






一、模型
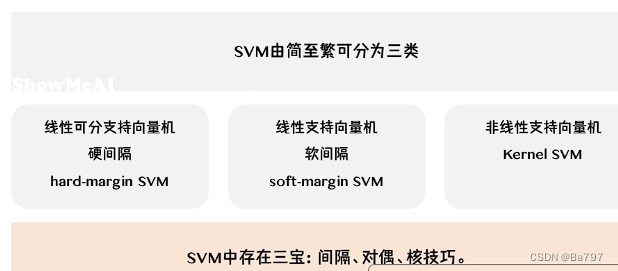
1、线性可分支持向量机:
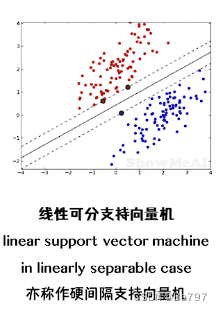
线性可分支持向量机是一种机器学习算法,用于解决二分类问题。它假设训练数据是线性可分的,即存在一个超平面能够完全将正例和负例分开。
该算法通过硬间隔最大化的原则来学习一个线性分类器,也被称为硬间隔支持向量机。硬间隔是指在两个不同类别的样本之间存在一个最大的间隔,该间隔能够尽可能地将两个类别的样本分开。
具体来说,线性可分支持向量机的目标是找到一个超平面,使得所有的正例样本都位于超平面的一侧,而负例样本位于另一侧,并且使得这个超平面到最近的正例样本和负例样本的距离(即间隔)最大化。
在训练过程中,支持向量机通过优化一个目标函数来找到最佳的超平面。目标函数的优化过程可以通过凸优化方法(如二次规划)来实现。通过求解这个优化问题,可以得到一个线性分类器,该分类器可以将新的样本点分配到不同的类别。
支持向量机的名称来源于在训练过程中,只有少数的样本点被选为支持向量,它们对于确定超平面起到关键作用。这些支持向量位于超平面距离最近的样本点上,它们决定了最终分类器的边界。
总结而言,线性可分支持向量机是一种通过硬间隔最大化来学习线性分类器的算法。它利用支持向量和最大间隔的原则,能够有效地处理线性可分的二分类问题。
2、线性支持向量机:
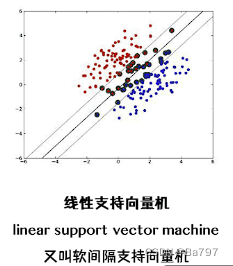
线性支持向量机是一种机器学习算法,用于解决二分类问题。与线性可分支持向量机相比,线性支持向量机允许训练数据在一定程度上近似线性可分,即存在一些分类错误的样本点或存在一些重叠的情况。
该算法通过软间隔最大化的原则来学习一个线性分类器,也被称为软间隔支持向量机。软间隔是指在考虑分类错误的情况下,尽可能地将不同类别的样本分开,并且使得分类错误和间隔之间达到一个平衡。
在训练过程中,线性支持向量机的目标是找到一个超平面,使得大多数样本点位于超平面的一侧,并且尽量减少分类错误和间隔之间的冲突。为了实现这一点,算法引入了一个惩罚项,用于衡量分类错误的程度。这个惩罚项可以是正则化项或者松弛变量。
通过优化一个目标函数,线性支持向量机尝试找到最佳的超平面,使得分类错误和间隔之间的总和最小化。目标函数的优化过程可以使用凸优化方法(如二次规划)来求解。
与线性可分支持向量机类似,线性支持向量机在训练过程中也会选择一些样本点作为支持向量,它们对于确定超平面起到关键作用。这些支持向量位于超平面附近,它们决定了最终分类器的边界。
总结而言,线性支持向量机是一种通过软间隔最大化来学习线性分类器的算法。它可以处理训练数据近似线性可分的情况,并且通过平衡分类错误和间隔,找到一个更加鲁棒的分类器。
3、非线性支持向量机
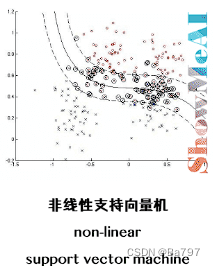
非线性支持向量机是一种机器学习算法,用于解决训练数据线性不可分的二分类问题。在这种情况下,无法通过直接的线性超平面来完全分开不同类别的样本。
为了处理这种情况,非线性支持向量机引入了核技巧(kernel trick)。核技巧是一种通过将输入特征映射到高维特征空间,从而使得原本线性不可分的问题在高维空间中变得线性可分的方法。
具体来说,非线性支持向量机通过定义一个核函数,该核函数能够计算两个样本在高维特征空间中的相似度。常用的核函数包括线性核、多项式核、高斯核等。这些核函数的选择取决于数据的特点和问题的需求。
在训练过程中,非线性支持向量机通过软间隔最大化的原则来学习一个非线性分类器。它尝试找到一个在高维特征空间中的超平面,使得大多数样本点位于超平面的一侧,并且尽量减少分类错误和间隔之间的冲突。优化目标函数的过程与线性支持向量机类似,可以使用凸优化方法进行求解。
通过核技巧,非线性支持向量机能够处理原本线性不可分的问题。它将样本映射到高维特征空间中,利用核函数计算样本之间的相似度,从而在高维空间中找到一个线性可分的超平面。这样,非线性支持向量机可以学习一个非线性的分类器,能够更好地处理复杂的数据分布。
总结而言,非线性支持向量机是一种通过使用核技巧和软间隔最大化来学习非线性分类器的算法。它能够处理训练数据线性不可分的情况,并通过将数据映射到高维特征空间中来解决这个问题。这使得非线性支持向量机在处理复杂数据分布时具有较强的表达能力。
可以参考这一篇【机器学习】支持向量机(4)——非线性支持向量机(核函数)_支持向量机非线性分类-CSDN博客![]() https://blog.csdn.net/Daycym/article/details/81290808
https://blog.csdn.net/Daycym/article/details/81290808
二、最大间隔分类器
1、分类问题与线性模型
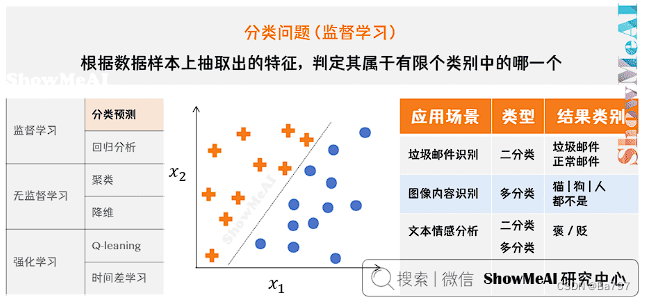

2、最大间隔分类器
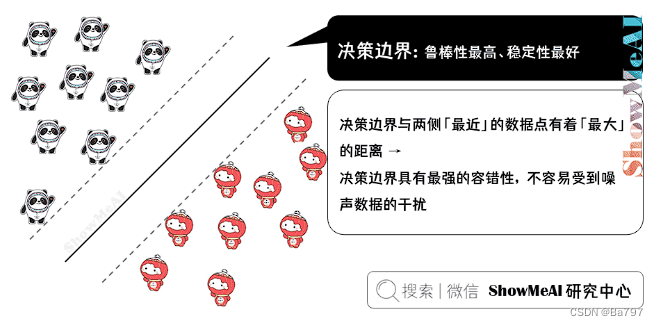
这个决策边界与两侧「最近」的数据点有着「最大」的距离,这意味着决策边界具有最强的容错性,不容易受到噪声数据的干扰。直观的理解就是,如果决策边界抖动,最不容易「撞上」样本点或者进而导致误判。
三、支持向量机详解
具体参考,本文内的全部图片均来自此
系列教程 (showmeai.tech)![]() https://www.showmeai.tech/tutorials/34?articleId=196
https://www.showmeai.tech/tutorials/34?articleId=196
四、总结
1、模型总结
支持向量机(Support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,他的学习策略就是间隔最大化,同时该方法可以形式化为一个求解图二次规划。
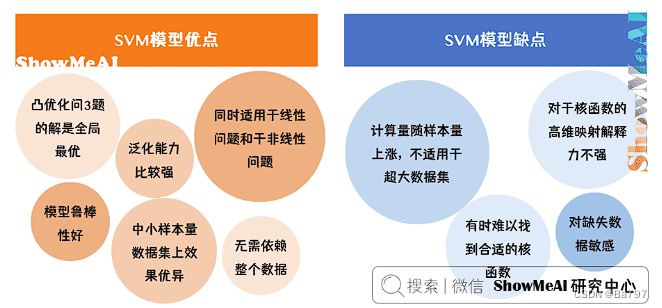
2、模型优缺点
3、基于python的代码解释
不同的核函数需要指定不同的参数。
-
针对线性函数,只需要指定参数 c,它表示对不符合最大间距规则的样本的惩罚力度。
-
针对多项式核函数,除了参数c 外,还需要指定degree,它表示多项式的阶数。
-
针对高斯核函数,除了参数 c外,还需要指定gamma值,这个值对应的是高斯函数公式中的值
(1)使用线性核函数
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
iris = datasets.load_iris()
X = iris.data[:, :2] #只取前两维特征,方便可视化
y = iris.target
svc = svm.SVC(kernel='linear', C=1).fit(X, y)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min) / 100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
plt.subplot(1, 1, 1)
Z = svc.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
plt.show()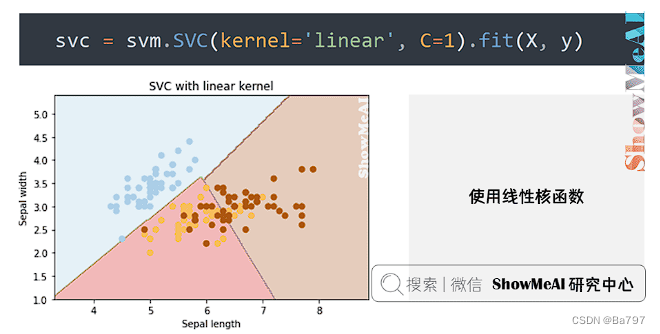
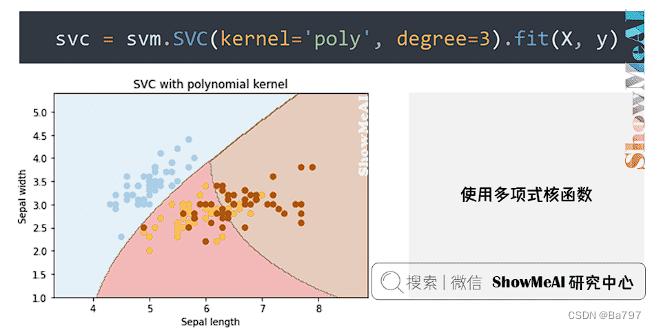
(2)使用多项式核函数
初始化 SVM 对象的代码替换为下面这行
svc = svm.SVC(kernel='poly', degree=3).fit(X, y)
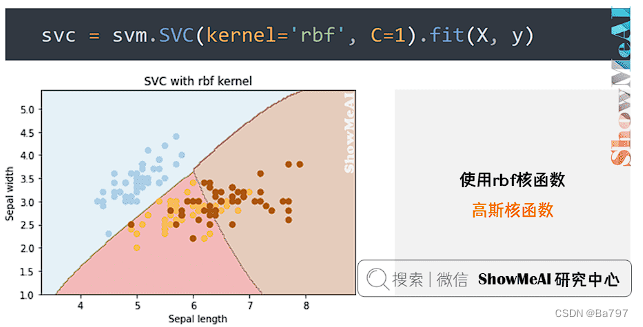
(3)使用高斯核函数
初始化 SVM 对象的代码替换为下面这行
svc = svm.SVC(kernel='rbf', C=1).fit(X, y)
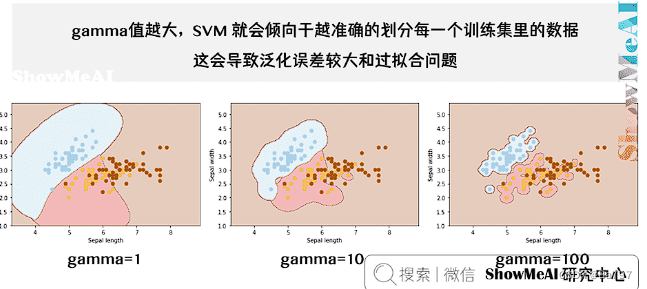
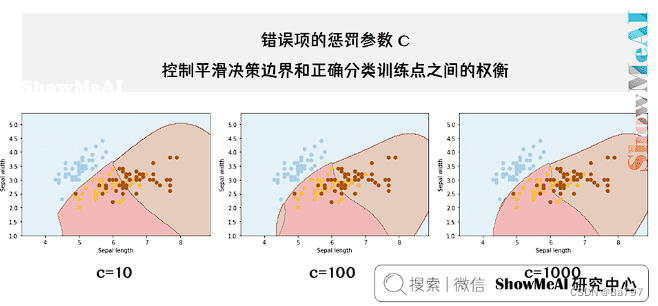
新人小白借此来巩固一下,链接都在文中,请佬们自行查看各种让人头大的公式
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









