







 本文介绍了Hadoop生态圈的主要组件,如HDFS、MapReduce、YARN、Hive、Pig等,以及MapReduce的特点和运行架构。同时对比了ApacheSpark的特性,强调了Linux系统指令在大数据处理和灾难恢复中的作用,包括冷备、温备和热备策略。
本文介绍了Hadoop生态圈的主要组件,如HDFS、MapReduce、YARN、Hive、Pig等,以及MapReduce的特点和运行架构。同时对比了ApacheSpark的特性,强调了Linux系统指令在大数据处理和灾难恢复中的作用,包括冷备、温备和热备策略。
一.Hadoop生态圈组件介绍
Hadoop生态圈包括多个组件,这些组件共同协作以支持大规模数据处理和分析。主要组件包括:
HDFS(Hadoop Distributed File System)。它是Hadoop的核心存储系统,提供高容错性和可扩展性,适合处理超大数据集。
MapReduce。这是一个编程模型,用于处理和生成超大数据集,它提供简单的编程接口,易于扩展,但随着大数据处理的需求增加,MapReduce的局限性也逐渐显现。
YARN(Yet Another Resource Negotiator)。它是Hadoop的资源管理器,负责集群资源的统一管理和调度。
Hive。它构建在Hadoop之上,提供类SQL查询语言,用于构建数据仓库和执行复杂的数据分析。
Pig。它是一种高级编程语言和平台,用于将复杂的数据处理流程转化为简单的脚本。
HBase。它是一个分布式、可扩展的列式数据库,适用于处理大规模结构化数据。
ZooKeeper。它是一个分布式协调服务,用于协调Hadoop集群中各个节点的行为。
Sqoop。它用于在Hadoop和关系型数据库之间进行数据传输。
Flume。它是一个分布式、可靠的系统,用于收集、汇聚和移动大规模日志数据。
Spark。它是一个高速大数据处理框架,支持内存计算和更广泛的数据处理模型。
Kafka。它是一个高吞吐量的分布式消息系统,用于发布和订阅流数据。
ES(Elasticsearch)。它是一个全文检索数据库,常与HBase结合使用,用于扩展索引功能。
这些组件共同构成了Hadoop生态圈,支持各种大数据处理和分析任务。
二.Map Reduce的特点及运行架构
1.Map Reduce的特点
MapReduce是一种编程模型,用于处理和生成大数据集。它由Google提出,并被Hadoop等大数据处理框架广泛采用。MapReduce的特点主要包括:
1. 易于编程:MapReduce模型将复杂的数据处理任务简化为两个步骤:Map步骤和Reduce步骤。这种分离使得编写并行程序变得简单。
2. 自动并行化:MapReduce框架自动处理任务的并行执行,开发者不需要手动管理并行计算的细节。
3. 容错性:MapReduce具有自动的错误恢复机制。如果某个任务失败,系统会自动重新执行该任务。此外,它还能够处理节点故障。
4.可扩展性:MapReduce设计用于处理大量数据,它可以在成千上万的节点上运行,具有良好的水平扩展性。
5. 资源管理:MapReduce框架负责资源的分配和管理,包括任务调度、数据复制和负载均衡。
6. 数据局部性:MapReduce尽可能地在存储数据的节点上执行Map任务,以减少网络传输,提高效率。
7. 数据流处理:MapReduce处理的是数据流,这意味着它不需要将整个数据集加载到内存中,而是可以处理流式数据。
8. 中间数据的持久化:MapReduce允许中间结果(Map阶段的输出)被持久化存储,这样即使Reduce任务失败,也可以从中间结果重新开始,而不是从头开始处理。
9. 灵活性:MapReduce允许开发者自定义Map和Reduce函数,以适应各种不同的数据处理需求。
10. 适合大规模数据处理:MapReduce特别适合于大规模数据集的处理,它可以有效地处理PB级别的数据。
尽管MapReduce有许多优点,但它也有一些局限性,比如对于迭代算法和实时数据处理的支持不足。因此,随着技术的发展,出现了其他如Apache Spark等更灵活的大数据处理框架。
2.Map Reduce的运行架构
MapReduce架构主要由以下几个组件组成:
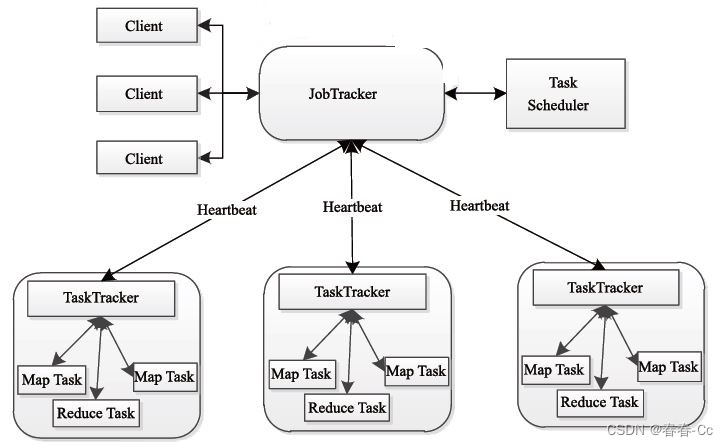
1. Client:用户编写的MapReduce程序通过Client提交给集群。Client负责与JobTracker通信,提交作业并监控作业的执行状态。
2. JobTracker:在Hadoop 1.x中,JobTracker是MapReduce框架的主节点,负责资源管理和作业调度。它监控所有TaskTracker的状态,调度Map和Reduce任务,并在任务失败时进行重试。
3. TaskTracker:每个计算节点上运行的TaskTracker负责执行具体的Map和Reduce任务。它会周期性地向JobTracker报告任务执行进度和资源使用情况。
4. Task:Map任务(MapTask)和Reduce任务(ReduceTask)是MapReduce作业的基本执行单元。MapTask处理输入数据并产生中间结果,ReduceTask则对这些中间结果进行汇总。
5. InputFormat 和 OutputFormat:InputFormat负责将输入数据转换成键值对供Map处理,OutputFormat则负责将Reduce的输出结果格式化并存储。
6. Combiner(可选):Combiner是一个可选的组件,它在Map阶段后、Reduce阶段前对数据进行局部聚合,以减少网络传输的数据量。
7. Shuffle:在Map和Reduce阶段之间,MapReduce会进行Shuffle操作,将Map任务的输出按照键进行排序和分组,然后传输给Reduce任务。
MapReduce的运行过程大致如下:
1. Client将作业提交给JobTracker。
2. JobTracker将作业分解为Map和Reduce任务,并调度这些任务在TaskTracker上执行。
3. MapTask处理输入数据,产生中间结果,这些结果会被持久化存储。
4. Shuffle阶段,中间结果被排序、分组,并传输给ReduceTask。
5. ReduceTask接收到中间结果,进行归约操作,得到最终结果。
6. 最终结果通过OutputFormat输出,通常存储在HDFS上。
在Hadoop 2.x中,JobTracker的角色被ResourceManager和ApplicationMaster取代,以支持更大规模的集群和更复杂的资源管理。
三.spark的特点,以及与MapReduce区别
Apache Spark是一个开源的分布式计算系统,它提供了一个快速、通用和表达性强的数据处理平台。以下是Spark的一些显著特点:
1. 速度快:Spark在内存计算方面比Hadoop MapReduce快上100倍,即使在磁盘上也快10倍以上。这得益于其高效的DAG(有向无环图)执行引擎。
2. 易用性:Spark提供了简洁的API,支持多种编程语言,包括Scala、Java、Python和R。这使得开发者可以更容易地编写和维护代码。
3. 多种数据处理模式:Spark不仅支持MapReduce的Map和Reduce操作,还支持更复杂的数据处理模式,如SQL查询、流处理、机器学习和图处理。
4. 内存计算:Spark能够将中间数据保存在内存中,减少了对磁盘的访问,从而显著提高了迭代计算的性能。
5. 容错性:Spark通过弹性分布式数据集(RDD)提供了一种高度容错的数据抽象,可以在节点失败时重新计算丢失的数据分区。
6. 可扩展性:Spark可以在大量廉价硬件上运行,具有良好的水平扩展性。
7. 组件丰富:Spark生态系统包含多个组件,如Spark SQL(用于SQL查询)、Spark Streaming(用于流处理)、MLlib(用于机器学习)和GraphX(用于图形处理)。
与MapReduce相比,Spark的主要区别包括:
1. 性能:Spark通常比MapReduce快,因为它优化了任务调度和内存使用,减少了磁盘I/O。
2. 编程模型:MapReduce仅支持Map和Reduce两种操作,而Spark提供了更丰富的操作集,包括filter、join、groupBy等。
3. 迭代计算:MapReduce不适合迭代计算,因为每次迭代都需要读写磁盘。Spark则可以有效地处理迭代算法,如机器学习算法。
4. 内存计算:MapReduce主要依赖磁盘存储,而Spark可以将数据保留在内存中,这对于迭代计算和交互式数据挖掘特别有用。
5. 容错性:MapReduce通过复制数据来实现容错,而Spark通过RDD的lineage(血统)信息来重建丢失的数据。
6. 生态系统:Spark拥有一个更加活跃和多样化的生态系统,提供了更多的库和工具,如Spark SQL、MLlib等。
7. 任务调度:MapReduce使用Hadoop的YARN进行任务调度,而Spark有自己的调度器,可以在YARN上运行,也可以独立运行。
总的来说,Spark在性能、易用性和数据处理能力上都优于MapReduce,特别是在需要迭代计算和内存计算的场景中。然而,MapReduce仍然是一个强大的工具,特别是在需要高吞吐量和批量处理的场景中。
四.冷备,温备,热备
冷备(Cold Backup)、温备(Warm Backup)和热备(Hot Backup)是数据备份和灾难恢复领域中的三种不同的备份策略,它们根据备份系统与生产系统的同步程度和准备状态来区分。
1. 冷备(Cold Backup):
- 冷备是指备份系统未安装或未配置成与当前使用的系统相同或相似的运行环境,应用系统数据没有及时装入备份系统。
- 在发生灾难时,需要重新安装和配置所需的运行环境,然后使用数据备份介质(如磁带或光盘)来恢复应用数据。
- 冷备的优点是设备投资较少,节省通信费用,通信环境要求不高。
- 缺点是恢复时间较长,可能需要数天至一周,数据完整性和一致性较差。
2. 温备(Warm Backup):
- 温备介于冷备和热备之间,备份系统已经安装并配置好,但可能不完全与生产系统同步,或者同步频率较低。
- 在需要时,温备系统可以较快地启动并承担业务,但可能需要一些时间来同步数据和配置,以达到生产系统的最新状态。
- 温备的优点是恢复时间比冷备短,但仍然需要一定的准备时间。
3. 热备(Hot Backup):
- 热备是指备份系统与生产系统实时同步,可以立即接管生产系统的工作任务,当生产系统发生故障或停机时,热备系统可以无缝切换,继续提供服务。
- 热备的优点是恢复速度快,转换波动可以忽略,用户几乎感觉不到服务中断。
- 缺点是设备即使在不使用时也在运行,需要持续耗能,维护成本较高。
在实际应用中,企业会根据自身的业务需求、成本预算和灾难恢复目标来选择合适的备份策略。例如,对于业务连续性要求极高的系统,可能会采用热备或温备策略;而对于成本敏感且业务中断影响较小的场景,则可能选择冷备。
五.大数据的必要学会的Linux系统指令
Linux操作系统提供了丰富的命令行工具,用于执行各种任务。以下是一些常用Linux命令及其意义的说明:
1. ls - 列出目录内容
- `ls`:列出当前目录下的文件和文件夹。
- `ls -l`:以长格式列出详细信息,包括权限、所有者、大小等。
- `ls -a`:显示所有文件,包括隐藏文件(以`.`开头的文件)。
2. cd - 更改目录
- `cd /path/to/directory`:切换到指定的目录。
- `cd ..`:返回上一级目录。
- `cd ~`:切换到用户的家目录。
3. pwd - 显示当前工作目录的路径。
4. cp- 复制文件或目录
- `cp source.txt destination.txt`:将`source.txt`复制到`destination.txt`。
- `cp -r source_dir destination_dir`:递归复制整个目录。
5. mv - 移动或重命名文件和目录
- `mv oldname.txt newname.txt`:将文件`oldname.txt`重命名为`newname.txt`。
- `mv file /path/to/directory/`:将文件移动到指定目录。
6. rm - 删除文件或目录
- `rm file.txt`:删除名为`file.txt`的文件。
- `rm -r directory`:递归删除名为`directory`的目录及其内容。
- `rm -f file.txt`:强制删除文件,忽略不存在的文件,不提示。
7. mkdir - 创建新目录
- `mkdir new_directory`:创建名为`new_directory`的新目录。
8. rmdir - 删除空目录
- `rmdir directory`:删除名为`directory`的空目录。
9. touch - 创建空文件或更新文件时间戳
- `touch file.txt`:如果文件不存在,则创建一个空的`file.txt`文件。
10. cat - 查看文件内容或创建文件
- `cat file.txt`:显示`file.txt`文件的内容。
- `cat > newfile.txt`:创建一个名为`newfile.txt`的新文件,并准备输入内容。
11. grep - 文本搜索
- `grep "pattern" file.txt`:在`file.txt`中搜索字符串"pattern"。
12. chmod - 更改文件权限
- `chmod 755 file.txt`:为`file.txt`设置权限(读、写、执行)。
13. chown - 更改文件所有者
- `chown newowner file.txt`:将`file.txt`的所有权更改为`newowner`。
14. ps - 显示当前进程
- `ps`:显示当前用户的进程。
- `ps aux`:显示系统上所有用户的进程。
15. kill- 终止进程
- `kill PID`:终止进程ID(PID)对应的进程。
16. top - 显示系统资源使用情况
- `top`:实时显示系统的资源使用情况,包括CPU、内存等。
17. df - 显示磁盘空间使用情况
- `df -h`:以易读的格式(如MB、GB)显示磁盘空间。
18. du - 显示目录或文件的磁盘使用情况
- `du -sh directory`:显示`directory`目录的总磁盘使用量。
19. tar - 文件压缩和解压缩
- `tar -cvf archive.tar /path/to/directory`:将目录压缩到`archive.tar`。
- `tar -xvf archive.tar`:解压缩`archive.tar`。
20. wget - 从网络下载文件
- `wget http://example.com/file.zip`:下载`http://example.com/file.zip`文件。
这些命令是Linux用户日常工作中的基础,掌握它们可以帮助你更高效地管理和操作Linux系统。在实际使用中,你可以通过`man`命令(如`man ls`)来查看每个命令的详细手册页,了解更多选项和用法。















 2069
2069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









