






1.MTL层的FIFO以及Queue:
TC3xx有4K的Tx FIFO以及8K的Rx FIFO。4个Tx Queue分享4K的Tx FIFO;4个Rx Queue分享8K的Rx FIFO。
1.1:FIFO和queue的关系:
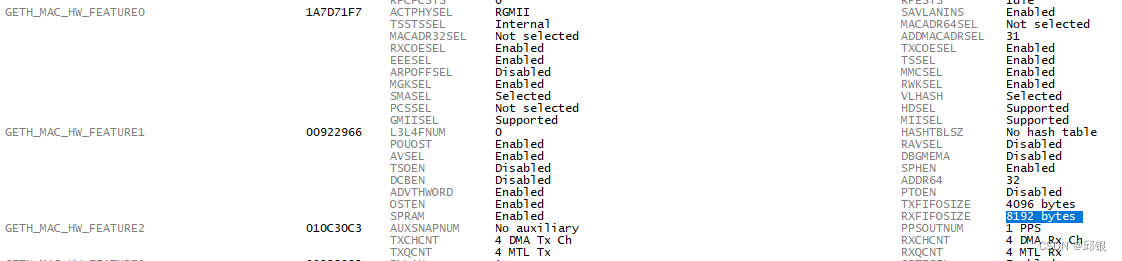
上述的MAC feature中可以看出TC3xx芯片上TXFIFO(4K)和RXFIFO(8K)的资源。
- 在UM的Queue Memory章节提到了Tx memory和Rx memory,如下图所示:

这段的描述讲述的是Geth模块理论上支持的最大FIFO大小,而非TC3xx实际的物理资源。
通过上述的解释可以看出Tx Queue和Rx Queue都是从FIFO里分出来的buffer资源,具体可以通过TQS和RQS进行细分。
2. Burst Mode
um中提到DMA请求burst transfer,也提到所谓beat和INCR transfer的关系,即:
如果只有一个beat,AHB就会触发SINGLE transfer(单拍传输);若有多个beat,AHB触发INCR transfer(未定义长度的自增传输)。
——而这里说的beat就要参考2.2中介绍的TxPBL;INCR就需要参考2.1节的介绍。
2.1. INCR transfer:未定义长度的自增传输
um中提到AHB initiate burst时候提到SINGLE,INCR4、INCR8、INCR16。参考下面的链接,其含义分别是:单拍传输;4拍自增传输;8拍自增传输以及16拍自增传输。
https://www.cnblogs.com/zhangcheng2020/p/16588110.html
2.2 EB代码中的设置:
代码中针对PBLX8和TXPBL、RXPBL寄存器进行了设置。
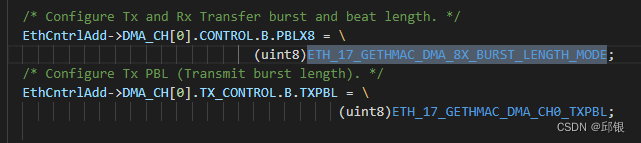
TxPBL:Transmit Programmable Burst Length。这个寄存器往往跟PBLx8配合起来使用,顾名思义就是“×8”的意思。
TxPBL的值等价于beat——一个beat会触发一个single transfer,也就是8字节的传输。

- TxPBL和PBLx8(如果设置)一起定义了transfer beats,按照data width为64bits(MAC Tx and Rx Common Feature中提到64bit data transfer interface)计算,那么一次INCR8 transfer(假设TxPBL=8),就可以将MTL FIFO中的64bytes发往MAC。
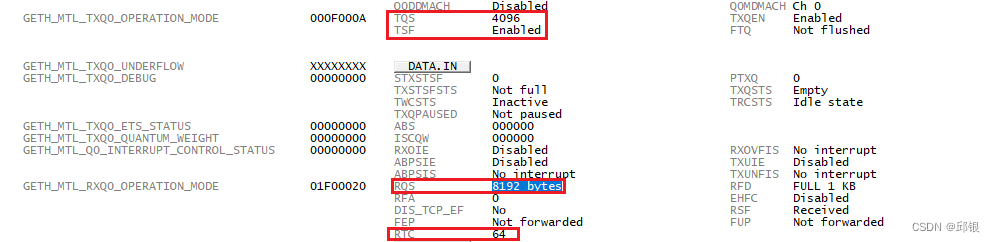
- um中也指出TxPBL的设置value的约束:即不能超过Tx FIFO长度的一半(寄存器:GETH_MTL_TXQ0_OPERATION_MODE.TQS)。
2.2.1.TQS:Transmit Queue Size:
在调试器中可以看到TQS=4096。

翻开EB的源码也可以看到EB对于Q0的初始化已经固化了这部分的设置:
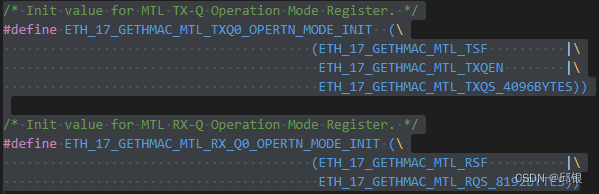
在寄存器MTL_TXQ#_OPERATION_MODE中有TQS的定义:这里的debug看到的是4096,但是他跟具体的寄存器的值(0x0F)还有一个换算关系:
我们之前提到过Queue Size是以256 byte = 1 block为单位的。换句话说,这里的TQS取决于我们愿意为这个Queue分配多大的空间(以256 btes为一个block来算):
- 如果我们愿意将4K的Tx FIFO都分配给Queue0,那么这里的TQS就是4096/256 = 16,也就是0x0F。
- 如果我们想分配一半的Tx FIFO给Queue0,剩下的给Queue1(如果Queue1使能的话),那么Queue0的TQS就是2048/256 = 8,也就是0x07.
2.2.2 RQS:Receive Queue Size:
跟TQS类似,在MTL_RXQ#_OPERATION_MODE中有RQS的定义,在MTL_TXQ#_OPERATION_MODE的TQS定义中,TQS一共占4bit,那么以256 bytes一个block为单位,一共有16个block,也就是4096。
类似的MTL_RXQ#_OPERATION_MODE中的RQS一共有占了5bit,同样以256 bytes一个block为单位,那么就是32个block,最大一个queue可以有8192个bytes。
3.DMA的中断类型以及使能:
3xx一共有4个channels,每一个channel都有独立的中断管理寄存器DMA_CHx_INTERRUPT_ENABLE,目前EB驱动里面仅仅使能了channel0,也就是说目前EB的Eth驱动不支持Qos(PCP)。
- DMA工作在System memory(Eth驱动代码中的descriptors)和MTL之间,换句话说就是通过AHB总线将数据从ram搬到TxFIFO的过程(反之是从RXFIFO搬运到system ram)。
- 每一个DMA 的channel对应MTL中的一个queue(四个queue共享FIFO)。
- DMA和Eth驱动程序通过“Control and Status registers”和“descriptors”进行信息交互。
- DMA_CH0_TXDESC_LIST_ADDRESS和DMA_CH0_RXDESC_LIST_ADDRESS分别记录descriptors的首地址:

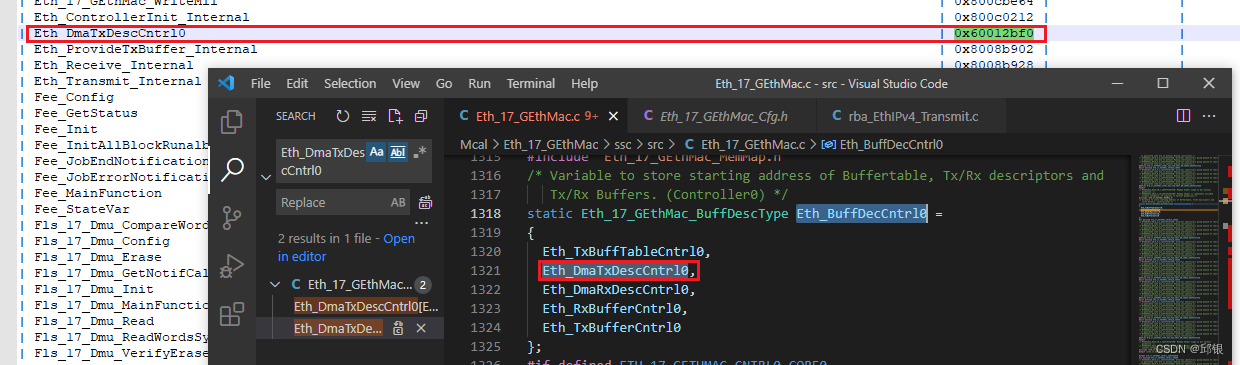
从RING_LENGTH = 0x13也可以看出软件中一共定义了有20个descriptors。同时驱动会维护一个Tx_buffer,长度为1528*RING_LENGTH。
这里的1528是EB工具为了8字节对齐而定义的长度:实际配置的不是1528,一般配置为frame的最大长度(1518或者1522)。
3.1. normal interrupt:
DMA的INTERRUPT_ENABLE中的某些bit触发(区分于SRC_GETH2.B.SRE的设置)发送完成中断以及接收完成中断。对应的是GETH_DMA_CHi_INTERRUPT_ENABLE寄存器设置
TIE:Enable DMA Channel0 transmit interrupt。
RIE:Enable DMA Channel0 receive interrupt。
详见3.4章节
3.2. abnormal interrupt:
还有一些异常情况也会触发DMA中断:
Transmit Buffer unavaliable interrupt和Receive Buffer unavaliable
详见3.4章节
3.3. interrupt periodically:
NULL;
3.4. 中断使能以及中断状态
无论是normal interrupt或者说abnormal interrupt。每一个中断都有状态bit以及相应的使能bit:
GETH_DMA_CHi_INTERRUPT_ENABLE、GETH_DMA_CHi_STATUS。这俩寄存器一个表示是否使能对应的中断,一个表明是否发生了相应的状态。
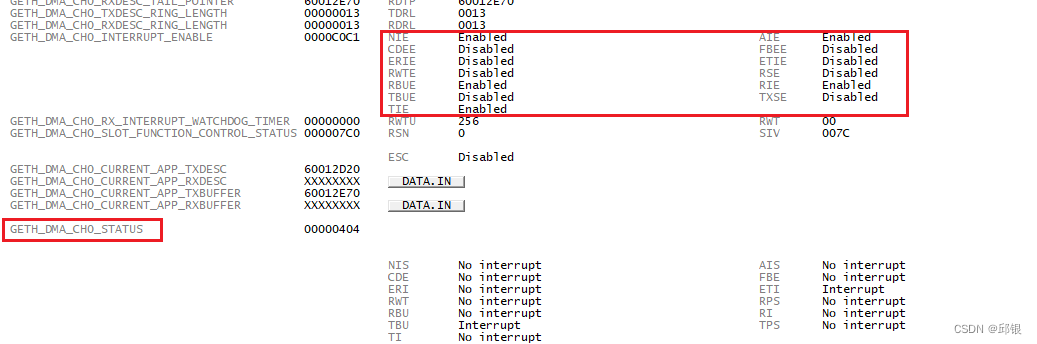
以channel0举例,分别有GETH_DMA_CH0_INTERRUPT_ENABLE和GETH_DMA_CH0_STATUS如下图所示:
这个初始化设置对应到EB驱动的Eth_17_lEnbaleGethInterrupt()
具体寄存器的信息如下图:
3.5.DMA Channel 和Queue的mapping:
3.5.1.Static mapping:
MTL_RXQ_DMA_MAP0 for queue 0 1,2,3; MTL_RXQ_DMA_MAP1 for queue 4,5,6,7。
DMA 仲裁机制对于4个channel来讲也有优先级一说,channel3>channel2>channel1>channel0。
3.5.2. Dynamic (Per Packet)Mapping:
3.6.isolar和davicn中为啥配ISR2~ISR9:
在davicn中我们都常用:
Interrupt Service Routine2来对应Queue0的Tx中断、Interrupt Service Routine6对应Queue0的Rx中断;
Interrupt Service Routine3来对应Queue1的Tx中断、Interrupt Service Routine7对应Queue1的Rx中断;
Interrupt Service Routine4来对应Queue2的Tx中断、Interrupt Service Routine8对应Queue2的Rx中断;
Interrupt Service Routine5来对应Queue3的Tx中断、Interrupt Service Routine9对应Queue3的Rx中断;
在Isolar中,我们常用
ETHSR0_ISR——Interrupt_SRC_GETH0(OSIsrAddress)
ETHSR2_ISR——Interrupt_SRC_GETH2——对应Queue0的tx
ETHSR6_ISR——Interrupt_SRC_GETH6——对应Queue0的Rx
在debug中观察IR.SRC寄存器为Eth模块准备了SRC_GETH0~SRC_GETH9这些个中断源管理单元。
3.6.1 SRC寄存器:
3.6.1.1.SRPN:
Eth的中断优先级,在一类中断时候,他可以设置1~255任意值
3.6.1.2. SRE:
Request enable,只有软件set了该bit,对应的中断服务程序才会被执行
3.6.1.3 TOS:type of service control
指定由哪个instance来响应中断。
Each Tricore CPU and Each syste DMA instance can act as an interrupt service provider(ISP)
000:CPU0
001:DMA?
010:CPU1
011:CPU2
100:CPU3
101:CPU4
110:CPU5
3.6.1.4. ECC
3.6.1.5. SRR:Service request flg
一旦有中断过来,硬件就会触发该bit,继而CPU响应中断
3.6.2 SRC index Number
387QP的SRCi从0xF0038000开始到0xF0038FF8(实际)结束,实际一共有1022个中断源。
通过看isolar的产物,可知GETH相关的SRC的地址,如下图所示: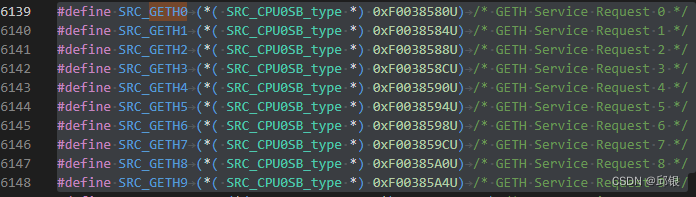
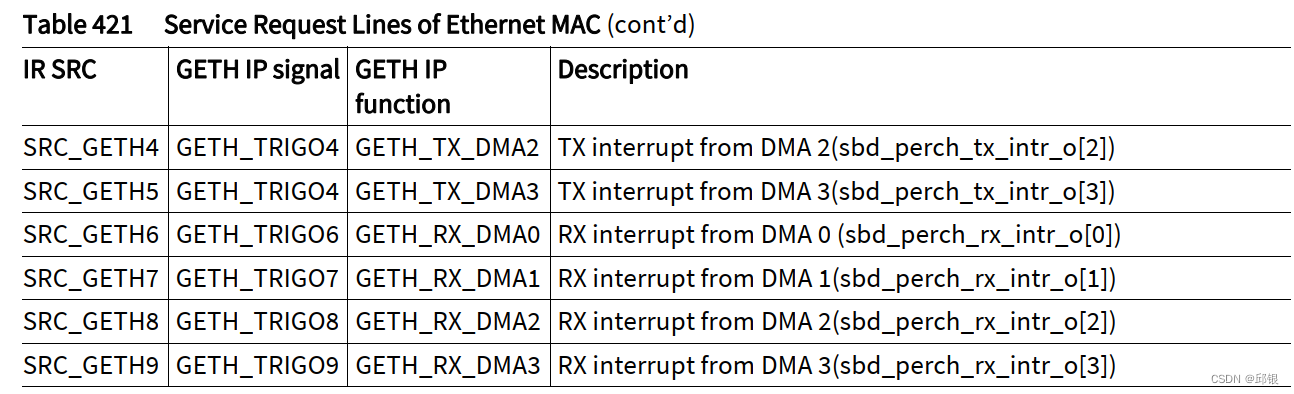
可以参见TC38x_appx_um_V1.2中的介绍,如下图所示:

3.6.3 SRC_GETH跟GETH_DMA_CH#_INTERRUPT_ENABLE之间是否有直接关系?
在isolar中,我们知道GETH_SRC的设置是在Os_InitializeInterruptTable中操作的,如下图所示:
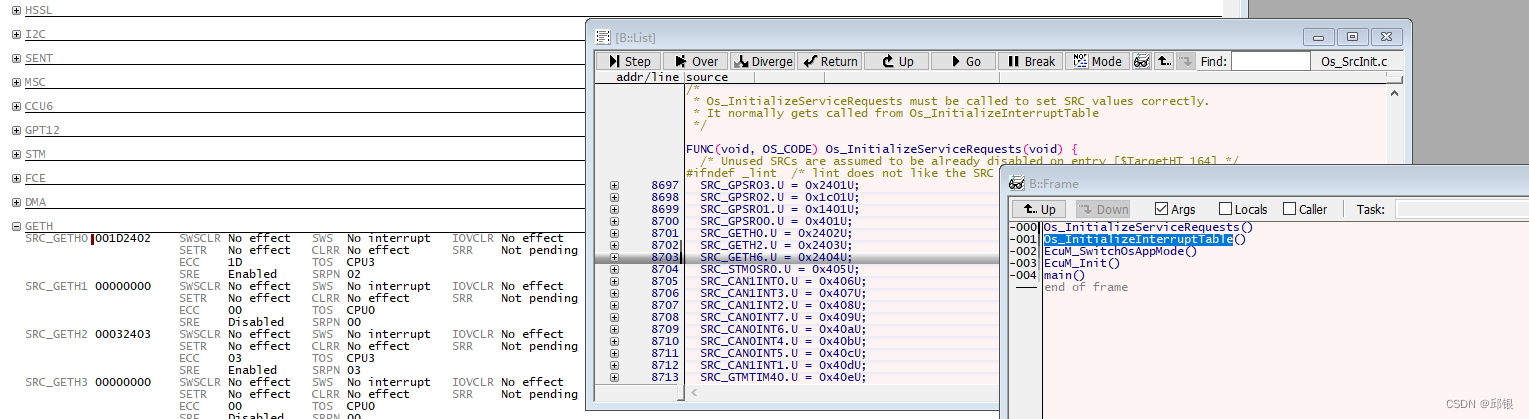
而GETH_DMA_CH#_INTERRUPT_ENABLE是在函数Eth_17_lEnbaleGethInterrupt()中设置的(3.4章节)。
4.Transmit / Receive Packet Processing:
4.1 Transmit Packet Processing:
数据的发送实际就是将数据从Transmit Descriptor中的buffer中搬移到 MTL的TX Queue里,数据到达TX FIFO中后还需要满足条件才可以触发实际的发送:
- Tx Queue中的数据超过transmit threshold(定义在TxQ#_OPERATION_MODE)——如果TSF(Transmit Store and Forward)使能后,该条件失效。
这里提到的threshold 是TTC(Transmit threshold Control),
- FIFO中有一个完整的frame——需要使能TSF。
从2.2.1截图中看到,目前我们选择的是第二种(使能TSF)。
4.1.1 发送挂起:
发送挂起一般由以下三个条件导致的:
- TDES3[31] = 0——在调用Eth_17_lTransmit时,需要将TDES3[31] = 1(此时descriptor被DMA所控制),来触发DMA数据搬运;在DMA数据搬移完成后,DMA将TDES3[31] = 0(可以被Application控制)。
这里提到的TDES3[31] = 0,表明descriptor此时正在被application拥有(owe),那么这时候,DMA会停止搬运,同时在GETH_DMA_CHi_STATUS的TBU(Transmit Buffer unavailable)置位。
一般而言,一旦发生类似的情况,GETH_DMA_CH0_STATUS的TBU(transfer Buffer Unavaliable)bit会置位:
——这是个常见的置位。但事实上Eth的发送并未停止,那是因为每次调用Eth_17_lTransmit时候都会重新设置TDES3[31] = 1.
- Transmit Error is detect because of underflow:
怎么理解文中提到的overflow以及underflow:
underflow的定义:

Overflow的定义:

- Tail Pointer equal to Current descriptor:
以当前的case举例子,一共有20(N)个descriptor,每个descriptor占16byte,也就是总共占320ytes。
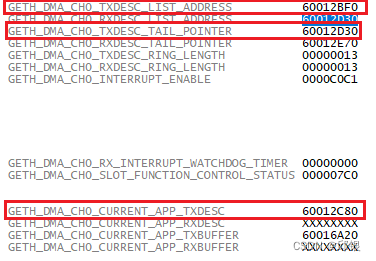
那么Current descriptor pointer依次轮询到的offset为0~19(N-1),也就是这里的0x60012BF0~0x60012D20,一旦Current descriptor pointer = tail_pointer,DMA就会报错。
4.1.2 descriptor quest和buffer quest区别:
目前在驱动代码中采用descriptor来传递system buffer 和MTL Queue之间的数据。
- descriptor quest
descriptor请求对于DMA仲裁来说其实使用的还是严格优先级:channel3>channel2>channel1>channel0
- buffer quest
buffer quest可以采用的优先级算法较多:WSP(Weighted Strict Priority)、WRR(Weighted Round Robin)以及Fixed Priority。
4.2 Receive Packet Processing:
- 一旦frame的MAC信息符合MAC的过滤条件,frame就会被搬移到MTL的Rx Queue中。
- 一旦Rx queue中的数据超过threshold,DMA就会启动数据搬运,将数据从Rx Queue中搬到descriptor指定的buffer中。小于64字节的frame将会从Rx queue中移除(若Forward Undersized Good Packets = 0)。

跟TSF的作用类似,接收端也有类似的寄存器RSF(Recieve Queue Store and Forward),一旦他使能了,刚提到的64bytes的阈值就失效了。
- 因为一个descriptor只能存储一个frame,若packet数据很大,那么则需要多个descriptor进行存储(待确认,因为UM中提到Descriptor allow large blocks of data transfer,each descriptor can transfer up to 32K)。
4.2.1 接收中断处理函数
在进入中断护理函数之后,做了一个general的判断:3.4章节提到的RI和RBU(Receive Buffer Unavaliable),若RBU置位,则去轮询所有的Rx descriptor。
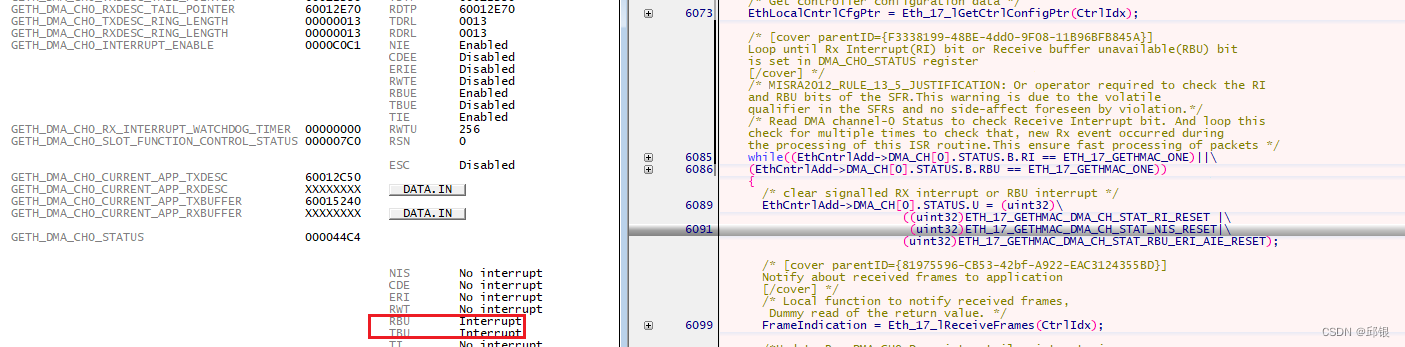
EB代码中通过for循环,轮询了所有被Application所OWN的Rx Descriptor(RDES3[31] = 0)。
在EB驱动里,Eth_17_lReceiveFrames会在两处被调用——一处中断,一处EthIf的轮询(Eth_Receive)
5.DMA如何识别到descriptor:
DMA如何识别到descriptor,并将数据从descriptor中搬到MTL的FIFO中?
在函数Eth_17_lDmaTxDescriptorInit()中将descriptor的地址给到了DMA的Channel TxDesc
那么软件中是如何定位GETH模块的基地址的?
在函数Eth_17_lDmaTxDescriptorInit()中,有一个变量Eth_GEthMacCntrl,而他存储了一个地址,这个地址就是GETH的基地址,所以说不需要pragma定位变量Eth_GEthMacCntrl,因为Eth_GEthMacCntrl它里面存储的是一个绝对地址。

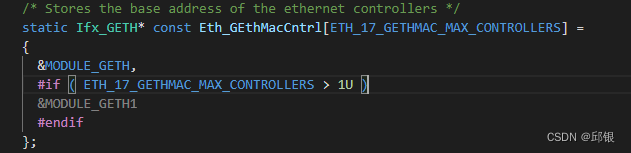

同理对于RxDescriptor的初始化,可以参考Eth_17_lDmaRxDescriptorInit()。















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









