






 OpenAI与DeepMind合作研发的最新算法,使用900bit人类反馈让AI系统在一小时内学会后空翻。通过人类选择的视频截图,系统学习目标并使用RL进行强化,减少了对复杂目标函数的依赖。已在模拟机器人和Atari游戏中展示强大性能,但面临人类反馈质量限制和可能的欺骗策略问题。
OpenAI与DeepMind合作研发的最新算法,使用900bit人类反馈让AI系统在一小时内学会后空翻。通过人类选择的视频截图,系统学习目标并使用RL进行强化,减少了对复杂目标函数的依赖。已在模拟机器人和Atari游戏中展示强大性能,但面临人类反馈质量限制和可能的欺骗策略问题。
编 | 王艺
编者按:
6月11日,Open.ai官方博客发文,宣布其与DeepMind安全部门合作开发的最新算法,该算法使用少量人为反馈进行强化学习,并能够处理更复杂的任务。仅需900bit的人类反馈,系统便学会了后空翻,需要人类参与的时间也从70小时将至1小时,该技术还能够被应用在更多其他方面,目前在虚拟机器人以及Atari平台的游戏上已经接受广泛测试。
构建安全AI系统的关键步骤之一是消除系统对人类编写的目标函数的需求。因为如果复杂的目标函数中有一点小错误,或者对复杂目标函数使用简单的代理,都可能会带来不是我们希望的甚至危险的后果。因此,我们与DeepMind的安全团队合作,开发了一种算法,可以通过人类告诉系统哪种行为更好而使系统得知人类的想法。
论文地址:https://arxiv.org/abs/1706.03741
我们提出了一种使用少量人为反馈来学习现阶段RL环境的学习算法。 有人类反馈参与的机器学习系统在很久之前就出现了,此次我们扩大了该方法的适用范围,使其能够处理更复杂的任务。仅需900bit的人类反馈,我们的系统就学会了后空翻,这是一个看似简单的任务,成功与否的评估方式简单粗暴,但具有挑战性。

仅需900bit的人类反馈,我们的系统就学会了后空翻
整体的培训过程是一个三节点的反馈循环,其中包括人类、代理对目标的理解、以及RL训练系统。

我们的AI代理最开始是在环境中随机行动,并定期向人类提供其行为的两个视频截图,人类选择其中最接近完成任务的一张(在这个问题下,是指后空翻任务),反馈给代理。AI系统逐渐地通过寻找最能表达人类目的的反馈函数(reward function)来创建该任务的模型。然后通过RL的方式学习如何实现这一目标。随着它行为的改善,它会继续针对其最不确定的环节征求人们对轨迹的正确反馈,并进一步提高对目标的理解。
我们的方法在效率上表现出色,如前所述,学会后空翻只需要不到1000bit的反馈数据。这就意味着,人类参与其中为机器提供反馈数据的工作时间不到一小时。而这一任务的平均表现为70小时(且模拟测量时假设的速率比实际操作时要快)。我们将继续努力减少人类对反馈数据的供应。您可以从以下视频中看到培训过程的加速版本。
我们已经在模拟机器人和Atari的许多任务上测试了我们的方法(系统没有访问reward function的权限:所以在Atari,系统没有办法访问游戏得分)。我们的代理可以从人类的反馈中学习,在我们测试的大部分环境中都能够实现强大的,甚至是超人的表现。 在以下动画中,您可以看到通过我们的技术训练的代理正在玩各种Atari游戏。 每个gif图片右侧的竖条表示每个代理预测的人类评估者将对其当前行为的认可程度。这些可视化表明,通过人类的反馈,1图中的代理在学习计量潜水舱中的氧气,2、3图中的代理在预估小球敲掉砖块的数量以及轨迹,或者在4图中学习如何从赛车撞车事故中恢复。
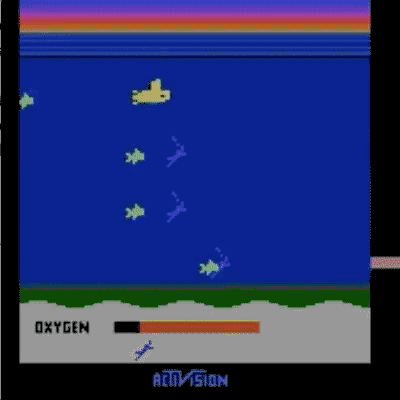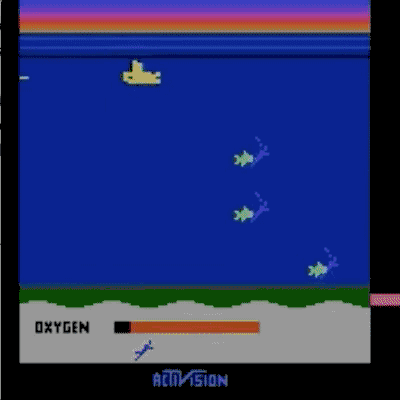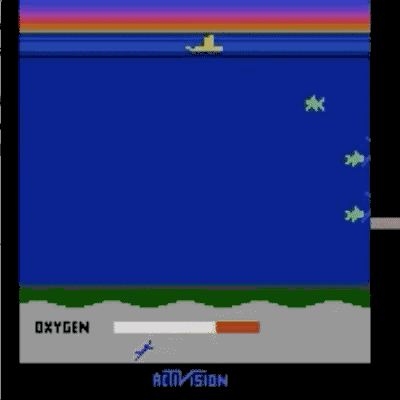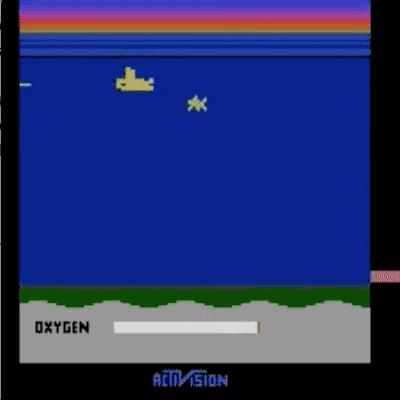


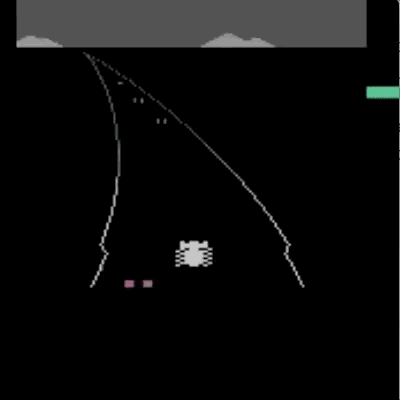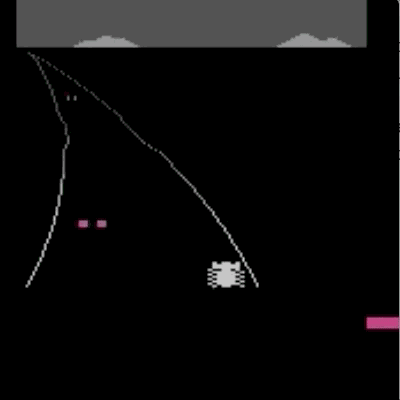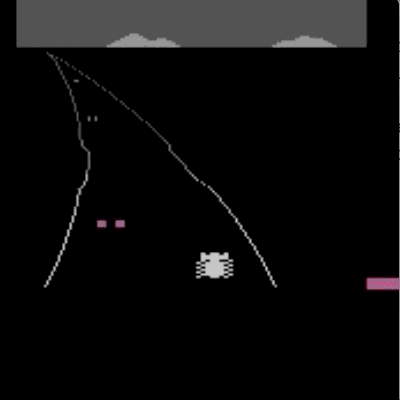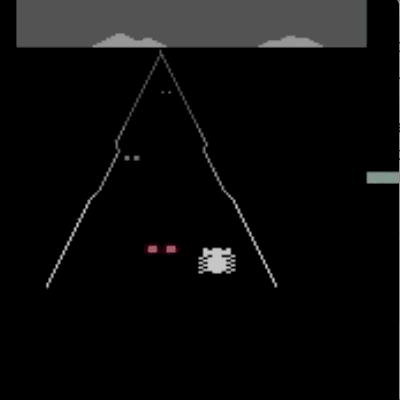
请注意,反馈不需要与环境中的正常的奖励函数保持一致:例如,在赛车比赛中,我们可以训练我们的代理,使其与其他车辆保持持平,而不是为了最大化游戏分数而超过他们。 我们有时会发现,从反馈中学习,比通过正常奖励函数进行强化学习效果更好,因为人类塑造的奖励,比环境中的奖励函数更有效。
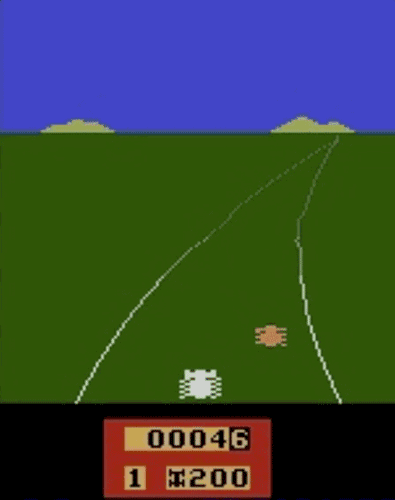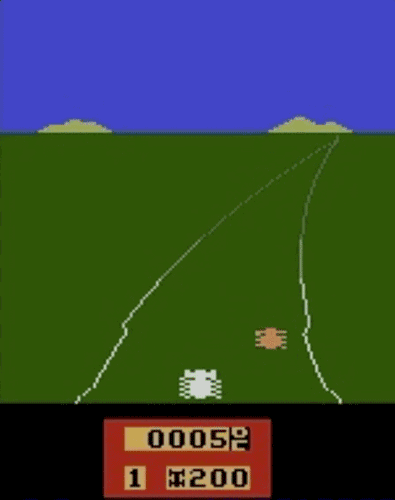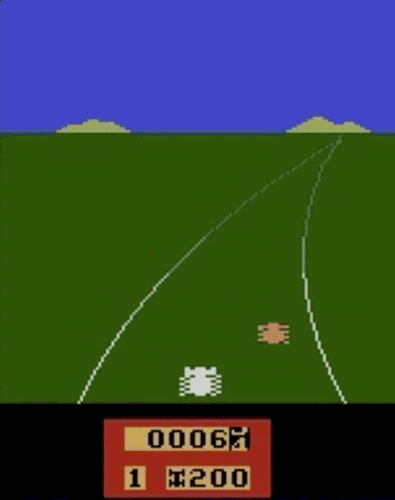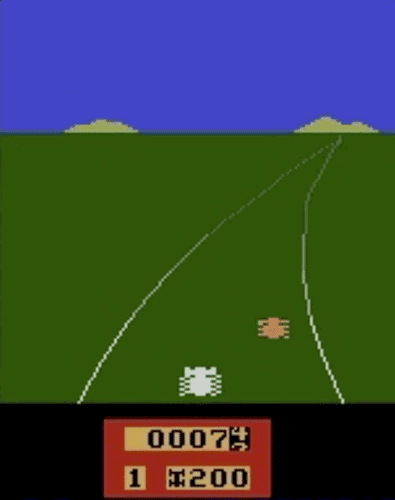
挑战与不足
我们算法的性能基于人类评价者对于什么样的行为看起来正确的直觉,所以如果人类对这个任务没有很好的把握,那么他们可能不会提供有用的反馈。 相应地,在某些领域,我们发现,系统可能会习得愚弄人类评价者的策略。 例如,如下所示,机器人的任务是抓取物体,而非将机械手放置在摄像机和物品之间,假装成正在抓取物品的样子。

对于这个特殊问题,我们通过添加视觉线索(上述动画中的粗白线)来处理,以便人类评估者轻松估计机械手的深度。
这篇文章中描述的研究是与雷尼姆德(LeMindMind)的Jan Leike,Miljan Martic和Shane Legg合作完成的。 我们两个组织计划继续就人工智能安全的主题展开长期合作。 我们认为,像这样的技术是迈向安全人工智能系统的一个环节,能够驱动机器实现像人类一样学习这一目标,并且可以补充和扩展现有的方法,如加强和模仿学习。 本文代表了OpenAI安全团队所做的工作,如果您有兴趣处理这样的问题,请加入我们!
脚注:
作为对比,我们花2小时写了一个reward function来训练系统后空翻(如下图),虽然它可以后空翻成功,但却明显不如开篇提到的GIF图中优雅。

我们认为,有许多情况下,比起手动编写对象代码,人类的反馈可以更直观,更快速地训练AI系统。
您可以通过下述代码在Open.ai gym中重现这个后空翻系统。
def reward_fn(a, ob):
backroll = -ob[7]
height = ob[0]
vel_act = a[0] * ob[8] + a[1] * ob[9] + a[2] * ob[10]
backslide = -ob[5]
return backroll * (1.0 + .3 * height + .1 * vel_act + .05 * backslide)2017中国人工智能大会(CCAI 2017)| 7月22日-23日 杭州
本届CCAI由中国人工智能学会、蚂蚁金服主办,由CSDN承办,最专业的年度技术盛宴:
- 40位以上实力讲师
- 8场权威专家主题报告
- 4场开放式专题研讨会
- 超过100家媒体报道
- 超过2000位技术精英和专业人士参会
与大牛面对面,到官网报名:http://ccai.caai.cn/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









