






2025百度线上赛入门指南
0. 前言
0.1. 内容简述
文档主要用于记录参加2025年智能车百度创意组线上赛的各种配置过程,不一定是最简或最优流程,存在一些并不合理的操作,例如随意在包里拉屎直接修改各包源码等
直白地说就是:在配置过程中如果遇到问题,可能会采取直接修改报错代码或者由于该错误并未被使用,就暂且不论。
该文档适用于Windows系统,虽然涉及到的内容大多有跨平台的适配,但是对于其他平台的部署并未进行验证。
0.2. 百度创意线上赛简述
这里写一下线上赛流程的简要解说,参考以下链接
1、paddlex和gradio参考项目链接
https://aistudio.baidu.com/projectdetail/8826252
2、目标检测的paddlex文档
https://paddlepaddle.github.io/PaddleX/latest/module_usage/tutorials/cv_modules/object_detection.html#413
3、线上赛要求文档
https://www.yuque.com/baiduzhangziyu/ewfmh6/yi2becxlkzydhx1w?singleDoc#
简短地说:通过官方给的数据集进行目标检测项目的标注、训练、优化、测试、部署。
扩展点说,除开制作报告那类撰写工作不谈,我们需要:
- 下载官方数据集,部署PaddleLabel环境,对数据集进行标注
- 安装并配置PaddleX环境,验证数据集,通过校验的数据集我们选取一些内置模型进行训练
- 训练后,我们可以导出各种训练、测试等数据,针对这些数据进行分析,评估模型表现。
- 重复训练,选取不同的模型及不同训练参数,对比效果
- 模型调优。通过图像增强(图像处理,凸出目标)或数据集增强(对特定标签或图片,提高权重或进行一定修改,以提高泛化特定目标的检测能力及泛化性能)、采集更多数据(扩充数据集)等方式,优化目标检测模型。
- 部署模型。把训练好的模型部署在AI-Studio平台上。
由于这篇教程的目的是快速上手有关技术,完成自己的首次部署以熟悉流程,所以重复训练的任务不在这里赘述,自动标志、模型调优有关内容会进行介绍,但可能不会给出具体代码或数据,且所占篇幅较少。
本文长期更新(尽量)
任务全流程
1. PaddleX安装
参考 https://aistudio.baidu.com/projectdetail/8826252 安装PaddleX
PaddleX官方文档 https://ai.baidu.com/ai-doc/AISTUDIO/Blno6j408
主要流程如下:
事后诸葛亮:建议这一段用管理员权限跑
找一个你喜欢的位置,克隆PaddleX源码
cd ~
git clone https://gitee.com/paddlepaddle/PaddleX.git
安装PaddleX,使用可编辑模式(-e),代码改动后不需要重新编译
cd ~/PaddleX
pip install -e .
pip install --user -e .
验证及插件安装
paddlex -h
能输出就是安装正常,接下来安装插件
paddlex --install --platform gitee.com
等一会后下载完毕,中间会滚很久,耐心等待。
安装时可能会出现以下问题:
1. pandas安装不上(后面装插件netifaces包还会再出这个问题)
ERROR: Failed building wheel for pandas ERROR: Failed to build
installable wheels for some pyproject.toml based projects (pandas)
我这里是由于VisualStudio的MSVC没有io.h头导致的,去安装下安装WindowsSDK就可以了,根本原因是这个头不是STL的,编译器默认可能不带。
补:MSVC+WindowsSDK配置方法
首先安装VisualStudio-2014+版本
对于WindowsSDK,有两种安装方法
- 搜索并下载WindowsKit安装程序
- 在VS内查找有关包并安装
具体内容较易搜索,关键词“WindowsSDK”,这里不展开说。安装后记得设定INCLUDE等环境变量,并重启所有依赖的应用。
如果这里的简短内容无法解决配置问题,之后会进行扩充。
对于一部分包,更简单地,可以直接pip install pandas以安装预编译包(netifaces需要自己搜锁对应的whl包,然后使用pip安装)
2. 一堆Warnings
这里的报错提示不小心给我删掉了,主要是围绕GPUtil这个包的,直接看下面的解释吧
这里贴一段AI的解释(翻译):
构建 'GPUtil' 项目时使用了传统的 setup.py bdist_wheel 机制
这种机制将在未来版本中被移除。pip 25.3 将强制执行这一行为变更。
意思就是这个功能比较老,但是包其实正常安装了,不必在意。
2. PaddleLabel安装及使用
2.1. PaddleLabel主体安装
参考官方 https://paddlecv-sig.github.io/PaddleLabel/CN/install.html
通过以下命令安装
pip install --upgrade paddlelabel
启动,终端输入pdlabel
上面这句,以及之后的很多语句可能需要先cd到PaddleX目录下才能使用
这时可能出错
ModuleNotFoundError: Please install connexion using the 'flask' extra
这表示缺少了该包的拓展,后面还会有很多缺少包的报错
尽管我自己配置时是一个一个试出来的,但为了阅读体验,每一段中,我会将后面出现的包全部整合到这里(后文同样)
requirements.txt我已整理出来,不过部分包通过
pip install -r requirements.txt
安装时会报错,需要一些调整,例如paddlepaddle得自己下合适版本,这样装貌似不太行
pip install connexion[flask] connexion[uvicorn]
再启动:
TypeError: Field.__init__() got an unexpected keyword argument 'exclude'
看报错信息定位到(后面发现这里的修改有点问题,参见:重新修正)
File "...\site-packages\paddlelabel\api\schema\task.py", line 18, in TaskSchema
猜测是多包之间的版本兼容问题,把这行改了
# annotations = fields.List(Nested("AnnotationSchema"), exclude=("task",))
annotations = fields.List(fields.Nested("AnnotationSchema", exclude=("task",)))
然后运行会出现这个问题:
TypeError: run() got an unexpected keyword argument 'debug'
意思是run()函数不能指定debug参数,这里我怀疑是版本兼容问题,但由于没找到具体的版本,反复测试版本很费事,我就直接把debug的参数去掉了,如下:
# ...\site-packages\paddlelabel\__main__.py
connexion_app.run(host=configs.host, port=configs.port, debug=configs.debug)
# 复制并注释掉原来的行,删掉debug参数
connexion_app.run(host=configs.host, port=configs.port)
当然,之后在官方的Github页面上找到了有关问题,回答中给出了部分包的版本号,一并修复了这个问题,所以你可以不动这部分代码(后文参见:重新修正)
再启动就能正常打开界面(如果页面没弹出或者被意外关掉了,本地的可以直接localhost:8080(仅win11)或者127.0.0.1:8080打开,端口号可能和我这个不一样,不行就看看启动日志)

2.2. 数据集创建(以及巨量配置问题修复)
线上赛数据集 https://aistudio.baidu.com/datasetdetail/330653 一共876张
下载数据集并解压,能看到有很多图片和一部分json文件(只标注了写文字的板子,而且还只有七十多张,基本和只有图片差不多了)
打开PaddleLabel,创建目标检测项目
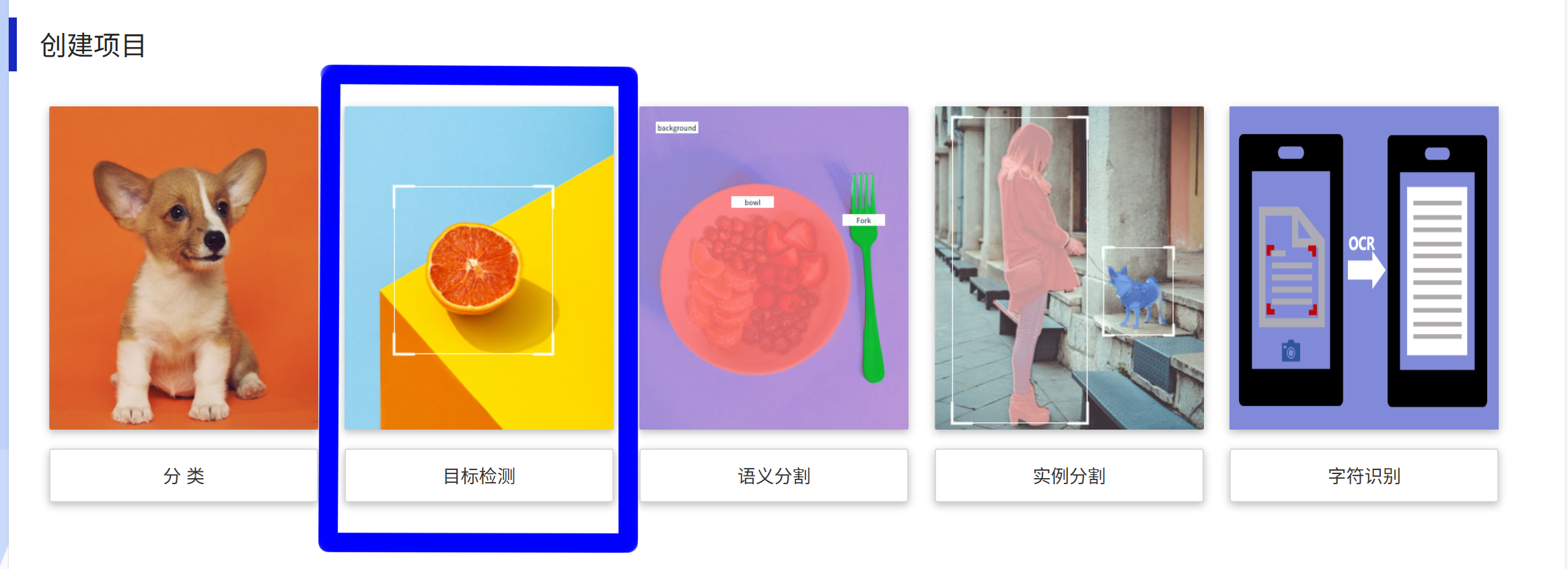
根据页面右侧提示配置项目
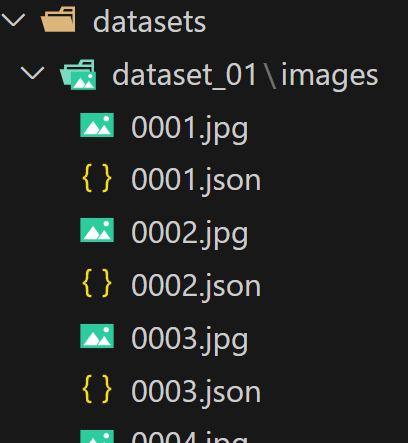 |  |
我的文件夹结构如图所示,数据集文件夹下一级为JPEGImages文件夹
故应当将“dataset_01”的绝对路径作为数据集路径
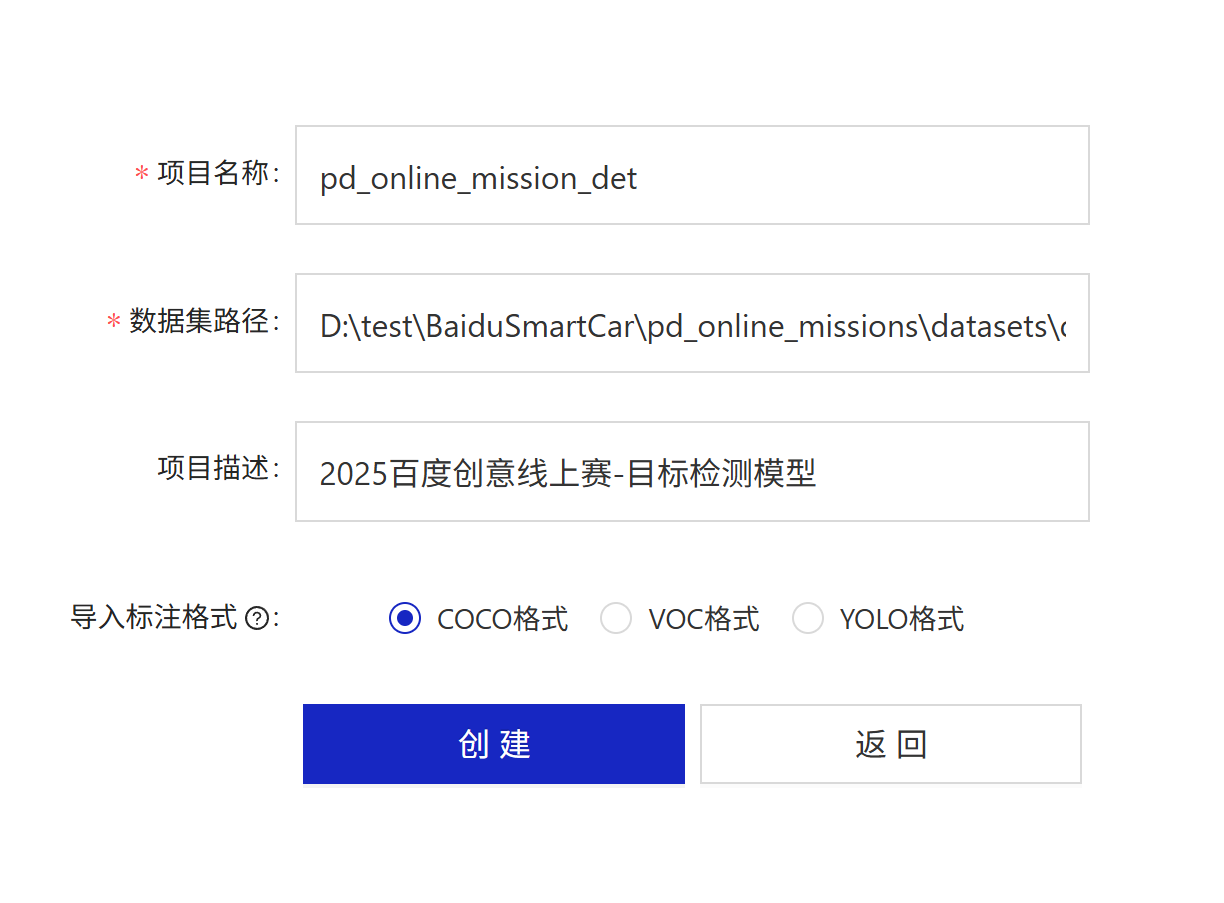
该修改的都做好后,可以tree . /f看看是不是这样的文件夹结构(若不导入其他数据,可以直接创建项目,基本只要图片文件夹正确即可)
回到PaddleLabel界面,创建项目(先别急着看下一行,无法创建也可能是文件夹层次不对或者内容为空,当然,内容为空的异常处理确实好像是官方没写的逻辑,后面为了灵活,我改动了一点代码以允许空文件的存在。)
哈哈!创建失败!
回到终端debug:
File "...\site-packages\paddlelabel\api\schema\project.py", line 22, in pre_load_action
if "label_dir" in data.keys() and data["label_dir"] == "":
^^^^^^^^^
AttributeError: 'function' object has no attribute 'keys'
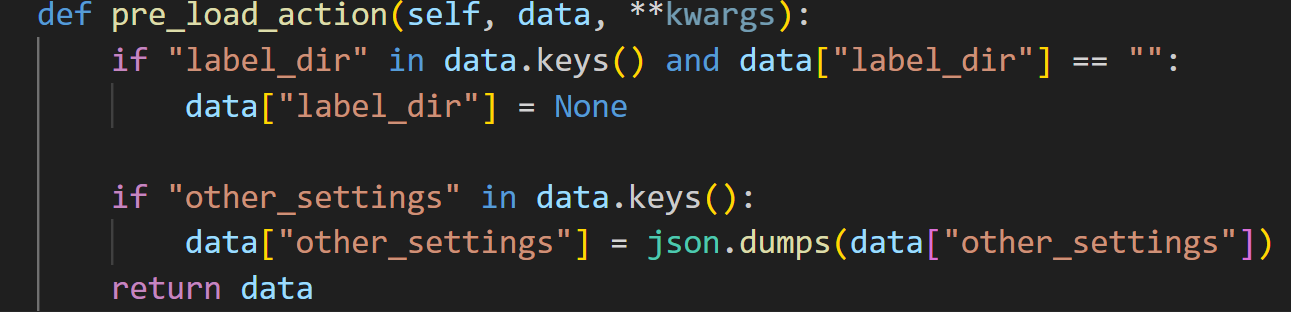
这个data有问题,应当是个字典,但是报错信息说它是个函数
if type(data) != dict:
print("\n\n\n!!!!!!!!!!!!!!!!!!!!! data : "+str(type(data))+"\n\n")
# 结果:!!!!!!!!!!!!!!!!!!!!! data : <class 'method'>
这个data怎么是class 'method’啊,看调用栈应该是别的库干的,应该是版本问题,经过搜索,我找到了官方对于这个问题的解答:
问题链接 https://github.com/PaddleCV-SIG/PaddleLabel/issues/214
解决如下:了解明白。 咱这个错误是coroutine版本不匹配 connexion==2.14.1 随后是flask报错AttributeError: module 'flask.json' has no attribute 'JSONEncoder' 同样重装对应版本,Flask==2.2.2 最后是werkzeug库报错ImportError: cannot import name 'url_quote' from 'werkzeug.urls'... 同样重装对应版本,Werkzeug==2.2.2 装好对应版本就能创建项目了 主要还是版本不匹配啊这里给个代码段:(一并解决了之前debug字段不存在的问题:之前的更改)
pip install uvicorn==0.14.0 --no-deps pip install connexion==2.14.1 --no-deps pip install anyio==3.0 --no-deps pip install Werkzeug==2.2.2 --no-deps pip install starlette==0.21.0 --no-deps pip install Flask==2.2.2 --no-deps pip install Flask-Cors==3.0.10 --no-deps pip install a2wsgi==1.8.0 --no-deps pip install alembic==1.12.1 --no-deps pip install a2wsgi uvicorn==0.18.1
如果后续还有报错IndexError: list index out of range,就是我说的空文件引起的,解决方法也很简单。
把这个:
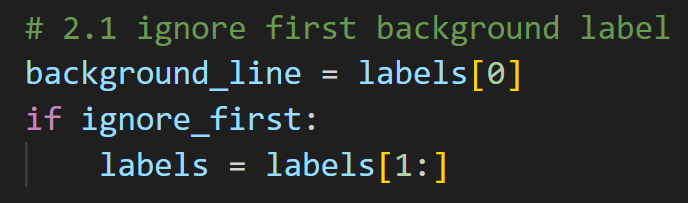
改成这个:
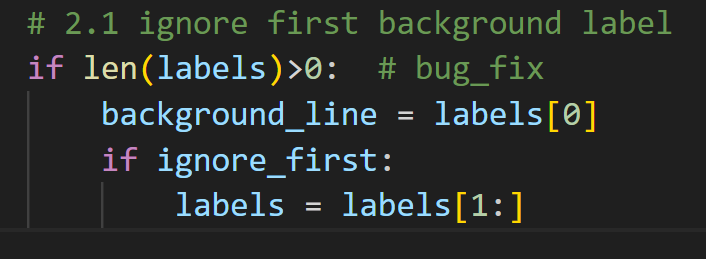
然后,启动!
2.3. 标注数据集
我习惯使用YOLO系的,其他格式也大差不差
先创建一些类别:
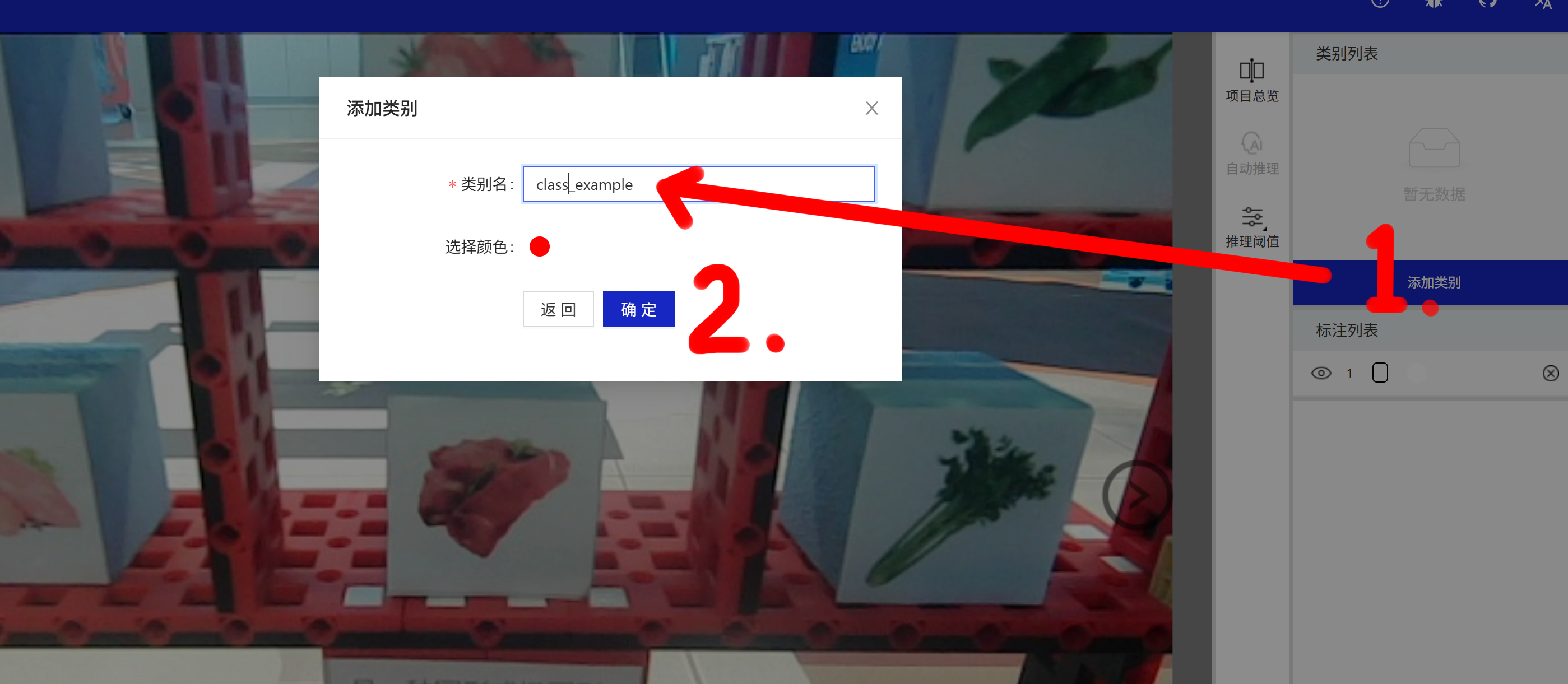

然后拉框标注即可,这里仅作演示,没有正经标注
如果你想使用官方标注过的那70多个框,看下一步的导入导出(及报错处理)

然后现在有新问题了:
在切换下一张中,前面更改的fields.Nested又炸了,改回去看看是哪个库
前面对于问题的定位与修改参见:上一个修复

重新修改了这段代码,中间这个版本能用,注意括号次序
现在能够正常利用PaddleLabel标注图片

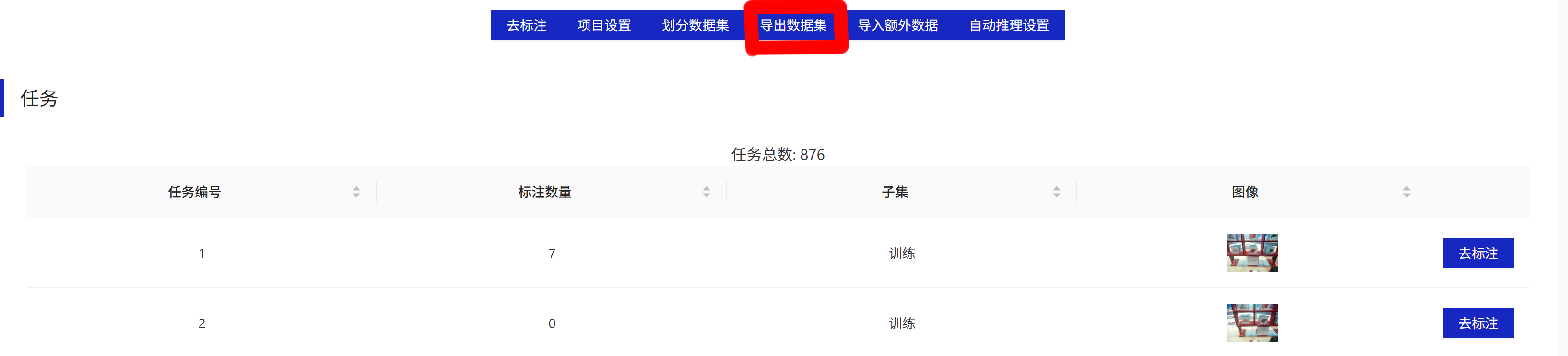
2.4. 导出导入数据集
在项目总览中进行导出操作如图
 |
 |
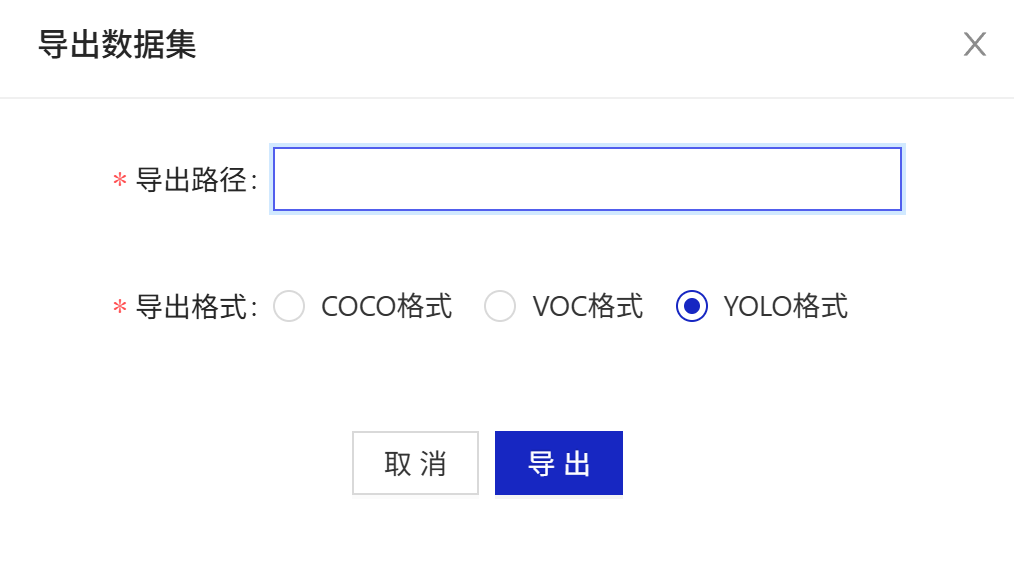 |
经过测试,能够正常导出
导入同理,由于问题的解决比较零散,这里给出一些可能的报错和修复方法,如下:
-
问题:额外数据导入失败


修复:临时使用可以直接把label_format参数改成你想要的常量,完整修复我再看看,还不完全清楚这个bug怎么来的,但是后来莫名其妙好了,没法再复现,应该是哪个包的版本问题
-
问题:新建项目导入不了其他数据

...\site-packages\paddlelabel\task\detection.py这里少一层对空字符串的处理导致anns为空的时候会炸
修复:增加处理逻辑,另外,后面两行的xmid, ymid, xlen, ylen = ann[1:]也需要防止ann长度问题,也很简单,如果len(ann)<5,直接continue即可 -
问题:pdlabel莫名其妙挂掉
提示"Fatal error in launcher: Unable to create process using"
这一段报错里面应该会有个什么exe,把那个删了(怕坏就挪到别的位置,之后修不好再挪回去)
然后pip install --upgrade paddlelabel再装一遍
没好就整个uninstall掉再重装,数据不会丢(只要没把数据放在包文件夹里,不过大多数人应该也不会这样做)
2.5. 数据集划分
为了让测试集能更真实地反映模型的识别准确度及泛化能力,我们需要划分数据集
在PaddleLabel中默认配置可以一遍过,没报错,在“项目总览”的顶上可以看到“划分数据集”,看着来就行
2.6. 自动标注
在标注了一部分图片后,可以初步训练一个小模型,辅助标注剩余的图片,提高标注效率
我之前搞过这个,没有完全重来,所以配置过程之后再补
3. PaddleX的使用
3.1. 数据集校验
各个基础模型的描述在 这里,模型文件也可以从该网站下载。
当然,本地clone了PaddleX的话,也可以在PaddleX\paddlex\configs\modules\object_detection找到
首先,我们需要校验上一步的数据集
注意这里我选择的模型需要COCO格式的标签,其他格式可以导入到PaddleLabel再导出为合适的格式
配置模型,需要配置训练的yaml(PaddleX文件夹里和模型文件放一起的):
Global:
model: PP-YOLOE_plus-S
mode: check_dataset # check_dataset/train/evaluate/predict
dataset_dir: D:/test/BaiduSmartCar/pd_online_missions/datasets/dataset_01_export
device: gpu:0
output: "output"
主要注意device和dataset_dir,根据情况自行调整,多卡就是gpu:0,1,2,3
配置好后运行以下命令执行校验(cd到PaddleX项目下)
python main.py -c paddlex/configs/modules/object_detection/PicoDet-S.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=D:\test\BaiduSmartCar\pd_online_missions\datasets\dataset_01
// 如果不能运行,去掉\和换行符
大概率会缺失几个库:
pip install colorlog pydantic filelock chardet ruamel.yaml GPUtil ujson prettytable
尝试再次运行命令,报错:
Ensure that both
instance_train.jsonandinstance_val.jsonexist in D:\test\BaiduSmartCar\pd_online_missions\datasets\dataset_01_export/annotations
这是因为PaddleLabel直接导出的文件夹结构和PaddleX的不太兼容
需要进行如下操作:
文件(夹)重命名
| 原名字 | 重命名 | |
|---|---|---|
| image | → | images |
| train.json | → | instance_val.json |
| test.json | → | instance_test.json |
文件夹结构重新调整
| 原位置 | 新位置 | |
|---|---|---|
| dataset/instance_train.json | → | dataset/annotations/instance_train.json |
| dataset/instance_val.json | → | dataset/annotations/instance_val.json |
| dataset/instance_test.json | → | dataset/annotations/instance_test.json |
验证通过后,会输出校验通过的信息,并且可以在PaddleX/output下看到一些信息文件,包括各类标签的统计等等
3.2. 模型训练
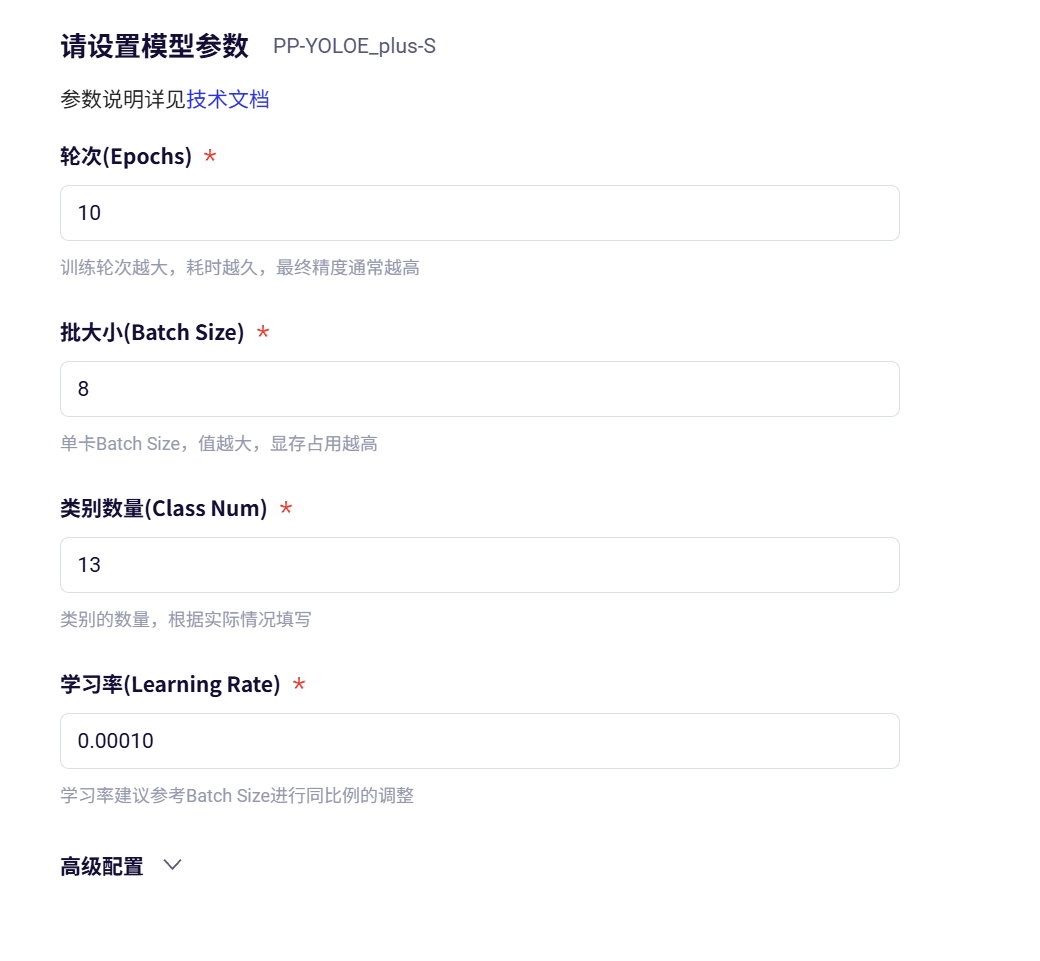
需要配置训练的yaml(PaddleX文件夹里和模型文件放一起的):
Train:
num_classes: 13
epochs_iters: 10
batch_size: 8
learning_rate: 0.0001
pretrain_weight_path: D:\test\BaiduSmartCar\pd_online_missions\paddle\PP-YOLOE_plus-S_pretrained.pdparams # use object365 pretrained
warmup_steps: 100
resume_path: null
log_interval: 10
eval_interval: 1
运行训练命令:
python main.py -c D:\test\BaiduSmartCar\pd_online_missions\paddle\PP-YOLOE_plus-S.yaml \
-o Global.mode=train \
-o Global.dataset_dir=D:/test/BaiduSmartCar/pd_online_missions/datasets/dataset_01_export \
-o Train.dy2st=True
// 最后一行dynamic-to-static用于加速训练
报错:
paddlex.utils.errors.others.UnsupportedParamError: ‘YOLOE_plus-S.yaml’ is not a registered model name.
原因:有组件没安装成功,尝试执行paddlex --install PaddleDetection
对于其他的功能,对应的组件名字可以在这里找到
安装过程中我出现了权限问题(Permission denied / 拒绝访问),使用管理员权限运行,能够正常安装
再次运行,报错未安装Paddle框架,所以还需要安装Paddle主框架(这里选择GPU版本)
预览版的支持问题:
在之前配置其他paddle项目的时候就有遇到过,由于预览版的版本号格式和原有处理逻辑不一致,会引起其他组件的问题
例如这个版本号字符串"3.0.0.dev20250514"就不能匹配其他地方默认处理的v1,v2,v3=v_string.split(".")
别的像什么匹配版本高低啥代码的自己看着改一下
再次启动训练,缺包:
pip install scipy imgaug scikit-learn visualdl motmetrics
对一部分过时代码:
// AttributeError: `np.sctypes` was removed in the NumPy 2.0 release. Access dtypes explicitly instead.
pip install numpy==1.26.4
// 或者去把包的源码修了也行,尽管不能保证别的地方有没有类似问题
如果报错:
Error: C:\home\workspace\Paddle\paddle\phi\kernels\gpu\one_hot_kernel.cu:37 Assertion `p_in_data[idx] >= 0 && p_in_data[idx] < depth` failed. Illegal index value, Input(input) value should be greater than or equal to 0, and less than depth [5], but received [0].
说明模型配置的.yaml中,num_classes没有配置正确
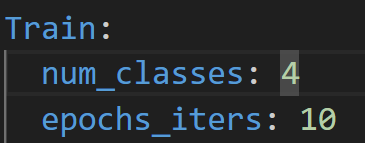
配置后错误不再出现

好!有得食!
模型训练后的输出在PaddleX/output下面
3.3. VisualDL模型可视化
安装pip install --upgrade --pre visualdl
使用命令直接启动VisualDL
visualdl --logdir D:/test/BaiduSmartCarPaddleX/output --port 8040
// 或更多组件
visualdl --logdir D:/test/BaiduSmartCar/PaddleX/output --host 0.0.0.0 --port 8040 --component_tabs scalar image text embeddings audio histogram hyper_parameters static_graph dynamic_graph pr_curve roc_curve profiler x2paddle fastdeploy_server fastdeploy_client
通过浏览器访问localhost:8040或127.0.0.1:8040进入可视化页面
缺包:
pip install paddle2onnx x2paddle gradio tritonclient[all] gevent geventhttpclient
有warning不管,报错的那个不兼容依赖没用到
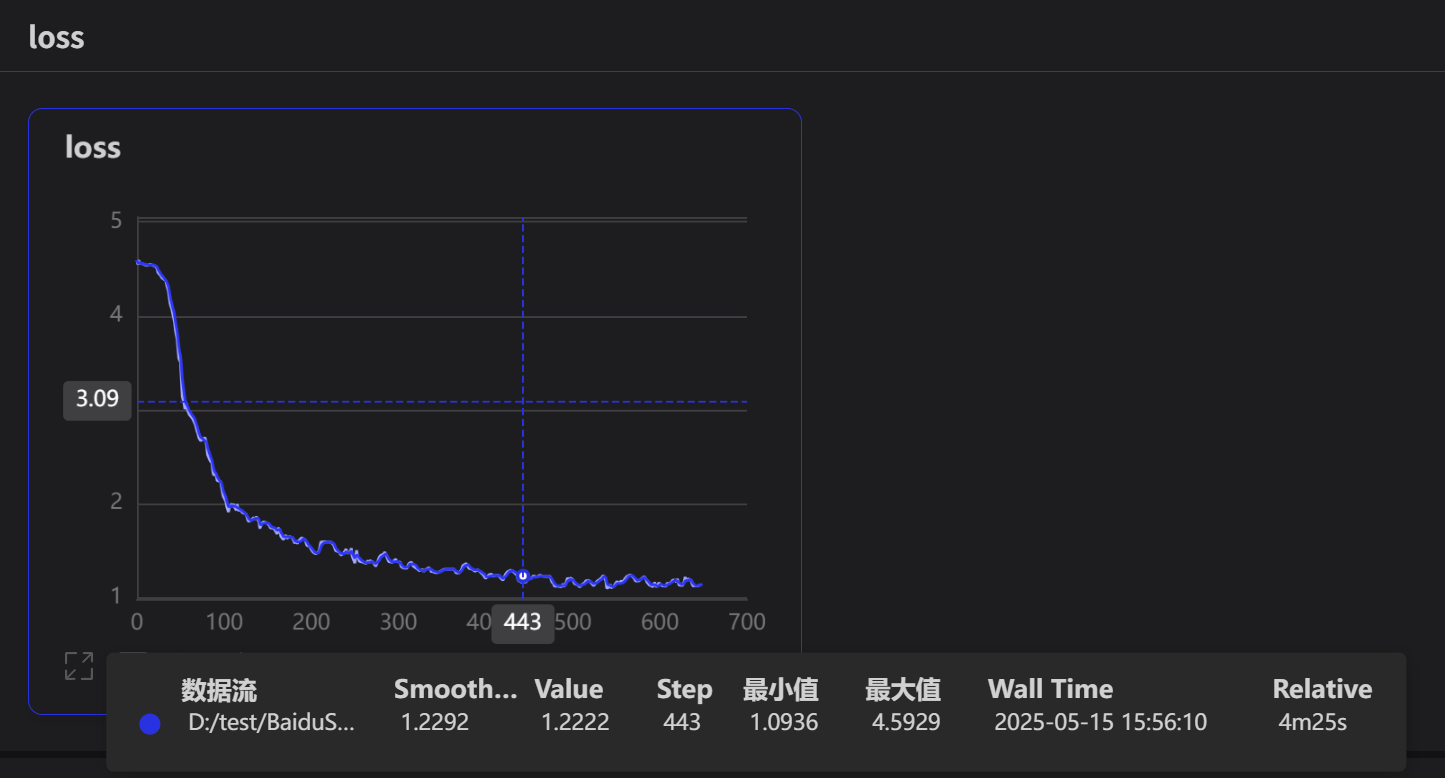
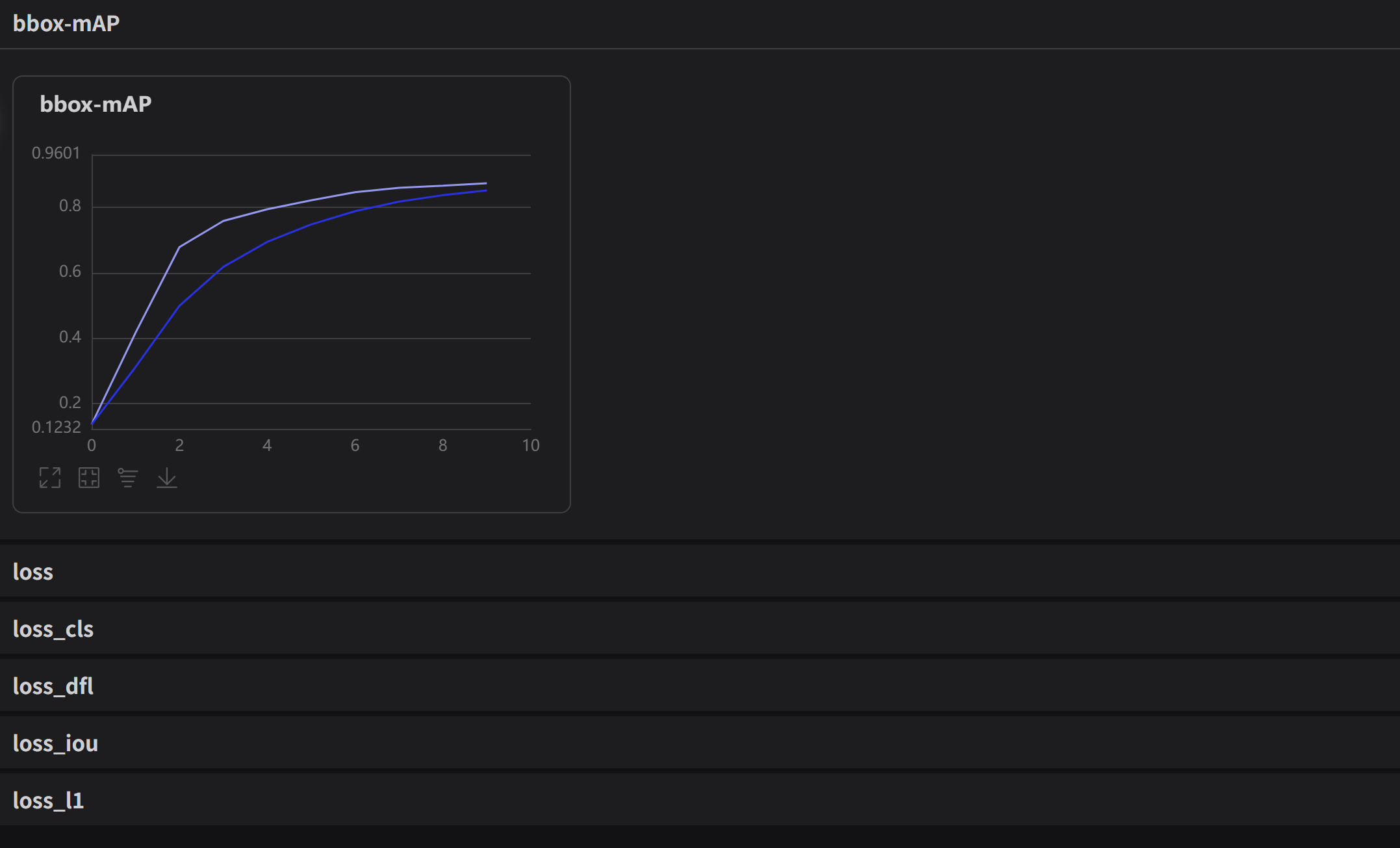
至此,本地部分基础内容已经完成
这真的是!泰 裤 辣!
4. AI-Studio在线部署
4.1. AI-Studio在线训练
非必须项,可以本地训练,但最终要在AI-Studio上部署
首先需要有一个AI-Studio账号,在这里创建你的数据集,
从数据集根目录打包得到数据集压缩包,上传到AI-Studio平台。
再在左侧“模型”页面创建图像识别产线
校验数据集,并选择合适的模型进行部署,我们暂时采用默认设置
运行后等待完成,得到模型的训练结果,可以下载到本地,也可以在线一键部署。(限免券就那么几张,我就不浪费了)
4.2. Gradio部署
安装依赖:
pip install gradio fastapi
安装全局的paddlex
pip install paddlex==3.0.0rc1
pip install "paddlex[base]==3.0.0rc1"
在AI-Studio中,创建一个Gradio项目
创建完了以后你会发现这东西跑到“应用”里面了,因为它比较轻量级
进去以后会默认打开README.md文件,那是自带的教程
git使用相关我不知道要不要写,我也是之前配置过,现在也不太清楚了
按照那个教程克隆本地仓库后(我个人倾向于开个新文件夹做),把前面训练的模型放进去,主要是这些东西:
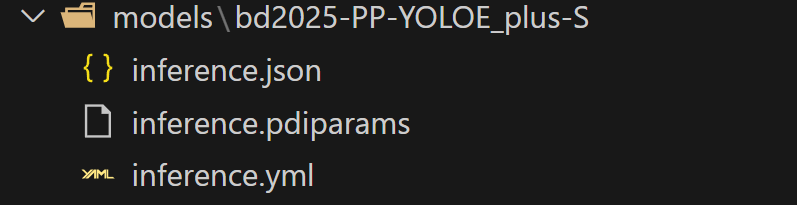
然后就可以基于Gradio进行部署了,这里给出一些基本用法:
import gradio as gr
def demo(img_input):
img_output=img_input
return img_output
demo = gr.Interface(fn=demo,
inputs="image",
outputs=gr.Image(type="numpy")
)
# 这里指定了输出图片的格式,默认是pil
# 输入输出可以有多个
demo.launch()
本地运行以下就可以看到效果,通过完成demo()这个函数,就可以实现想要的功能,实际处理逻辑这里就暂时不作介绍了
然后我们要将项目跑在云端
git提交所有更改后在AI-Studio上“发布应用”,填写完信息,选择那个免费的配置就可以发布了,通过公开你的应用,可以让其他人进行访问。
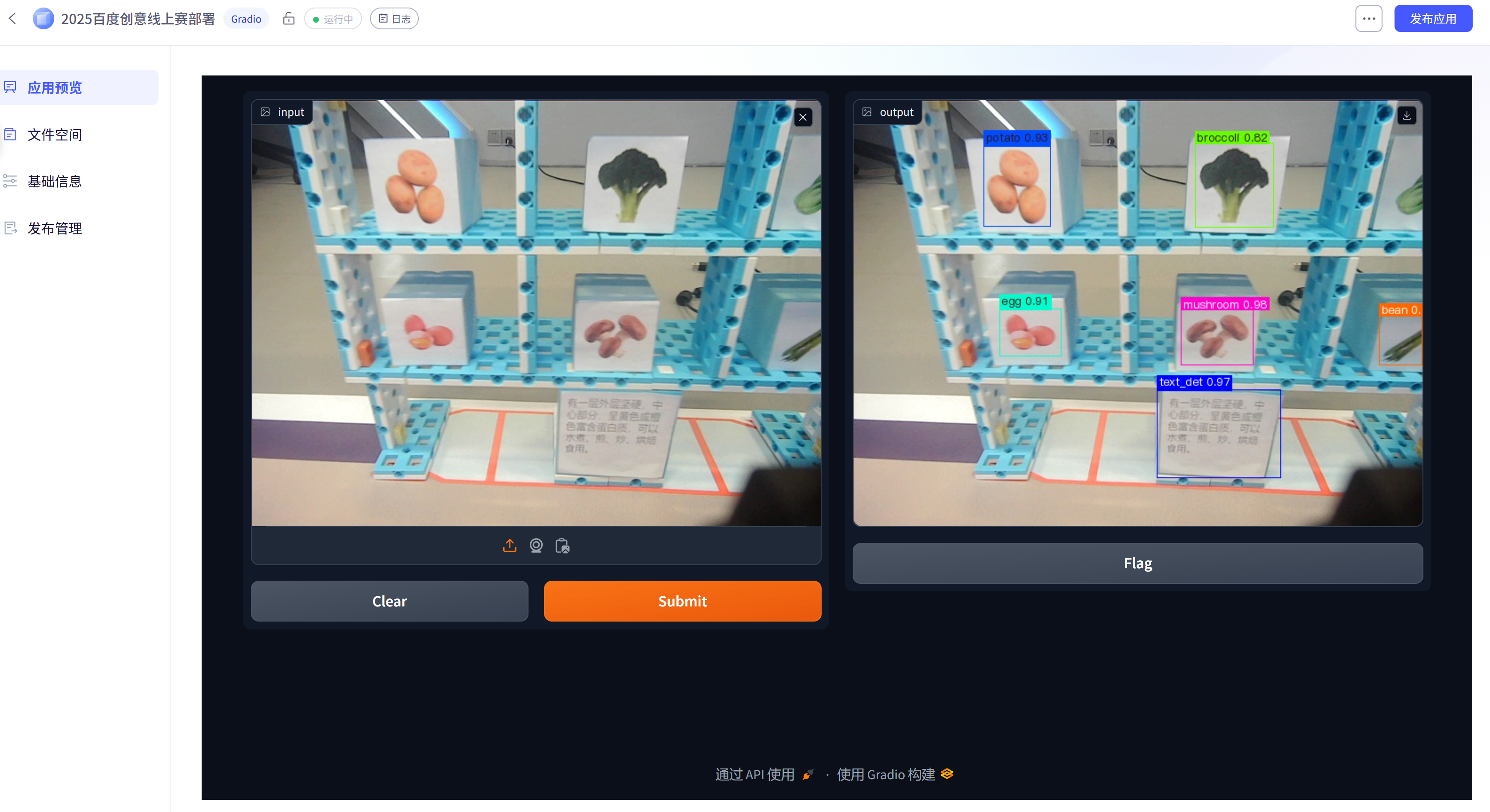
这里来说几个我自己踩的坑:
-
路径问题
这个坑我其实没踩,这里只是提醒一下,由于云端的路径和本地的不一样,如果是工作空间外的文件,需要放进工作空间,并且采用相对路径调用。 -
环境问题
这个估计很多人都遇到了,AI-Studio的环境居然没有PaddleX!
一种方法是把所有包放进工作空间,但不推荐,因为浪费空间。
我的解决方式是在代码里写一行运行pip install进行安装
可以自行实现一个小module,负责检查环境及安装,这样在主程序中调用一下之后,就可以正常运行有依赖的代码了(而且不会让主程序一开头就很丑)。 -
颜色问题
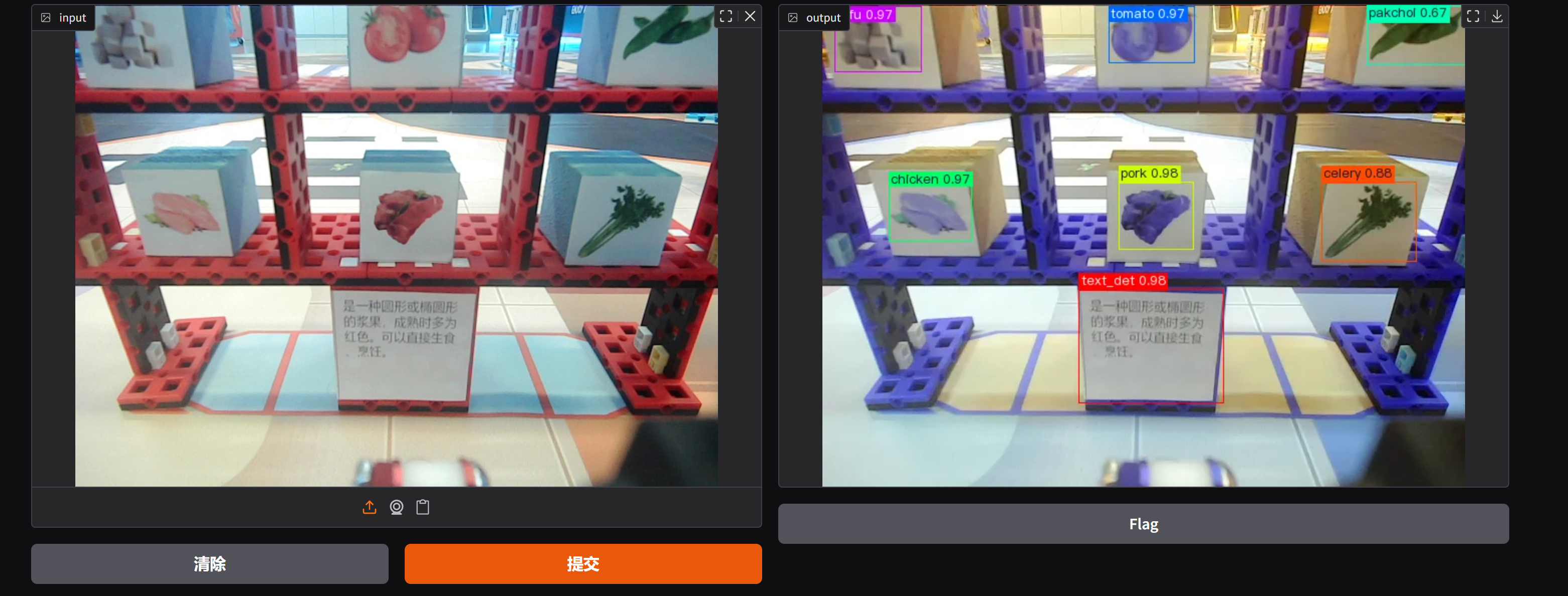
如图,输出图片的检测都正常,但是颜色不对
这是因为opencv默认的颜色格式是bgr而通常的显示会使用rgb,需要把颜色通道调换一下。
到这里,基本的配置流程就完结了,希望能帮到大家。
当然了,目前这篇文章还很不完善,以下内容还未加入:
- 训练服务器的搭建
- 自动标注
- 模型优化(包含数据集增强)
- etc.

















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









