







对Scrapy框架的使用已有一段时间,现将个人经验作一个记录和分享。
由于在windows上安装Scrapy各种不成功,因此还是推荐在Linux上安装。
一、虚拟机的安装
下载 VMWare Workstation Player 12以上 (自行百度下载即可)
安装后 创建虚拟机
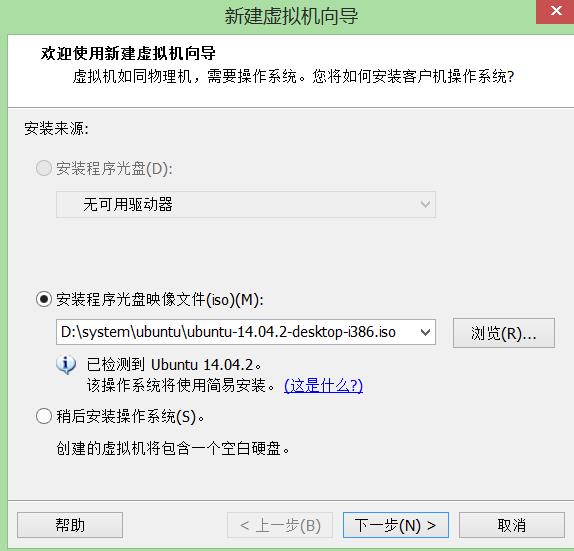
浏览 —-将下载的ubuntu镜像导入
设置好用户名密码后下一步
更新 VMWare Tools时 选择是 (可以桌面全屏,虚拟机和本机之间复制粘贴)
到这里,虚拟机差不多安装成功了
二、Ubuntu的其他配置(可选)
由于下载的是英文的镜像,个人习惯改为中文
将ubuntu界面改为中文 :
点击右上角找到 system setting > language setting > Install/ Remove Languages
找到Chinese(simplified) 安装
安装完成,发现新问题如下图;中文是灰色,不可选
鼠标左键点住汉语(中文)那一行,往上拖到最上面的位置(到第一项Engli
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









