







最近在学习python爬虫系列课程,也在学习写一些程序实例,这篇文章是爬取豆瓣图书的前250本数的名称和其他信息。
前期准备
1.安装适合的python编辑器,本人使用的是Anaconda中的Jupyter Notebook,因为便于编写和管理python的各种第三方库,所以推荐大家也使用。下载地址为:https://www.anaconda.com/download/
2.本文章要使用python库中的requests和BeautifulSoup4库爬取网页和解析网页。因为不是python自带的标准库,所以要手动安装以上两个库。
- requests库下载地址:https://pypi.python.org/pypi/requests/
- Beautiful Soup4库下载地址:https://pypi.python.org/pypi/beautifulsoup
3.用pip安装以上两个库,Win+R打开输入cmd, 输入如下:
pip install requestspip install beautifulsoup4网页分析
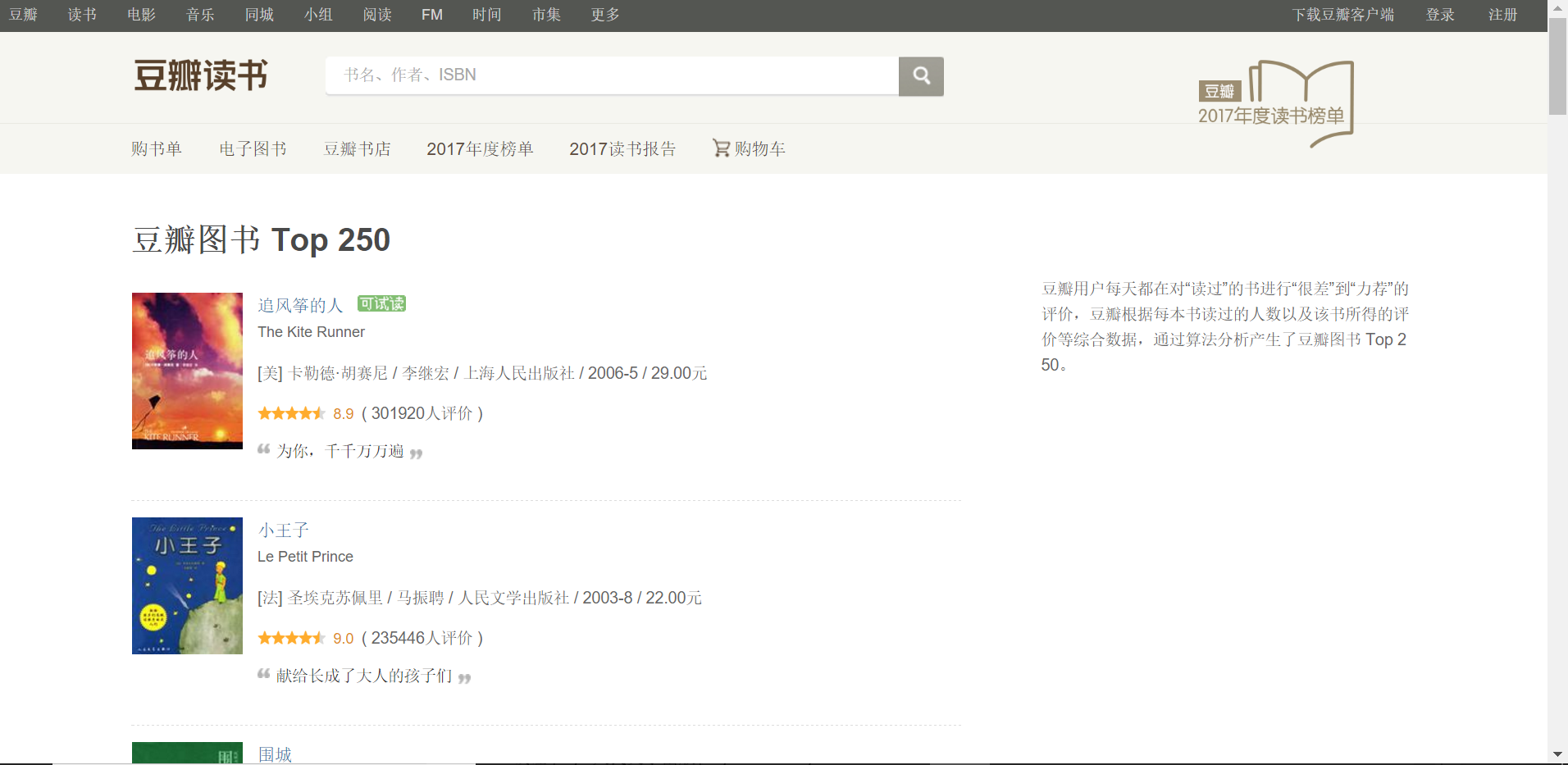
下面我们开始我们的爬虫程序主体,我们将要访问的是豆瓣图书的前250榜单的书名和其他信息
https://book.douban.com/top250?
如下图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









