






残差神经网络
原论文:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
一、何为残差?
残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。“残差”蕴含了有关模型基本假设的重要信息。如果回归模型正确的话, 我们可以将残差看作误差的观测值。
更准确地,假设我们想要找一个 𝑥,使得 f(x)=b,给定一个 x𝑥的估计值 x0,残差(residual)就是 b−f(x0),同时,误差就是 x−x0。即使 x𝑥不知道,我们仍然可以计算残差,只是不能计算误差罢了。
二、何为残差神经网络?
残差神经网络(Residual Neural Network,简称ResNet)是一种特殊的深度学习模型,它通过引入残差连接来解决深度神经网络训练中的梯度消失或梯度爆炸问题。残差连接允许网络中的信息直接传播到更深的层,从而使得网络能够更容易地学习和训练。
1、为什么不使用传统深度卷积网络而改用残差神经网络?
理论上,增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时可以取得更好的结果。但VGG、GoogLeNet等网络单纯增加层数遇到了一些瓶颈:简单增加卷积层,训练误差不但没有降低,反而越来越高。在CIFAR-10、ImageNet等数据集上,单纯叠加3×3卷积,何恺明等人发现,训练和测试误差都变大了。
而且理论上,可以训练一个 shallower 网络,然后在这个训练好的 shallower 网络上堆几层 identity mapping(恒等映射------“什么都不学习”,学术上被称为恒等映射(Identity Mapping),用数学表达式表示为:H(x)=x。其中,H(x)是我们希望拟合的一个网络结构,或者说是一种映射关系) 的层,即输出等于输入的层,构建出一个 deeper 网络。这两个网络(shallower 和 deeper)得到的结果应该是一模一样的,因为堆上去的层都是 identity mapping。这样可以得出一个结论:理论上,在训练集上,**Deeper 不应该比 shallower 差,即越深的网络不会比浅层的网络效果差。但为什么会出现图 1 这样的情况呢,随着层数的增多,训练集上的效果变差?这被称为退化问题(degradation problem)。
理论上,越深的网络,效果应该更好;但实际上,由于训练难度,过深的网络会产生退化问题,效果反而不如相对较浅的网络。这主要是因为深层网络存在着梯度消失或者爆炸的问题,模型层数越多,越难训练。如下图所示
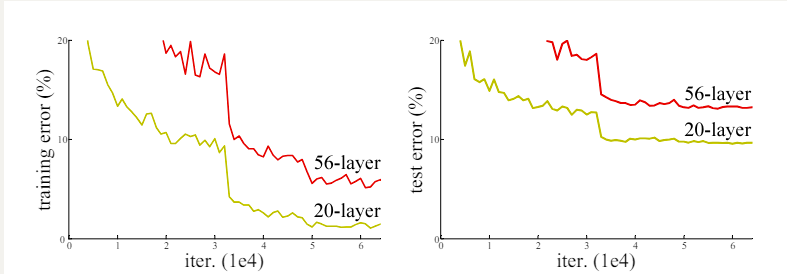
ResNet通过引入残差块(Residual Block)来解决这个问题。残差块允许输入直接跳过一些层,从而使得梯度能够更有效地传播。残差网络越深,训练集上的效果会越好。(测试集上的效果可能涉及过拟合问题。过拟合问题指的是测试集上的效果和训练集上的效果之间有差距。)
2、残差块—Basic
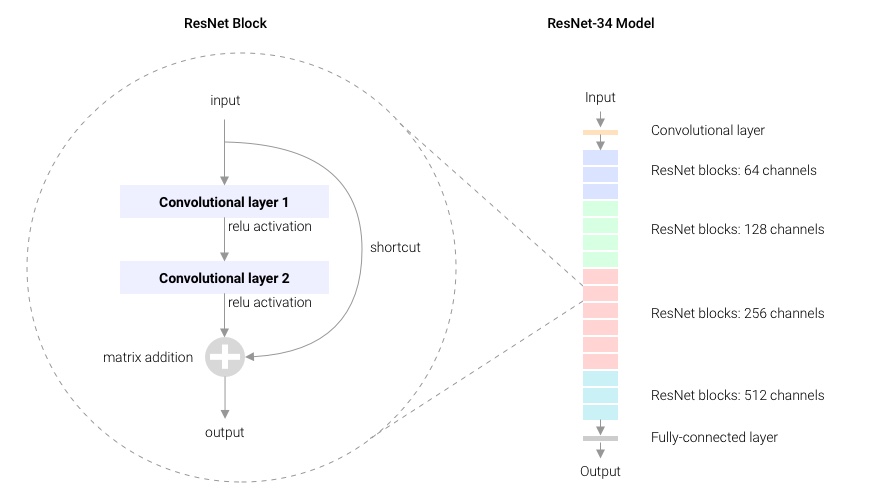
残差网络通过加入 shortcut connections,变得更加容易被优化。包含一个 shortcut connection 的几层网络被称为一个残差块(residual block),如图 2 所示。(shortcut connection,即图 2右侧从 𝑥 到 ⨁ 的箭头)
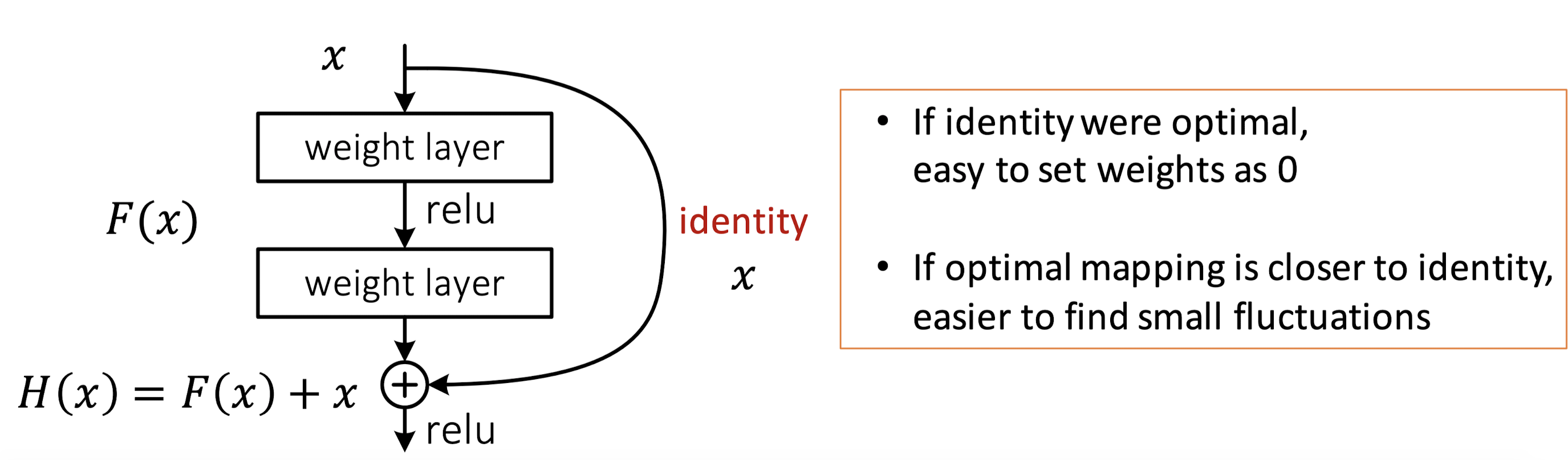
如图 2所示,x𝑥表示输入,F(x)表示残差块在第二层激活函数之前的输出,即 F(x)=W2σ(W1x),其中 W1和 W2表示第一层和第二层的权重,σ表示 ReLU 激活函数。(这里省略了 bias(偏差))最后残差块的输出是 σ(H(x))。
当没有 shortcut connection(即图 右侧从 x到 ⨁的箭头)时,残差块就是一个普通的 2 层网络。残差块中的网络可以是全连接层,也可以是卷积层。设第二层网络在激活函数之前的输出为 H(x)。如果在该 2 层网络中,最优的输出就是输入 x,那么对于没有 shortcut connection 的网络,就需要将其优化成 H(x)=x;对于有 shortcut connection 的网络,即残差块,如果最优输出是 x,则只需要将 F(x)=H(x)−x 优化为 0 即可。后者的优化会比前者简单。这也是残差这一叫法的由来。
3、另一种残差块 —Bottleneck
ResNet-34核心部分均使用3×3卷积层,总层数相对没那么多,对于更深的网络,作者们提出了另一种残差基础块。下图左侧为ResNet-34所使用的残差基础块,被成为Basic Block;右侧为ResNet-50/101/152等深层网络上使用的残差基础块,被称为Bottleneck Block,Bottleneck Block中使用了1×1卷积层。如输入通道数为256,1×1卷积层会将通道数先降为64,经过3×3卷积层后,再将通道数升为256。1×1卷积层的优势是在更深的网络中,用较小的参数量处理通道数很大的输入。
左侧输入输出通道数均为64,残差基础块中两个3×3卷积层参数量是:$ 3 \times 3 \times 64 \times 64 + 3 \times 3 \times 64 \times 64 = 73728$右侧,输入输出通道数均为256
残差基础块中的参数量是:
1
×
1
×
64
×
256
+
3
×
3
×
64
×
64
+
1
×
1
×
64
×
256
=
69632
1 \times 1 \times 64 \times 256 + 3 \times 3 \times 64 \times 64 + 1 \times 1 \times 64 \times 256 = 69632
1×1×64×256+3×3×64×64+1×1×64×256=69632。两个一比较,使用1×1卷积层,参数量减少了。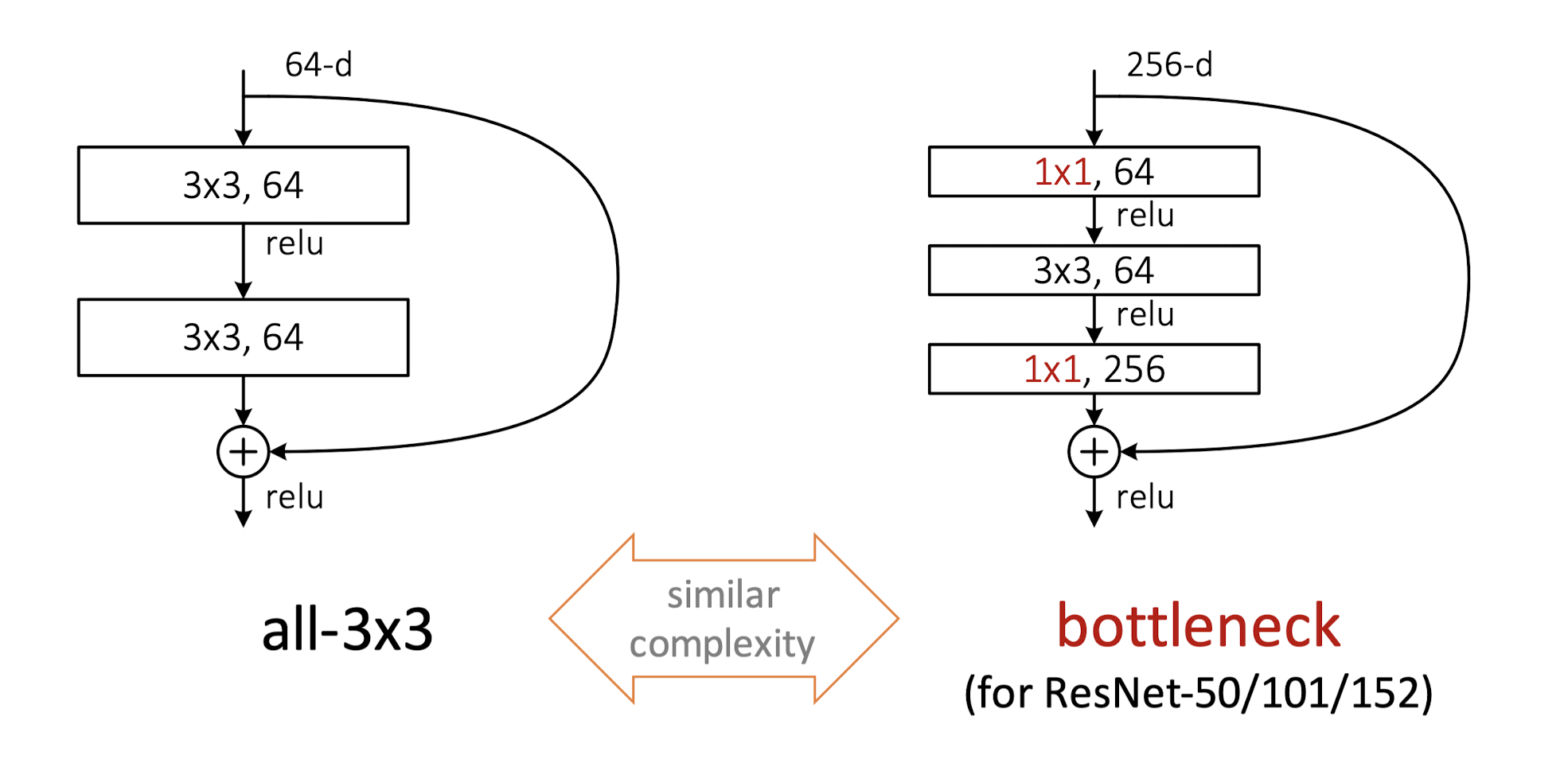
三、ResNet-34
基于残差基础块,我们可以构建ResNet网络,论文中给出了基于ImageNet数据集的ResNet-34和VGG-19的对比图。最左侧是VGG-19,中间是只使用3×3卷积层的Plain Network(没有使用Shortcut),右侧是使用了Shortcut的ResNet-34。ResNet-34除了第一层是7×7卷积层、最后一层是全连接层外,中间全是3×3卷积层。
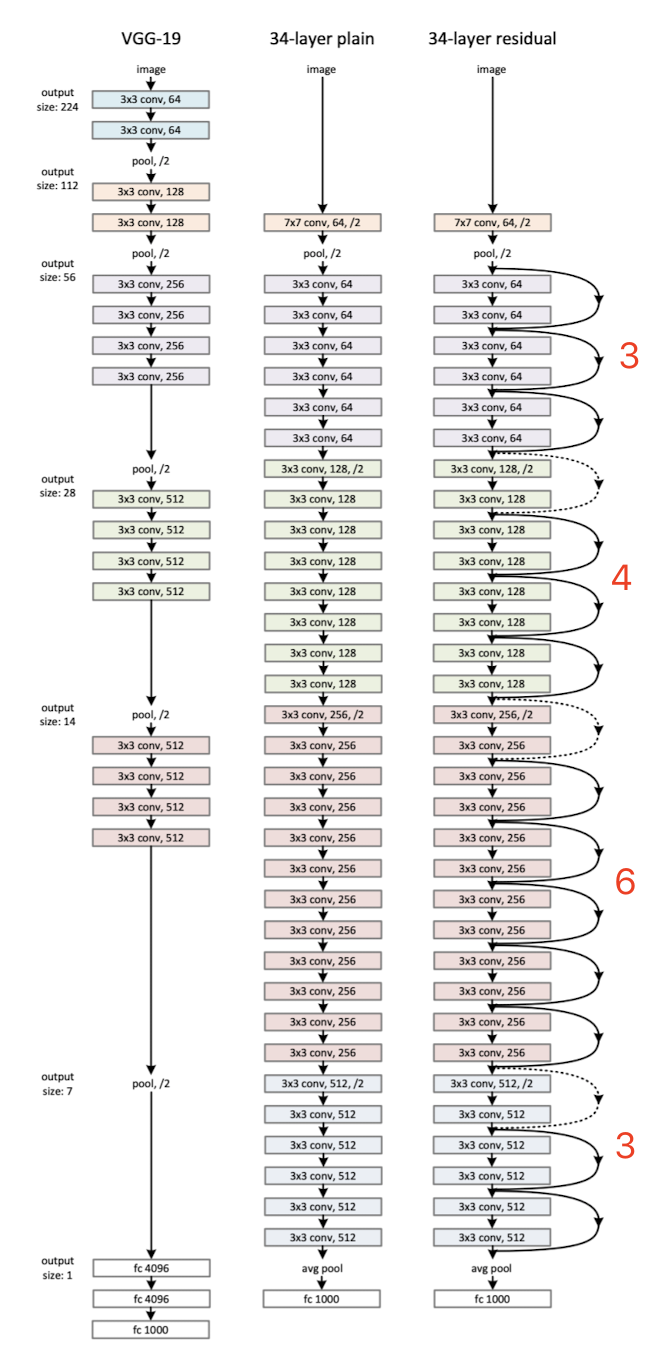
最右侧是ResNet-34,命名为ResNet-34,是因为网络中7×7卷积层、3×3卷积层和全连接层共34层。在计算这个34层时,论文作者并没有将BatchNorm、ReLU、AvgPool以及Shortcut中的层考虑进去。图4右侧ResNet-34中的3×3卷积层的颜色不同,共4种颜色。每种颜色表示一个模块,由一组残差基础块组成,只不过残差基础块的数量不同,从上到下依次是[3, 4, 6, 3]个残差基础块。另外,图4右侧,残差基础块中用实线Shortcut表示维度没有变化(可以直接相加);虚线Shortcut表示维度变化了,比如通道数从64变为128,无法直接相加,或者在xxx上填充0,或者使用1×1卷积层改变维度。下图解释更为直观
四、ResNet家族
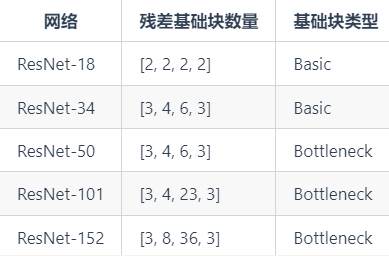
如果改变ResNet-34中残差基础块的数量[3, 4, 6, 3],可以组合出几种不同的网络,共同构成了ResNet家族。下表为各个网络的信息。以最常用来作为各类Benchmark的ResNet-50为例,残差基础块的数量为:3 + 4 + 6 + 3 = 16,每个残差基础块都使用Bottleneck,Bottleneck里共3个卷积层(2个1×1卷积层+1个3×3卷积层),16 × 3 = 48,加上一开始的7×7卷积层和最后的全连接层,共50层。
pre-activation
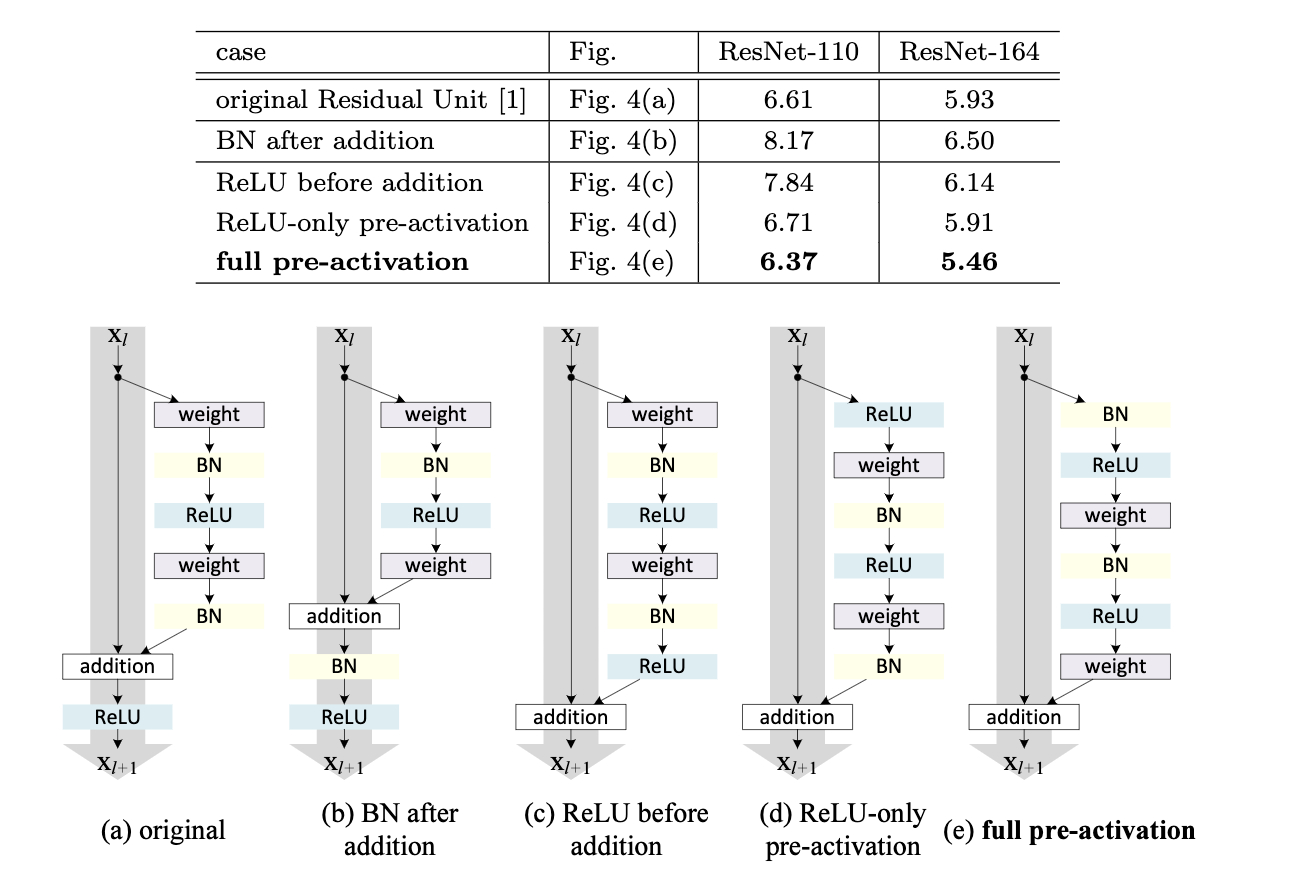
对BatchNorm、ReLU和卷积层的位置进行调整。图中a/b/c/d/e是几种残差基础块的构成方式,这几种残差块包含的模块是一样的,都是权重层(卷积层)、BN(BatchNorm)、ReLU以及加法运算。根据作者们的证明和分析,图7中的e能获得很大的收益,在CIFAR-10上的表现最好(图7上半部分的表格为CIFAR-10上的表现)。图中e先进行BatchNorm和ReLU,再进行卷积运算。这种将BatchNorm和ReLU提前的方式被称为pre-activation,意思是激活(activation)提前到卷积层前面。
五、使用CIFAR10数据集ResNet18残差网络模型的图像识别
#!/usr/bin/env python
# coding: utf-8
# # 1.导入相关模块
import os
import time
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import sys
import d2lzh_pytorch as d2l
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(torch.__version__)
print(torchvision.__version__)
print(device)
# # 2.获取数据集并做预处理(CIFAR10)
#图像预处理变换的定义
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), #在一个随机的位置进行裁剪,32正方形裁剪,每个边框上填充4
transforms.RandomHorizontalFlip(), #以给定的概率随机水平翻转给定的PIL图像,默认值为0.5
transforms.ToTensor(), #将PIL Image或者 ndarray 转换为tensor,并且归一化至[0-1]
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),#用平均值和标准偏差归一化张量图像,
#(M1,…,Mn)和(S1,…,Sn)将标准化输入的每个通道
])
transform_test = transforms.Compose([ #测试集同样进行图像预处理
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# 对图像进行预处理变换,可以一定程度提高模型精度,提升收敛速度。
#下载数据集并设置存放目录,训练与否,下载与否,数据预处理转换方式等参数,得到cifar10_train训练数据集与cifar10_test测试数据集
cifar10_train = torchvision.datasets.CIFAR10(root='E:/AI/Datasets/CIFAR10', train=True, download=True, transform=transform_train)
cifar10_test = torchvision.datasets.CIFAR10(root='E:/AI/Datasets/CIFAR10', train=False, download=True, transform=transform_test)
#展示数据集类型及数据集的大小
print(type(cifar10_train))
print(len(cifar10_train), len(cifar10_test))
#打印其中一个数据,得到其图像尺寸,数据类型与对应的标签
feature, label = cifar10_train[3]
print(feature.shape, feature.dtype)
print(label)
#此函数使输入数字标签,返回字符串型标签,便于标签可读性
def get_CIFAR10_labels(labels):
text_labels = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
return [text_labels[int(i)] for i in labels]
print(get_CIFAR10_labels([0,1,2,3,4,5,6,7,8,9]))
#此函数用于显示图像与对应标签
def show_cifar10(images, labels):
d2l.use_svg_display() #图像以可缩放矢量图形式显示
_, figs = plt.subplots(1, len(images), figsize=(13, 13))#返回第一个变量为画布,第二个变量为1行,len(images)列,13大小的图片的一个图片画布
#这里的_表示我们忽略(不使用)的变量
for f, img, lbl in zip(figs, images, labels): #zip为打包,把figs, images, labels中的每个元素对应打包在一起
img=torchvision.utils.make_grid(img).numpy() #make_grid将多张图片拼在一起,这里img只有一张图片
f.imshow(np.transpose(img,(1,2,0))) #将图片的维度调换,从[C,W,H]转换为[W,H,C],以便于显示
f.set_title(lbl) #画布上设置标题为标签
f.axes.get_xaxis().set_visible(False) #X轴刻度关闭
f.axes.get_yaxis().set_visible(False) #Y轴刻度关闭
plt.show() #绘图
# # 3.定义ResNet18模型
# 本实验为了达到精度0.9的要求,尝试使用过LeNet,VGG-16作为网络模型,但测试集精度最优分别只达到了0.68与0.85。
#
# 之后使用了更先进的MSRA何凯明团队的残差网络(Residual Networks),综合考虑硬件条件约束后,采用简单的18层ResNet-18作为网络模型进行训练,测试集精度勉强达到0.9。
#
# 对于更加复杂先进的网络结构,可以得到更高的测试集精度,但由于硬件显卡性能瓶颈,需要非常长的训练时间甚至会显存不够而报错,所以没有进一步实验。
#
# 由于原始的ResNet是基于ImageNet的图像尺寸而定义的,为了适应CIFAR10数据集,我做了一些改动。
#定义带两个卷积路径和一条捷径的残差基本块类
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1): #初始化函数,in_planes为输入通道数,planes为输出通道数,步长默认为1
super(BasicBlock, self).__init__()
#定义第一个卷积,默认卷积前后图像大小不变但可修改stride使其变化,通道可能改变
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
#定义第一个批归一化
self.bn1 = nn.BatchNorm2d(planes)
#定义第二个卷积,卷积前后图像大小不变,通道数不变
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,stride=1, padding=1, bias=False)
#定义第二个批归一化
self.bn2 = nn.BatchNorm2d(planes)
#定义一条捷径,若两个卷积前后的图像尺寸有变化(stride不为1导致图像大小变化或通道数改变),捷径通过1×1卷积用stride修改大小
#以及用expansion修改通道数,以便于捷径输出和两个卷积的输出尺寸匹配相加
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes,kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
#定义前向传播函数,输入图像为x,输出图像为out
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x))) #第一个卷积和第一个批归一化后用ReLU函数激活
out = self.bn2(self.conv2(out))
out += self.shortcut(x) #第二个卷积和第二个批归一化后与捷径相加
out = F.relu(out) #两个卷积路径输出与捷径输出相加后用ReLU激活
return out
#定义残差网络ResNet18
class ResNet(nn.Module):
#定义初始函数,输入参数为残差块,残差块数量,默认参数为分类数10
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
#设置第一层的输入通道数
self.in_planes = 64
#定义输入图片先进行一次卷积与批归一化,使图像大小不变,通道数由3变为64得两个操作
self.conv1 = nn.Conv2d(3, 64, kernel_size=3,stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
#定义第一层,输入通道数64,有num_blocks[0]个残差块,残差块中第一个卷积步长自定义为1
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
#定义第二层,输入通道数128,有num_blocks[1]个残差块,残差块中第一个卷积步长自定义为2
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
#定义第三层,输入通道数256,有num_blocks[2]个残差块,残差块中第一个卷积步长自定义为2
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
#定义第四层,输入通道数512,有num_blocks[3]个残差块,残差块中第一个卷积步长自定义为2
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
#定义全连接层,输入512*block.expansion个神经元,输出10个分类神经元
self.linear = nn.Linear(512*block.expansion, num_classes)
#定义创造层的函数,在同一层中通道数相同,输入参数为残差块,通道数,残差块数量,步长
def _make_layer(self, block, planes, num_blocks, stride):
#strides列表第一个元素stride表示第一个残差块第一个卷积步长,其余元素表示其他残差块第一个卷积步长为1
strides = [stride] + [1]*(num_blocks-1)
#创建一个空列表用于放置层
layers = []
#遍历strides列表,对本层不同的残差块设置不同的stride
for stride in strides:
layers.append(block(self.in_planes, planes, stride)) #创建残差块添加进本层
self.in_planes = planes * block.expansion #更新本层下一个残差块的输入通道数或本层遍历结束后作为下一层的输入通道数
return nn.Sequential(*layers) #返回层列表
#定义前向传播函数,输入图像为x,输出预测数据
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x))) #第一个卷积和第一个批归一化后用ReLU函数激活
out = self.layer1(out) #第一层传播
out = self.layer2(out) #第二层传播
out = self.layer3(out) #第三层传播
out = self.layer4(out) #第四层传播
out = F.avg_pool2d(out, 4) #经过一次4×4的平均池化
out = out.view(out.size(0), -1) #将数据flatten平坦化
out = self.linear(out) #全连接传播
return out
#将ResNet类(参数为BasicBlock基本残差块,[2,2,2,2]四层中每层2个基本残差块)赋给对象net
net = ResNet(BasicBlock, [2, 2, 2, 2])
#打印net,查看网络结构
print(net)
# 可以看到网络结构由6大部分构成
#
# 1.最初的一个卷积层与批归一化层,输入图片[3,32,32],输出图片[64,32,32]
#
# 2.第一层,包括两个残差块
#
# 第一个残差块包含两个卷积与两个批归一化,输入图片[64,32,32],输出图片[64,32,32],捷径未加卷积修改
# 第二个残差块包含两个卷积与两个批归一化,输入图片[64,32,32],输出图片[64,32,32],捷径未加卷积修改
#
# 3.第二层,包括两个残差块
#
# 第一个残差块包含两个卷积与两个批归一化,输入图片[64,32,32],输出图片[128,16,16],捷径通过步长为2的1×1卷积修改输出为[128,16,16]
# 第二个残差块包含两个卷积与两个批归一化,输入图片[128,16,16],输出图片[128,16,16],捷径未加卷积修改
#
# 4.第三层,包括两个残差块
#
# 第一个残差块包含两个卷积与两个批归一化,输入图片[128,16,16],输出图片[256,9,9],捷径通过步长为2的1×1卷积修改输出为[256,9,9]
# 第二个残差块包含两个卷积与两个批归一化,输入图片[256,9,9],输出图片[256,9,9],捷径未加卷积修改
#
# 5.第四层,包括两个残差块
#
# 第一个残差块包含两个卷积与两个批归一化,输入图片[256,9,9],输出图片[512,5,5],捷径通过步长为2的1×1卷积修改输出为[512,5,5]
# 第二个残差块包含两个卷积与两个批归一化,输入图片[512,5,5],输出图片[512,5,5],捷径未加卷积修改
#
# 6.全连接层,输入神经元节点数为512 * 5 * 5,输出神经元节点数为10
# # 4.训练模型准备
#定义一个训练批量的样本数
batch_size=128
#构建可迭代的数据装载器(参数为数据集,一个批量的样本数,是否乱序,工作线程数)
train_iter = torch.utils.data.DataLoader(cifar10_train, batch_size=128, shuffle=True, num_workers=2)
test_iter = torch.utils.data.DataLoader(cifar10_test, batch_size=100, shuffle=False, num_workers=2)
#多GPU训练及优化
if device == 'cuda':
#对象net可进行多GPU并行处理
net = torch.nn.DataParallel(net)
#cudnn是英伟达为深度神经网络开发的GPU加速库,让内置的cudnn的auto-tuner自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题。
cudnn.benchmark = True
# 创建了一个准确度评估的函数,主要用来在训练过程中将每轮所得网络模型输入测试集数据,进而获得其泛化精度
#定义准确度评估函数(参数为数据装载器,网络模型,运算设备)
def evaluate_accuracy(data_iter, net, device=None):
# 如果没指定device就使用net的device
if device is None and isinstance(net, torch.nn.Module):
device = list(net.parameters())[0].device
#累计正确样本设为0.0,累计预测样本数设为0
acc_sum, n = 0.0, 0
#准确度评估阶段,with torch.no_grad()封装内关闭梯度计算功能
with torch.no_grad():
#从数据加载器上批量读取数据X与标签y
for X, y in data_iter:
if isinstance(net, torch.nn.Module):#若网络模型继承自torch.nn.Module
net.eval()#进入评估模式, 这会关闭dropout,以CPU进行准确度累加计算
#判断net(X.to(device)).argmax(dim=1)即X经net后输出的批量预测列表中每一个样本输出的最大值和y.to(device)此样本真实标签是否相同,
#若相同则表示预测正确,等号表达式为True,值为1;否则表达式为False,值为0。将批量所有样本的等号表达式值求和后再加给acc_sum
#每一次acc_sum增加一批量中预测正确的样本个数,随着不断的遍历,acc_sum表示累计的所有预测正确的样本个数
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train()# 改回训练模式
else: #若使用自定义的模型
#查看net对象中是否有变量名为is_training的参数,若有将is_training设置成False后遍历累加每一批量中的预测正确的样本数量
if('is_training' in net.__code__.co_varnames):
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
#若net对象中没有变量名为is_training的参数,则遍历累加每一批量中的预测正确的样本数量
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0] #每一次y.shape[0]表示一批量中标签个数,也就是样本个数。所以n表示累计的所有预测过的样本个数,无论正确与否
return acc_sum / n #用累计的所有预测正确的样本个数除以累计的所有预测过的样本个数得到准确率
# 创建了一个训练函数,主要用来进行循环训练,并在每轮训练结束后,打印本轮的训练集精度与测试集精度等训练信息
#定义训练函数(参数为网络模型,训练加载器,测试加载器,批量样本数,优化器,运算设备,训练回合数)
def train(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device) #网络模型搬移至指定的设备上
print("training on ", device) #查看当前训练所用的设备
loss = torch.nn.CrossEntropyLoss() #损失函数loss使用交叉熵损失函数
batch_count = 0 #批量计数器设为0
for epoch in range(num_epochs):#循环训练回合,每回合会以批量为单位训练完整个训练集,一共训练num_epochs个回合
#每一训练回合初始化累计训练损失函数为0.0,累计训练正确样本数为0.0,训练样本总数为0,start为开始计时的时间点
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter: #循环每次取一批量的图像与标签
X = X.to(device) #将图像搬移至指定设备上
y = y.to(device) #将标签搬移至指定设备上
y_hat = net(X) #将批量图像数据X输入网络模型net,得到输出批量预测数据y_hat
l = loss(y_hat, y) #计算批量预测标签y_hat与批量真实标签y之间的损失函数l
optimizer.zero_grad() #优化器的梯度清零
l.backward() #对批量损失函数l进行反向传播计算梯度
optimizer.step() #优化器的梯度进行更新,训练所得参数也更新
train_l_sum += l.cpu().item() #将本批量损失函数l加至训练损失函数累计train_l_sum中
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()#将本批量预测正确的样本数加至累计预测正确样本数train_acc_sum中
n += y.shape[0] #将本批量训练的样本数,加至训练样本总数
batch_count += 1 #批量计数器加1
test_acc = evaluate_accuracy(test_iter, net)#对本回合训练所得网络模型参数,以批量为单位,测试全集去验证,得到测试集预测准确度
#打印回合数,每回合平均损失函数,每回合的训练集准确度,每回合的测试集准确度,每回合用时
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
# # 5.训练模型
#设置学习率lr,训练回合数num_epochs
lr, num_epochs = 0.01, 50
#设置优化器为Adam优化器,参数为网络模型的参数和学习率
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
#开始训练模型,参数为网络模型,训练加载器,测试加载器,批量大小,优化器,运算设备,训练回合数
train(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
# 一共循环了50个回合,损失函数已经几乎不再减小了,训练集精度也趋于恒定。
#
# 可以从测试准确度test acc上看到,该模型的饱和测试集训练精度可以勉强达到0.9,满足了实验要求。
#保存网络模型的参数至mymodel.pth文件
torch.save(net.state_dict(),'mymodel.pth')
# # 6.验证模型
#重新加载数据集与测试集,但不做预处理变形,便于图片展示。
cifar10_train = torchvision.datasets.CIFAR10(root='E:/AI/Datasets/CIFAR10', train=True, download=True, transform=transforms.ToTensor())
cifar10_test = torchvision.datasets.CIFAR10(root='E:/AI/Datasets/CIFAR10', train=False, download=True, transform=transforms.ToTensor())
#重新构建训练加载器与测试加载器,但批量大小为6,便于图片展示。
train_iter = torch.utils.data.DataLoader(cifar10_train, batch_size=6, shuffle=True, num_workers=2)
test_iter = torch.utils.data.DataLoader(cifar10_test, batch_size=6, shuffle=False, num_workers=2)
#新建另一个训练集与测试集,做预处理变形,便于将其输入已训练好的网络模型来展示其输出的预测标签
cifar10_train_tran = torchvision.datasets.CIFAR10(root='E:/AI/Datasets/CIFAR10', train=True, download=True, transform=transform_train)
cifar10_test_tran = torchvision.datasets.CIFAR10(root='E:/AI/Datasets/CIFAR10', train=False, download=True, transform=transform_test)
#新建新数据集的训练加载器与测试加载器,但批量大小为6,便于标签展示。
train_iter_tran = torch.utils.data.DataLoader(cifar10_train_tran, batch_size=6, shuffle=True, num_workers=2)
test_iter_tran = torch.utils.data.DataLoader(cifar10_test_tran, batch_size=6, shuffle=False, num_workers=2)
dataiter = iter(test_iter) #创建无预处理的测试加载器的迭代器
images, labels = dataiter.next() #返回batch_size幅图片与标签,即6幅图片images与标签labels
show_cifar10(images, get_CIFAR10_labels(labels))#展示测试集的这六幅图片与标签
print('GroundTruth: ', ' '.join('%5s' % get_CIFAR10_labels([labels[j].numpy()]) for j in range(6)))#打印真实的标签GroundTruth
dataiter_tran = iter(test_iter_tran) #创建有预处理测试集的测试加载器的迭代器
images_tran, labels_tran = dataiter_tran.next()#返回batch_size幅图片与标签,即6幅图片images与标签labels
images_tran=images_tran.to(device) #将图片搬移至GPU
labels_tran=labels_tran.to(device) #将标签搬移至GPU
outputs = net(images_tran) #将有预处理的测试集批量图片输入已经训练好的网络模型,输出批量预测数据outputs
_, predicted = torch.max(outputs.data, 1) #得到批量预测数据outputs.data的最大值索引predicted列表
print('Predicted: ', ' '.join('%5s' % get_CIFAR10_labels([predicted[j].cpu().numpy()]) for j in range(6)))#打印预测的标签Predicted
# 可以看到,对测试集中的六幅图片,通过训练好的模型预测所得的标签与真实的标签完全一致,实现了图像分类的目的,实验完成。
# # 四.实验总结
# 本次试验中以ResNet18残差模型为图像识别的网络模型,其测试精度达到了约0.9,但由于其层数较浅,并未完全发挥残差网络的优势。
# 相比较LeNet,AlexNet,VGG16,GoogLeNet等模型,更深的网络层数带来的不仅仅是精度的缺失,模型的训练也更加困难,梯度消失导致反向传播无法继续。
# 而何凯明博士发明的残差网络使得网络层数加深的同时准确度反而出现了提升。例如在较浅的饱和网络后面再加上几个恒等映射层(Identity mapping,也即y=x,输出等于输入),
# 这样就增加了网络的深度,并且误差不会增加,也即更深的网络不会带来训练集上误差的上升。而这里提到的使用恒等映射直接将前一层输出传到后面的思想,
# 便是著名深度残差网络ResNet的灵感来源。只需要将残差F(x)=H(x)-x训练至趋于零,就可以实现加深网络层数而不降低准确度。
# 由于残差网络的出现,深度学习神经网络的层数瞬间从几十层深入到上百层,甚至可以达到更深的上千层。目前先进的一些网络结构均采用深度网络模型,用于达到更高的准确度。
# 对于CIFAR10数据集,一些常见深度网络进度如下:
#
# VGG16 92.64%
#
# ResNet18 93.02%
#
# ResNet50 93.62%
#
# ResNet101 93.75%
#
# RegNetX_200MF 94.24%
#
# RegNetY_400MF 94.29%
#
# MobileNetV2 94.43%
#
# ResNeXt29(32x4d) 94.73%
#
# ResNeXt29(2x64d) 94.82%
#
# DenseNet121 95.04%
#
# PreActResNet18 95.11%
#
# DPN92 95.16%
对于CIFAR10数据集,一些常见深度网络进度如下:
VGG16 92.64%
ResNet18 93.02%
ResNet50 93.62%
ResNet101 93.75%
RegNetX_200MF 94.24%
RegNetY_400MF 94.29%
MobileNetV2 94.43%
ResNeXt29(32x4d) 94.73%
ResNeXt29(2x64d) 94.82%
DenseNet121 95.04%
PreActResNet18 95.11%
DPN92 95.16%
参考:
代码:https://github.com/Li-Y-D/Image-classification-CIFAR10-ResNet18/blob/main/%E5%9B%BE%E5%83%8F%E5%88%86%E7%B1%BB_ResNet18%E6%A8%A1%E5%9E%8B_CIFAR10%E6%95%B0%E6%8D%AE%E9%9B%86_%E7%B2%BE%E5%BA%A690%25.ipynb
https://github.com/Li-Y-D/Image-classification-CIFAR10-ResNet18/blob/main/%E5%9B%BE%E5%83%8F%E5%88%86%E7%B1%BB_ResNet18%E6%A8%A1%E5%9E%8B_CIFAR10%E6%95%B0%E6%8D%AE%E9%9B%86_%E7%B2%BE%E5%BA%A690%25.ipynb
https://www.cnblogs.com/wuliytTaotao/p/9560205.html














 833
833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









