






泛型
在学习泛型的时候,我们是否会有这样的疑惑?
1.java是怎么实现泛型擦除的呢?
2.java是怎么进行自动类型转换的呢?
3.为什么泛型不支持基本类型int,string?
4.为什么不可以 T t=new T()?
5.既然会擦除(T)为(Object),那这样的强转还有什么意义?
6.为什么不能给静态泛型 public static T t;为什么不行
。。。
当真正理解泛型,这些问题自然不再是问题。这篇文章我们就会一一为大家解惑。
前置知识
- 我们一定要搞清楚,编译,加载两者之间的关系。
编译:生成.class字节码文件的过程,.class字节码文件,这个文件记录了所有代码信息,可以反编译成我们真正运行的代码。这里一定要注意,.class文件记录的是类的所有信息,而不仅仅只是反编译成的代码,比如类名,方法名等等信息,都会记录。而最后生成的Class对象,也不仅仅是反编译出来的代码运行!!!,举个最简单的例子,我们可以通过Class对象获取类名,而仅仅是运行这个代码是做不到的。
加载:表示将.class字节码文件写入内存的过程,此过程一般是通过类加载器来完成,而类加载器又分为两种【事实上有四种,这里暂且这么认为】,一种是启动了类加载器。String,Integer这些java提供的类,这些类会在编译的时候就加载。而我们自己写的类是懒加载,也就是当我们使用到一个类时【主函数调用到】,会先去内存中找,找不到,再去class文件中找,找到后生成Class对象保存到内存。——————》由此我们知道,每个Class对象其实是通过.class文件生成的,.class文件记录了类的所有信息,每个类只有一个Class对象。
- 我们还需要理解编译逻辑
class Test{
public void set(int a){
return a;
}
}
public class Main {
public static void main(String[] args) {
Test test=new Test();
test.set(111);
}
}我们思考一个问题,当编译test.set(111);的时候,编译器是怎么知道我们只能传入int类型的,类型的限定是在Test类中,而方法的执行却在Main中!!!【编译相当于将信息保存下来了】
编译和加载是不一样的,加载我们奉行懒加载,而编译我们是一次性全部编译,流程是如下:
- 编译器查看myClass的类型(在本例中是MyClass)。
- 在MyClass类中查找名为test的方法,并检查其方法签名(方法名和参数类型列表)。在本例中,MyClass类中有一个签名为
public int test(int a)的方法。 - 编译器检查123这个参数值的类型(int),看它是否与方法签名中的int参数类型匹配。因为匹配,所以编译通过。
- 编译器记录该方法调用的返回值类型是int。
接下来我们进入正式的泛型学习中。
基本使用
什么是泛型
这里先说结论,
总泛型对类没有意义,但是对 对象是有意义的。(对象知道自己的泛型是什么,但是类不知道!!!,同时也可以说只有在new 对象之后,泛型才会生效)
1. 什么是泛型呢?我们先来看一下泛型的基本使用。
class MyArrayList<E> { public E set(E e) { return e; } } public class Main { public static void main(String[] args) { MyArrayList<String> list = new MyArrayList<>(); list.set("aaa"); list.set(123);//报错 } }
当我们在类上指定泛型,这个泛型就能当作类去使用。当我们指定list的泛型是<String>,那么E就只能接收String类型数据。这里主要体现了泛型的作用如下:
1. 限制传入数据类型
· 在new的时候限制传入类型,一旦传入非此类型数据,立马报错。 就类似int b =“abc”类型不能报错类似。
注意,泛型只在此时起到了作用(因为list是new出来的对象),之后的任何使用,都会进行泛型擦除,起不到任何作用【暂时先怎么说,便于理解】。
2. 优化Object需要强制类型转换的问题
· 被使用者不知道使用者会传入什么类型数据,如果我们没有给集合指定类型,默认所有数据都是
Object,Object类作为所有类的父类,无法使用子类的特有方法【多态】。如果要使用,我们需要
强制类型转换,这样势必会导致代码写死的情况。
· 事实上,泛型由于擦除机制,一样无法调用方法,依然要强制类型转换,只不过这个类型转换编译器
帮我们自动完成了,也就是自动类型转换。。。。。。【具体怎么转,往下看】
泛型擦除机制:
1. 泛型只是一个编译期技术,也就是说,编译MyClass时,主函数可能压根还没有编译,更别说知道传入什么类型了!!!
为了正常编译,所有的<E>会被擦除,E会变成Object。
class MyClas<T>{
T t;
}
//真正使用的时候其实会变成
class MyClas{
Object t;
}假如这里传入的泛型是<String>。t在使用过程中,其实依然是Object类型,是无法调用 T .String的特有方法的。(简单说,就是他现在还不是一个对象!!!)
2.这里的擦除并不是完全擦除,而是转换成他的第一边界。(这个可以先不管,后面会说)
接下来我们看一下以下代码
public class Main {
public static void main(String[] args) {
MyArrayList<String> list=new MyArrayList<>();
list.add("aaa");
String s = list.get(0);//按照之前的理解,这里应该是Object s才对啊。
}
}2.按照我们之前的理解,“aaa”存入之后,不是会变成Object类型吗?那为什么get返回的依然是String类型呢?
这里非常重要!
我们来看一下源码。
public class MyArrayList<E> {
private Object[] elem;
public E get(int index) {//返回E类型
return (E)elem[index];//可以强转
}
public void set(int index, T e) {//存入的时候就是泛型,只不过擦除之后变成Object,但是依然具备泛型的功能
elem[index] = e;
}
}对.class文件进行反编译之后其实会变成
public class Test {//<E>被擦除
private Object[] elem;
public Object get(int index) {//返回E类型
return elem[index];//(E)被擦除
}
public void set(int index, Object e) {//存入的时候就是泛型,只不过擦除之后变成Object,但是依然具备泛型的功能
elem[index] = e;
}
}我们会发现程序真正执行的代码返回的Object类型,那为什么可以用String接收呢?
这得益于编译器的“自动类型转换机制”
我们看一下主函数 String s = list.get(0);这句化的字节码文件。
L2
LINENUMBER 7 L2
ALOAD 1
ICONST_0
LDC "aaa"
INVOKEVIRTUAL test111/MyArrayList.set (ILjava/lang/Object;)Ljava/lang/Object;
CHECKCAST java/lang/String //自动类型转换
ASTORE 3看第七行, java/lang/String这不就是泛型类型吗!其实这一段的意思其实就是自动类型转换。当虚拟机运行这段代码的时候,会根据这个信息,将Object转换成String。
从这里我们可以知道,自动类型转换是记录在主函数的(new的哪个地方)!这个对象在new的时候,会记录下泛型,所以当然知道泛型是什么!
我看了很多资料,很多都说是在return (E)elem[index]; (E)的位置插入(String)的类型转换,其实这样理解是有误差的,这一步其实是在运行的时候执行的,也就是虚拟机执行的,而不是编译的时候! 所以我一度以为自动类型转换的信息是记录在MyArrayList类里的,其实不是,这个类压根不知道泛型是什么类型!
3.那我们来看一下如果对泛型修改会发生什么问题?
- 这个类压根不知道泛型是什么,也即是根本不知道这里的T是String类型
- 同时这样做会破坏类的唯一性(产生类爆炸),如果我们
ArrayList<String> list=new ArrayList<>();
list = new ArrayList<Integer>();//报错
泛型会被擦除成Object,为什么这里不可以赋值呢?
因为对象知道自己的泛型是什么!!!
4.那么编译器又是怎么知道自己要转换,并且转换成什么类型呢?
这就类似于java中的父子类之间的转化 如果有一个父类,和子类
Object obj = new String(); 这种写法事实上不准确,但是方便理解就这样写
虽然儿子对象是用父亲接收的但是这个类本身是从儿子转过去的,他依然具有儿子的所有特性,只不过这些特性暂时被隐藏了起来
方便大家理解,这里给大家画一个图。
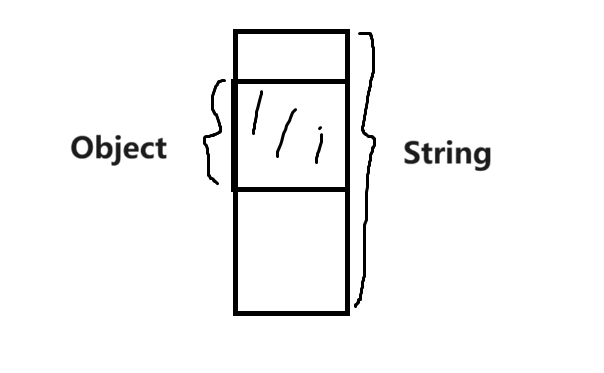
通过这个图,简单的理解下。我们用Object来存储String,但是Object是父类,功能少,占用内存少,只能访问自己的那一块空间,一旦超出,就会内存越界。虽然Object访问不了String的特性,但是String的内存依然在那保留着。我们依然可以对Object进行强转,成为String。【当然内存的真实分配肯定没有这么简单】
同理到我们这里,虽然泛型所有都是Object,但是数据真实占用的内存是真实不变的,所以说,虚拟机依然可以通过访问这块空间,来确定实际类型!
再次声明一遍,数据本身的 内存/真实类型 是不会变的!
5.那(E)不应该也会被擦除成为(Object)吗,你这样强转不是没有意义吗?
public class MyArrayList<E> {
private Object[] elem;
public E get(int index) {//返回E类型
return (E)elem[index];//可以强转
}
}其实不然,虽然E会进行泛型擦除,但是在擦除前,T其实会被当作一个未知类型去处理的,get方法返回值是T,为了满足语法的统一性,我们需要对elem也进行强转,虽然这个强转没有意义。
我们再来看看一下代码。
public class Main {
public static void main(String[] args) {
MyArrayList<String> list=new MyArrayList<>();
String aaa = list.set(0, "aaa");
Integer test = list.test(123);
String s = list.get(0);
}
}
class MyArrayList<E> {
private Object[] elem=new Object[10];
public E set(int index, E e) {
elem[index] = e;
System.out.println(e.getClass());//插入这一句话
return e;
}
}6.最后会输出class java.lang.String,按照我们之前的理论,e应该是Object类型,他从头到尾应该都不知道自己是String类型才对啊,为什么会这样呢?
继续沿用上面的理论。
数据的本身类型是真实存在的,无论用上面父类接收,但是他自己本身就是原来的类型!!!
所以e.getClass();的意思就是传入数据的类型。
再次声明一遍,数据本身的 内存/真实类型 是不会变的!
总结:也就是说,我用泛型接受一个对象,泛型本身没有含义,但是传入的对象本身是有意义的!!!
到这里为止我们的理论体系基本已经构建完成(当然后面还会介绍一些特性),到这里我们已经可以解决很多泛型问题了。
问题解决
问题1:为什么泛型不支持基本类型?
按照前文,所有的泛型都是Object,而int,string此类基本类型是无法转换成Object的。
问题2:相信大家会有这样的疑问。为什么不能使用泛型的形参创建对象?T t=new T();————》Object t=new Object();
T t=new T();————》Object t=new Object();看似好像可以,但是,编译时,T在擦除前,就是一个不确定类,只是起到一个占位标示作用。而具体的new()是需要具体的信息的。连new都new不了,压根就没有擦除成Object t=new Object();一说。
泛型本身没有意义,只不过他接受了有意义的对象之后,变的有意义了!!!
所以直接去new一个没有意义的东西,肯定报错!!!
问题3:不能给静态成员变量定义泛型
class MyArrayList<E> {
public static E e;//报错
public static E set(int index, E e) {//报错
return e;
}
}我们会发现,E是不能定义在static中的,会报“无法从 static 上下文引用 'test111.MyArrayList.this'”的错误。这是为什么呢?很简单,我们的E是定义在类上的,而静态就意味着,我们根本不需要创建对象,直接就可以调用,这显然是不允许的。无法引用上下文错误,也是因为这个,我们可以把静态代码块看作独立的一部分,他和其他非静态是隔离的【这样我为了保证其可以独立被调用所设计的】。
还是那句话,泛型本身是没有意义的,只有接受了有意义的对象之后,才会变得有意义,而普通的对象,只有被调用是才执行,这个时候,对象已经传过来了,所以这个泛型已经有意义了!!但是如果是静态,这个对象没有创建也可以调用这个方法 ,那么类没有,类上的泛型也就不存在 ,而静态方法也无法获取这个泛型!!!
既然静态无法获取类上的泛型,那方法上的泛型能不能获取呢?【泛型方法后面会说,这边举例是为了更好的展示】
class MyArrayList<E> {
public static <T> T set(int index, T t) {
return t;
}
}这里会发现是没有问题的! 因为泛型本身就定义在了静态方法上,当然可以获取信息。
这就涉及静态的知识,类是独立的,但是方法不是,也就是说,这个方法只有被调用时才执行,执行时,调用者一定已经指明泛型了!!!
问题4:泛型引用问题,泛型不一致的类可以互相赋值吗?
// 错误写法1:间接传递(通常发生在方法传参,比如将stringList传给print(List<Object> list))
List<String> stringList = new ArrayList<>();
List<Object> list = stringList;
// 错误写法2:直接赋值
List<Object> list = new ArrayList<String>();
这两种写法都是不被允许的。这就有问题了,List<String> 会被擦除成List,List<Object>会被擦除成List,既然如此为什么不可以互相赋值呢?
这个问题在现在看来,是不是很简单了,对象知道自己的泛型,当然不能赋值了
首先ArrayLIst类中的泛型本身没有意义,但是被赋值之后,就变得有意义了,所以我们在new的时候指定了String,所以此时他已经有意义了 ,所以他并不能被List<Object>接受!!!
那问题就来了,Object不是String的父类吗,为什么不能赋值!!!
这里强调一点
Object是String的父类,但是List<Object> 并不是List<String> 的父类,本质上,他的类型只是List,只不过是带有泛型的List,而泛型本身不是类,但是他会防御限制不同的泛型的值传给我
问题5:List<String>.class 和 V.class为什么不被允许?
Object list = JSON.parseObject(json, List< String >.class);//error
List<Object> list = JSON.parseObject(json, List.class);//ok
List<String> list = new ArrayList();
Class<? extends ArrayList> aClass = list.getClass();//Ok ==> List
V.class;//error
v.getClass();//ok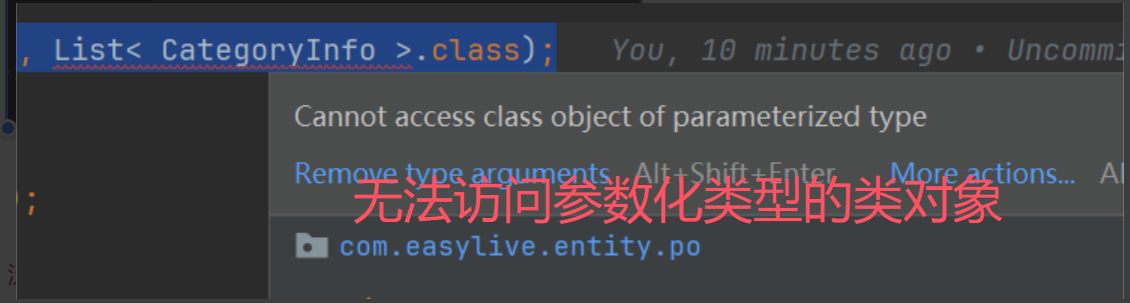
泛型本身没有意义,V.class不被允许,但是v是已经赋值完的泛型,他已经有意义了,所以他可以获取到反射对象。
泛型本身没有意义,所以List< String >.class连对象都没有创建,这就和直接V.class一样,没有意义。
strings.getClass();可以,是因为我已经创建了对象,泛型本身没有意义,但是创建了对象是有意义的,所以可以通过对象获取反射。
问题六:获取的反射有没有泛型信息?
List<String> list = new ArrayList();
Class<? extends ArrayList> aClass = list.getClass();
System.out.println(aClass);// ArrayList我们发现获取到的反射类是ArrayList,并不包含泛型为什么呢?
泛型本身是没有意义的,而反射的本质就是独立的类(即使没有new这个类也存在),既然如此当然没有泛型(泛型只有在赋予值之后才有意义)。
问题七:我们怎么证明泛型本身没有意义,只有在赋值之后才有意义这句话呢?
public static void main(String[] args) {
List<String> list1 = new ArrayList<>();
List<Integer> list2 = new ArrayList<>();
System.out.println(list1.getClass()==list2.getClass() ?"true":"false");
ArrayList<String> type1 = new ArrayList<String>() {};
ArrayList<Integer> type2 = new ArrayList<Integer>() {};
System.out.println(type1.getClass()==type2.getClass() ? "true":"false");
}
//true false我们知道,反射类是最原始的类,他本身就与泛型相冲突,上面都是ArrayList,不管你泛型相不相同,但是反射类是相同的,所以是true
下面是匿名类,这个类已经不是ArrayList类了,而是他的匿名子类(类似于加入了我们自己方法的子类),但是我们并不能调用我们自己定义的方法(虽然我们这里没有写任何方法),这是因为这个子类付给了父类,父类不能调用子类的方法。跑远了,回到问题中,所以type1和type2都是ArrayList不同的俩哥哥子类,那么他们的反射当然也不同。
获取泛型
泛型本身没有意义,但是赋值之后是有意义的,也就是说,赋值后的泛型是又意义的,那要如何获取泛型呢?
第一步构造两个类,一个是实际的泛型对象FanDto,一个是用来获取泛型参数的类FanDemo
public class FanXin<T>{
T data;
String name;
public T getData(){
return data;
}
public void setData(T data){this.data = data}
}
public class FanDemo<T>{
private FanDemo(){}
}第二步我们获取父泛型类FanDemo
//实例化获取匿名子类
Class fanClass = new FanDemo<FanXin<String>>(){}.getClass();
//通过匿名子类获取泛型父类
Type type =fanClass.getGenericSuperclass();
ParameterizedType genericType = (parameterizedType) type;
System.out.println(genericType);
//com.jointem.base.vo.FanDemo<com.jointem.base.vo.FanXin<java.lang.String>>到这里大家可能会感到很蒙蔽,大致会有一下四种疑问,在这里我会一一为大家解答。
为什么必须要获取的是匿名子类的反射对象?
泛型本身没有意义,只有我们给予他意义之后,他才会有意义,也就是说,泛型对于一个类而言,是没有意义的,它只对对象有意义!!!也就是说,我们直接通过类的反射去拿,是拿不到反射信息的!
那为什么我们要使用匿名对象呢,直接new不行吗?
这里我举个例子大家就知道了
List<String> list1 = new ArrayList<String>();
List<String> list2= new ArrayList<String>();
List<Integer> list23= new ArrayList<Integer>();
List<String> list4= new ArrayList<String>(){ };
list1.getClass(); //java.lang.ArrayList
list2.getClass();//java.lang.ArrayList
list3.getClass();//java.lang.ArrayList
list4.getClass();//class com.easylive.component.RedisComponent$1
无论是list1,list2, list3他们获取的是类对象,这个类对象是一个新的对象,他不依附于任何用它创建的对象,所以说,虽然list1,list2,list3是三个对象,但是他获取的类对象是同一个。
但是list4不一样,list4类似于我们新写了一个类(ArrayList<String>的子类),所以我们获取到的父类信息中,就包含泛型信息。
ParameterizedType类型是什么类型 ? 和Class有什么区别?
parameterized:参数 ==》 参数类型
我们可以理解为Type,就是有泛型的Class
- 如果父类是参数化的泛型(如 ArrayList<String>),返回的是 ParameterizedType。
- 如果父类是非泛型类(如 ArrayList),返回的是 Class。
- 如果父类是泛型变量(如 T),返回的是 TypeVariable。
为什么不能直接返回Class?
Class 是 Java 中的一个具体类,只能表示原始类型(raw type)。然而,当父类是泛型时,需要更多的信息来描述泛型的类型参数
getGenericSuperclass()方法有什么含义?
获取父类的类对象(getClass()方法获取到的是当前对象的类对象)
为什么一定要搞一个FanDemo<T>,直接使用FanXin可不可以?
可以,这里只是做一个展示
我发现我们已经获取到了泛型父类FanDemo
第三步通过泛型父类获取目的泛型类FanDto
泛型父类类型为ParameterizedType类型,通过getActualTypeArguments获取泛型参数数组
//实例化获取匿名子类
Class fanClass = new FanDemo<FanXin<String>>(){}.getClass();
//通过匿名子类获取泛型父类
parameterizedType genericType =fanClass.getGenericSuperclass();
//获取泛型参数组,这里我们FanDemo只有一个泛型,所以数组只有一个
Type[] types = genericType.getActualTypeArguments();
for(Type type : types){
parameterizedType parameterizedType = (parameterizedType)type;
System.out.println(parameterizedType.getTypeName());
}
com.jointem.base.vo.FanDto<java.lang.String)这个时候我们获取到了我们想要的泛型对象FanDto,接下来我们需要获取FanDto的泛型参数
第四步 获取FanDto的泛型参数T的类型
//实例化获取匿名子类
Class fanClass = new FanDemo<FanXin<String>>(){}.getClass();
//通过匿名子类获取泛型父类
parameterizedType genericType =fanClass.getGenericSuperclass();
//获取泛型参数组,这里我们FanDemo只有一个泛型,所以数组只有一个
Type[] types = genericType.getActualTypeArguments();
for(Type type : types){
parameterizedType parameterizedType = (parameterizedType)type;
//再次获取泛型参数
Type[] type1s = parameterizedType.getActualTypeArguments();
for(Type type1 : type1s){
System.out.println(type1.getTypeName());
}
}
java.lang.string这个时候我们得到了FanDto的泛型类型为String,ok 大功告成
最后通过获取泛型对应的字段
Class cls =new FanDto<String>().getClass();
TypeVariable[]typeVariables =cls.getTypeParameters()
for(TypeVariable typeVariable:typeVariables){
System.out.println(typeVariable);
}
Field[]fields = cls.getDeclaredFields();
for(Field field : fields){
System.out.println(field.getGenericType());
}
T
T
class java.lang.String泛型体系已经构建起来了,泛型的一些问题我们也已经解决,接下来我们拓展一下泛型的使用。
泛型的拓展
我们希望指定一个泛型,编译器可以顺便帮我们监管一下他的所有子类,或者父类这要怎么做呢?
这就引出了我们的泛型的通配符。
?表示不确定的类型
它可以进行类型的限定
? extends E : 表示可以传递E或者E所有的子类类型【继承了E的所有类】
? super E :表示可以传递E或者E所有的父亲类型
class YE{}
class Fu extends Ye{}
class Zi extends Fu{}
class Student{}
public class Main{
public static void main(String[] args){
ArrayList<Ye> list1 = new ArrayList<>();
ArrayList<Fu> list2 = new ArrayList<>();
ArrayList<Zi> list3 = new ArrayList<>();
ArrayList<Student> list4 = new ArrayList<>();
method(list1);
method(list2);
method(list3);
method(list4);//报错,因为Student没有继承Ye
}
public static void method(ArrayList<? Extends Ye> list){}//泛型通配符
}当我们使用了<? Extends Ye>,这个时候,编译器就会帮我们监管所有继承了Ye的类。这样不就可以解决我们的问题了吗。
泛型都会被擦除成Object,如果我们想控制这种擦除,有没有办法实现呢?其实这样可以通过我们的通配符解决。
我们可以用在泛型定义中。
class MyArrayList<T extends String> {
T t;
}
——————》经过擦除
class MyArrayList {
String t;
}这里的意思就是让T继承String,当泛型擦除的时候,所有的T都会被String替代。这就是我们上面所说的边界,T的边界从Object变为了String。
当我们在类上定义了泛型,那么就意味着,类中的所有泛型都要和类定义的一致,也就是所有方法只能操作同一种泛型,这样做当然很好,一定程度上保证了统一性,但是有时候我们希望有个别方法可以操作别的泛型怎么办呢?
这就需要用到我们的泛型方法。
class MyArrayList<E> {
public E get(int index) {
}
public static <T> T test(T t){
return t;
}
}这里我们可以看到 <T> T 这里的意思就是定义了一个泛型T,并且返回值类型也是T。
这里的泛型T是只在此方法生效的,类似于方法的形参,只能在方法中使用。
这里T是区别于类的泛型的,即使我们写成E,和类一样,也不会影响其独立性。
既然独立与类,在使用时,又要怎么指定泛型的具体类型呢?
MyArrayList<String> mylist=new MyArrayList<>();
Integer result=mylist.test(123);我们发现,从头到尾都没有指定方法泛型啊,只在类上指定了类的泛型是String。
其实不然,当我们调用test(123)时,编译器会自动检查,传入的是Integer【其实检查出来的是int,然后自动装箱了】然后编译器不就能确定泛型是Integer了吗。所以传入的泛型就是Integer。有因为这个方法返回值为T,所以还会自动类型转换。
通配符拓展
传入参数类型未知,我们可以用泛型,如果传入参数个数也未知呢?
通过...来实现。————他的底层其实就是数组。
class List{
public static <E> void add(ArrayList<E> list,E...e){//通过三个点,表示可变参数
for(E element : e){
list.add(element);
}
}
}
//调用
public class Mian{
public static void main(String[]args){
ArrayList<Integer> list=new ArrayList<>();
List.add(list,1,2,3,4,5);//我们可以传递任意个数参数
}
}泛型接口
如何使用带泛型的接口
- 实现类给出具体的类型——————————》如果实现类确定类型,使用此方式
- 实现类延续泛型,创建对象时再确定————》类型需要使用者提供,实现类不知道
class MyArrayList1 implements List<String>{
}
class MyArrayList1<E> implements List<E>{//将接口的泛型延续下来
}
public class Main{
public static void main(String[] args){
MyArrayList1 list=new MyArrayList1();//不需要指定泛型,会自动使用接口指定的String来分装类
MyArrayList1<String> list=new MyArrayList1<>();//需要指定泛型
}
}我们能不能定义一个保存泛型的数组呢ArrayList<String>[] listArr=new ArrayList<>[5];?
泛型一般作用于集合,他和数组在设计上就是冲突的。
在 Java 中,不能直接创建泛型数组,包括 ArrayList<String>[] listArr = new ArrayList<>[5]; 这样的语法是不允许的。这是因为 Java 中的泛型数组存在类型擦除的问题,导致无法安全创建泛型数组。
在 Java 中,数组具有运行时类型信息,而泛型在编译时会被擦除。这导致泛型数组的创建变得复杂且不安全。如果允许直接创建泛型数组,可能会导致类型安全性问题。
但是我们如果非要创建也可以。
可以声明带泛型的数组引用,但是不能直接创建带泛型的数组对象
public class Test{
public static void main(String [] args){
//error
ArrayList<String>[] listArr=new ArrayList<>[5];
//这样可以,但是不好
ArrayList[] list=new ArrayList[5];
ArrayList<String>[] listArr=list;
//这样比较好
ArrayList<String>[] listArr = new ArrayList[5];
}
}为什么第二种方式不好呢,因为第二种方式将list暴露出来了,会出现越过listArr,通过list直接赋值的情况。但是编译不会报错,泛型只会在定义泛型的那一句话中,进行检查。也就是说list和listArr是两个引用指向了一个数组,虽然后者指定了泛型,编译器会帮我们监管,但是前者依然可以使用。我们希望,当我们往listArr中存入不符合泛型的数据时,会立马标红,报错。【编译报错】
public class Test{
public static void main(String [] args){
//不好的true
ArrayList[] list=new ArrayList[5];
ArrayList<String>[] listArr=list;
ArrayList<Integer> intList=new ArrayList<>();
intList.add(0);
list[0]=intList;//通过list直接赋值
String s=listArr[0].get(0);//后面取到的是Integer,而泛型却是String
==============================================================================
//好的true
ArrayList<String>[] listArr = new ArrayList[5];
ArrayList<Integer> intList=new ArrayList<>();
intList.add(0);
listArr[0]=intList;//这里会立马报错,因为listArr规定了String数组泛型,而这里是Integer数组
}
}第一次写文,如果错误,希望大家可以指出。

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









