






目录
一、什么是逻辑回归?
由于逻辑回归的原理是用逻辑函数把线性回归的结果(-∞,∞)映射到(0,1),故先介绍线性回归函数和逻辑函数。
1 线性回归函数
线性回归函数的数学表达式:
其中xi是自变量,y是因变量,y的值域为(-∞,∞),θ0是常数项,θi(i=1,2,...,n)是待求系数,不同的权重θi反映了自变量对因变量不同的贡献程度。
我们初中学过的一元一次方程:y=a+bx,这种只包括一个自变量和一个因变量的回归分析称为一元线性回归分析。
初中学过的二元一次方程:y = a+b1x1+b2x2,三元一次方程:y = a+b1x1+b2x2+b3x3,这种回归分析中包括两个或两个以上自变量的回归分析,称为多元线性回归分析。
不管是一元线性回归分析还是多元线性回归分析,都是线性回归分析。
2 逻辑函数(Sigmoid函数)
2.1 逻辑函数的数学表达式
2.2 逻辑函数的图像
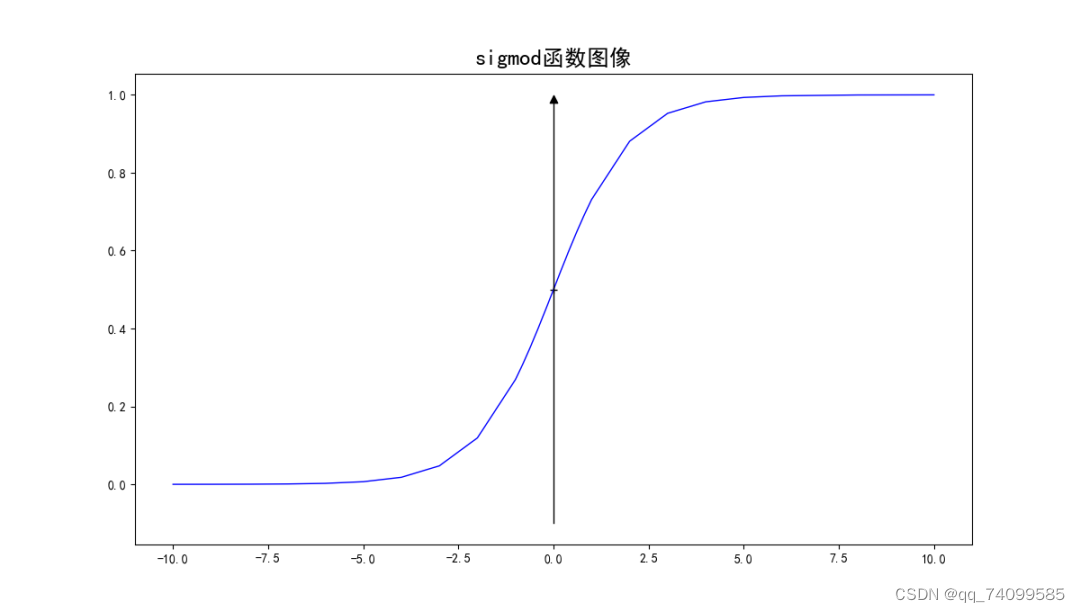
图一 sigmod函数大致图像
从图1可以看出,当z趋于-∞, g(z)趋于0, 当z趋于∞, g(z)趋于1, 且函数的值阈为(0,1)。原理是当z趋于-∞,e⁻¹趋于∞, g(z)趋于0, 当z趋于∞, 趋于0, g(z)趋于1。
同时可以发现当z趋于5时, g(z)的值已经到0.99附近, z越大, g(z)越趋于1。
想一想我们平时碰到的概率,我们可能认为明天下雨的概率为0.3,天晴的概率为0.7。抛一枚硬币正面的概率为0.5,反面的概率也为0.5。概率也是介于0到1之间的一些数,很自然我们可以把sigmod函数的值域和概率联系起来。
2.3 逻辑函数的导函数
逻辑函数的表达式为:
导函数为:
从上面的推导可以看出逻辑函数的导函数可以转化成本身的一个表达式,这在后面用梯度下降法求解参数时会用到,可以先有个印象。
从本节对逻辑函数的介绍知,逻辑函数是一个连续且任意阶可导的函数,值域为(0,1)。
3 逻辑回归函数
在逻辑回归的由来一文中详细推导了得出逻辑回归函数的步骤,也得知逻辑回归的因变量g(y)就是伯努利分布中样本为1的概率。
前文中也提到过逻辑回归的原理是用逻辑函数把线性回归的结果从(-∞,∞)映射到(0,1)。我们用公式描述上面这句话:
把线性回归函数的结果y,放到sigmod函数中去,就构造了逻辑回归函数。
由y的值域和sigmod函数的值域知,在逻辑回归函数中用sigmod函数把线性回归的结果(-∞,∞)映射到(0,1),得到的这个结果类似一个概率值。
我们转换一下逻辑回归函数,过程如下:
上式中,现在把逻辑回归的结果g(y)看成某个事件发生的概率,那么这个事件不发生的概率就是1-g(y),两者的比值称为几率(odds)。令g(y)=p,可以得到如下公式:
即线性回归的结果等于对数几率。
如果我们把车贷中违约(不按期还款产生坏账)客户的样本标签定义为1,正常(按期还款)客户的样本标签定义为0。可以进一步把逻辑函数的值定义为客户违约的后验概率。
如果历史上我们积累了大量的违约客户和正常客户的样本数据,比如违约客户和正常客户的年龄、工资、房贷、在第三方平台借款数目等等众多标签。
这些标签就是逻辑回归函数中的xi,我们可以用这些样本数据训练逻辑回归模型,并求解得到变量x的参数(系数)θ。
标签数据年龄、工资等是已有信息,如果参数(系数)θ也已经求出,把标签数据和参数代入逻辑回归模型,就可以预测任一客户违约的概率。
二、如何求解逻辑回归中的参数?
1 极大似然函数
先来看一个小例子:如果小华这次考试考了90分以上,妈妈99%会奖励小华一个手机,如果没有考到90分以上,妈妈99%不会奖励小华手机。现在小华没有得到手机,问小华这次有没有考到90分。
可能我们的第一反应是小华大概率没有考到90分以上。这种利用已知样本结果,反推最有可能导致这样结果的参数值,就是极大似然估计。
结合逻辑回归函数,如果我们已经积累了大量的违约客户和正常客户的样本数据,利用极大似然函数由果溯因,估计出使得目前结果的可能性最大参数(系数)θ,有了参数我们就可以求任何一个客户违约的概率了。
我们上文提到过客户违约的后验概率:
相应的可以得到客户不违约的概率:
如果令
违约的后验概率可以写成:
不违约的后验概率可以写成:
对于某一个客户,我们采集到了样本数据(x,y)。对于这个样本,他的标签是y的概率可以定义成:
其中y∈{0,1}。当y=0时,上式为不违约的后验概率,当y=1时,上式为违约的后验概率。
现在我们有m个客户的观测样本
将每一个样本发生的概率相乘,就是这个合成在一起得到的合事件发生的总概率(利用概率中的乘法公式),即为似然函数,可以写成:
其中θ为待求参数。
注:我们总是希望出现目前结果的可能性最大,所以想要得到极大化似然函数对应的参数θ。
为便于求解,我们引入不改变函数单调性的对数函数ln,把连乘变成加法,得到对数似然函数:
至此,可以用梯度上升法求解对数似然函数,求出使得目前结果的可能性最大的参数θ。也可以由对数似然函数构造损失函数,用梯度下降法求出使得损失最小对应的参数θ,接下来看下逻辑回归中的损失函数。
注:使用对数似然函数,不仅仅把连乘变成加法,便于求解,而且对数似然函对应的损失函数是关于未知参数的高阶连续可导的凸函数,便于求其全局最优解。
2 构造损失函数
在机器学习中有损失函数的概念,我们知道损失函数一般定义为预测值和真实值的差,比如我们预测小华在这次考试中能考98分,成绩出来了小华实际考了97分,小华的成绩预测值和真实值差为1,这个1通俗理解就是损失函数的值。
从上面的案例知,如果损失函数越小,说明模型预测越准。所以在函数比较复杂没有确定解(解析解)或很难求出确定解的情况下,一般求的是数值解(近似解)。一般模型求数值解可以求出使得损失函数最小对应的参数θ。
结合逻辑回归中的极大似然函数,如果取整个数据集上的平均对数似然损失,我们可以得到:
![]()
其中J(θ)为损失函数,由对数似然函数前面添加负号取平均得到。
即在逻辑回归模型中,最大化似然函数和最小化损失函数实际上是等价的(求最大化对数似然函数对应的参数θ和求最小化平均对数似然损失对应的参数θ是一致的),即:
![]()
那如何求得损失函数最小对应的参数呢?可以用下节讲到的方法:梯度下降法。
3 用梯度下降法求解参数
先以一个人下山为例讲解梯度下降法的步骤:
- step1:明确自己现在所处的位置;
- step2:找到现在所处位置下降最快的方向;
- step3: 沿着第二步找到的方向走一个步长,到达新的位置,且新位置低于刚才的位置;
- step4:判断是否下山,如果还没有到最低点继续步骤一,如果已经到最低点,则停止。
从上面的分析知,用梯度下降法求解参数最重要的是找到下降最快的方向和确定要走的步长。
那么什么是函数下降最快的方向?
如果学过一元函数的导数,应该知道导数的几何意义是某点切线的斜率。除此之外导数还可以表示函数在该点的变化率,导数越大,表示函数在该点的变化越大。
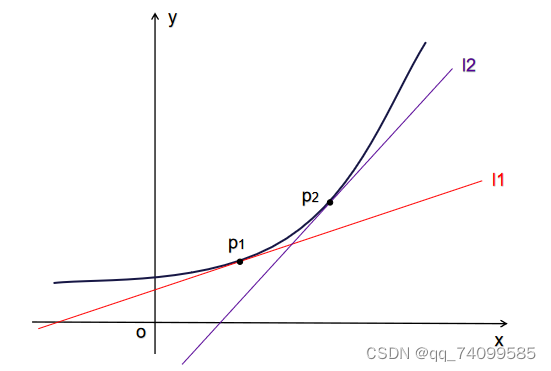
图2 曲线的导函数
从图2可以发现p2点的斜率大于p1点的斜率,即p2点的导数大于p1点的导数。
对于多维向量
![]()
它的导数叫做梯度(偏导数),当求某个变量的导数时,把其它变量视为常量,对整个函数求导,也就是分别对于它的每个分量求导数,即
![]()
对于函数的某个特定点,它的梯度就表示从该点出发,函数值变化最为迅猛的方向。至此梯度下降法求解参数的方向已经找到,那就是函数的梯度方向。
接下来推导损失函数的梯度(偏导数):
由损失函数的公式知:
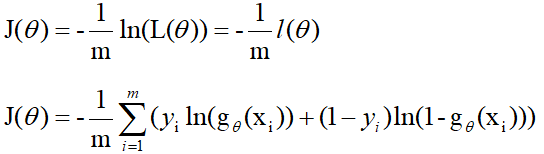
对损失函数求偏导:
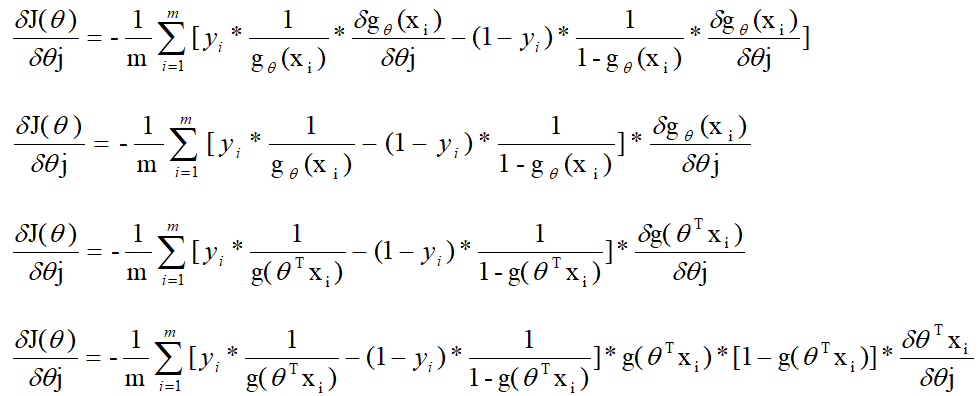
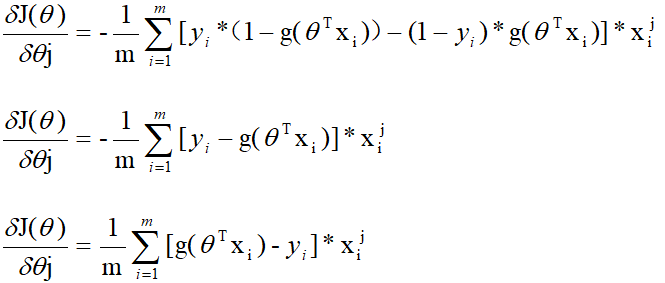
至此,找到了梯度下降中的方向,只要给定一个步长就可以用迭代的方式来求待求参数,迭代的公式为:
![]()
三.代码实现
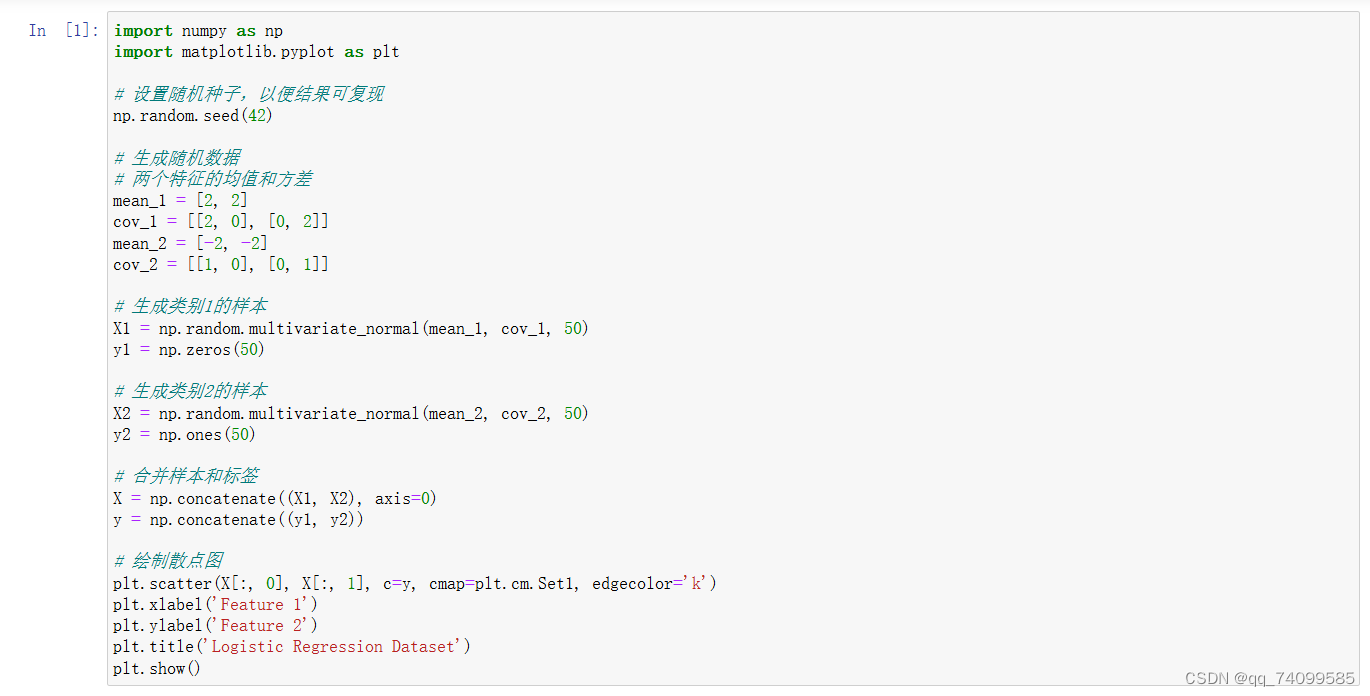
生成数据集
我们通过下面的代码自行生成一个样本数量为100的数据集
运行结果如下
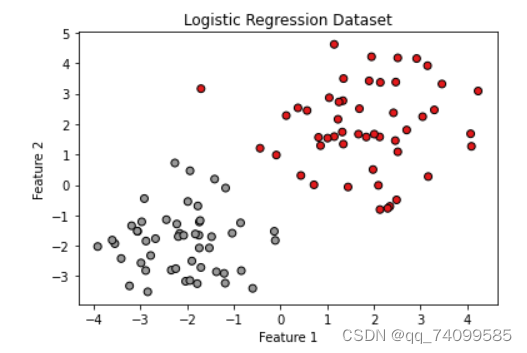
图中,类别1为右上部分,标签为0;类别2为左下部分,标签为1
使用sklearn库
我们可以通过使用sklearn库来简洁地实现LR 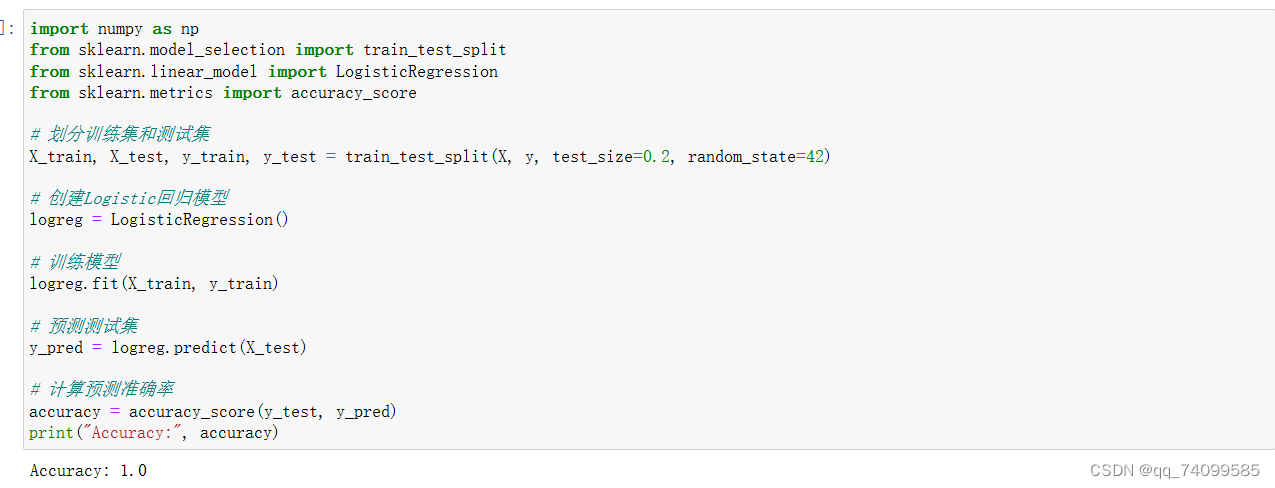
最终测试集上计算得到的准确率accuracy为1,可见该分类器的效果非常好















 2297
2297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









