






目录
前言
支持向量机(SVM)是一种常见的机器学习方法,常用于分类(线性和非线性分类问题),回归问题。本文将详细介绍一下支持向量机算法
SVM算法
SVM算法称为支持向量机,是一种监督学习算法,主要用于分类和回归分析。
SVM是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。
SVM算法的原理是找到一个最佳的超平面,将不同类别的数据点分开,并且使得超平面到最近的数据点的间隔最大化。具体来说,SVM通过最大化间隔来寻找最优的超平面,以此来实现对数据的分类和回归分析。
SVM 的基本原理
1. 超平面:在二维空间中,超平面是一条直线;在三维空间中,它是一个平面;而在更高维度的空间中,它是一个超平面。SVM 的目标就是找到一个最佳的超平面,能够将不同类别的数据点分开
2. 最大间隔:SVM 试图找到一个超平面,使得该超平面到最近的数据点(支持向量)的距离(称为间隔)最大化。这样可以增加分类的鲁棒性和泛化性能
3. 核技巧:在处理非线性可分数据时,SVM 通过核技巧将数据映射到更高维的空间,以便在新的空间中找到一个更好的超平面来分类数据
4. 损失函数和最优化:SVM 通过最小化损失函数和引入正则化项来求解最优的超平面,以得到最佳的分类结果
5. 支持向量:在训练过程中,只有距离超平面最近的一些数据点(支持向量)对最终的超平面有影响,这些数据点决定了最终的分类结果
SVM 的原理涉及到凸优化、间隔最大化以及核技巧等概念,这使得 SVM 能够在实践中取得很好的分类效果。总的来说,SVM 以间隔最大化为目标,通过求解相应的优化问题来找到最佳的分类超平面。
SVM算法的作用与优点
SVM算法主要用于解决分类和回归问题。具体来说,SVM的作用包括:
1. 分类问题:SVM可以用来将数据分为两个或多个类别。通过找到一个最佳的超平面,将不同类别的数据点分开,实现对数据的分类。SVM还可以使用核函数来处理非线性分类问题
2. 回归问题:SVM也可以用于解决回归问题。通过设置合适的参数和核函数,SVM能够拟合出非线性的回归曲线,对数据进行回归分析
3. 异常检测:SVM可以用于检测异常值和异常模式,从而在数据挖掘和异常检测方面有较好的应用 总之,SVM算法在解决数据分类、回归和异常检测等问题上具有广泛的应用。
其中, SVM算法的优点包括:
1. 适用性广泛:可以用于分类和回归分析
2. 非线性分类:SVM可以使用核函数对非线性数据进行分类
3. 支持向量:SVM找到的超平面只依赖于少数的支持向量,使得算法更加高效
SVM算法简单例子的实现步骤
SVM(支持向量机)的实现步骤如下:
4.1 数据准备:
准备带标签的训练数据集,每个样本有若干特征和对应的类别标签
# 生成样本数据
np.random.seed(0)
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
Y = [-1] * 20 + [1] * 20 # 两类样本的标签,使用-1和1代表两个类别4.2 初始化模型参数:
初始化权重向量 w 和偏置 b,通常初始化为 0 或者随机值
# 定义SVM模型
class SimpleSVM:
def __init__(self):
self.w = None
self.b = None
def fit(self, X, y):
n_samples, n_features = X.shape
self.w = np.zeros(n_features)
self.b = 0
learning_rate = 0.014.3 训练模型:
通过梯度下降等优化方法,迭代计算最优的超平面来最大化间隔,并对样本进行分类
# 训练模型
for _ in range(1000):
for idx, x_i in enumerate(X):
condition = y[idx] * (np.dot(x_i, self.w) - self.b) >= 1
if condition:
self.w -= learning_rate * (2 * 0.01 * self.w)
else:
self.w -= learning_rate * (2 * 0.01 * self.w - np.dot(x_i, y[idx]))
self.b -= learning_rate * y[idx]4.4 根据预测值确定类别:
根据模型参数和输入数据计算预测值,使用 sign 函数将其转换为类别标签
def predict(self, X):
return np.sign(np.dot(X, self.w) - self.b)4.5 可视化决策边界:
通过绘制决策边界,将模型对数据的分类结果可视化,以便观察模型的效果
# 实例化SVM模型并进行训练
svm = SimpleSVM()
svm.fit(X, Y)
# 绘制决策边界
def plot_decision_boundary(X, Y, model):
h = .02 # 步长
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired)
plt.show()
# 绘制决策边界
plot_decision_boundary(X, Y, svm)SVM算法简单例子的完整实现
SVM 算法的简单例子实现如下:
完整代码:
import numpy as np
import matplotlib.pyplot as plt
# 生成样本数据
np.random.seed(0)
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
Y = [-1] * 20 + [1] * 20 # 两类样本的标签,使用-1和1代表两个类别
# 定义SVM模型
class SimpleSVM:
def __init__(self):
self.w = None
self.b = None
def fit(self, X, y):
n_samples, n_features = X.shape
self.w = np.zeros(n_features)
self.b = 0
learning_rate = 0.01
# 训练模型
for _ in range(1000):
for idx, x_i in enumerate(X):
condition = y[idx] * (np.dot(x_i, self.w) - self.b) >= 1
if condition:
self.w -= learning_rate * (2 * 0.01 * self.w)
else:
self.w -= learning_rate * (2 * 0.01 * self.w - np.dot(x_i, y[idx]))
self.b -= learning_rate * y[idx]
def predict(self, X):
return np.sign(np.dot(X, self.w) - self.b)
# 实例化SVM模型并进行训练
svm = SimpleSVM()
svm.fit(X, Y)
# 绘制决策边界
def plot_decision_boundary(X, Y, model):
h = .02 # 步长
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired)
plt.show()
# 绘制决策边界
plot_decision_boundary(X, Y, svm)运行结果:
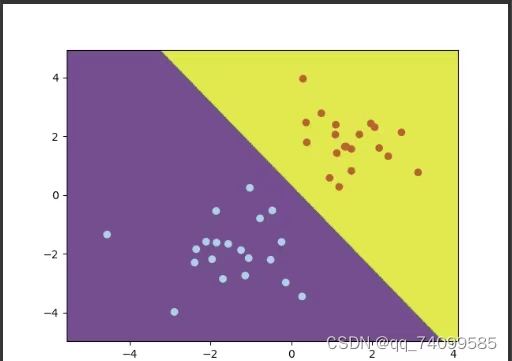
实验总结
本次实验中,我尝试实现了一个简单的支持向量机(SVM)模型。总的来说,本次实验使我更好地理解了支持向量机的基本原理和实现过程,实现能够对线性可分数据进行分类的SVM算法模型。















 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









