









89ip代理爬取代码实现
一、代码实现
import requests
import time
import random
from fake_useragent import UserAgent
from lxml import etree
import os
import csv
"""
89ip代理爬取
"""
class IPSipder(object):
def __init__(self):
self.url = "https://www.89ip.cn/index_{}.html"
self.headers = {'User-Agent': UserAgent().random}
# 统计有效ip个数
self.count = 0
# 获取ip表格行
def get_html(self, url):
html = requests.get(url=url, headers=self.headers).text
parser_html = etree.HTML(html)
tr_list = parser_html.xpath('//tbody/tr')
return tr_list
# 提取ip和port
def parser_html(self, tr_list):
proxies_list = []
for tr in tr_list:
# 获取ip
ip = tr.xpath('./td/text()')[0].strip()
# 获取port
port = tr.xpath('./td/text()')[1].strip()
# 将ip和port封装到字典中,便于proxies代理调用
ip_dict = {
"http": "http://" + ip + ":" + port,
"https": "https://" + ip + ":" + port
}
# 将获取的所有ip和port放入列表
proxies_list.append(ip_dict)
return proxies_list
# 保存有效ip到csv文件,如不要保存,可用在run方法中将其注释掉即可
def save_ip(self, proxy, save_filename):
try:
if proxy:
# 设置将保持的文件放到桌面
save_path = "c:/Users/" + os.getlogin() + "/Desktop/"
save_file = save_path + save_filename
print('保存位置:', save_file + '.csv')
with open(save_file + ".csv", 'a+', encoding='utf-8') as f:
fieldnames = ['http', 'https']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writerows(proxy)
except Exception as e:
print(e.args)
# 检查哪些IP是可用的
def check_ip(self, proxies_list):
use_proxy = []
for ip in proxies_list:
try:
response = requests.get(url="http://httpbin.org/", headers=self.headers, proxies=ip, timeout=3)
# 使用百度一直失败,不知何原因
# response = requests.get(url="https://www.baidu.com/", headers=self.headers, proxies=ip, timeout=3)
# 判断哪些ip可用
if response.status_code == 200:
# 将可用IP封装到列表,共后期使用或保存
use_proxy.append(ip)
self.count += 1
print('当前检测ip', ip, '检测可用')
except Exception as e:
# print(e.args)
print('当前检测ip', ip, '请求超时,检测不合格')
# else:
# print('当前检测ip', ip, '检测可用')
return use_proxy
def run(self):
begin = int(input("请输入要抓取的开始页:"))
end = int(input("请输入要抓取的终止页:"))
filename = input("请输入保存文件名称:")
for page in range(begin, end + 1):
print(f"#################抓取第{page}页################################")
# 重构url
url = self.url.format(page)
# 解析出所有的ip行
parser_html = self.get_html(url)
# 获取所有的ip代理
proxies_list = self.parser_html(parser_html)
# 筛选可用的ip
proxy_id = self.check_ip(proxies_list)
# 将可用的IP代理存入文件中:如若不想保存到文件中,将下面这行代码注销即可
self.save_ip(proxy_id, filename)
# 随机休眠2~3秒
time.sleep(random.randint(2, 3))
if __name__ == "__main__":
spider = IPSipder()
# 执行
spider.run()
print(f'共统计到有效ip' + str(spider.count) + "个!")
二、代码运行
请输入要抓取的开始页:2
请输入要抓取的终止页:2
请输入保存文件名称:proxy-ip
#################抓取第2页################################
当前检测ip {'http': 'http://139.196.151.191:9999', 'https': 'https://139.196.151.191:9999'} 检测可用
当前检测ip {'http': 'http://114.102.45.39:8089', 'https': 'https://114.102.45.39:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://114.231.46.231:8089', 'https': 'https://114.231.46.231:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://124.71.157.181:8020', 'https': 'https://124.71.157.181:8020'} 检测可用
当前检测ip {'http': 'http://121.40.137.141:80', 'https': 'https://121.40.137.141:80'} 请求超时,检测不合格
当前检测ip {'http': 'http://117.69.232.45:8089', 'https': 'https://117.69.232.45:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://114.102.45.89:8089', 'https': 'https://114.102.45.89:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://115.29.148.215:8999', 'https': 'https://115.29.148.215:8999'} 检测可用
当前检测ip {'http': 'http://120.46.197.14:8083', 'https': 'https://120.46.197.14:8083'} 检测可用
当前检测ip {'http': 'http://113.223.215.128:8089', 'https': 'https://113.223.215.128:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://112.124.2.212:20000', 'https': 'https://112.124.2.212:20000'} 检测可用
当前检测ip {'http': 'http://114.102.47.164:8089', 'https': 'https://114.102.47.164:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://117.69.154.91:41122', 'https': 'https://117.69.154.91:41122'} 请求超时,检测不合格
当前检测ip {'http': 'http://123.182.59.167:8089', 'https': 'https://123.182.59.167:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://223.215.176.74:8089', 'https': 'https://223.215.176.74:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://114.231.105.68:8089', 'https': 'https://114.231.105.68:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://121.43.34.143:80', 'https': 'https://121.43.34.143:80'} 请求超时,检测不合格
当前检测ip {'http': 'http://121.40.109.183:80', 'https': 'https://121.40.109.183:80'} 请求超时,检测不合格
当前检测ip {'http': 'http://116.63.130.30:7890', 'https': 'https://116.63.130.30:7890'} 请求超时,检测不合格
当前检测ip {'http': 'http://114.102.44.113:8089', 'https': 'https://114.102.44.113:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://116.63.130.30:443', 'https': 'https://116.63.130.30:443'} 请求超时,检测不合格
当前检测ip {'http': 'http://114.231.46.160:8089', 'https': 'https://114.231.46.160:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://183.164.243.29:8089', 'https': 'https://183.164.243.29:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://114.102.44.137:8089', 'https': 'https://114.102.44.137:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://117.57.93.63:8089', 'https': 'https://117.57.93.63:8089'} 请求超时,检测不合格
当前检测ip {'http': 'http://159.226.227.90:80', 'https': 'https://159.226.227.90:80'} 请求超时,检测不合格
当前检测ip {'http': 'http://159.226.227.99:80', 'https': 'https://159.226.227.99:80'} 请求超时,检测不合格
当前检测ip {'http': 'http://183.164.243.44:8089', 'https': 'https://183.164.243.44:8089'} 请求超时,检测不合格
保存位置: c:/Users/qwy/Desktop/proxy-ip.csv
共统计到有效ip5个!
三、说明
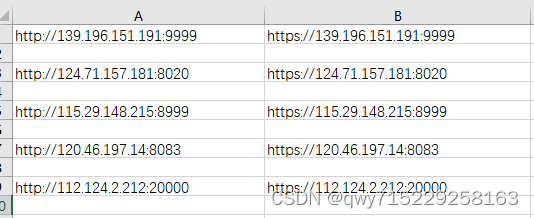
1.在 c:/Users/qwy/Desktop/proxy-ip.csv下的文件如下:















 2865
2865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









