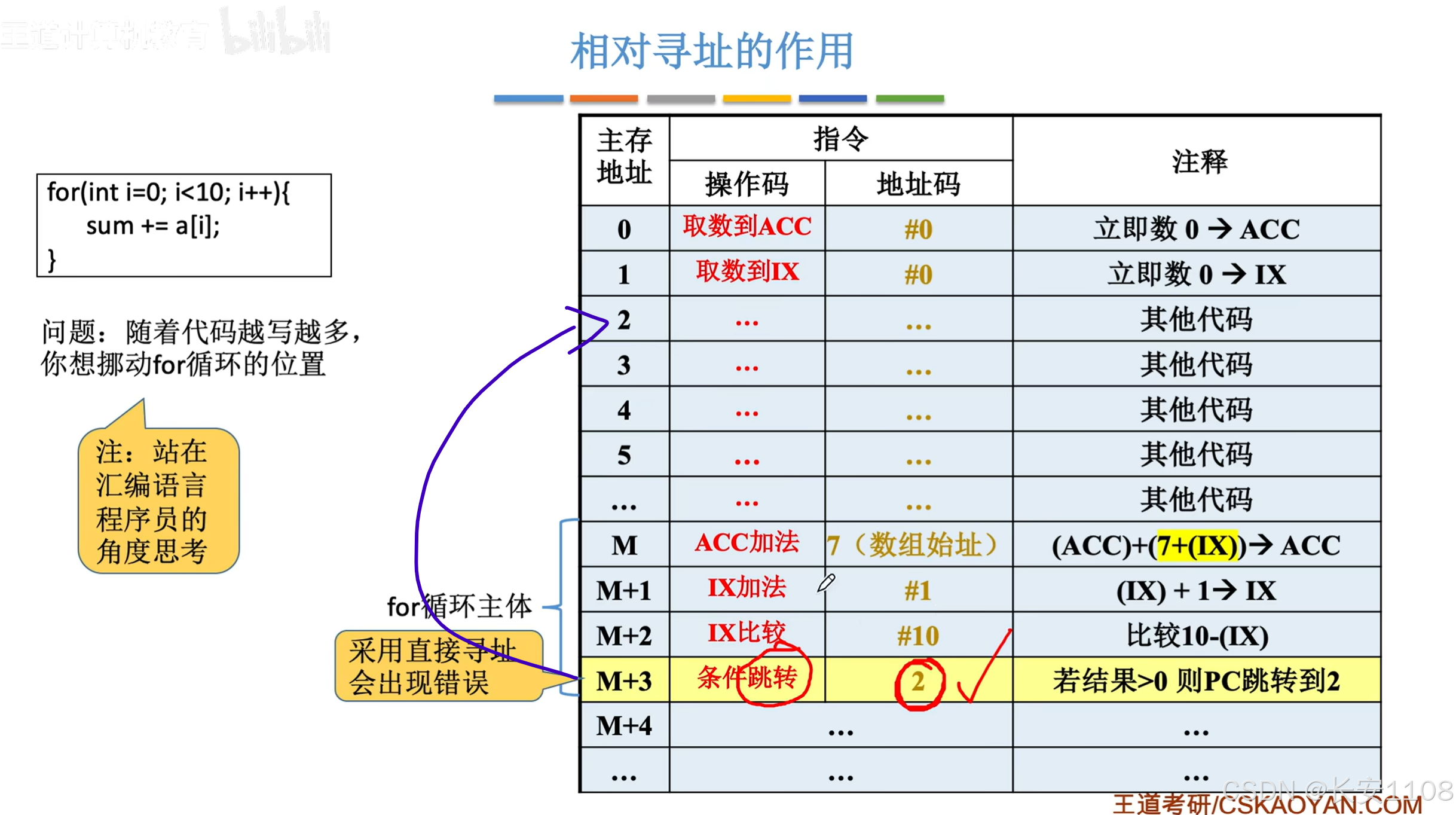
这样,如果还是采用相对寻址,其会跳转到的代码,不是我们预期的结果,我们想让其跳转至M
采用相对寻址:
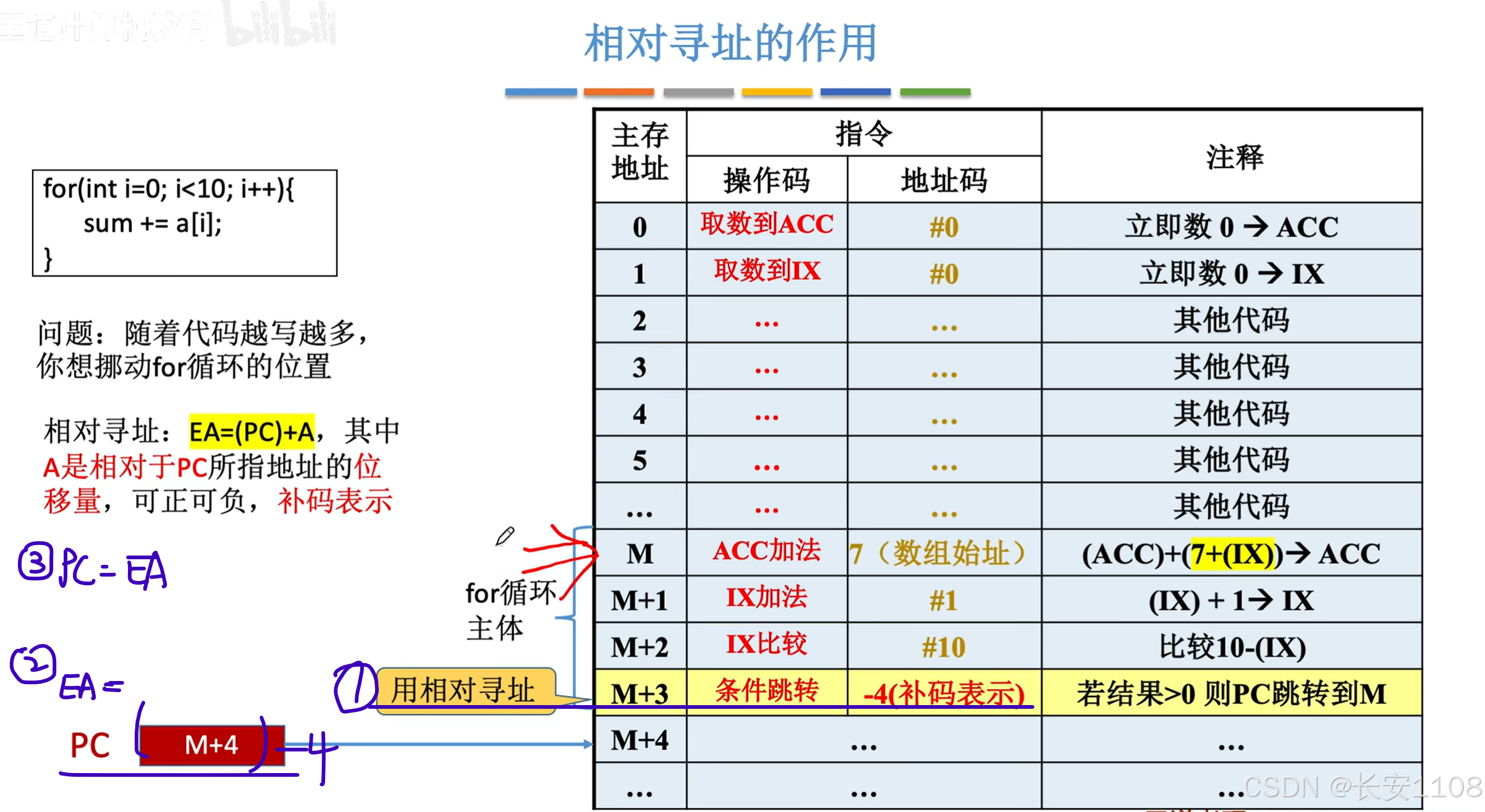
1、我们修改跳转语句寻址方式,我们改为“相对寻址”(需要加入一些寻址特征的二进制来说明),操作数为-4
2、PC此时在M+4,此时我们通过相对寻址,计算EA = (PC)- 4,即(EA) = M;
3、而将EA的数据给到PC,并不是相对寻址的作用,而是因为它是“跳转指令”,其EA会被赋值给PC
优点:
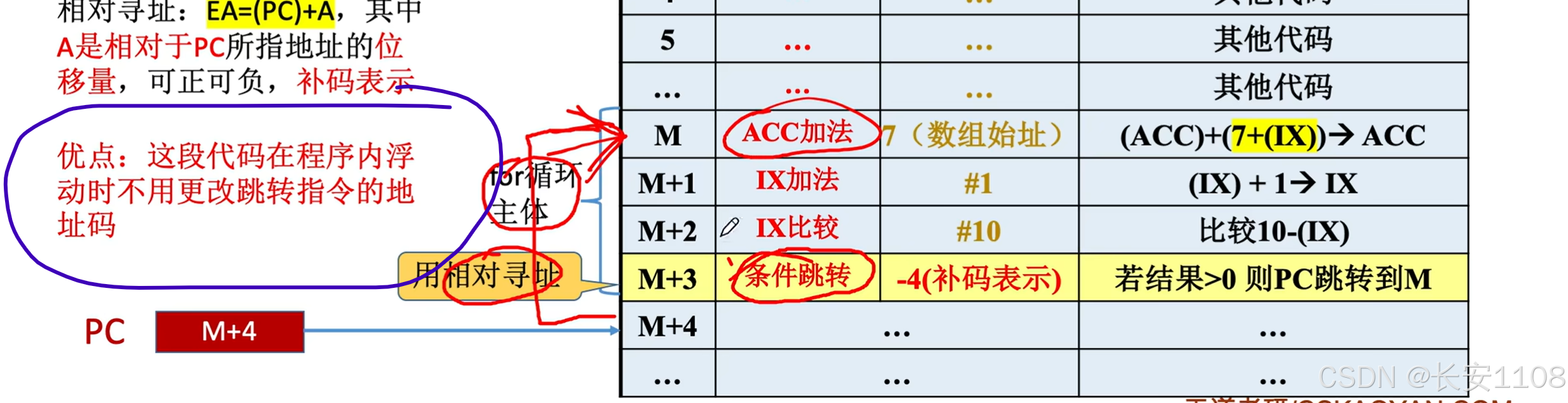
方便“某段代码”在“整体代码”内部进行浮动
拓展:
当然了,这段代码移动了,其之前设置的“数组首地址”的偏移地址也要修改,所以:

总结:
PS:基址寻址:指的是整个程序代码在主存中浮动
这里的相对寻址:指的是“部分代码”在“整个代码”中浮动
总结
补充:
更多信息可以参考“微机原理”
4.2.4 数据寻址–堆栈寻址
总览
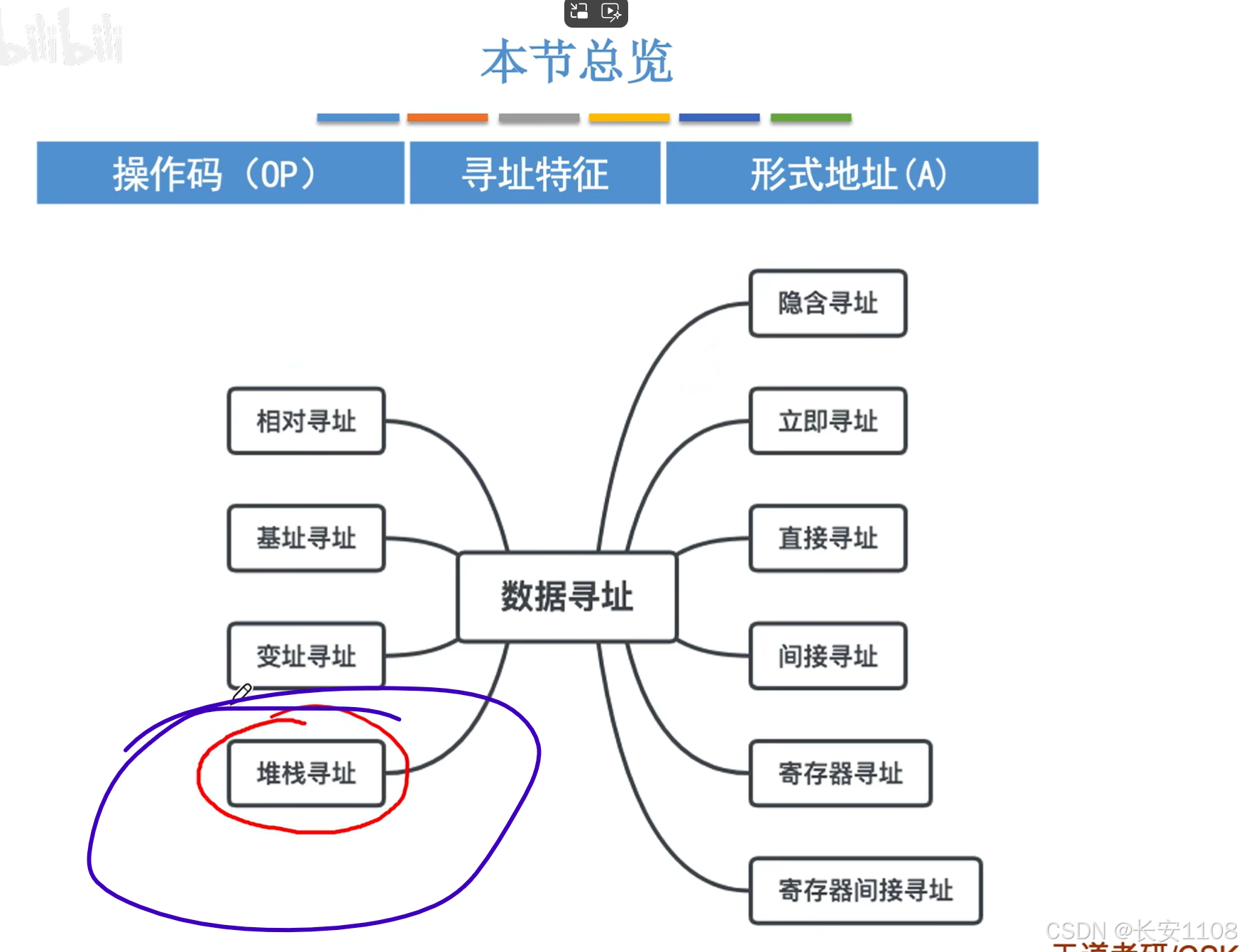
简介
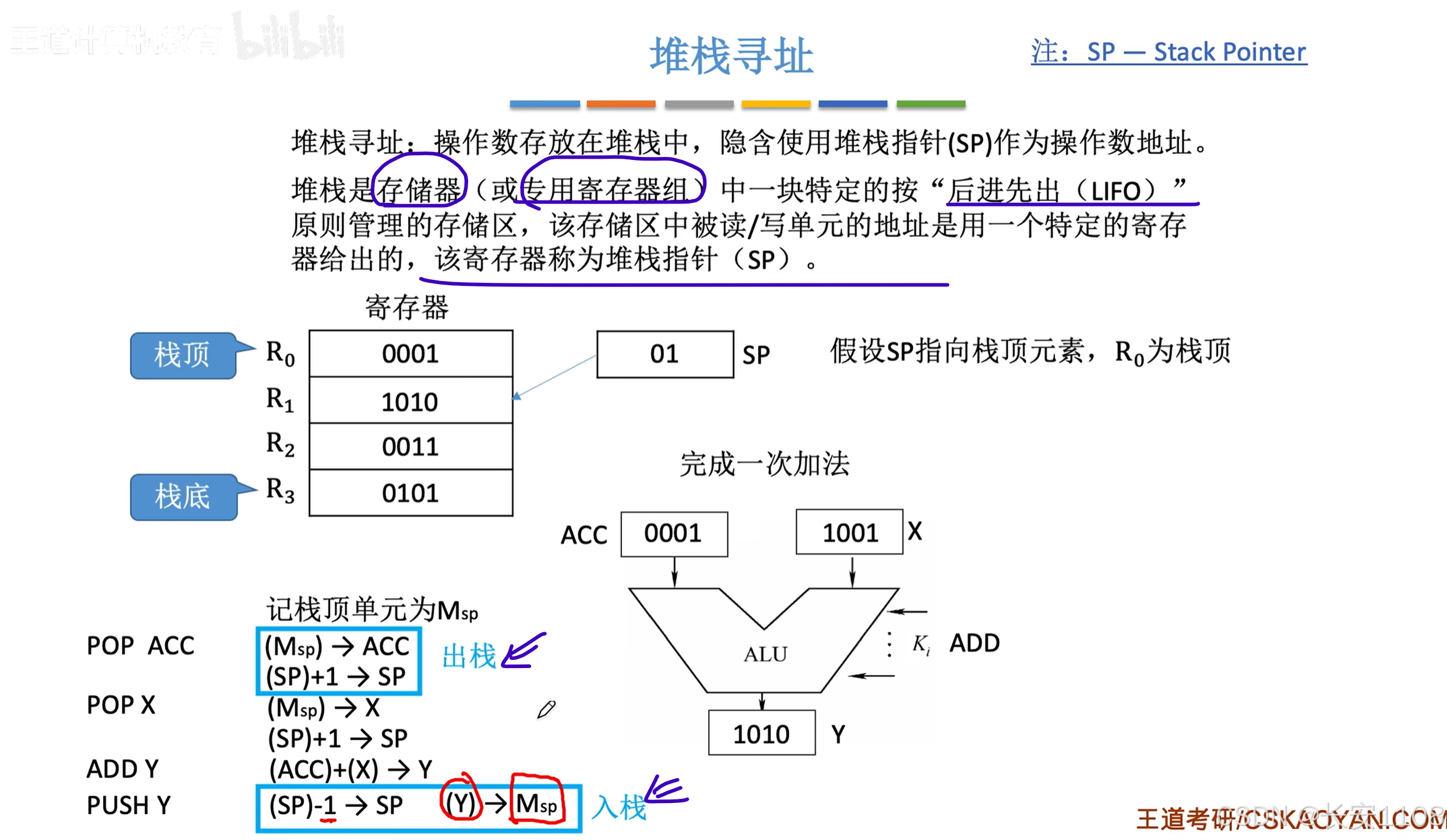

注意
栈操作,入栈时,是只拷贝,从栈外面拷贝值入栈,也就是那个提供源数据的位置的数据不会丢失
且,SP的移动,是硬件自动完成的
总结
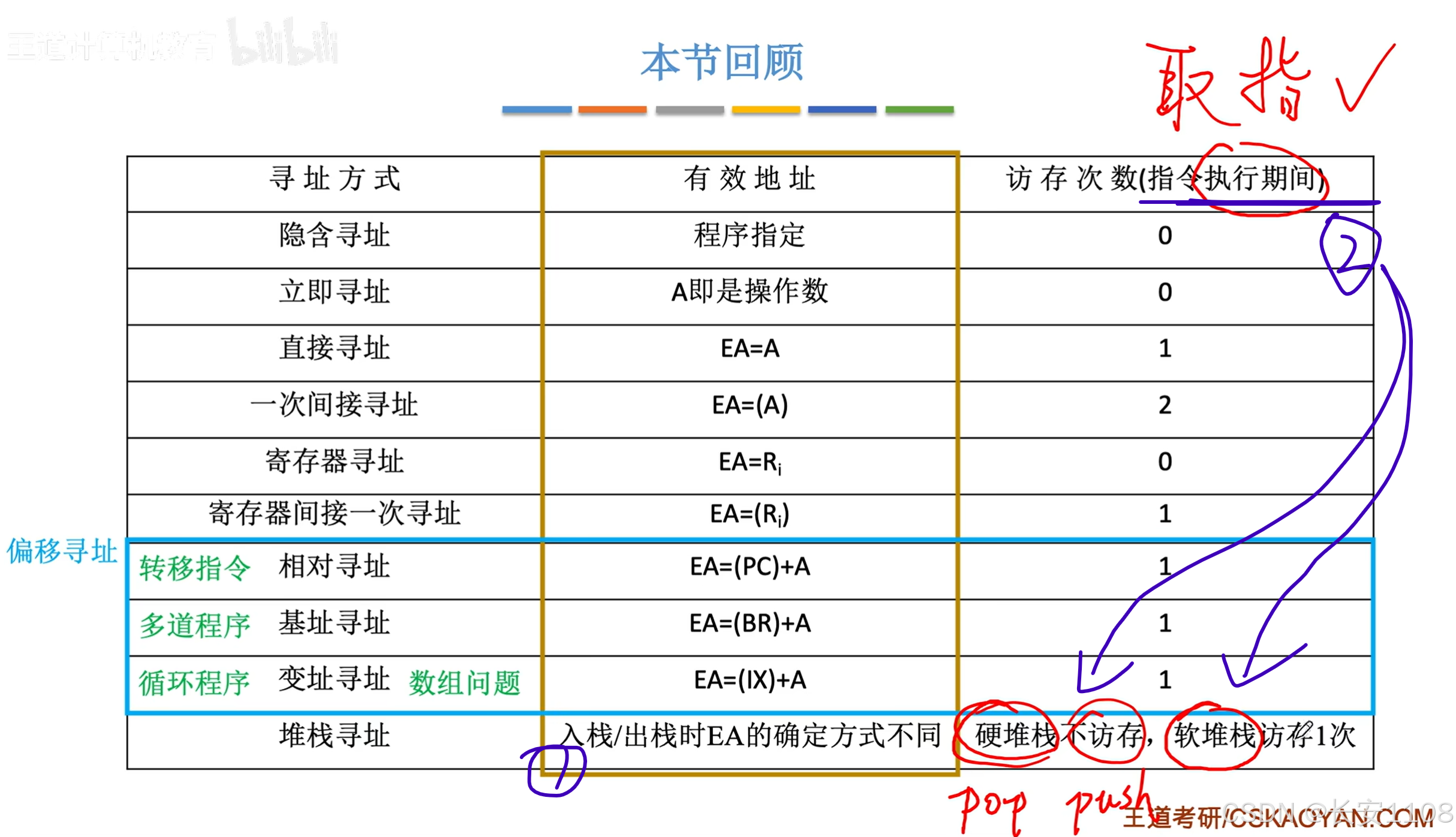
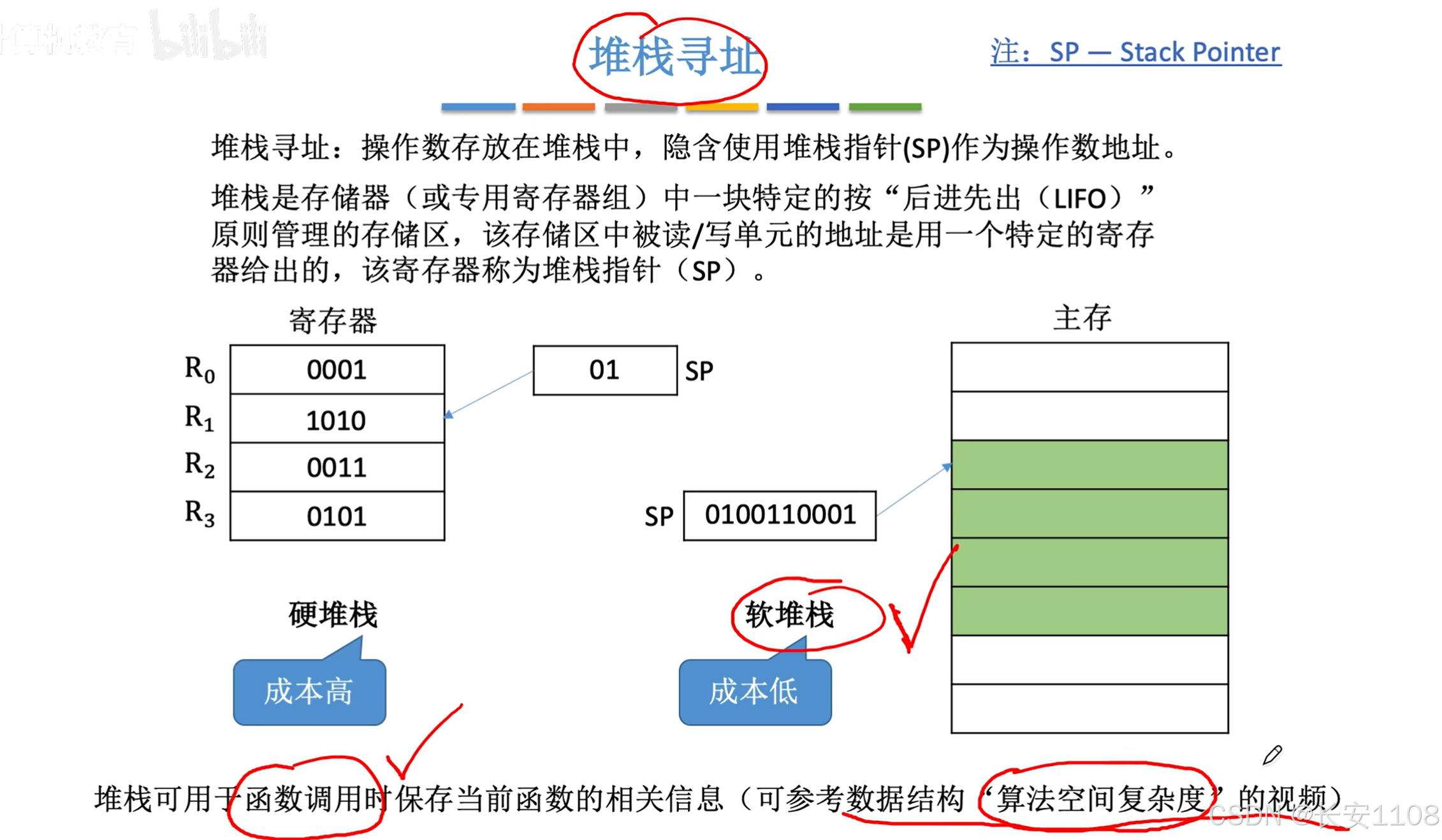
关于堆栈:
1、入栈与出栈的EA确定方式不同,说的是入栈时,SP先移动,出栈时,先把值拿走,然后SP再移动
(但SP的移动都是硬件控制的)
2、注意表中说的是“指令执行期间”的访存次数
4.3
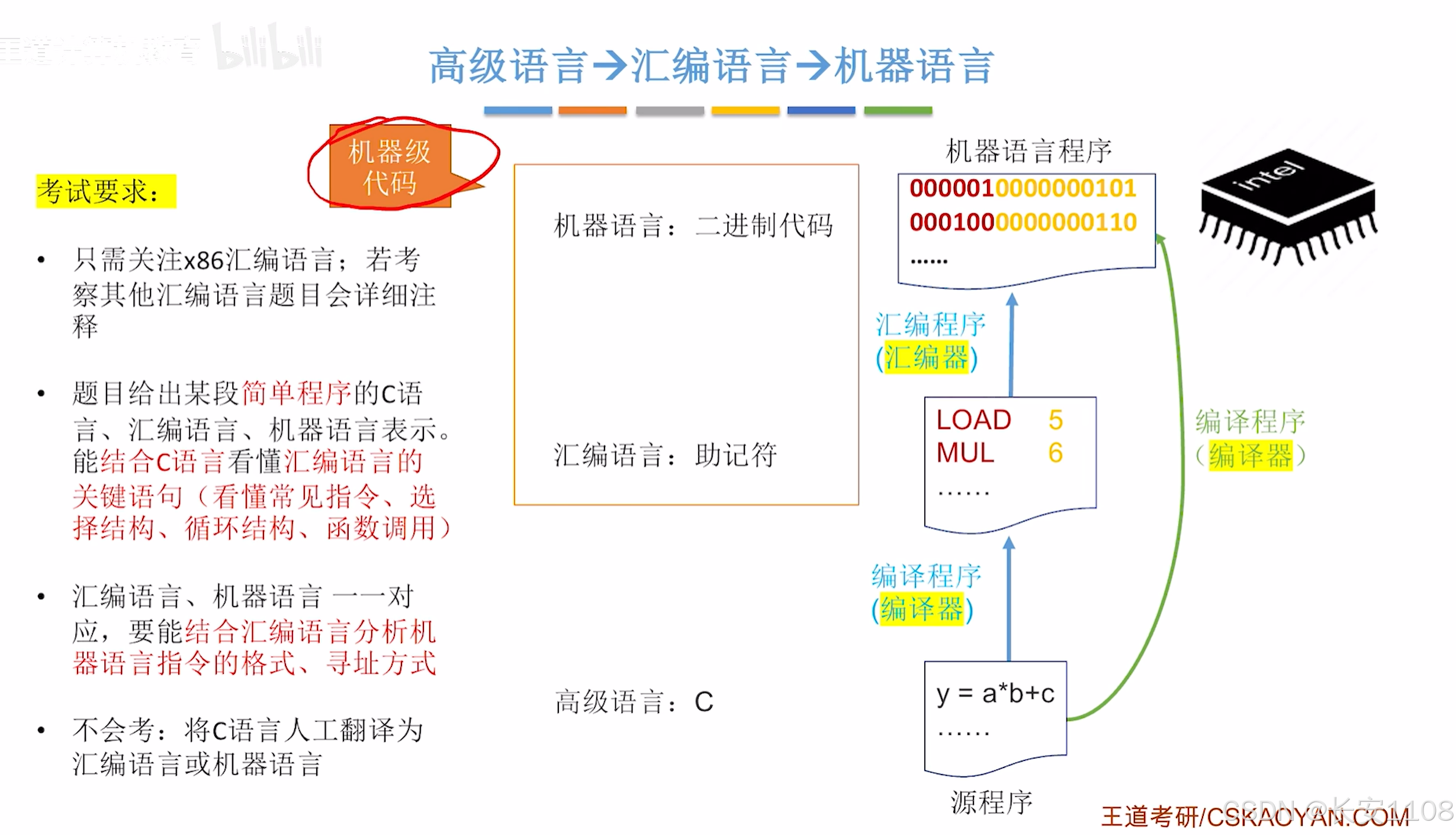
4.3.1 高级语言与机器代码之间的对应
总览

















 4830
4830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









