







欢迎来到我们的微信公众号,今天我们将深入探讨 Go 语言中的 string 类型。string 是 Go 语言中非常核心的一个数据类型,理解它的工作方式将帮助我们编写更高效、更安全的代码。
什么是 Go 语言中的 string?
在 Go 语言中,string 类型被定义为只读的字节序列。也就是说,string 类型的值是不可变的。这与许多其他语言(如 Python 或 Java)中的字符串行为是一致的。
str := "Hello, Gopher"
str[0] = 'h' // 这将产生编译错误
在上述代码中,我们尝试修改 string 的第一个字符,但 Go 编译器会报错,因为 string 是不可变的。
string 标准概念
Go标准库 builtin 给出了所有内置类型的定义。源代码位于 src/builtin/builtin.go ,其中关于string的描述如
下:
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string
所以 string 是 8 比特字节的集合,通常但并不一定是 UTF-8 编码的文本。 另外,还提到了两点,非常重要:
- string 可以为空(长度为0),但不会是 nil;
- string 对象不可以修改。
string 的内部结构
string 在内部是由两部分组成的:一部分是指向实际数据的指针,另一部分是记录字符串长度的整数。这种设计使得 string 在数据大的情况下传递和处理效率非常高,因为复制 string 只需要复制这两部分,而不需要复制实际的数据。
type stringStruct struct {
str unsafe.Pointer
len int
}
其数据结构很简单:
- str:字符串的首地址;
- len:字符串的长度; string 数据结构跟切片有些类似,只不过切片还有一个表示容量的成员,事实上string 和切片,准确的说是 byte 切片经常发生转换。这个后面再详细介绍。
string 与编码
Go 语言的 string 本质上就是字节的序列,它并不关心这些字节代表什么。这使得 string 可以包含任何数据,包括无效的 UTF-8 字符序列。
str := "Hello, 世界"
for i := 0; i < len(str); i++ {
fmt.Printf("%x ", str[i])
}
在上述代码中,我们可以看到 string 中的每个字节的十六进制表示。对于 ASCII 字符 "Hello, ",我们看到的是它们的 ASCII 码值。但对于 “世界”,我们看到的是它们的 UTF-8 编码。
string 的操作
声明
var str string
str = "Hello World"
字符串构建过程是先跟据字符串构建 stringStruct,再转换成 string。转换的源码如下:
func gostringnocopy(str *byte) string { // 跟据字符串地址构建string
ss := stringStruct{str: unsafe.Pointer(str), len: findnull(str)} // 先构造stringStruct
s := *(*string)(unsafe.Pointer(&ss))
return s
}
尽管 string 是不可变的,我们仍然可以通过一些方法来"改变"一个 string,实际上我们是创建了一个新的 string。例如,我们可以使用 + 运算符来连接两个 string。
str1 := "Hello"
str2 := "World"
str3 := str1 + ", " + str2 // "Hello, World"
我们也可以使用 strings 包中的函数来处理 string,如 strings.Replace、strings.ToUpper 和 strings.ToLower 等。
str := "Hello, World"
str = strings.Replace(str, "World", "Gopher", -1) // "Hello, Gopher"
str = strings.ToUpper(str) // "HELLO, GOPHER"
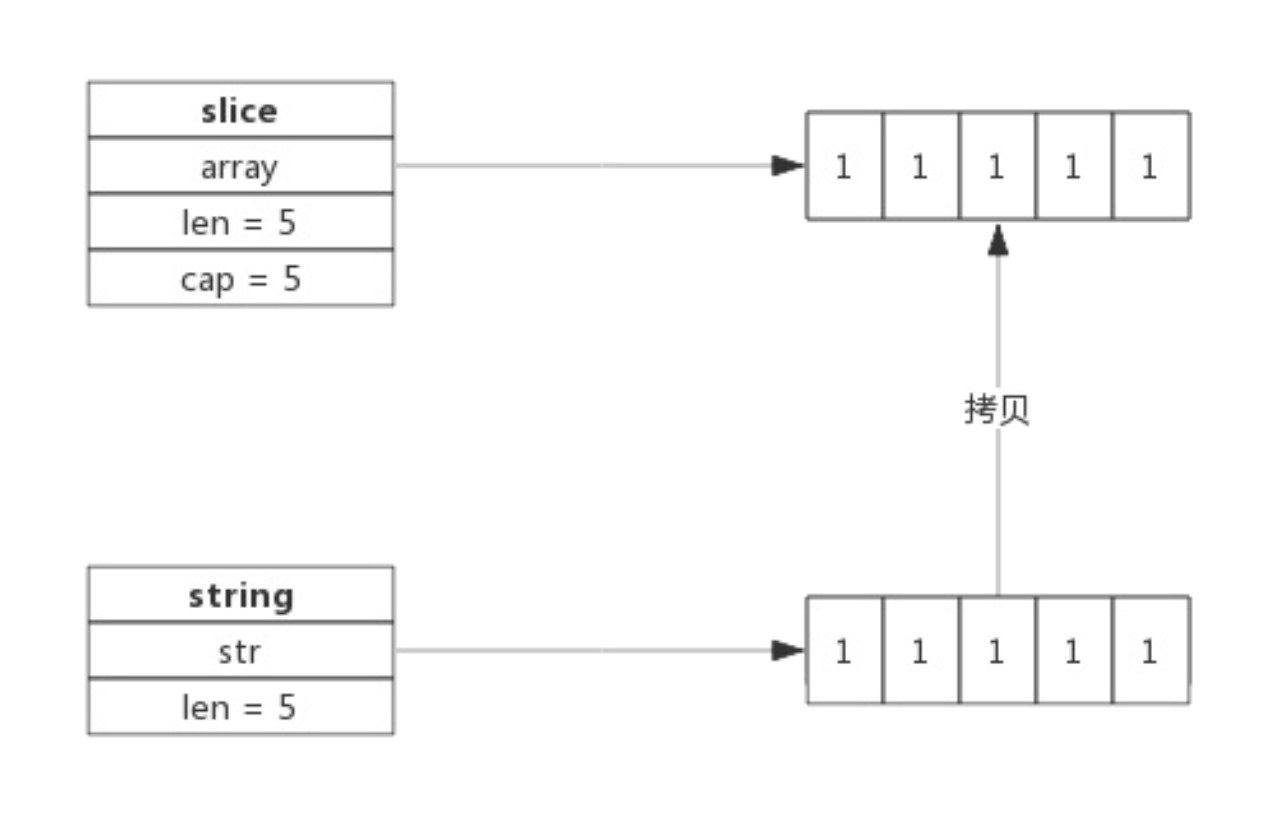
[]byte 转 string
byte 切片可以很方便的转换成 string,如下所示:特别需要注意的是这种转换需要一次内存拷贝。
func GetStringBySlice(s []byte) string {
return string(s)
}
转换过程如下:
- 跟据切片的长度申请内存空间,假设内存地址为p,切片长度为len(b);
- 构建string(string.str = p;string.len = len;)
- 拷贝数据(切片中数据拷贝到新申请的内存空间)
转换示意图:

string 转 []byte
string 也可以方便的转成 byte 切片,如下所示:
func GetSliceByString(str string) []byte {
return []byte(str)
}
string 转换成 byte 切片,也需要一次内存拷贝,其过程如下: 申请切片内存空间,将 string 拷贝到切片。
字符串拼接
字符串可以很方便的拼接:
str := "Str1" + "Str2" + "Str3"
即便有非常多的字符串需要拼接,性能上也有比较好的保证,因为新字符串的内存空间是一次分配完成的,所以性能消耗主要在拷贝数据上。
一个拼接语句的字符串编译时都会被存放到一个切片中,拼接过程需要遍历两次切片,第一次遍历获取总的字符串长度,据此申请内存,第二次遍历会把字符串逐个拷贝过去。
字符串拼接伪代码如下:
func concatstrings(a []string) string { // 字符串拼接
length := 0 // 拼接后总的字符串长度
for _, str := range a {
length += length(str)
}
s, b := rawstring(length) // 生成指定大小的字符串,返回一个 string 和切片,二者共享内存空间
for_,str:=rangea{
copy(b, str) // string无法修改,只能通过切片修改
b = b[len(str):]
}
return s
}
因为 string 是无法直接修改的,所以这里使用 rawstring() 方法初始化一个指定大小的 string,同时返回一个切 片,二者共享同一块内存空间,后面向切片中拷贝数据,也就间接修改了string。
rawstring() 源代码如下:
func rawstring(size int) (s string, b []byte) { // 生成一个新的string,返回的string和切片共享相同的空间
p := mallocgc(uintptr(size), nil, false)
stringStructOf(&s).str = p
stringStructOf(&s).len = size
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, size}
return
}
总结
Go 语言中的 string 是一个复杂但强大的工具。理解 string 的内部工作原理可以帮助我们更好地使用它,并编写出更高效、更安全的代码。
为什么字符串不允许修改?
像 C++ 语言中的 string,其本身拥有内存空间,修改 string 是支持的。但 Go 的实现中,string 不包含内存空间,只有一个内存的指针,这样做的好处是 string 变得非常轻量,可以很方便的进行传递而不用担心内存拷贝。
因为 string 通常指向字符串字面量,而字符串字面量存储位置是只读段,而不是堆或栈上,所以才有了 string 不可修改的约定。
string 和 []byte 如何取舍
string 和 []byte 都可以表示字符串,但因数据结构不同,其衍生出来的方法也不同,要跟据实际应用场景来选择。
string 擅长的场景:
- 需要字符串比较的场景;
- 不需要 nil 字符串的场景;
[]byte 擅长的场景:
- 修改字符串的场景,尤其是修改粒度为1个字节;
- 函数返回值,需要用 nil 表示含义的场景;
- 需要切片操作的场景;
如果您想了解更多关于 Go 语言的知识和技巧,欢迎关注我们的微信公众号。我们将定期分享更多有关 Go 语言的深入文章和教程。
请关注公众号【Java千练】,更多干货文章等你来看!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









