






 本文介绍了如何使用Python爬取豆瓣图书《三体》的评论,通过BeautifulSoup解析HTML结构,利用requests获取网页内容,然后使用jieba进行中文分词,最后生成词云图展示评论中的高频词汇。
本文介绍了如何使用Python爬取豆瓣图书《三体》的评论,通过BeautifulSoup解析HTML结构,利用requests获取网页内容,然后使用jieba进行中文分词,最后生成词云图展示评论中的高频词汇。
Python爬取豆瓣图书评论并生成词云图——以《三体》为例
导入必要的库
import requests #用于爬取html
from bs4 import BeautifulSoup #用于转换soup对象,方便处理
from wordcloud import WordCloud #词云图
from collections import Counter #计数工具
import heapq #计数工具
import jieba.posseg as psg #分词工具
import matplotlib.pyplot as plt #显示词云图
查看网址、headers
- 登录豆瓣图书网,打开任意图书短评,并登录
- 点击F12进入开发者模式,选择网络,刷新一下页面
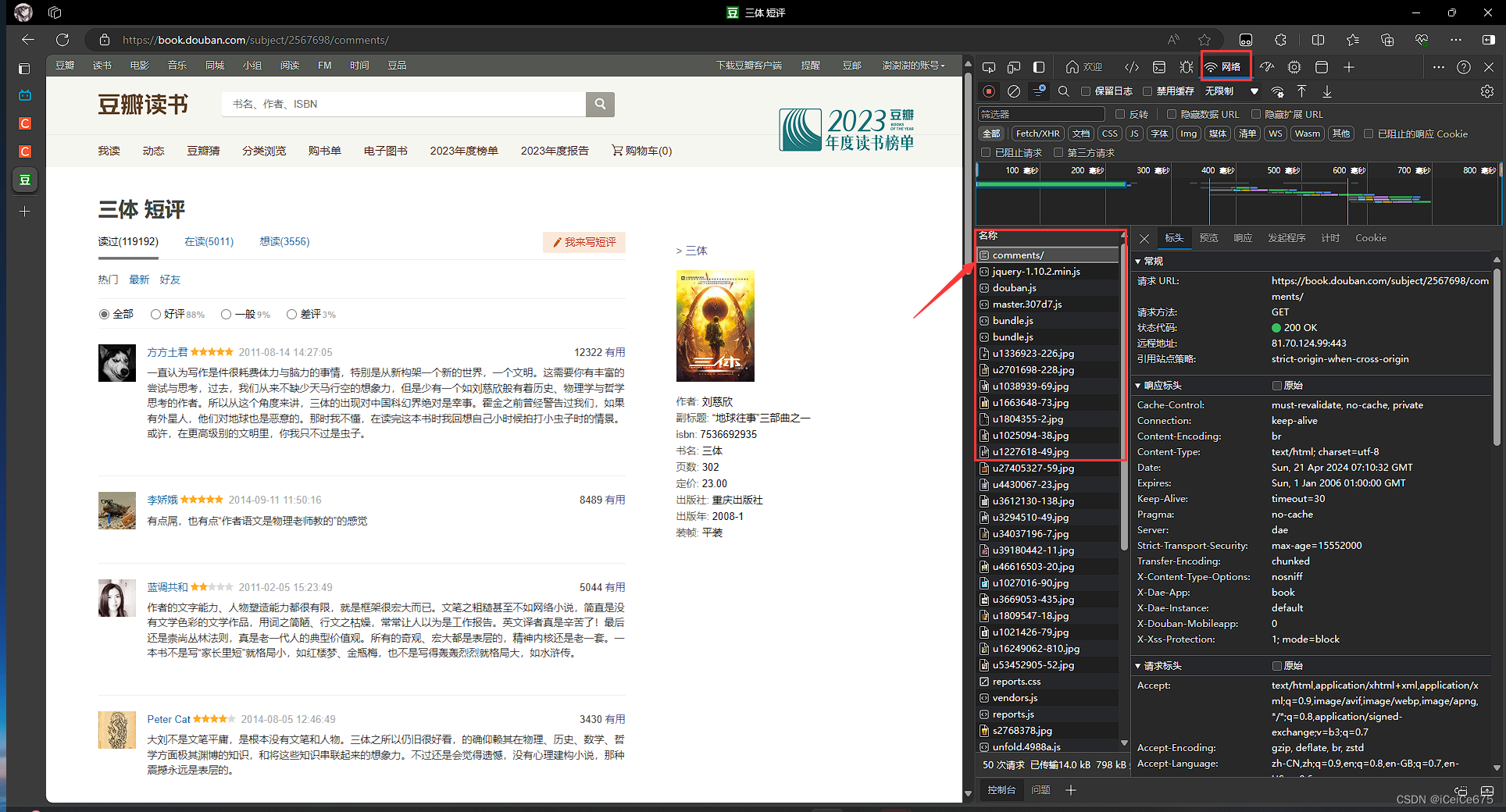
- 查看cookie与User-Agent

- 这样我们就可以定义我们的
headers了db_headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0" \ ,'cookie':'bid=uQtf0......27093'} - 查看前后页,发现网址中的start对应第几个评论开始,sort后对应按热度(score)还是按时间(time)排序(当然 subject 后的数字就对应哪本书了,修改此数字即可分析你感兴趣的书)

不难想到利用format格式化表示网址f"https://book.douban.com/subject/2567698/comments/?start={i*20}&limit=20&status=P&sort=score"
获取评论
分析html结构,定义函数
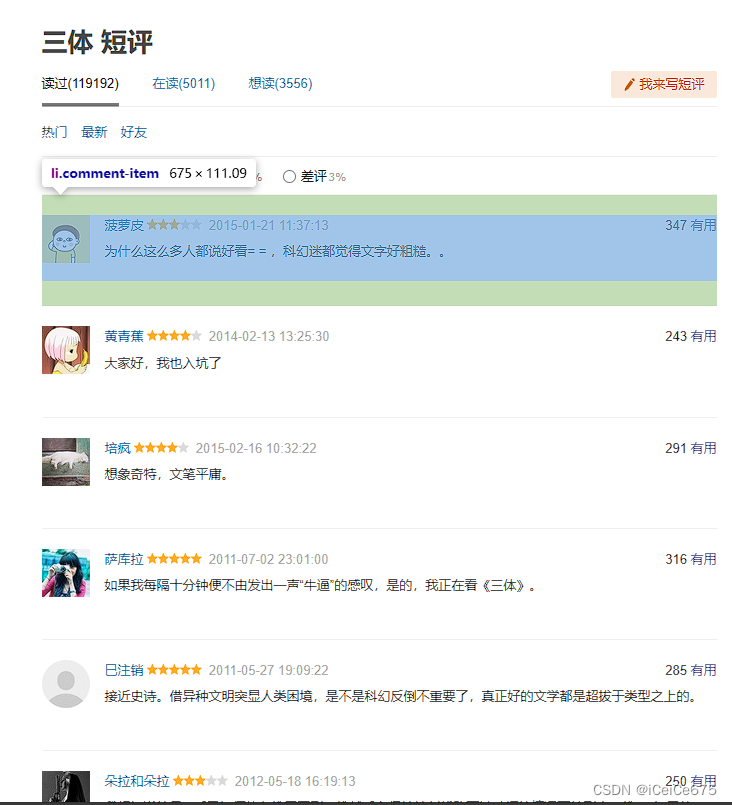
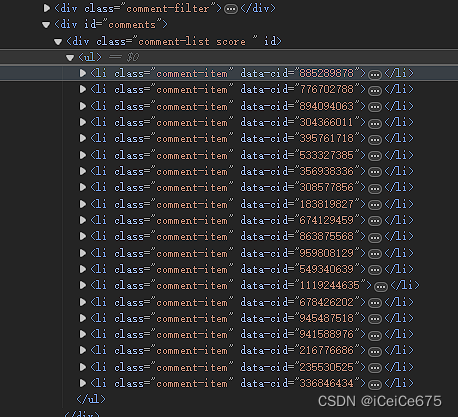
可以看到评论列表位于 class_ 为 “comment-item” 的 div 标签下
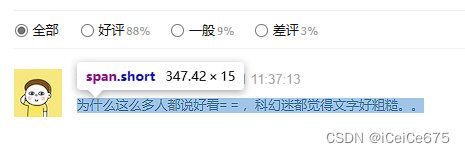
继续查看 li 标签,发现评论在 class_ 为 “short” 的 span 标签下,调用 string 属性即可获取

def get_pg_html(url, head):
"""返回短评html"""
try:
r = requests.get(url, headers=head)
r.raise_for_status()
return r
except:
print(url+"抓取失败!")
return None
def get_comments(html):
"""根据该页html返回该页评论列表"""
soup = BeautifulSoup(html.text, 'html.parser')
com_li_lst = soup.body.find_all(class_="comment-item") #返回评论li列表
return [li.find(class_="short").string for li in com_li_lst] #返回评论内容
爬取评论
comments = []
for i in range(15): #提取最热300条
url = f"https://book.douban.com/subject/2567698/comments/?start={i*20}&limit=20&status=P&sort=score"
html = get_pg_html(url, db_headers)
comments.extend(get_comments(html)) #追加到列表
for i in range(5): #提取最新100条
url = f"https://book.douban.com/subject/2567698/comments/?start={i*20}&limit=20&status=P&sort=time"
html = get_pg_html(url, db_headers)
comments.extend(get_comments(html)) #追加到列表
print(len(comments))
comments[-20:]
out:
400
['物理的尽头是数学,数学的尽头是哲学,哲学的尽头是神学。',
'三体的开头,铺垫得有点无聊,也可能是因为有点深奥吧,差点看不下去了,不过看了后面两本,觉得这一本的铺垫很重要。',
'“也许,人类和邪恶的关系,就是大洋与漂浮于其上的冰山的关系,它们其实是同一种物质组成的巨大水体,冰山之所以被醒目地认出来,只是由于其形态不同而已,而它实质上只不过是这整个巨大水体中极小的一部分……人类真正的道德自觉是不可能的,就像他们不可能拔着自己的头发离开大地。要做到这一点,只有借助于人类之外的力量”。',
'除了一两个闪光点,整体被虚吹神化到无以复加。Netflix的改编成就了这本庸作。',
'谁懂啊我读完第一部真的以为自己看了1/3结果发现页数对不上…',
'去魅了。在我这两星半,就算是陈述物理学天文学也不该是这么硬邦邦的枯燥,生活大爆炸每集都有物理学科普,虽然也无聊但不会让人想跳过,这里叙述太大片了,但批斗那里说的不错,三体人想象确实有创意,还差两篇结尾没看完',
'大框架不错,冲着侦探部分去的,里面的物理理论完全没看懂😂',
'相较于三本书,最喜欢第一本,徐徐道来的故事把人逐渐的引入科学,让物理小白也可以深陷其中。',
'想象力还可以,主要在于物理知识。文笔很一般,毫无美感,对人物的刻画也干瘪,简直不如武侠小说。有点太宏观,忽视了个体人,纯写物理技术,没写出人的血肉。',
'“在中国,任何超脱飞扬的思想都会砰然坠地的,现实的引力太沉重了。”\n相信在这种环境下,如果我是叶文洁,我也会发出那条信息。',
'一分减在男凝',
'想象力丰富得叹为观止',
'慕名而来但是真觉得描写水平太差了 人文含量超低 说话土土的 故而多么厉害的设定在当下这个故事爆炸的时代 也都没什么了(纯个人感受)没有办法把一件事情写好 再厉害的世界观 上线也就到那了。',
'补标',
'感觉像维伦纽瓦沙丘1一样,整本书像是一个大型预告',
'👍🏻',
'看完剧补一下,只能说还行吧。网飞的改编帮忙提升了很多',
'第二遍读了,真的很好',
'相比起其他,三体一更像是一个巨大的背景介绍\n介绍三体的恶劣环境\n介绍三体前往地球的初衷\n介绍地球人即将面临的危机\n从“物理学不存在”到“智子锁死的科学”,再到“我们都是虫子”的认知\n开头的悬疑恐怖感挺足的\n眼前的倒计时让人身临其境地觉得可怕\nps.喜欢史强和叶文洁,不同类型的智慧人',
'宇宙苍穹映射出人类的悲喜和无知,他们自以为是的以为,整个宇宙都在为他们闪耀。\n\n大刘的笔,大史的晚,淼淼的眼睛,叶文洁的超然,杨卫宁的牺牲,罗辑的天才脑袋…等等等等,谢谢你们在一段时间带我遨游宇宙,更深刻的看待人生起伏,学会变幻无常的道理。']
文本预处理
#文本预处理
rule = lambda s:len(set(s))/len(s)>0.5 #规则:重复字不超过一半
pure_comments = [c for c in filter(rule, comments)] #提取有效评论
print(f"有效评论数:{len(pure_comments)}")
jieba_lst = []
sign = """!@#$%^&*()_+-=[]{};':",./<>?|\\:“”《》?【】;’、,。!…\n\t """
for comment in comments:
for ch in sign:
comment = comment.replace(ch,"") #删去无用字符
jieba_lst.extend(psg.lcut(comment)) #获取分词
out:
有效评论数:396
print(len(jieba_lst))
jieba_lst[:20]
out:
13730
[pair('一直', 'd'),
pair('认为', 'v'),
pair('写作', 'v'),
pair('是', 'v'),
pair('件', 'q'),
pair('很', 'd'),
pair('耗费', 'v'),
pair('体力', 'n'),
pair('与', 'p'),
pair('脑力', 'n'),
pair('的', 'uj'),
pair('事情', 'n'),
pair('特别', 'd'),
pair('是从', 'v'),
pair('新', 'a'),
pair('构架', 'n'),
pair('一个', 'm'),
pair('新', 'a'),
pair('的', 'uj'),
pair('世界', 'n')]
关于 jieba 库的词性可参考以下文章:
Python——jieba优秀的中文分词库(基础知识+实例)

接下来选择我们需要的词,并大致查看出现次数
#提取关键词
vital_words = [w.word for w in jieba_lst if w.flag in ('a','i','l','n','nr','ns','nt','nz')]
text = " ".join(vital_words) #组合
ndic = dict(Counter(vital_words))
heapq.nlargest(20, ndic.items(), key=lambda x:x[1])
out:
[('三体', 100),
('科幻', 95),
('人', 81),
('人类', 75),
('文笔', 66),
('文明', 63),
('大', 56),
('故事', 51),
('宇宙', 50),
('世界', 40),
('感觉', 39),
('人物', 39),
('好', 39),
('叶文洁', 39),
('小说', 38),
('作者', 37),
('物理', 33),
('中国', 32),
('想象力', 31),
('游戏', 29)]
生成词云图
#词云图
wc = WordCloud(width=600, height=600, max_font_size=150, min_font_size=5, max_words=40,background_color='white',\
font_path=r"C:\Users\...\SmileySans-Oblique.ttf") #创建词云对象
wc_img = wc.generate(text)
plt.imshow(wc_img)
out:
<matplotlib.image.AxesImage at 0x21ef0723fd0>

关于 WordCloud ,可以了解以下文章:
python词云 wordcloud库详细使用教程
wordcloud词云图美化

















 6355
6355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









