









jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
下面是我写的一个案例欢迎大家参考:
package crawlerTest;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupTest {
public static void main(String[] args) throws IOException {
/*
* 解析一个字符串
*/
String html = "<html><head><title>First parse</title></head>"
+ "<body><p>Parsed HTML into a doc.</p></body></html>";
Document doc = Jsoup.parse(html);
System.out.println(doc);
/*
* 解析url
*/
String url="http://www.tripadvisor.com/SearchForums?q=airbnb&x=18&y=10&pid=34633&s=+";
Document doc1=Jsoup.connect(url).userAgent("bbb").timeout(50000).get();
Elements ele=doc1.select("table[class=forumsearchresults]").select("tr[class~=firstpostrow?]");
for (Element elem:ele) {
String _id=elem.attr("id");
String _url="http://www.tripadvisor.com"+elem.select("td[onclick~=setPID?]").select("a").
attr("href");
String _content=elem.select("td[onclick~=setPID?]").select("a").text();
System.out.println(_id+"===="+_url+"===="+_content);
}
}
}
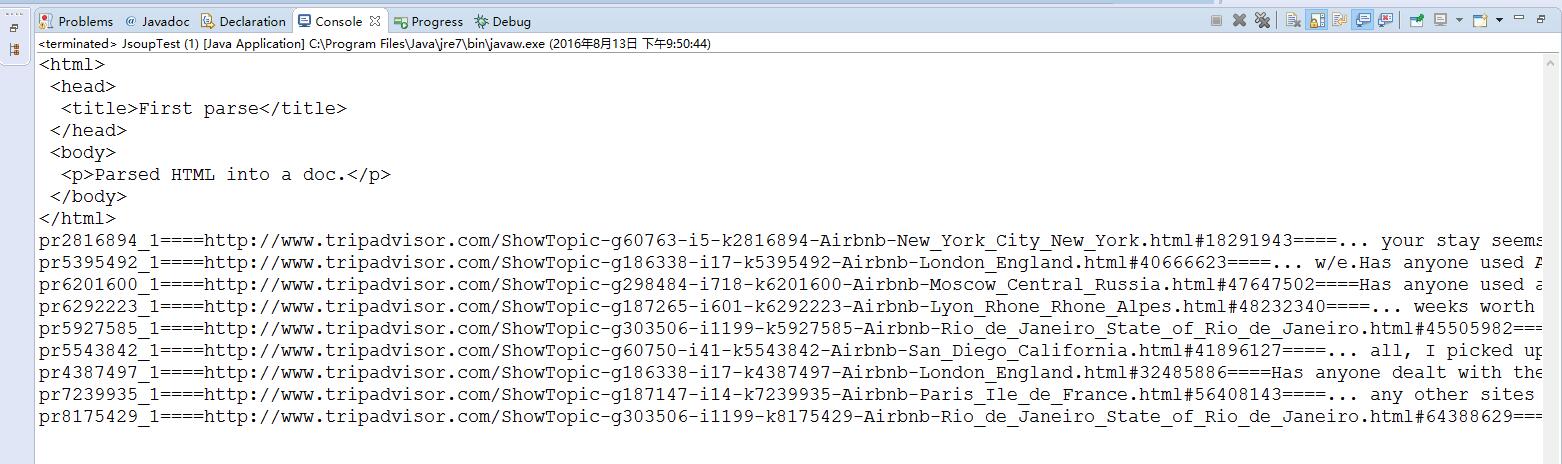
下图为我输出的结果:















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









