







Hadoop入门配置系列博客目录一览
1、Eclipse中使用Hadoop伪分布模式开发配置及简单程序示例(Linux下)
2、使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令、下载dfs文件至本地)
3、Hadoop完全分布式集群安装及配置(基于虚拟机)
4、Eclipse中使用Hadoop集群模式开发配置及简单程序示例(Windows下)
5、Zookeeper3.4.9、Hbase1.3.1、Pig0.16.0安装及配置(基于Hadoop2.7.3集群)
6、mysql5.7.18安装、Hive2.1.1安装和配置(基于Hadoop2.7.3集群)
7、Sqoop-1.4.6安装配置及Mysql->HDFS->Hive数据导入(基于Hadoop2.7.3)
8、Hadoop完全分布式在实际中优化方案
9、Hive:使用beeline连接和在eclispe中连接
10、Scala-2.12.2和Spark-2.1.0安装配置(基于Hadoop2.7.3集群)
11、Win下使用Eclipse开发scala程序配置(基于Hadoop2.7.3集群)
12、win下Eclipse远程连接Hbase的配置及程序示例(create、insert、get、delete)
Hadoop入门的一些简单实例详见本人github:https://github.com/Nana0606/hadoop_example
本篇博客主要介绍“Hive:使用beeline连接和在eclispe中连接”。
在mysql5.7.18安装、Hive2.1.1安装和配置(基于Hadoop2.7.3集群)中,已经讲到了mysql和hive的安装和配置。本篇博客第一部分讲的是使用beeline连接hive的方法,第二部分讲的是在eclipse中远程连接hive。
准备工作
1、启动hadoop服务 2、启动mysql服务使用beeline连接
1、启动hiveserver2服务
在根目录下, 使用下面的命令启动hiveserver2服务:hive --service hiveserver2
注意:建议使用hive.log来观察是否有错误之类的,hive.log默认存储在/tmp/${user.name}/下。我本人在操作这一步的时候等了一大会仍然没有停止,也没有强制关闭此进程(强制关闭可能会带来问题:Hive启动提示端口10000被占用:SelectChannelConnector@0.0.0.0:10000: java.net.BindException),所以我直接又开了一个命令行窗口,在另一个窗口进行的以下操作。
2、beeline操作
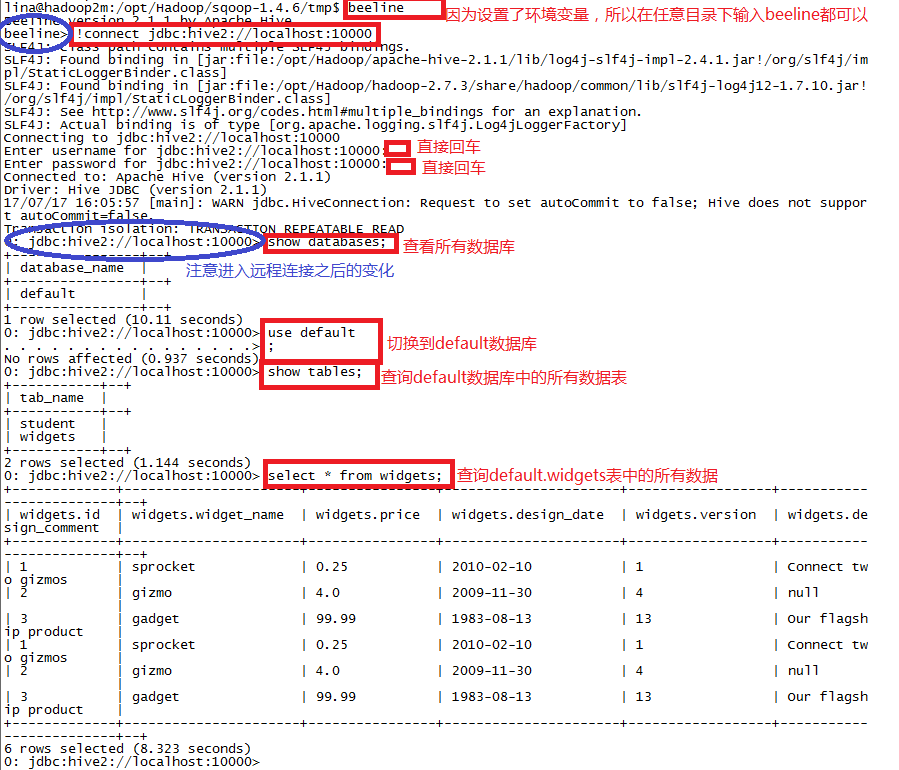
Step1: 在根目录下输入beeline命令,会出现beeline的版本信息
Step2: 输入!connect jdbc:hive2://localhost:10000,会提示你输入用户名和密码。因为在hive-site.xml文件中默认不认证,我们也没有更改,所以这里用户名和密码直接回车即可。
Step3: 连接成功之后,便可以进行数据库的查询等操作了,查询结果应该和直接用hive进入的命令行的执行结果相同。
如下图:
在eclispe中连接
1、启动hiveserver2服务
使用命令开启hiveserver2服务: ``` hive --service hiveserver2 ```2、Eclispe中连接hadoop
详见:[Eclipse中使用Hadoop集群模式开发配置及简单程序示例(Windows下)](http://blog.csdn.net/quiet_girl/article/details/74936039),主要是HDFS的连接。3、简单代码示例
Step1: 新建一个Java Project,在新建一个class文件
Step2: 导入jar包
Build Path->Configure Build Path->Libraries,将下列jar包添加到项目中:
$HIVE_INSTALL/lib下的全部jar包和
/hadoop-2.5.1/share/hadoop/common下所有jar包,及里面的lib目录下所有jar包
/hadoop-2.5.1/share/hadoop/hdfs下所有jar包,不包括里面lib下的jar包
/hadoop-2.5.1/share/hadoop/mapreduce下所有jar包,不包括里面lib下的jar包
/hadoop-2.5.1/share/hadoop/yarn下所有jar包,不包括里面lib下的jar包
Step3: 代码如下:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class hiveTest {
//连接函数
public static Connection getConnection(){
Connection connection = null;
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
connection = DriverManager.getConnection("jdbc:hive2://192.168.163.131:10000", "", "");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return connection;
}
public static void main(String[] args) throws Exception {
Connection con = getConnection();
Statement stmt = con.createStatement();
String querySQL = "SELECT * FROM default.student";
ResultSet res = stmt.executeQuery(querySQL);
//输出查询结果
while (res.next()) {
System.out.println(res.getString(1)+" " + res.getString(2));
}
}
}
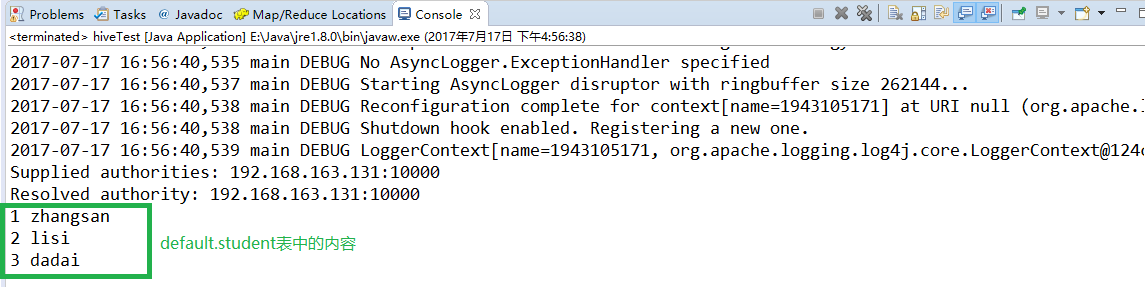
Step4: 右击代码 --> Run As --> Run on Hadoop,运行结果如下:
注: HWI的使用详见:http://www.cnblogs.com/xinlingyoulan/p/6025692.html















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









