







文章目录
- 1. int和Integer有什么区别
- 2. &和&&的区别
- 3. 简述Java的异常分类
- 4 .简述接口和抽象类的区别
- 5 .final关键词有哪些用法
- 6. 第⼀次执行String str = new String("abc")创建了几个对象,为什么?
- 7. String,StringBuffer,StringBuilder有什么区别
- 8. 列出⼀些常见的运行时异常
- 9. Collection和Collections的区别
- 10. HashMap和HashTable的区别
- 11. 成员变量、局部变量、类变量存储在内存的什么地方
- 12. 简述JDK8的内存结构
- 13. 列举你知道的几个的JVM参数
- 14.简述发生以下错误StackOverflowError,OutOfMemoryError的场景
- 15. 什么是守护线程,线程合并join方法的作用
- 16. Java开发手册禁止使用快捷线程池(也就是Executors),要求通过标准构造器ThreadPoolExecutor 去构造工作线程池。为什么?
- 17.ThreadPoolExecutor构造函数如下,简述每⼀个参数的作用?
- 18. 简述线程池的拒绝策略有哪些?
- 19. 下面代码运行结果是什么?说明原因
- 20 说明JDK1.7和JDK1.8中的HashMap的结构有什么不同?
- 21 简述JDK1.8中HashMap的原理,什么是扩容,链化和树化,分别发生在什么场景?
- 22 简述HashMap中的key的hashCode和equals的作用是什么?
- 23 说明JDK1.8的ArrayList的扩容机制
- 24 简述TreeMap的原理,以及什么是自然排序和定制排序,如何实现?
- 25 列举你熟悉的常见的IO流有哪些
- 26 如何在不改变String内存地址的情况下,改变String的内容
- 27 TCP协议和UDP协议的区别是什么?
- 28 为什么关闭连接的需要四次挥手,而建立连接却只要三次握手呢?
- 29 什么连接建立的时候是三次握手,可以改成两次握手吗?
- 30 为什么主动断开方在TIME-WAIT状态必须等待2MSL的时间?
1. int和Integer有什么区别
- int是Java的基本数据类型,而Integer是int的包装类。
- int直接存储整数值,而Integer是一个对象,包含了一些额外的方法和功能。
- int的默认值是0,而Integer的默认值是null。
2. &和&&的区别
- &是按位与运算符,用于对两个操作数执行位级别的逻辑与操作。
- &&是逻辑与运算符,用于对两个操作数执行逻辑与操作。
- &会对两个操作数进行按位与运算,并返回结果;而&&会进行短路逻辑与运算,只有在第一个操作数为真时才会对第二个操作数进行求值。
- 在条件判断中,&会对两个条件都进行判断,而&&只要有一个条件为假就会立即停止判断。
3. 简述Java的异常分类
Java的异常分为三种类型:
1.受检异常(Checked Exception):继承自Exception类,编译器强制要求必须处理的异常,可以使用try-catch块捕获或者在方法上使用throws关键字声明抛出。
例如
IOException在文件操作中可能会发生的输入/输出异常SQLException在数据库操作中可能会发生的SQL异常。ClassNotFoundException:在动态加载类时,找不到指定的类。
2.运行时异常(Runtime Exception):继承自RuntimeException类,通常由程序错误导致,不需要显式捕获或声明抛出,可以选择性地处理。
例如
- NullPointerException:当尝试访问空对象引用时抛出。
- ArrayIndexOutOfBoundsException:数组下标越界时抛出。
- ArithmeticException:在算术运算中出现错误时抛出,如除数为零。
3.错误(Error):继承自Error类,通常由严重的系统问题导致,无法恢复或处理。
例如
- OutOfMemoryError:当尝试使用更多内存超出JVM可分配的限制时抛出。
- StackOverflowError:当方法调用的堆栈太深而导致栈溢出时抛出。
- NoSuchMethodError:当尝试调用不存在的方法时抛出。
4 .简述接口和抽象类的区别
- 接口(Interface)是一种完全抽象的类,它只包含常量和抽象方法的定义,没有变量和方法的实现。一个类可以实现多个接口。
- 抽象类(Abstract Class)是一个可以包含抽象方法和具体方法实现的类,它不能被实例化,只能被子类继承。一个类只能继承一个抽象类。
5 .final关键词有哪些用法
- 修饰类:使用final修饰的类不能被继承,即为最终类。
- 修饰方法:使用final修饰的方法不能被子类重写,即为最终方法。
- 修饰变量:使用final修饰的变量为常量,一旦赋值后不可更改。
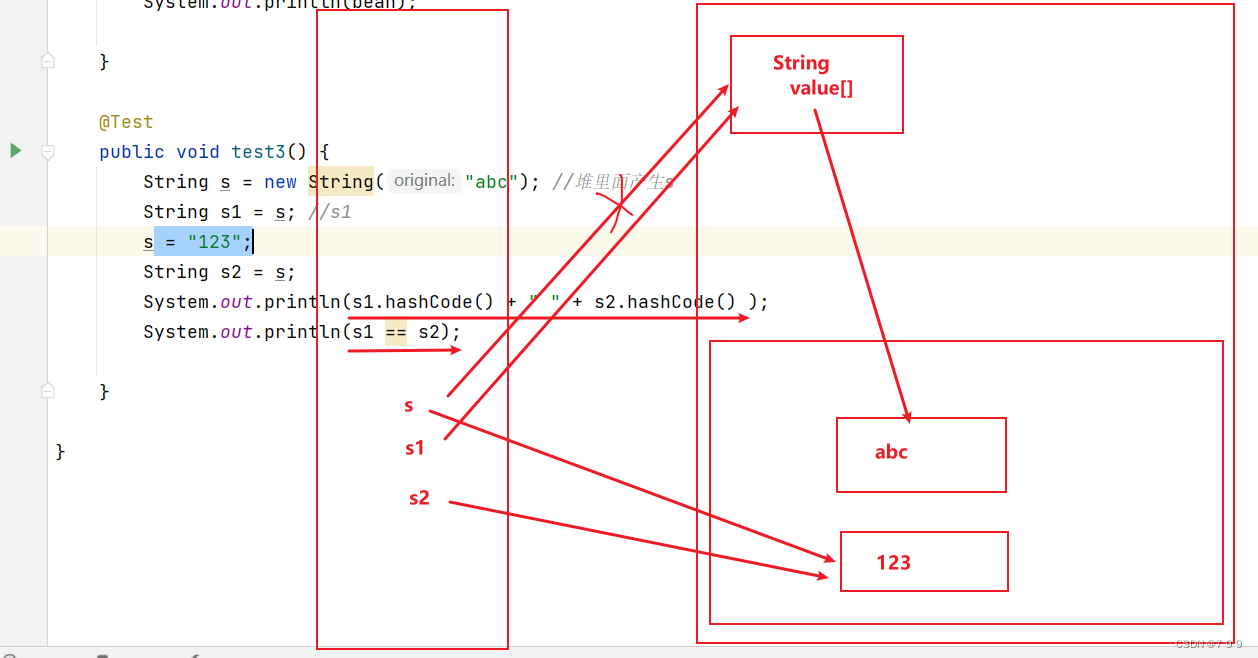
6. 第⼀次执行String str = new String(“abc”)创建了几个对象,为什么?
第一次执行 String str = new String(“abc”) 创建了两个对象:
- 一个是 “abc” 字符串常量,它存在于字符串常量池中。
- 另一个是 new String(“abc”) 创建的新的字符串对象,它存在于堆内存中。
7. String,StringBuffer,StringBuilder有什么区别
- String 类是不可变的,每次对字符串进行操作都会生成一个新的字符串对象,效率较低。
- StringBuffer 和 StringBuilder 类是可变的,可以进行字符串的修改操作,并且不会生成新的字符串对象。
- StringBuffer 是线程安全的,适用于多线程环境。
- StringBuilder 是非线程安全的,适用于单线程环境,效率更高。
8. 列出⼀些常见的运行时异常
- NullPointerException:空指针异常,当尝试访问空引用对象时抛出。
- ArrayIndexOutOfBoundsException:数组索引越界异常,当访问数组超出有效范围时抛出。
- IllegalArgumentException:非法参数异常,当方法接收到非法参数时抛出。
- ArithmeticException:算术异常,当发生除零或溢出等算术错误时抛出。
- ClassCastException:类转换异常,当尝试将对象强制转换为不兼容类型时抛出。
9. Collection和Collections的区别
- Collection 是 Java 集合框架中表示一组对象的接口,它是集合类的根接口。
- Collections 是一个包含了各种静态方法的工具类,提供了对集合进行排序、查找、同步等操作的方法。它不是集合类,而是一组操作集合的工具方法。
10. HashMap和HashTable的区别
- HashMap 是非线程安全的,而 HashTable 是线程安全的。
- HashMap 允许键和值都可以为 null,而 HashTable 不允许。
- HashMap 是通过 Iterator 进行迭代,而 HashTable 是通过 Enumeration 进行迭代。
- HashMap 是 JDK 1.2 引入的新集合类,而 HashTable 是早期的集合类,现在通常建议使用 HashMap 替代 HashTable
11. 成员变量、局部变量、类变量存储在内存的什么地方
成员变量、局部变量和类变量存储在不同的内存位置:
- 成员变量存储在对象的堆内存中,每个对象都有一份独立的成员变量副本。
- 局部变量存储在栈内存中,方法执行时会在栈上创建对应的局部变量空间,方法执行结束后会自动释放。
- 类变量(静态变量)存储在方法区(也称为永久代或元数据区)中,它属于类的属性,在 JVM 加载类的过程中被初始化,整个程序运行期间只有一份。
12. 简述JDK8的内存结构
1.程序计数器(Program Counter Register):记录当前线程执行的字节码指令地址。
2.虚拟机栈(VM Stack):存储方法调用的栈帧,包括局部变量表、操作数栈等信息。
3.本地方法栈(Native Method Stack):为虚拟机执行本地方法服务。
4.堆内存(Heap):存放对象实例,被所有线程共享。
5.方法区(Method Area):存储已加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
6.运行时常量池(Runtime Constant Pool):存放编译器生成的各种字面量和符号引用。
7.直接内存(Direct Memory):与堆内存不同,直接内存通过 Native 函数库直接分配内存,不受 Java 堆大小的限制。
这个只需要打出七个名称即可
13. 列举你知道的几个的JVM参数
- -Xms:设置初始堆内存大小。
- -Xmx:设置最大堆内存大小。
- -Xss:设置每个线程的栈大小。
- -XX:PermSize:设置永久代(JDK 8 之前)或元数据区(JDK 8+)初始大小。
- -XX:MaxPermSize:设置永久代(JDK 8 之前)或元数据区(JDK 8+)最大大小。
- -XX:+UseParallelGC:启用并行垃圾回收器。
14.简述发生以下错误StackOverflowError,OutOfMemoryError的场景
StackOverflowError
- 方法的无限递归调用
- 方法调用链过长
- 对象循环引用
OutOfMemoryError
- 创建过多的对象,超出堆内存的限制
- 大量线程的创建
- 加载过多的class文件
15. 什么是守护线程,线程合并join方法的作用
setDaemon(true) 方法
- 守护线程是一种运行在后台的线程,它的作用是为其他线程提供服务,不会阻止程序的终止。当只剩下守护线程时,JVM 就会退出。
join()方法会阻塞当前线程,直到目标线程执行完毕或达到指定的超时时间。join()方法通常用于实现多个线程之间的协同工作,即保证某个线程在其他线程执行完毕后再执行。这可以用来等待子线程完成任务、获取子线程的计算结果等。
16. Java开发手册禁止使用快捷线程池(也就是Executors),要求通过标准构造器ThreadPoolExecutor 去构造工作线程池。为什么?
Java开发手册禁止使用快捷线程池(例如Executors提供的方法),要求使用标准构造器ThreadPoolExecutor去构造工作线程池。这是因为快捷线程池在一些场景下可能会引发一些问题,例如:
-
FixedThreadPool和SingleThreadPool容易导致OOM(Out of Memory):这是因为这两种快捷线程池使用的是无界的LinkedBlockingQueue作为任务队列,当任务提交速度大于线程处理速度时,会导致任务队列不断增长,最终导致内存溢出。 -
CachedThreadPool和ScheduledThreadPool容易导致资源耗尽:这是因为这两种快捷线程池使用的是同步队列SynchronousQueue作为任务队列,当任务提交速度大于线程处理速度时,会创建大量线程,消耗系统资源,可能导致系统崩溃。
通过使用ThreadPoolExecutor的标准构造器,可以更加灵活地配置线程池参数,如核心线程数、最大线程数、任务队列等,从而避免上述问题。可以根据实际需求合理配置线程池,以充分利用系统资源,并且避免对系统产生过大的负载影响。
17.ThreadPoolExecutor构造函数如下,简述每⼀个参数的作用?
// 使⽤标准构造器,构造⼀个普通的线程池
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime, TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize:核心线程数,指同时能够执行任务的线程数量。maximumPoolSize:最大线程数,指线程池中允许存在的最大线程数量。keepAliveTime:线程空闲时间,指当线程池中的线程数量超过核心线程数时,多余的空闲线程在被终止之前等待新任务的最长时间。unit:keepAliveTime 的时间单位。workQueue:工作队列,用于存储还未被执行的任务。threadFactory:线程工厂,用于创建新的线程。handler:拒绝策略,指当线程池无法接受新任务时的处理方式。
18. 简述线程池的拒绝策略有哪些?
- AbortPolicy(默认):丢弃任务并抛出RejectedExecutionException异常。
- CallerRunsPolicy:由调用线程执行该任务,即主线程会执行被拒绝的任务。
- DiscardPolicy:直接丢弃任务,不做任何处理。
- DiscardOldestPolicy:丢弃最早进入工作队列的任务,然后尝试再次提交当前任务。
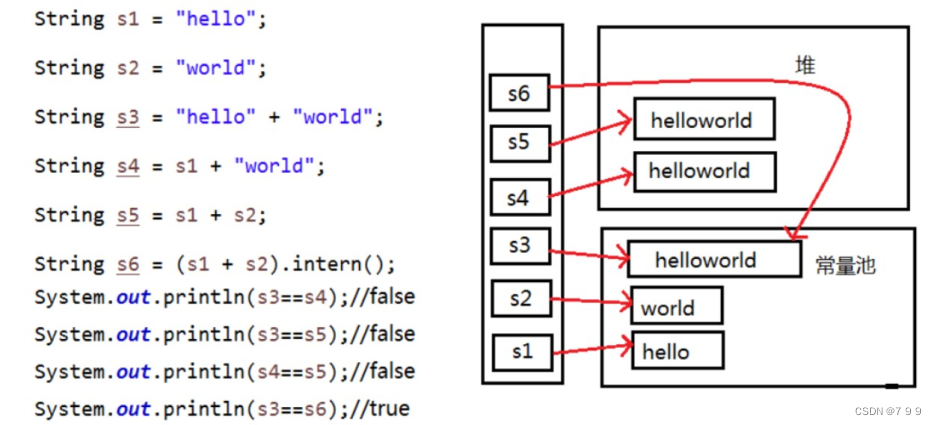
19. 下面代码运行结果是什么?说明原因
@Test
public void test2() {
String s1 = "hello";
String s2 = "world";
String s3 = "hello" + "world";
String s4 = s1 + "world";
String s5 = s1 + s2;
String s6 = (s1 + s2).intern();
System.out.println(s3 == s4);
System.out.println(s3 == s5);
System.out.println(s4 == s5);
System.out.println(s3 == s6);
}
运行结果:
false
false
false
true
因为,
s3指向常量池里的helloword字面量,而s4指向堆中对象
s3指向常量池里的helloword字面量,而s5指向堆中对象
s4和s5都指向堆中对象,但他们是不同对象,地址不一样所以false
s6通过intern()可以使其比较字面量的值,所以true
20 说明JDK1.7和JDK1.8中的HashMap的结构有什么不同?
JDK1.7和JDK1.8中HashMap的结构有所不同。JDK1.7中使用数组+链表的结构实现HashMap,而JDK1.8中引入了红黑树的概念,使用数组+链表/红黑树的结构实现HashMap。这是为了解决JDK1.7中当链表过长时导致查询性能下降的问题。
21 简述JDK1.8中HashMap的原理,什么是扩容,链化和树化,分别发生在什么场景?
JDK1.8中HashMap的原理是使用数组加链表/红黑树的方式实现。扩容发生在当HashMap中的元素数量超过负载因子(0.75)与数组长度的乘积时,会重新调整数组大小,并将原有元素重新分布到新的数组中。链化发生在当插入新元素时,如果该位置已经存在元素(也就是发生哈希冲突),则以链表的形式进行存储。树化发生在当链表长度达到一定阈值(链表长度为8,数组长度>=64)时,将链表转换为红黑树,提高查询效率,并且树还会在树上节点小于6时再次链化成为链表
22 简述HashMap中的key的hashCode和equals的作用是什么?
HashMap中的key的hashCode用于确定key在数组中的存储位置,equals方法用于判断两个key是否相等。hashCode和equals方法的正确实现保证了在HashMap中可以准确地找到对应的value。
23 说明JDK1.8的ArrayList的扩容机制
JDK1.8: ArrayList像懒汉式,一开始创建一个长度为0的数组,当添加第一个元素时再创建一个始容量为10的数组
当当前元素数量超过数组长度时,会创建一个新的更大长度的数组,并将原有元素复制到新数组中
扩容长度为原来的1.5倍
24 简述TreeMap的原理,以及什么是自然排序和定制排序,如何实现?
TreeMap是基于红黑树实现的有序映射数据结构。自然排序是指根据元素的自然顺序进行排序,例如数字的升序、字符串的字典序等。定制排序是指根据用户定义的Comparator进行排序。TreeMap通过红黑树的特性来保证元素的有序性和高效的插入、删除、查找操作。
25 列举你熟悉的常见的IO流有哪些
常见的IO流有:InputStream、OutputStream、Reader、Writer等。其中常见的实现类有FileInputStream、FileOutputStream、BufferedReader、BufferedWriter等,用于读写文件或其他流数据。
26 如何在不改变String内存地址的情况下,改变String的内容
setAccessible(true)
通过反射来获取string对象对其进行修改
27 TCP协议和UDP协议的区别是什么?
1.连接性:TCP是面向连接的协议,建立连接、传输数据、断开连接都需要进行握手和挥手等操作;而UDP是无连接的协议,发送数据时不需要建立连接和断开连接。
2.可靠性:TCP提供可靠的数据传输,它使用序号、确认应答、重传等机制来确保数据的可靠性和顺序性;而UDP不提供数据可靠性保证,仅仅把应用程序传给它的数据报发送出去,不保证数据是否安全到达目的地。
3.有无拥塞控制:TCP具有拥塞控制机制,可以根据网络状况动态调整发送速率,以避免网络拥塞;UDP没有拥塞控制机制,数据发送速率取决于发送端的速度。
4.通信效率:由于TCP在传输过程中需要进行三次握手、四次挥手等操作,以及拥塞控制等机制,因此相对于UDP来说传输开销较大,通信效率相对较低;而UDP没有这些额外的开销,传输效率较高。
5.适用场景:TCP适用于对数据传输可靠性要求较高的场景,如文件传输、网页访问、电子邮件等;UDP适用于实时性要求较高、数据传输可靠性要求较低的场景,如音视频流媒体、实时游戏等。
28 为什么关闭连接的需要四次挥手,而建立连接却只要三次握手呢?
关闭连接时,被动断开方在收到对方的FIN结束请求报文时,很可能业务数据没有发送完成,并不能直接立即关闭连接,被动方只能先回复一个ACK响应报文,告诉主动断开方:“你发的FIN报文我收到了,只有等我所有的业务报文都发送完了,我才能真正的结束,在结束之前,我会发你FIN+ACK报文的,你先等着”。所以,被动断开方的确认报文,需要拆开成为两步,故总体就需要四次挥手。
而建立连接场景中, Server端的应答可以稍微简单一些。当Server端收到Client端的SYN连接请求报文后,其中ACK报文表示对请求报文的应答,SYN报文用来表示服务端的连接也已经同步开启了,而ACK报文和SYN报文之间,不会有其他报文需要发送,故可以合二为一,可以直接发送一个SYN+ACK报文。所以,在建立连接时,只需要三次握手即可。
29 什么连接建立的时候是三次握手,可以改成两次握手吗?
三次握手完成两个重要的功能:一是双方都做好发送数据的准备工作,而且双方都知道对方已准备好。二是双方完成初始SN序列号的协商,双方的SN序列号在握手过程中被发送和确认。
如果把三次握手改成两次,可能会发生死锁。两次握手的话,缺失了Cilent的二次确认ACK帧,
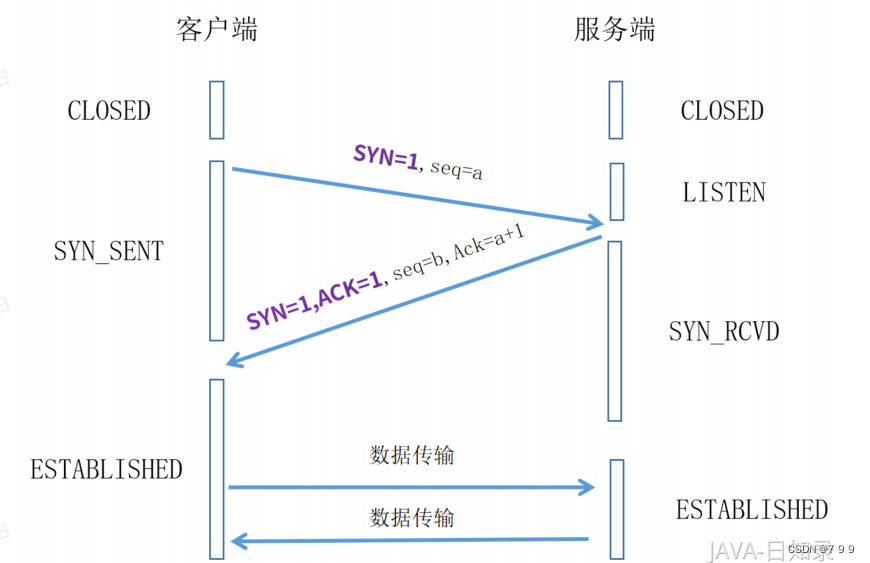
这是一个假想图,Client向Server发送一个SYN请求帧,Server收到后发送了确认应答的SYN+ACK帧,按照两次握手的协定,Server认为连接已经成功地建立了,可以开始发送数据帧。这个过程中,如果确认应答SYN+ACK帧传输中被丢失,Client没有收到,Client将不知道Server是否已经准备好,也不知道Server的SN序列号,Client认为连接还未建立成功,将忽略Server发来的任何数据,会一直等待Server的SYN+ACK确认应答帧。而Server在发出数据帧后,一直没有收到对应的数据帧后,一直没有收到对应的ACK确认后,就会产生超时,重复发送同样的数据帧,就形成了死锁
30 为什么主动断开方在TIME-WAIT状态必须等待2MSL的时间?
在TCP协议中,当一端主动断开连接时,会进入 TIME-WAIT 状态,并等待一段时间(2倍的最大报文段生存时间,MSL)才能彻底关闭连接。这个等待时间主要有以下几个原因:
1.确保旧连接的所有数据都被接收:TIME-WAIT 状态的目的是为了确保网络中的所有数据报文都被接收和处理完毕。即使另一端已经发送了关闭连接的确认报文(FIN),但在网络中可能仍然有一些报文需要运行一段时间才能到达。等待一段时间可以确保这些延迟的报文到达并被接收。
2.防止旧连接的报文在新连接中混淆:如果一个新的连接在旧连接的 TIME-WAIT 状态结束前建立起来,并且使用了相同的 IP 地址和端口号,那么可能会导致旧连接的持续报文被错误地传递给新连接。通过等待一段时间,可以确保旧连接的所有报文都从网络中消失,避免混淆。
3.允许旧连接的重传报文到达目的地:在 TCP 协议中,报文的重传是常见的情况。在 TIME-WAIT 状态期间,旧连接的任何重传报文都可以被正确地处理。如果立即关闭连接而不等待,那么可能会导致重传报文被误认为是新连接的报文。
总结起来,等待 2MSL(最大报文段生存时间)的时间可以确保旧连接的所有数据都被接收和处理,防止旧连接的报文与新连接混淆,并允许旧连接的重传报文到达目的地。这样可以保证网络的可靠性和连接的正确关闭。
















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









