









首先我们都应该知道分组求和要用到这个group by,而这也是她最普遍的用法。
SELECT hi.descriptions, SUM(nvl(hi.qty, 0))
FROM hcm_items hi
WHERE 1 = 1
GROUP BY hi.descriptions可能难点还有集合内求和,用于求结果集中同类和
select sum(alias.assemble_qty) over (partition by alias.WORKCELL_ID)
from EMT_ISSUE_PROCESS_ACT alias
where 1 = 1;上面的是group by的常用用法,接下来就简单说一下她的一些升级用法,集体什么效果就不一一贴图示呢,想要知道效果,还是得自己尝试,毕竟经过自己手的东西,才有可能成为自己的东西,简单说完升级用法,再来仔细说我想要说的加点料,因为除了特殊料之外,其他的很多人都已经做过了,并且很多人也吃过了。
- 在Group By 中使用Rollup 产生常规分组汇总行 以及分组小计:
Group By Rollup(字段A,字段B),Rollup 后面跟了n个字段,就将进行n+1次分组,从右到左每次减少一个字段进行分组;然后进行 union
- 在Group By 中使用Cube 产生Rollup结果集 + 多维度的交叉表数据源:
Group By Cube(字段A,字段B), Cube 后面跟了n个字段,就将进行2的N次方的分组运算;然后进行 union
除此之外还有GROUPING函数和Grouping Set方法,这两个用的相对较少,前一个是看行列分组情况的,后一个可以代替多次union,需要详细了解的可以去其他地方看看,这里就 不多做解释了,原谅博主的懒。。。
接下来说一下关于料的问题,先上一张图吧。
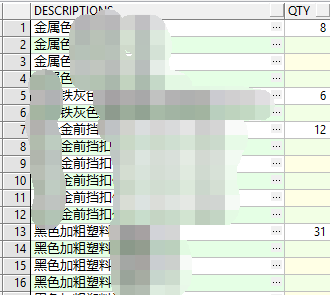
看这个图,不知道你有没有闪过一些实现的思路。。。
这里对图示内容解释一下吧,看第一列值,可以看出,这是一个排序后的结果,而第二列则是第一列分组求和的数值。这里可能大家就会有疑问了,分组求和后,相同的列不是会何并,然后在对应的行列得到一个求和值吗?这里怎么不是这样的。正因为不是这样,所以这才是真正的料。下面就给大家看看实现的具体sql吧。
WITH item AS
(SELECT t.descriptions,
CASE
WHEN t.qty < 0 THEN
NULL
ELSE
t.qty
END qty,
rownum seq
FROM (SELECT hi.descriptions, -rownum qty
FROM hcm_items hi
WHERE hi.items_code = 'test'
UNION
SELECT hi.descriptions, SUM(hi.qty) qty
FROM hcm_items hi
WHERE hi.items_code = 'test'
GROUP BY hi.descriptions) t)
SELECT tab.descriptions, tab.qty
FROM item tab
WHERE tab.seq NOT IN (SELECT t.seq - 1 FROM item t WHERE t.qty IS NOT NULL)
ORDER BY tab.descriptions, tab.qty;
看了sql,先给科普一下别的一点知识,然后再一点点解释一下这句sql。
- UNION: 去除重复记录
- UNION ALL : 保留重复记录
- INTERSECT: 取交集
- MINUS: 取差集
接下来我就按照这句sql的大体执行顺序来解释一下这句sql吧。我们可以注意到,第一部分执行的sql是由union来合并的两个数据集合,第一个集合很简单,就是将对应数据查出来,需要注意的是,数值列数取的rownum的负值,而第二个数据集合是取的分组求和结果集。接下来第二层就是将非求和值的负值清空,将这样的结果集用with as语句定义为一个子查询部分。最后再将这样的结果去掉汇总行的前一行,然后排序,便能得到这样一个特别的准确的结果。
或许这不是一个最好的办法,但是也是实现这个效果的一个思路,有思路便能类推,解决更多的问题。。。如有道友有更好的思路,还望告知,谢谢
















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











