






在写最短路径的时候,看见了需要运用链式前向星的题目;
理解
链式前向星是通过结构体把各个数据连接起来,可以有效减少数据查找的时间,需要引用一个head【】数组,此数组的意义相当于指示标,其数组的下标表示的是需要查找的起始节点,然后又要引入一个结构体,里面包括终止节点和此节点有相同起始节点的下标,所查找的节点的边长,用表格来表示head和结构体就是如下:
| 结构体数组 | 1 | 2 | 3 | 4 | 5 |
| next(to的好兄弟) | 0 | 0 | 0 | 0 | 0 |
| to(所查找起始节点的终止节点 | |||||
| wei(边长) |
| head | 1 | 2 | 3 | 4 | 5 |
| 结构体数组的下标 |
举一个例子,如果要输入{(1,2,1),(1,3,2),(1,4,2),(2,3,5)}这么一组数据进入上面的表格中;
首先因为head的下标是代表上面结构体数组的下标那么输入(1,2,1)之后,表格中的数据应该是这样的:
| 结构体数组 | 1 | 2 | 3 | 4 | 5 |
| next(to的好兄弟) | 0 | 0 | 0 | 0 | 0 |
| to(所查找起始节点的终止节点 | 2 | ||||
| wei(边长) | 1 |
| head | 1 | 2 | 3 | 4 | 5 |
| 结构体数组的下标 | 1 |
此时上面表格里的意思就是(先看head,再看结构体数组):和节点一有关系的点要从结构体数组的1号里面去找,那么可以找到to 里面的节点是2,可以知道2和节点1相连接且边长为1,然后再看next,看to有没有兄弟,发现是0,那就是和节点1有关的只有节点2;
然后再把(1,3,2)输入进表格:
| 结构体数组 | 1 | 2 | 3 | 4 | 5 |
| next(to的好兄弟) | 0 | 1 | 0 | 0 | 0 |
| to(所查找起始节点的终止节点 | 2 | 3 | |||
| wei(边长) | 1 | 2 |
| head | 1 | 2 | 3 | 4 | 5 |
| 结构体数组的下标 | 2 |
此时发现第二个输入进去的数据还是关于节点1 的数据,此时表格中的变化规律和第一个差不多,只是next变成了1,还有head[1]变成了2,这就说明我们再去找节点1 的时候要从结构体数组的第二位开始找,那么此时可以找到节点3是和节点1有关系的,那么再看next变成了1,就说明在结构体数组的一号位置还有它的兄弟,那么就查找结构体数组的一号位置,又可以找到节点2。
那么将所有的数据都放入表格后,是这个样子:
| 结构体数组 | 1 | 2 | 3 | 4 | 5 |
| next(to的好兄弟) | 0 | 1 | 2 | 0 | 0 |
| to(所查找起始节点的终止节点 | 2 | 3 | 4 | 3 | |
| wei(边长) | 1 | 2 | 2 | 5 |
| head | 1 | 2 | 3 | 4 | 5 |
| 结构体数组的下标 | 3 | 4 |
代码实现
struct
{
int t;
int next;
int wei;
}e[num];
//核心代码
void dep(int v1,int v2,int wei)
{
e[++cnt].t = v2;
e[cnt].next = head[v1];
e[cnt].wei = wei;
head[v1] = cnt;
}
//和dijsktra的结合
void L_dij(int n)
{
int min;
while(book[pos]==0)
{
min = inf;
book[pos] = 1;
for(int i=head[pos];i!=0;i=e[i].next)
{
if(book[e[i].t]==0 && dis[e[i].t]>dis[pos]+e[i].wei)
dis[e[i].t] = dis[pos]+e[i].wei;
}
for(int k=1;k<=n;k++)
{
if(book[k]==0 && dis[k]<min)
{
min = dis[k];
pos = k;
}
}
}
}例题
# 【模板】单源最短路径(弱化版)
## 题目背景
本题测试数据为随机数据,在考试中可能会出现构造数据让SPFA不通过,如有需要请移步 [P4779](https://www.luogu.org/problemnew/show/P4779)。
## 题目描述
如题,给出一个有向图,请输出从某一点出发到所有点的最短路径长度。
## 输入格式
第一行包含三个整数 $n,m,s$,分别表示点的个数、有向边的个数、出发点的编号。
接下来 $m$ 行每行包含三个整数 $u,v,w$,表示一条 $u \to v$ 的,长度为 $w$ 的边。
## 输出格式
输出一行 $n$ 个整数,第 $i$ 个表示 $s$ 到第 $i$ 个点的最短路径,若不能到达则输出 $2^{31}-1$。
## 样例 #1
### 样例输入 #1
```
4 6 1
1 2 2
2 3 2
2 4 1
1 3 5
3 4 3
1 4 4
```
### 样例输出 #1
```
0 2 4 3
```
## 提示
【数据范围】
对于 $20\%$ 的数据:$1\le n \le 5$,$1\le m \le 15$;
对于 $40\%$ 的数据:$1\le n \le 100$,$1\le m \le 10^4$;
对于 $70\%$ 的数据:$1\le n \le 1000$,$1\le m \le 10^5$;
对于 $100\%$ 的数据:$1 \le n \le 10^4$,$1\le m \le 5\times 10^5$,$1\le u,v\le n$,$w\ge 0$,$\sum w< 2^{31}$,保证数据随机。
**Update 2022/07/29:两个点之间可能有多条边,敬请注意。**
对于真正 $100\%$ 的数据,请移步 [P4779](https://www.luogu.org/problemnew/show/P4779)。请注意,该题与本题数据范围略有不同。
样例说明:
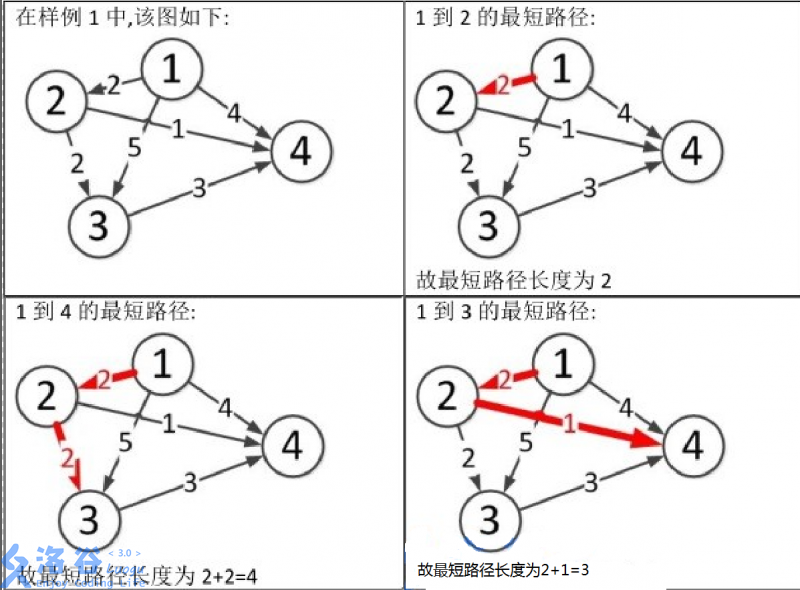
图片1到3和1到4的文字位置调换
代码
#include<stdio.h>
#define num 1001000
int cnt,book[num],dis[num],head[num];
int inf=2147483647;
int pos;
struct
{
int t;
int next;
int wei;
}e[num];
void initia(int n)
{
cnt=0;
for(int i=1;i<=n;i++)
{
book[i]=0;
dis[i]=inf;
head[i]=0;
}
dis[pos]=0;
}
void dep(int v1,int v2,int wei)
{
e[++cnt].t = v2;
e[cnt].next = head[v1];
e[cnt].wei = wei;
head[v1] = cnt;
}
void L_dij(int n)
{
int min;
while(book[pos]==0)
{
min = inf;
book[pos] = 1;
for(int i=head[pos];i!=0;i=e[i].next)
{
if(book[e[i].t]==0 && dis[e[i].t]>dis[pos]+e[i].wei)
dis[e[i].t] = dis[pos]+e[i].wei;
}
for(int k=1;k<=n;k++)
{
if(book[k]==0 && dis[k]<min)
{
min = dis[k];
pos = k;
}
}
}
}
int main()
{
int n,m,s;
scanf("%d%d%d",&n,&m,&s);
pos=s;
initia(m);
for(int i=1;i<=m;i++)
{
int x,y,z;
scanf("%d%d%d",&x,&y,&z);
dep(x,y,z);
}
L_dij(n);
for(int i=1;i<=n;i++)
printf("%d ",dis[i]);
printf("\n");
return 0;
}
















 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









