






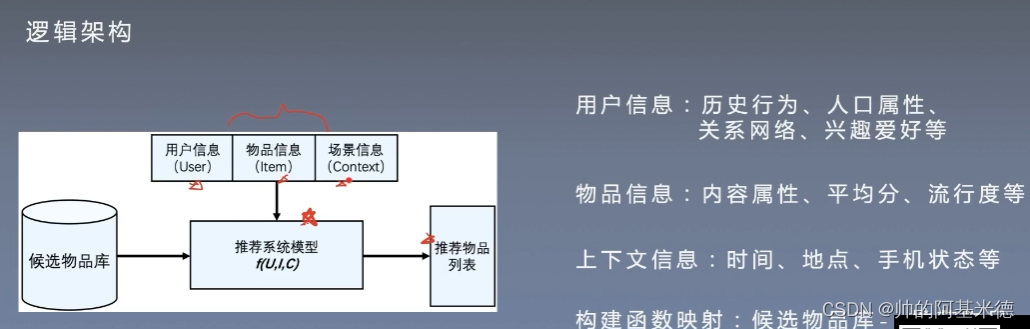
数据清洗,数据统计和分析;用户长短期兴趣建模,推荐模型优化,在线服务开发;支持业务发展,提升用户效率
能力要求:



Chapter 1
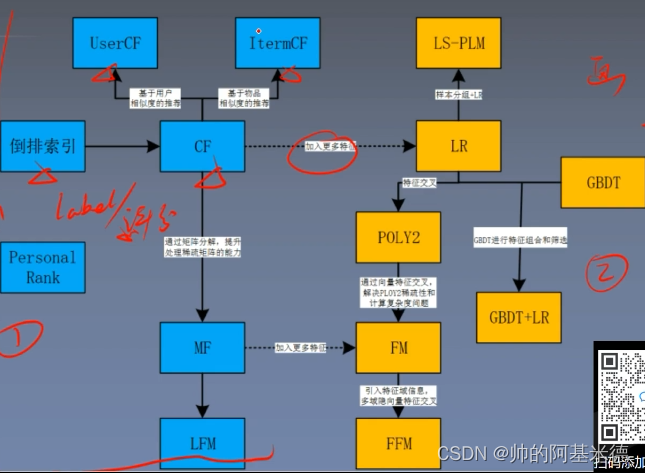
1. 掌握协同过滤算法
2. 熟悉矩阵分解和LFM算法
3. 了解PersonalRank 算法思路
4.比较各算法优缺点并针对场景选型
1. 倒排索引
* 搜索引擎的核心技术之一,其核心目的是从大量文档中查找包含某些词的文档集合,并在O(1) 或 O(logn)的时间复杂度完成
* 一般过程:

* 其中第二步 是 去除词条中的 无关词(停顿词) ,因为其对文章含义没影响
举例:有这样几个文章
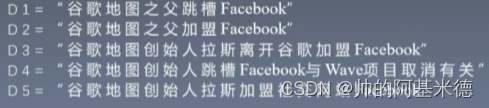
首先通过 NLP 相关工具 将上面的内容 分词,得到词条:
![]()
将其中的 无关词 (与、的、之...)去掉,并建立索引映射:

当用户搜索某一个词条,系统就能给出 对应文章
* 基础推荐模型:--词频-逆文档频率(TF- IDE):
对每个文档采用 词袋(BOW)以向量方式描述文档,方便进行相似性度量
TF : 表示对应的 词 出现的频率
IDF(m) = log( N / DF(m) ) N: 总的文章数量; m: 对应词条的出现频率
即,当 某一词条出现频率和文章数相同时,IDF值就小(某一词条对推荐文章的贡献力)

2. 基于邻域的推荐算法
2.1 UserCF 算法(基于用户的协同过滤) :
1. 找到和目标用户兴趣相似的用户集合(描述用户相似性)
2. 将相似用户喜欢的,且 目标用户没有听过的物品推荐给目标用户(根据相似性做推荐)
2.1.1 计算相似性

分子: 目标用户和兴趣相似用户 喜爱物品的交集; 分母: 目标用户和兴趣相似用户 喜爱物品的并集

两个公式 用来描述 两个用户之间的 相似性
举例:

存在问题:
1. 用户间产生交集的物品少, 怎么办?
* 建立倒排表,减小计算量
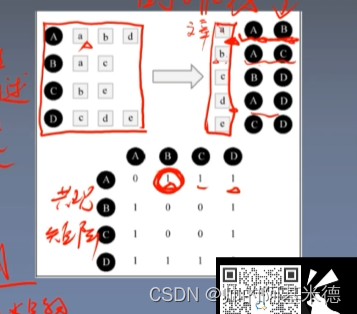
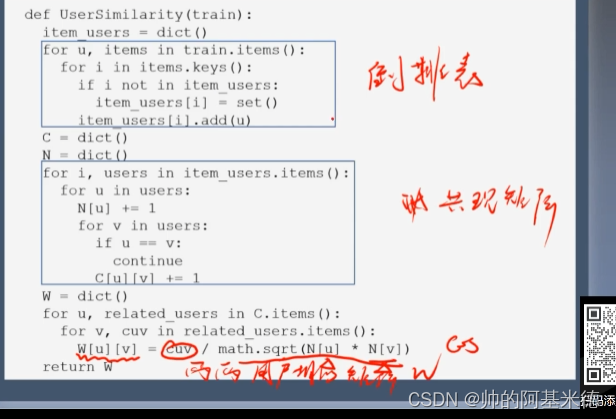
* 建立倒排表后,得到共性矩阵 ,再通过 上述两个公式 计算相似性
2. 热门物品不能差异化地度量 人之间的相似性
IIF(逆物品频率)
相似性计算: N(i) : 物品 i 被人喜欢的次数,相当于 TF(词频);当它大的时候,权重(相似性就越小)
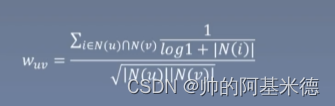

2.1.2 根据相似度推荐 ( P(u,i): 将物品 i 推荐给 用户U )
找出 与 用户 U 相似度 排名前K的 ,并且含有物品 i 的用户 ;
Wuv :上面计算的共性矩阵的W的值; Rvi: 用户v 对物品 i 的喜爱程度

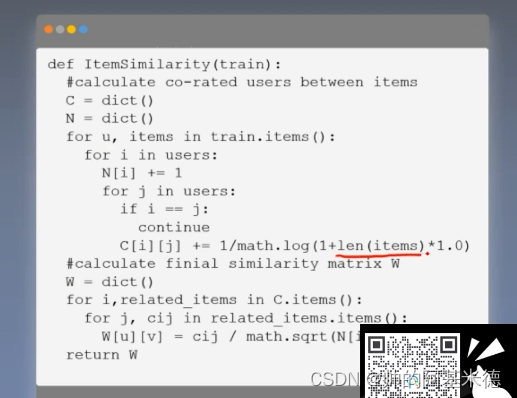
2.2 ItermCF 算法(基于物品的协同过滤) :
1.定义: 一种通过分析用户行为记录,计算物品之间的相似度,并进行推荐的方法
2.过程:

一个喜欢物品 i 用户,同时还喜欢物品 j 的程度(即 物品间的相似度)

举例:

计算好两物品间的相似性;接下来就是要 推荐:
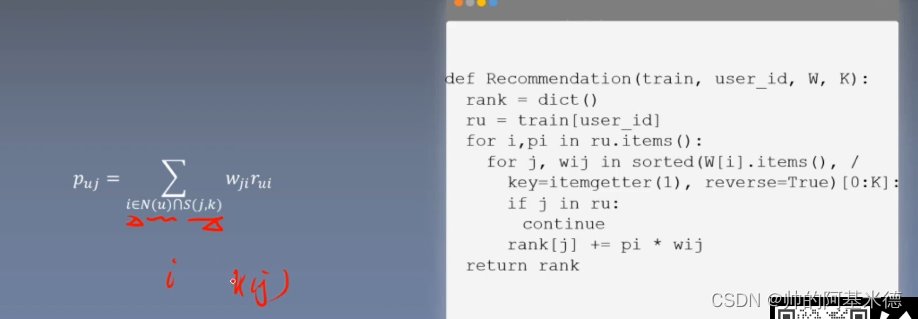
Pu,j: 与用户 U 喜欢的物品 i 中 相似的前K个物品 j ;累加:物品i、j 相似的权重 * 用户U对 i 的喜爱程度
存在问题:(优化:IUF)

N(u): 用户U喜欢多少物品。 若他喜欢的物品很多,说明他活跃度很高,他喜欢的物品间相似性度量不具代表性。
总结: UserCF : 给用户推荐 跟他兴趣爱好相似的用户 喜欢的物品
ItemCF : 给用户推荐 他之前喜欢物品 的相似物品。

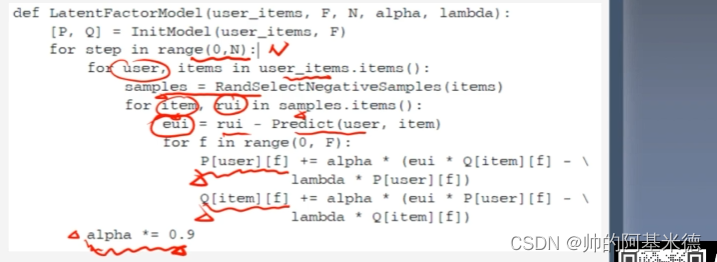
3. 隐语义模型(LFM):
---------基于兴趣分类的方法,可以对物品的兴趣进行分类。对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品。
3.1 矩阵分解模型




用户对k个不同类别的喜好程度 * 物品 i 属于这个类别的概率;
为解决上问题 , 我们从数据出发, 确定某个物品属于哪一类, 以及确定 分成哪几类(k)
对于数据:
以 用户 有过行为的物品为正样本,没有过行为的物品为负样本,进行训练

进行样本选择的代码: 在一个样本池中, 随机选取是负样本的样本

得到数据后,就要进行模型训练

得到损失函数 C 后对 p、q求偏导, 然后对参数 α 更新;最后得到训练好的 p 、q , 然后即可用训练好的模型进行预估
代码实现:
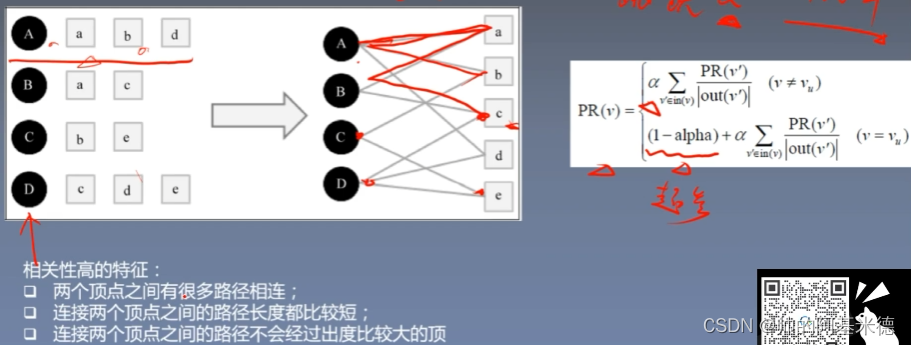
4 、基于图的模型
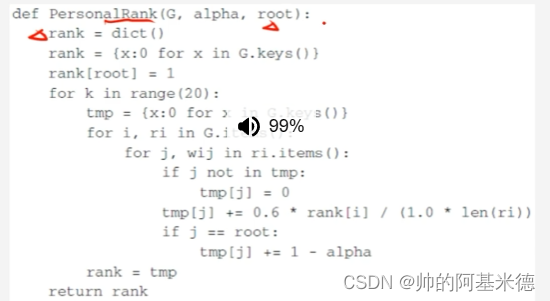
5 基础推荐算法下
















 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









