






https://blog.csdn.net/qscftqwe/article/details/156021173
上节课链接,配套使用更佳
一.闭散列代码实现
1.1 提要
#pragma once
#include <iostream>
#include <vector>
enum State//状态
{
Empty,//空
Exist,//存在
Delete//删除
};
struct HashData
{
State _state = Empty;//元素的状态
int _val = 0;//元素的值
};
class HashTable
{
typedef HashData Data;
public:
HashTable()
{
_table.resize(10);
}
private:
std::vector<Data> _table;
//这里的n是为了统计哈希表里面的有效数据,是为了和vector的size_t做区别
size_t _n = 0;
};
关于状态这个枚举,我在后面讲解的时候会进行分析,还有一点要注意的就是我这个_table这个应该是Data*的我写成Data,不是说错了而是说前者更推荐,我这次写的有问题!
1.2 插入
//线性探测
bool Insert(int val)
{
//不允许重复插入
Data* ret = Find(val);
if (ret != nullptr)
{
return false;
}
//扩容
if (((double)_n / _table.size() >= 0.7))
{
size_t newSize = _table.size() * 2;//扩两倍
//创建新表
std::vector<Data> newTable(newSize);
// 从老哈希表插入
for (auto& data : _table)
{
if (data._state == Exist)
{
size_t hashi = (data._val % newSize + newSize)% newSize;
while (newTable[hashi]._state == Exist)
{
//该位置不为空不可以插入要往前走
hashi = (hashi + 1) % newSize; // 线性探测
}
//该位置为空或删除可以插入
newTable[hashi] = data;
}
}
//交换新表和旧表
_table.swap(newTable);
}
//增加
//求该值在哈希表的位置
size_t hashi = (val % _table.size() + _table.size()) % _table.size();
//看看哈希表该值是否存在
while (_table[hashi]._state == Exist)
{
++hashi;
hashi = hashi % _table.size();//避免值超出范围了
}
//为空或者为删除
_table[hashi]._val = val;
_table[hashi]._state = Exist;
++_n;//加入成功
return true;
}注意:闭散列和开散列的插入都是不能有重复的元素的!
关于这个Insert要重点讲扩容这部分!
扩容:
- 哈希表的扩容和传统的扩容是不一样的,传统的扩容都是满了才扩,而哈希表它因为有哈希冲突因此引进负载因子,我们是根据负载因子来扩容的!
- 然后我们在讲一下为什么要引入状态吧,首先我们知道数组最大的劣势就是删数据要用O(n)进行搬运,我们之前处理vector的时候是为什么可以直接用有效个数--即可完成,因为我们vector是线性序列的数据结构,因此它要插入的位置是可视化(即我们知道它要插哪里)
- 但是哈希表它是关联性容器,所以它要插入的位置是不可视化的,因此我们无法通过有效个数--来完成对数据的删除,因此我们用状态来表示是否经行删除,引进状态我们就知道数组的终点是那个位置(empty)而删除状态表明该坑为空里面的数据无效,最后exist状态表明该坑不为空里面数据有效。
-
size_t hashi = (data._val % newSize + newSize)% newSize; hashi = (hashi + 1) % newSize;然后就是介绍这两条代码,首先第一条它是避免val是负数的情况,这是安全取摸法,第二条这个和循环队列有点像就是都有一个从头走的概念!
最后关于后面的增加就不需要在讲了,因为扩容它本身就有包含增加这种!不过可能有些人会对这三行代码有疑问!
newTable[hashi] = data;
_table[hashi]._val = val;
_table[hashi]._state = Exist;你可能会疑惑为什么从老哈希表插入,不需要修改值和状态,注意data是Data类型也就是说它包含这val和state,后面的就不必多说了!
1.3 查找
Data* Find(int val)
{
//保存开始位置
size_t start = (val % _table.size() + _table.size()) % _table.size();
size_t hashi = start;
//对数组进行查找
do {
if (_table[hashi]._state == Empty)
return nullptr; // 真空位置 → 不存在
if (_table[hashi]._state == Exist && _table[hashi]._val == val)
{
return &_table[hashi];//找到了
}
hashi++;
hashi = hashi % _table.size();
} while (hashi != start); // 防止死循环
//当找到空那么说明该数组所有元素都被查询完毕
return nullptr;
}要点:
一定要采用do while循环,因为一开始hahsi==start,如果先判断那么就直接退出了,而在查找这一个函数当中你就更能明白状态的重要性!
为什么返回类型要是Data*类型,因为在学习插入和删除,你发现他们都可以借助查询功能,因此才会被设计成Data*类型!
1.4 删除
bool Erase(int val)
{
Data* ret = Find(val);
if (ret != nullptr)
{
ret->_state = Delete;
--_n;
return true;
}
return false;
}如果用上查询,那么删除其实非常的简单,就不做讲解了
1.5 完整代码
#pragma once
#include <iostream>
#include <vector>
enum State//状态
{
Empty,//空
Exist,//存在
Delete//删除
};
struct HashData
{
State _state = Empty;//元素的状态
int _val = 0;//元素的值
};
class HashTable
{
typedef HashData Data;
public:
HashTable()
{
_table.resize(10);
}
//线性探测
bool Insert(int val)
{
//不允许重复插入
Data* ret = Find(val);
if (ret != nullptr)
{
return false;
}
//扩容
if (((double)_n / _table.size() >= 0.7))
{
size_t newSize = _table.size() * 2;//扩两倍
//创建新表
std::vector<Data> newTable(newSize);
// 从老哈希表插入
for (auto& data : _table)
{
if (data._state == Exist)
{
size_t hashi = (data._val % newSize + newSize)% newSize;
while (newTable[hashi]._state == Exist)
{
hashi = (hashi + 1) % newSize; // 线性探测
}
newTable[hashi] = data;
}
}
//交换新表和旧表
_table.swap(newTable);
}
//增加
//求该值在哈希表的位置
size_t hashi = (val % _table.size() + _table.size()) % _table.size();
//看看哈希表该值是否存在
while (_table[hashi]._state == Exist)
{
++hashi;
hashi = hashi % _table.size();//避免值超出范围了
}
//为空或者为删除
_table[hashi]._val = val;
_table[hashi]._state = Exist;
++_n;//加入成功
return true;
}
Data* Find(int val)
{
//获取一开始位置
size_t start = (val % _table.size() + _table.size()) % _table.size();
size_t hashi = start;
//对数组进行查找
do {
if (_table[hashi]._state == Empty)
return nullptr; // 真空位置 → 不存在
if (_table[hashi]._state == Exist && _table[hashi]._val == val)
{
return &_table[hashi];//找到了
}
hashi++;
hashi = hashi % _table.size();
} while (hashi != start); // 防止死循环
//当找到空那么说明该数组所有元素都被查询完毕
return nullptr;
}
bool Erase(int val)
{
Data* ret = Find(val);
if (ret != nullptr)
{
ret->_state = Delete;
--_n;
return true;
}
return false;
}
private:
std::vector<Data> _table;
//这里的n是为了统计哈希表里面的有效数据,是为了和vector的size_t做区别
size_t _n = 0;
};二.开散列的代码实现
1.提要
//节点
struct HashNode
{
HashNode(int val)
:_val(val)
,_next(nullptr)
{}
int _val;
HashNode* _next;
};
class HashBucket
{
typedef HashNode Node;
typedef HashBucket Self;
public:
HashBucket()
{
_table.resize(10, nullptr);
}
HashBucket(const Self& Bucket)
{
size_t newSize = Bucket._table.size();
_n = Bucket._n;
_table.resize(newSize,nullptr);
//拷贝数据
for (size_t i = 0; i < Bucket._table.size(); i++)
{
Node* cur = Bucket._table[i];
while (cur)
{
Node* newNode = new Node(cur->_val);//用老链表的节点构建新链表
size_t hashi = (newNode->_val % newSize + newSize) % newSize;
//类似挂咸鱼的那种挂法,把钩子的第一条咸鱼挂在该咸鱼下面
//然后把咸鱼挂在钩子上面
newNode->_next = _table[hashi];
_table[hashi] = newNode;
cur = cur->_next;
}
}
}
~HashBucket()
{
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}
private:
std::vector<Node*>_table;
size_t _n = 0;
};关于这部分重点要讲的就是拷贝构造和
拷贝构造:
- 首先我们要大概清楚哈希桶(开散列)大概是长什么样的,这个我上一章也讲,不过这里同样贴出!
- 其实你根据这张图片你就知道了这是由两种数据结构组成的:数组和链表,每一个数组存放的就是一条链表,所以我们要拷贝就是把这数组中的所有链表拷过去!
- 我们知道要把链表拷过去但是这么拷过去呢,首先我们单链表它头插是不是O(1),所以我们采用头插的方法,关于哈希桶实用头插的方法就有点像挂咸鱼,首先你有一条咸鱼,然后你会把钩子上的一串咸鱼取下来然后把这一串咸鱼挂在当前这个咸鱼下面,刮完后再把新的一串咸鱼挂在钩子上。
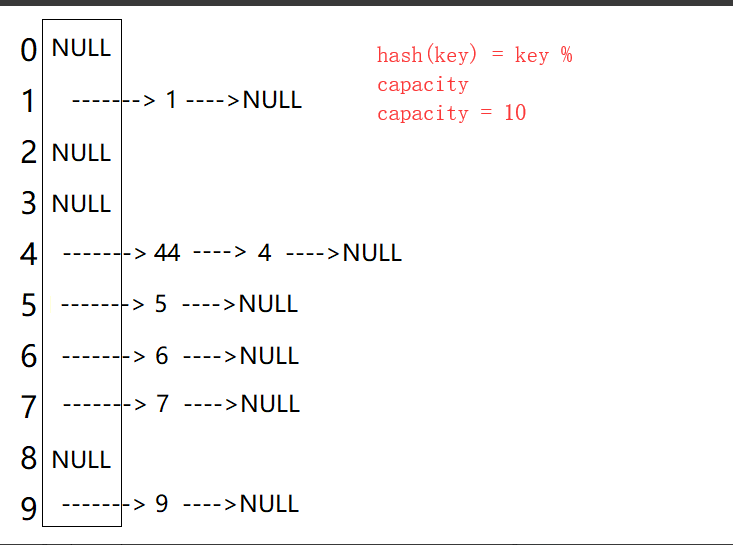
至于析构就没什么好说的了,就是循环所有链表然后一 一删除链表上的节点即可!
1.2 插入
bool Insert(int val)
{
Node* ret = Find(val);//看看这个有没有重复
if (ret != nullptr)
return false;
//负载因子为1在扩容
if (_n == _table.size())
{
size_t newSize = _table.size() * 2;
std::vector<Node*>table;
table.resize(newSize, nullptr);
//遍历旧表到新表
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];//获取链表的第一个节点
while (cur)
{
Node* next = cur->_next;
//头插到新表
//获取要插在那个桶里面
size_t hashi = (cur->_val % newSize + newSize) % newSize;
//类似挂咸鱼的那种挂法,把钩子的第一条咸鱼挂在该咸鱼下面
//然后把咸鱼挂在钩子上面
cur->_next = table[hashi];
table[hashi] = cur;
cur = next;
}
}
//交换新表和旧表
_table.swap(table);
}
size_t hashi = (val % _table.size() + _table.size()) % _table.size();
//头插
Node* newNode = new Node(val);
newNode->_next = _table[hashi];
_table[hashi] = newNode;
++_n;
return true;
}至于这个插入代码,其实你只要会闭散列的插入+拷贝构造用的方法,其实这个有没什么好说的,看我代码注释自己理解即可!
最后关于这个负载因子这么说呢,可以调成70%,不过我上节课讲的是100%,那我这边就采取100%的写法,当然70会更好的!
1.3 查找
Node* Find(int val)
{
size_t hashi = (val % _table.size() + _table.size()) % _table.size();
Node* cur = _table[hashi];
while (cur)
{
if (cur->_val == val)
{
//找到了
return cur;
}
cur = cur->_next;
}
return nullptr;
}代码不做讲解!
1.4 删除
bool Erase(int val)
{
size_t hashi = (val % _table.size() + _table.size()) % _table.size();
Node* cur = _table[hashi];//记录要删除的节点
Node* prev = nullptr;//删除节点的上一个节点
while (cur)
{
if (cur->_val == val)
{
//删除的刚好是第一个节点
if (prev == nullptr)
{
prev = cur->_next;
_table[hashi] = prev;
}
else//删除的不是第一个节点
{
prev->_next = cur->_next;
}
delete cur;
--_n;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}这个重点部分就是单链表删除会遇到的问题,就是你删除的节点正好是链表的第一个节点该怎么处理的,只要注意这个处理删除和之前处理析构差不多!
1.5 完整代码
#pragma once
#include <iostream>
#include <vector>
class HashBucket
{
typedef HashNode Node;
typedef HashBucket Self;
public:
HashBucket()
{
_table.resize(10, nullptr);
}
HashBucket(const Self& Bucket)
{
size_t newSize = Bucket._table.size();
_n = Bucket._n;
_table.resize(newSize,nullptr);
//拷贝数据
for (size_t i = 0; i < Bucket._table.size(); i++)
{
Node* cur = Bucket._table[i];
while (cur)
{
Node* newNode = new Node(cur->_val);//用老链表的节点构建新链表
//安全获取位置
size_t hashi = (newNode->_val % newSize + newSize) % newSize;
//类似挂咸鱼的那种挂法,把钩子的第一条咸鱼挂在该咸鱼下面
//然后把咸鱼挂在钩子上面
newNode->_next = _table[hashi];
_table[hashi] = newNode;
cur = cur->_next;
}
}
}
~HashBucket()
{
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}
bool Insert(int val)
{
Node* ret = Find(val);//看看这个有没有重复
if (ret != nullptr)
return false;
//负载因子为1在扩容
if (_n == _table.size())
{
size_t newSize = _table.size() * 2;
std::vector<Node*>table;
table.resize(newSize, nullptr);
//遍历旧表到新表
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];//获取链表的第一个节点
while (cur)
{
Node* next = cur->_next;
//头插到新表
//获取要插在那个桶里面
size_t hashi = (cur->_val % newSize + newSize) % newSize;
cur->_next = table[hashi];
table[hashi] = cur;
cur = next;
}
}
//交换新表和旧表
_table.swap(table);
}
size_t hashi = (val % _table.size() + _table.size()) % _table.size();
//头插
Node* newNode = new Node(val);
newNode->_next = _table[hashi];
_table[hashi] = newNode;
++_n;
return true;
}
Node* Find(int val)
{
size_t hashi = (val % _table.size() + _table.size()) % _table.size();
Node* cur = _table[hashi];
while (cur)
{
if (cur->_val == val)
{
//找到了
return cur;
}
cur = cur->_next;
}
return nullptr;
}
bool Erase(int val)
{
size_t hashi = (val % _table.size() + _table.size()) % _table.size();
Node* cur = _table[hashi];//记录要删除的节点
Node* prev = nullptr;//删除节点的上一个节点
while (cur)
{
if (cur->_val == val)
{
//删除的刚好是第一个节点
if (prev == nullptr)
{
prev = cur->_next;
_table[hashi] = prev;
}
else//删除的不是第一个节点
{
prev->_next = cur->_next;
}
delete cur;
--_n;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
private:
std::vector<Node*>_table;
size_t _n = 0;
};C++哈希表的实现就是采用开散列(哈希桶)的方式实现的,不过我所展现的是非常简单的,因为哈希表分成unordered_map和unordered_set,因此还要对此进行封装,然后加上封装、迭代器……就会太复杂了,所以无论是哈希还是map/set都没有像之前一样实现的更彻底!

















 3105
3105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









