






全文链接:[2106.05786v1] CAT: Cross Attention in Vision Transformer (arxiv.org)
交叉注意力,块内部注意力与单通道特征注意力交叉使用。其中,块内部注意力属于局部注意力,单通道特征注意力属于全局注意力。
1.Inner-Patch Self-Attention(IPSA)

这个步骤与swintsf一样,都是在一个小范围内进行attention,而不是在全图中进行。在计算attention上没有任何差别。CAT代码class Attention(nn.Module)与SWIN代码class WindowAttention(nn.Module)对应,没有区别。在数据转化时,代码同样相同。文章中的复杂度计算公式也一样。
2.Cross-Patch Self-Attention Block
块内部像素间的注意力机制只是保证了一个图块内部像素间的相互关系被捕捉,但整幅图像的信息交换也相当关键。受depthwise卷积的启发,作者提出了CPSA。
每个单通道特征图天然具有全局空间信息。Cross - Patch Self - Attention算法,分离每个通道特征图,将每个通道划分为H / N × W / N个子块,并使用自注意力来获取整个特征图中的全局信息。
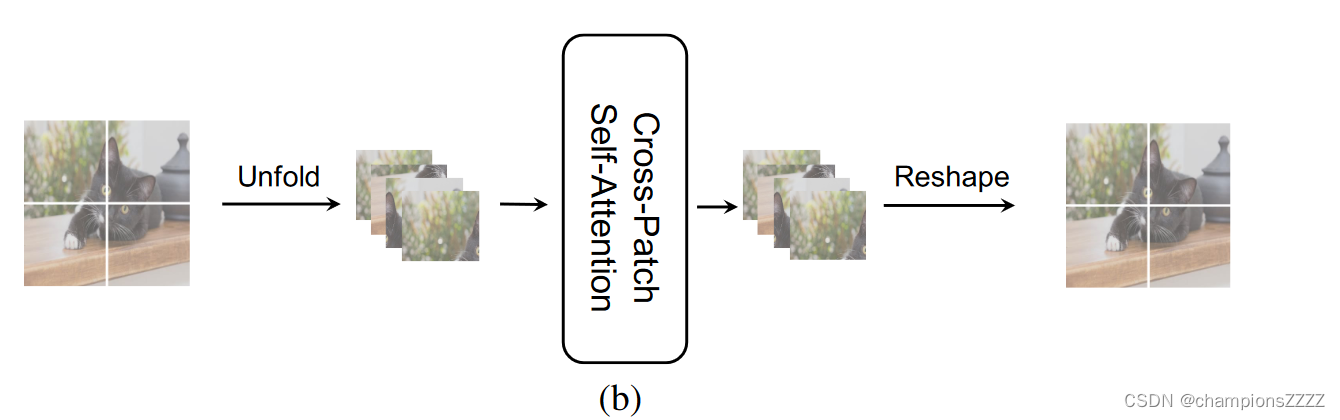
文中给出的图是将一个波段分块,然后堆叠起来,做注意力。对每一个波段进行相同的操作。
3.文章中的错误
但是有比较矛盾的地方。文中指明

N is patch size in CPSA。对于一个单波段影像,N是切割大小,那么会总共切割成*
个块,堆叠起来就是
*
个波段。将图像块大小表示为(高度,宽度,波段),将(
,
,
*
)大小的图像输入注意力块,根据自注意力计算公式:

得不到以上CPSA的计算量结果。除非N指的是单波段影像在长和高方向切割的图像块的个数,也就是图像块的大小是(,
,
)。用以下图像解释,将这整个图像分为蓝黄绿黑四块,那么,N=2而不是N=3。
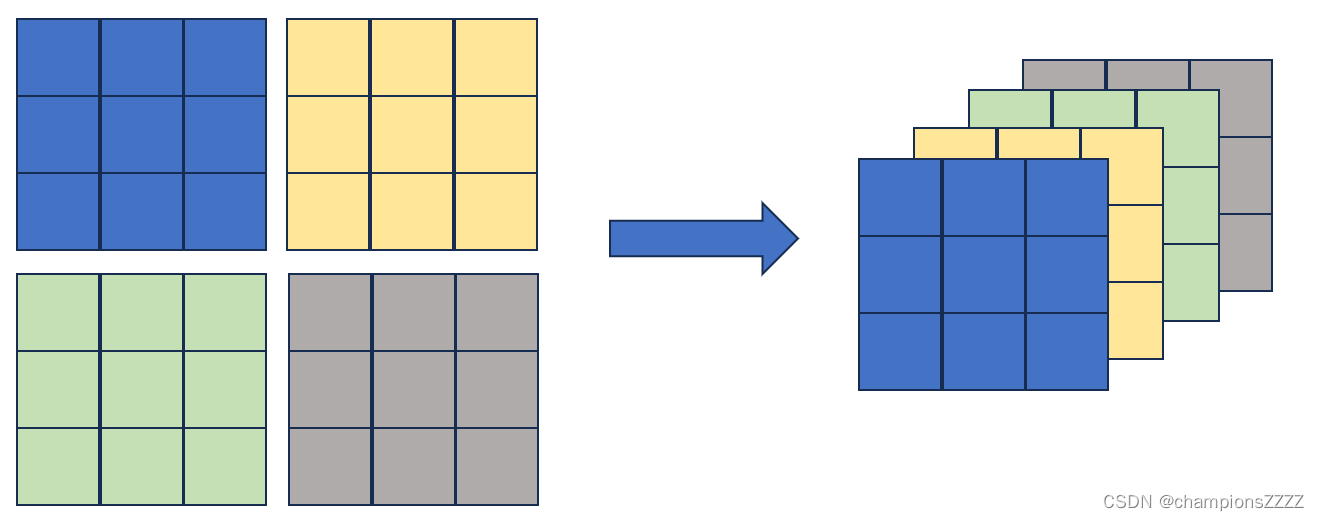
从给定代码来看:
在class CATBlock(nn.Module)模块定义了attention
self.attn = Attention(
dim=dim if attn_type == "ipsa" else self.patch_size ** 2, patch_size=to_2tuple(self.patch_size),
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop, rpe=rpe)其中,dim参数指的是特征多少,也就是波段数,可以看到对于“cpsa”模式,参数dim=patch_size ** 2,与猜测一致。那么为什么patch_size这个参数不变呢。Attention模块代码中可以看到patch_size参数只和相对位置编码有关,对于“cpsa”模式,使用的是绝对位置编码(‘ipsa’使用相对位置编码),因此该参数没有作用。
再看forword函数里面的数据处理模式:
# partition
patches = partition(x, self.patch_size) # nP*B, patch_size, patch_size, C
patches = patches.view(-1, self.patch_size * self.patch_size, C) # nP*B, patch_size*patch_size, C
# IPSA or CPSA
if self.attn_type == "ipsa":
attn = self.attn(patches) # nP*B, patch_size*patch_size, C
elif self.attn_type == "cpsa":
patches = patches.view(B, (H // self.patch_size) * (W // self.patch_size), self.patch_size ** 2, C).permute(0, 3, 1, 2).contiguous()
patches = patches.view(-1, (H // self.patch_size) * (W // self.patch_size), self.patch_size ** 2) # nP*B*C, nP*nP, patch_size*patch_size
attn = self.attn(patches).view(B, C, (H // self.patch_size) * (W // self.patch_size), self.patch_size ** 2)
attn = attn.permute(0, 2, 3, 1).contiguous().view(-1, self.patch_size ** 2, C) # nP*B, patch_size*patch_size, C对于IPSA,在进入attention之前,将输入数据的形状变换为(nP*B, patch_size*patch_size, C)
对于CPSA,在进入attention之前,输入数据形状为(nP*B*C, nP*nP, patch_size*patch_size)
其中,nP指的是行方向和列方向上图像块的个数。
由此证明了,对于CPSA模式,无论是文中的N,还是代码中的patch_size,指的都不是图像块的大小,而是行方向和列方向上图像块的个数。















 1395
1395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









