







本篇结合深度神经网络特点、postNorm与preNorm的公式阐释、实验结论以及具体Post Norm的用法来解释大模型结构设计中往往使用postNorm而非preNorm这一现象。
我们知道,大模型网络结构中基本上都用Post Norm,而几乎不用Pre Norm。其实Pre Norm与Post Norm之间的对比算是“老生常谈”的话题了,一个比较明确的结论是:
同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm。
那么是为什么呢?
本文通过公式阐释、实验结论以及具体Post Norm的用法来试图解释这个结论,下面是一个快捷目录。
1. 直观理解
2. 实验结论
3. PostNorm 结构的模型中 warm up 是如何起作用的?
一、直观理解
1. 结论
Pre Norm的深度有“水分”!
也就是说,一个L层的Pre Norm模型,其实际等效层数不如L层的Post Norm模型;而因为pre Norm实际层数少了导致效果变差了。
2. 公式阐释
1)Pre Norm 和 Post Norm的公式
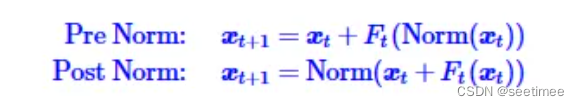
式中,Norm主要指Layer Normalization,但在一般的模型中,它也可以是Batch Normalization、Instance Normalization等,相关结
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









