






相信大家已经知道,对于联合索引,索引失效的情况
- 最左前缀
- 模糊查询,如%工程
- >,<
从这里我们可以发现,索引失效往往是出现范围查找时出现的问题?
这三种情况在这里我就不一 一说明了。我们就解决一个问题,
为什么>后面的索引会失效,但是>=后面的索引不会失效?-相信解决这个问题之后,其他的问题也就解决了。
接下来我们看看在没有范围查询时,联合索引是怎么进行查找到。
我们对num,name,和email建立联合索引。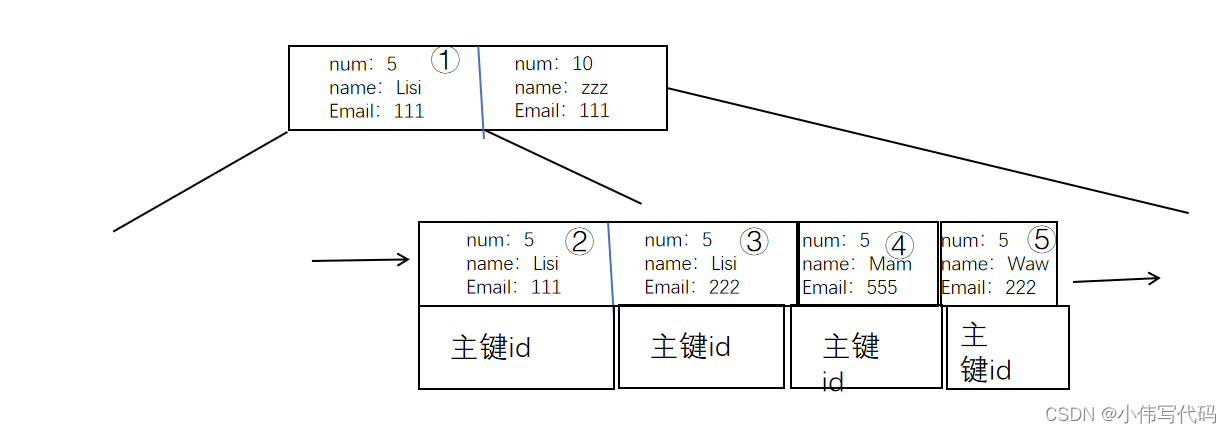
假设上图就是建立好的b+树索引,对于b+树而言,所有数据都会按顺序保存在最后一层。上面的所有层只是作为索引,加快查找速度。也就是说最终的目的,就是通过索引在最底层找到对应的数据了。
- 当我们要找num=5,name=‘Lisi’,Email=111的时候,
先通过num=5在序号一之后,通过指针,走到序号2,发现数据一致,通过其所对应的主键id,回表查询数据。
- 当我们要找num=5,name>=‘Lisi’,email=222时
先根据num找到序号1,然后找name=‘list’,发现也是序号1,然后找email=222,找到序号三,此时找到了第一个符合条件的值,到这里是否已经完成查找了吗?其实并没有,我们来看序号四,会发现序号四其实并不符合条件,但是序号5又是符合条件的。(并不是序号三之后的所有元素都符合条件)。既然存在这个问题,那么mysql是如何解决的呢?,很简单,当确定了序号3是第一个元素之后,由于b+树是有顺序的,所以mysql会从序号3开始,去遍历其右边所有的数据,找到所有符合条件的情况。
那这里到底有没有使用到email的索引呢?
很显然使用到了,我们通过email=222找到了符合条件的第一个数据序号3通过序号3来遍历的。
这样是合理的,可以避免全部遍历。
所以我们可以知道,所谓的走了索引,只是表示在搜索时,使用了这个索引,但是并不代表只使用了索引,在这里其实依然是有遍历的。
按照我们以上的理解,不应该会使用索引么,为什么>会导致索引失效呢?
当我们使用>号时,又会发生什么呢?
num=5,name>‘Lisi’,email=222时,
会先根据前两个条件找到序号一,然后在底层找到序号一的对应序号二,然后直接从序号2开始遍历。
整个过程完全没有使用email。
为什么不使用email呢?
因为条件是>Lisi,那么找到name=Lisi,email=111的这条数据完全没有意义(并不是第一个符合条件的数据,但是符合条件的数据一定在这个数据后面)。
为什么不像之前一样,先找到最左边的数据(第一个满足条件的数据),也就是序号5呢,这样不是可以避开一些多余遍历,提高性能吗?
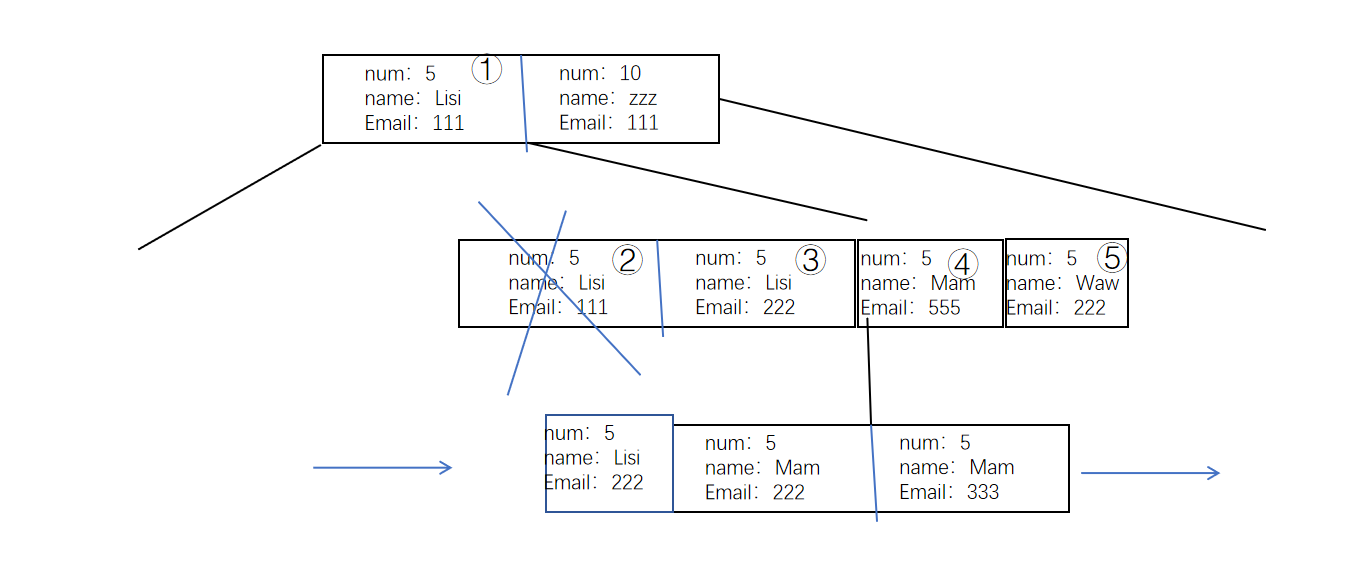
从这里我们可以发现,第一个符合条件的数可以在序号三和序号四之间,也可以在序号四序号五之间,也可以在序号5后面,我们要在检索时就找到第一个符合条件的数是非常困难的(事实上也需要逐个遍历),效率反而更低了。
出现这种情况最主要的原因其实就是在范围搜索之后的索引,也就是这里的emal,在搜索中并不能起到一个确定作用(>=除外)。范围查询索引失效其实就是这个问题。















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









