





连线图:
没加蓝牙前的接线图:

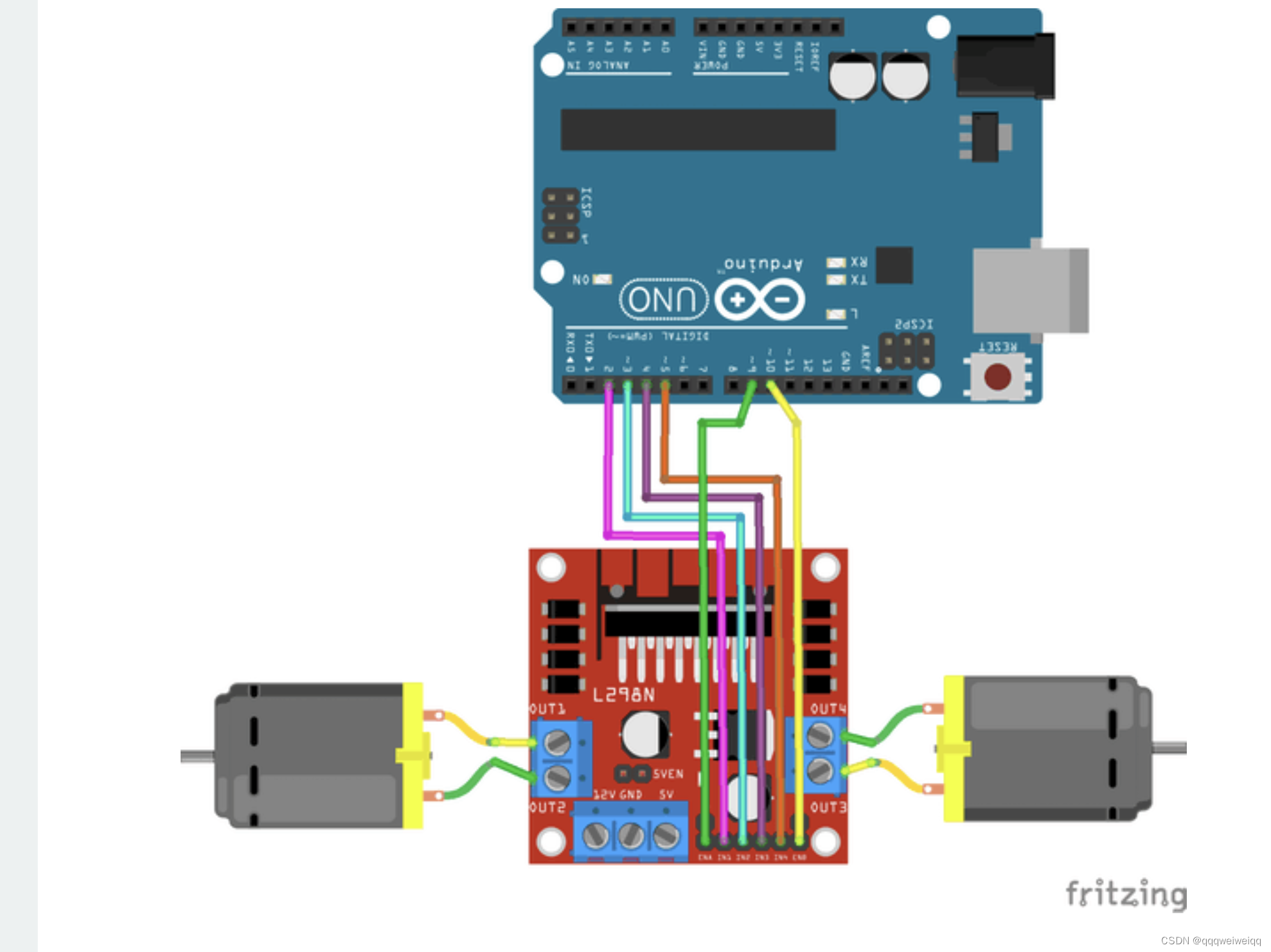
源自这篇文章:
L298n Motor driver Arduino | Motors | Motor Driver | L298n | Arduino Project Hub
加上蓝牙以后:

In-Depth: Interfacing HC05 Bluetooth Module with Arduino
就是用的是上面的两张图片组合起来的 不过我这个里面加的是12V电源 很好
代码如下:

连线图:
没加蓝牙前的接线图:
源自这篇文章:
L298n Motor driver Arduino | Motors | Motor Driver | L298n | Arduino Project Hub
加上蓝牙以后:
In-Depth: Interfacing HC05 Bluetooth Module with Arduino
就是用的是上面的两张图片组合起来的 不过我这个里面加的是12V电源 很好
代码如下:











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 2967
2967







