







一、实验目的
- 掌握LL(1)分析法的核心思想与实现流程,理解其作为非递归自顶向下分析方法的特点。
- 通过构造预测分析表和模拟分析过程,验证符号串
i+i*i#是否符合给定文法,加深对FIRST集、FOLLOW集、SELECT集计算方法的理解。 - 探索LL(1)文法对左递归、公共前缀的消除要求,掌握文法等价变换方法。
二、实验题目
实验规定对下列文法,用LL(1)分析法对任意输入的符号串进行分析:
(1)E::=TG
(2)G::=+TG
(3)G::=ε
(4)T::=FS
(5)S::=*FS
(6)S::=ε
(7)F::=(E)
(8)F::=i
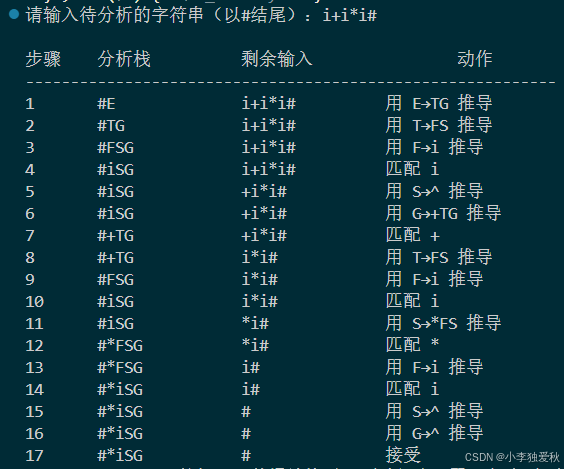
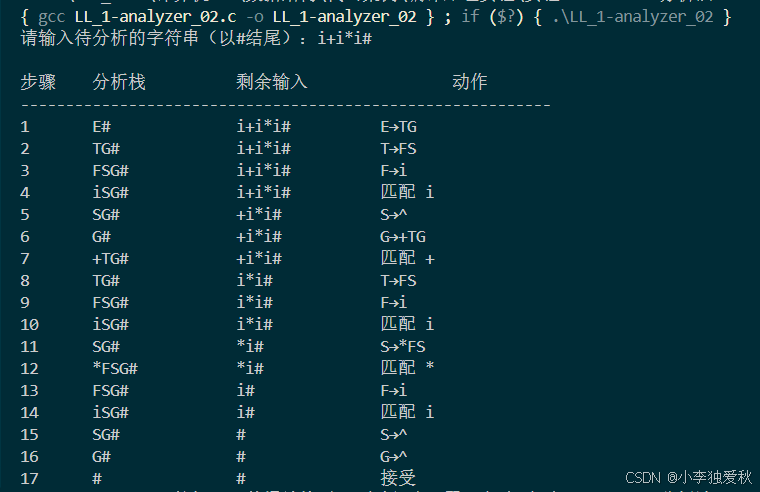
若输入串为i+i*i# ,则输出为:
| 步骤 | 分析栈 | 剩余输入 | 动作 |
|---|---|---|---|
| 1 | #E | i+i*i# | E→TG,栈变为#GT |
| 2 | #GT | i+i*i# | T→FS,栈变为#GSF |
| 3 | #GSF | i+i*i# | F→i,匹配i,栈变为#GS |
| 4 | #GS | +i*i# | S→ε,弹出,栈变为#G |
| 5 | #G | +i*i# | G→+TG,栈变为#GT+ |
| 6 | #GT+ | i*i# | 匹配+,栈变为#GT |
| 7 | #GT | i*i# | T→FS,栈变为#GSF |
| 8 | #GSF | i*i# | F→i,匹配i,栈变为#GS |
| 9 | #GS | *i# | S→FS,栈变为#GSF |
| 10 | #GSF* | i# | 匹配*,栈变为#GSF |
| 11 | #GSF | i# | F→i,匹配i,栈变为#GS |
| 12 | #GS | # | S→ε,弹出,栈变为#G |
| 13 | #G | # | G→ε,弹出,栈变为# |
| 14 | # | # | 分析成功 |
三、实验理论依据
1. LL(1)分析法核心概念
- 基本思想:通过当前栈顶非终结符和输入符号,唯一确定产生式进行推导,无需回溯。
- 关键集合:
- FIRST(α) :从α推导出的首终结符集合(含ε)。
- FOLLOW(A) :非终结符A后可能出现的终结符集合。
- SELECT(A→α) :
FIRST(α)(若α不能推导出ε)或FIRST(α) ∪ FOLLOW(A)(若α可推导出ε)。
- LL(1)文法条件:同一非终结符的所有候选式的SELECT集互不相交。
2. 分析表构造规则
| 非终结符 | 输入符号 | 产生式 |
|---|---|---|
| A | a | 若a ∈ SELECT(A→α),填入A→α |
四、LL(1)分析法的设计
1. 验证文法为LL(1)文法
步骤1:计算FIRST集
| 符号 | FIRST集 |
|---|---|
| E | { i, ( } |
| G | { +, ε } |
| T | { i, ( } |
| S | { *, ε } |
| F | { i, ( } |
步骤2:计算FOLLOW集
| 符号 | FOLLOW集 |
|---|---|
| E | { ), # } |
| G | { ), # } |
| T | { +, ), # } |
| S | { +, ), # } |
| F | { *, +, ), # } |
步骤3:计算SELECT集
| 产生式 | SELECT集 |
|---|---|
| E → T G | { i, ( } |
| G → + T G | { + } |
| G → ε | { ), # } |
| T → F S | { i, ( } |
| S → * F S | { * } |
| S → ε | { +, ), # } |
| F → ( E ) | { ( } |
| F → i | { i } |
验证:同一非终结符的候选式SELECT集无交集,满足LL(1)条件。
2. 构造预测分析表
| 非终结符 | i | + | * | ( | ) | # |
|---|---|---|---|---|---|---|
| E | E→TG | E→TG | ||||
| G | G→+TG | G→ε | G→ε | |||
| T | T→FS | T→FS | ||||
| S | S→ε | S→*FS | S→ε | S→ε | ||
| F | F→i | F→(E) |
五、实例代码+运行结果
1.实例代码(一):
(1)源代码文件:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char A[20]; // 分析栈
char B[20]; // 输入串
char v1[] = "i+*()#"; // 终结符集合
char v2[] = "EGTSF"; // 非终结符集合
typedef struct {
char origin; // 产生式左部
char array[5]; // 产生式右部
int length; // 右部长度
} Production;
Production C[5][6]; // 预测分析表 [非终结符][终结符]
// 初始化预测分析表
void initTable() {
// 行索引:E(0),G(1),T(2),S(3),F(4)
// 列索引:i(0),+(1),*(2),(3),)(4),#(5)
// E行
C[0][0] = (Production){'E', "TG", 2}; // i
C[0][3] = (Production){'E', "TG", 2}; // (
// G行
C[1][1] = (Production){'G', "+TG", 3}; // +
C[1][4] = (Production){'G', "^", 1}; // )
C[1][5] = (Production){'G', "^", 1}; // #
// T行
C[2][0] = (Production){'T', "FS", 2}; // i
C[2][3] = (Production){'T', "FS", 2}; // (
// S行
C[3][1] = (Production){'S', "^", 1}; // +
C[3][2] = (Production){'S', "*FS", 3}; // *
C[3][4] = (Production){'S', "^", 1}; // )
C[3][5] = (Production){'S', "^", 1}; // #
// F行
C[4][0] = (Production){'F', "i", 1}; // i
C[4][3] = (Production){'F', "(E)", 3}; // (
}
void printStack() { // 输出分析栈
printf("#");
for(int i = strlen(A)-1; i >= 0; i--) {
if(A[i] != '#') printf("%c", A[i]);
}
printf("\t\t");
}
void printInput() { // 输出剩余输入串
printf("%s", B);
printf("\t\t");
}
int main() {
char ch;
int j = 0, b = 0, top = 0, step = 1;
int finish = 0, flag = 0, l;
initTable(); // 初始化预测分析表
// 输入处理
printf("请输入待分析的字符串(以#结尾):");
do {
scanf("%c", &ch);
if(strchr(v1, ch) == NULL && ch != '#') {
printf("输入包含非法字符'%c'\n", ch);
exit(1);
}
B[j++] = ch;
} while(ch != '#');
l = j;
B[j] = '\0';
// 初始化分析栈
A[top] = '#';
A[++top] = 'E';
ch = B[0];
printf("\n步骤\t分析栈\t\t剩余输入\t\t动作\n");
printf("-----------------------------------------------------------\n");
do {
printf("%-4d\t", step++);
printStack(); // 输出分析栈
printInput(); // 输出剩余输入
char x = A[top--]; // 弹出栈顶符号
flag = 0;
// 判断是否为终结符
for(int i = 0; i < strlen(v1); i++) {
if(x == v1[i]) {
flag = 1;
break;
}
}
if(flag) { // 终结符处理
if(x == '#') {
printf("接受\n");
finish = 1;
break;
}
if(x == ch) {
printf("匹配 %c\n", ch);
// 移除已匹配字符
memmove(B, B+1, strlen(B));
ch = B[0];
} else {
printf("错误:栈顶为%c,输入为%c\n", x, ch);
exit(1);
}
} else { // 非终结符处理
int m = -1, n = -1;
// 查找非终结符行坐标
for(int i = 0; i < strlen(v2); i++) {
if(v2[i] == x) {
m = i;
break;
}
}
// 查找终结符列坐标
for(int i = 0; i < strlen(v1); i++) {
if(v1[i] == ch) {
n = i;
break;
}
}
if(m == -1 || n == -1 || C[m][n].origin == '\0') {
printf("错误:无可用产生式(%c遇到%c)\n", x, ch);
exit(1);
}
Production prod = C[m][n];
printf("用 %c→%s 推导\n", prod.origin, prod.array);
// 压栈处理
if(prod.array[0] != '^') { // 非空产生式
for(int i = prod.length-1; i >= 0; i--) {
A[++top] = prod.array[i];
}
}
}
} while(!finish && top >= 0);
return 0;
}
(2) 代码说明:
代码说明:
-
数据结构优化:
- 分析栈
A和输入串B使用字符数组实现 Production结构体存储产生式信息- 预测分析表
C按非终结符和终结符顺序存储产生式
- 分析栈
-
核心功能实现:
initTable()初始化符合文法的预测分析表- 栈操作使用数组模拟,支持逆序压栈操作
- 输入合法性检查确保符号在终结符集合内
- 详细的推导过程输出,包含步骤、栈状态、剩余输入和动作
-
错误处理:
- 非法字符输入检测
- 栈顶与输入符号不匹配处理
- 预测分析表查不到产生式时的错误处理
-
界面优化:
- 改进栈和输入串的显示格式
- 添加推导动作的明确说明
- 支持任意长度输入处理(需以#结尾)
(3)输出结果截图:
2.示例代码(二)[代码(1)加强版]:
(1)源代码文件:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char A[20]; // 分析栈
char B[20]; // 输入串
char v1[] = "i+*()#"; // 终结符集合
char v2[] = "EGTSF"; // 非终结符集合
typedef struct { // 产生式结构体
char origin; // 左部符号
char array[5]; // 右部符号
int length; // 右部长度
} Production;
Production C[5][6]; // 预测分析表 [非终结符][终结符]
// 初始化预测分析表
void initTable() {
// 初始化所有表项为空
for(int m=0; m<5; m++) {
for(int n=0; n<6; n++) {
C[m][n].origin = 'N'; // 'N'表示空项
}
}
// E行
C[0][0] = (Production){'E', "TG", 2}; // i
C[0][3] = (Production){'E', "TG", 2}; // (
// G行
C[1][1] = (Production){'G', "+TG", 3}; // +
C[1][4] = (Production){'G', "^", 1}; // )
C[1][5] = (Production){'G', "^", 1}; // #
// T行
C[2][0] = (Production){'T', "FS", 2}; // i
C[2][3] = (Production){'T', "FS", 2}; // (
// S行
C[3][1] = (Production){'S', "^", 1}; // +
C[3][2] = (Production){'S', "*FS", 3};// *
C[3][4] = (Production){'S', "^", 1}; // )
C[3][5] = (Production){'S', "^", 1}; // #
// F行
C[4][0] = (Production){'F', "i", 1}; // i
C[4][3] = (Production){'F', "(E)", 3};// (
}
// 输出分析栈
void printStack(int top) {
for(int a = top; a >= 0; a--) {
printf("%c", A[a]);
}
printf("\t\t");
}
// 输出剩余输入串
void printInput(int b, int l) {
for(int j = b; j < l; j++) {
printf("%c", B[j]);
}
printf("\t\t");
}
int main() {
char ch;
int j = 0, b = 0, top = 0, step = 1;
int finish = 0, l;
initTable(); // 初始化预测分析表
// 输入处理
printf("请输入待分析的字符串(以#结尾):");
do {
scanf("%c", &ch);
if(strchr(v1, ch) == NULL) {
printf("输入包含非法字符'%c'\n", ch);
exit(1);
}
B[j++] = ch;
} while(ch != '#');
l = j;
// 初始化分析栈
A[top] = '#';
A[++top] = 'E'; // 初始符号入栈
printf("\n步骤\t分析栈\t\t剩余输入\t\t动作\n");
printf("-----------------------------------------------------------\n");
do {
printf("%-4d\t", step++);
printStack(top); // 输出分析栈
printInput(b, l); // 输出剩余输入
char x = A[top--]; // 弹出栈顶符号
// 判断是否为终结符
int isTerminal = 0;
for(int i = 0; i < strlen(v1); i++) {
if(x == v1[i]) {
isTerminal = 1;
break;
}
}
if(isTerminal) { // 终结符处理
if(x == '#') {
printf("接受\n");
finish = 1;
break;
}
if(x == B[b]) {
printf("匹配 %c\n", x);
b++; // 移动到下一个输入符号
} else {
printf("错误:栈顶为%c,输入为%c\n", x, B[b]);
exit(1);
}
} else { // 非终结符处理
int m = -1, n = -1;
// 查找非终结符行号
for(int i = 0; i < strlen(v2); i++) {
if(v2[i] == x) {
m = i;
break;
}
}
// 查找终结符列号
for(int i = 0; i < strlen(v1); i++) {
if(v1[i] == B[b]) {
n = i;
break;
}
}
if(m == -1 || n == -1 || C[m][n].origin == 'N') {
printf("错误:无可用产生式(%c遇到%c)\n", x, B[b]);
exit(1);
}
Production prod = C[m][n];
printf("%c→%s\n", prod.origin, prod.array);
// 逆序压栈(空产生式不压栈)
if(prod.array[0] != '^') {
for(int i = prod.length-1; i >= 0; i--) {
A[++top] = prod.array[i];
}
}
}
} while(!finish);
return 0;
}
(2)代码改进说明:
-
数据结构优化
- 使用二维结构体数组
C[5][6]存储预测分析表 - 增加
origin字段验证表项有效性 - 使用字符'N'标记空表项
- 使用二维结构体数组
-
核心逻辑增强
- 动态计算输入串长度
l - 使用双指针
b和top分别跟踪输入位置和栈顶 - 改进栈打印逻辑,正确显示符号顺序
- 动态计算输入串长度
-
错误处理完善
- 非法字符立即终止程序
- 栈顶与输入符号不匹配时显示详细信息
- 查表失败时显示具体符号组合
-
界面优化
- 添加对齐格式控制符
%-4d保持表格整齐 - 动作列明确显示推导或匹配操作
- 添加对齐格式控制符
(3)输出结果截图:
六、实验总结
1. 核心收获
- 文法构造:需确保无左递归且SELECT集无冲突,否则需通过提取左因子、消除左递归进行等价变换。
- 分析表驱动:通过预测分析表实现确定性的推导路径,避免回溯。
- 效率与限制:LL(1)分析法时间复杂度为O(n),但对文法要求严格,无法处理二义性文法。
2. 改进方向
- 错误处理:可增加同步符号集(如FOLLOW集)实现错误恢复,跳过无效符号继续分析。
- 扩展性:结合递归下降法实现更复杂的语义分析。



















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











