






1.三维人脸重建:从一张或多张2D图像中重建出人脸3D模型。
2.3D人脸模型:M=(S,T)
其中,S表示人脸3D坐标形状向量。包含X,Y,Z,坐标信息。
这里的n指的是模型的顶点数,T表示对应点的纹理信息向量,包含R,G,B,颜色信息。
2D的人脸图片可以看作是3D人脸在2D平面杀昂的一个投影,I代表M的2D投影,I(u,v)代表像素(u,v)处的纹理值,所以3D人脸重建就是2D图片中计算出M的估计:M^=(S^,T^)
表示脸部模型;
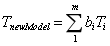
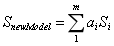
其中,这里的m是采集的人脸样本数。
上述的线性组合中,人脸样本数数量较大,且样本特征之间存在相关性,因此进行PCA(主成分分析)法。

3.纹理信息
分类:颜色纹理和几何纹理
颜色纹理:颜色的变化或者明暗的不同来表现出不同的纹理细节。
几何纹理:纹理不仅有颜色和明暗,并且还有凹凸感。
方式:
图像纹理(贴图纹理):通过映射把纹理图案中的像素--指定给三维物体表面。
函数纹理:通过数学函数生成的纹理图案,直接根据函数映射到物体表面,比如在屏幕上面生成棋盘。
纹理映射:通过数字化技术把纹理图案覆盖或者映射或者投射到三位物体的表面,给物体增加表面细节的过程。
纹理映射的思想:需要寻找一种纹理空间(u,v)坐标到三维物体曲面(s,t)坐标之间的映射关系,将纹理空间对应的坐标上对应的彩色参数值(R,G,B)映射到三维物体曲面上,从而使三位物体曲面得到彩色纹理细节。
4.什么是UV:
UV坐标是指所有的图像文件都是二维的一个平面。水平方向是U,垂直方向是V,通过这个平面的,二维的UV坐标系,我们可以定位图像上的任意一个像素。
多边形为了贴图就额外引进了一个UV坐标,以便把多边形的顶点和图像文件上的像素对应起来,这样才能在多边形表面上定位纹理贴图。所以说多边形的顶点除了具有三维空间坐标外,还具有二维的UV坐标。对于纹理贴图而言,一张贴图的U和V左边的数值范围都是0到1.
UV就是将图像上每一个点精确对应到模型物体的表面,在点与点之间的间隙位置由软件进行图像光滑插值处理,这就是所谓的UV贴图。
网格展开到平面区域,除了可展开到平面,其它曲面在展开后都会产生一些扭曲。一般有两种扭曲。一种是曲面本身的几何所决定的,比如球面展开到平面,一定会产生扭曲。想要减少展开的扭曲程度,可以在扭曲程度大的地方增加曲面割线,另一种是展开算法中的约束产生扭曲,比如固定边界的UV展开。一种直观的观察展开扭曲程度的方式是把一张棋盘格越均匀,UV展开扭曲越小。
4.人脸密集对齐:
人脸对齐可以看作在一张人脸图像搜索人脸预先定义的点(也叫人脸形状),通常从一个粗糙估计的形状开始,然后通过迭代来细化形状估计。人脸对齐要将人脸肿的eyes,mouth,nose,chin检测出来,用特征点标记出来。
人脸对齐,又叫做人脸特征点定位(检测),需要先人工指定点的具有规律的位置,然后再输入的人脸上按照特征点分布规律把点标记出来。
应用:1>五官定位;2>表情识别;3>人脸漫画,素描生成;4>增强现实;5>换脸;6>3D建模。
挑战:大姿态,夸张表情,光线明暗,遮挡,场景多变等问题。
稀疏人脸对齐:5、34或68个特征点;
密集人脸对齐:数以千计的特征点。

6,人么是人脸姿态;
姿态:(pitch,yaw,roll)三种角度,分别代表上下翻转,左右翻转,平面内旋转的角度

人脸姿态估计的思想:旋转三维标准一定角度,直到模型上“三维特征点”的“2维投影”,与待测试图像上的特征点(图像上的特征点显然是2维)尽量重合。
可以利用非线性最小二乘方法来建立模型,模型公式:
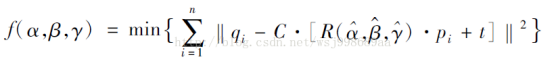
其中,(α,β,γ)代表人脸姿态三个旋转角度,N代表着一张人脸上标定特征点的歌书,qi代表着待测试人脸特征点,pi代表对应着的三维通用标准模型特征点,R代表旋转矩阵,t为空间偏移向量,s为伸缩因子。R的具体形式是:

7.3D Morphable Model (3DMM)即3维形变模型
算法的大致思想史利用一个人脸数据库构造一个平均人脸变形模型,在给出新的人脸图像后,将人脸图像与模型进行匹配结合,修改模型相应的参数,将模型进行形变,直到模型与人脸图像的差异减到最小,这时对纹理进行优化调整,即可完成人脸建模。
8:透视投影
在计算机三维图像中,投影可以看作是一种将三位坐标的方法,常用到的有正交投影和透视投影。正交投影多用于三维建模,透视投影则由于和人的视觉系统相似,多用于在2维平面中队三维世界的呈现。
透视投影是为了获得接近真实三维物体的视觉效果而在二维的纸或者画布平面上绘图或者渲染的一种方法,也称为透视图。它具有消失感,距离感,相同大小的形体呈现出有规律的变化等一系列的透视特性,能逼真地反应形体的空间形象。透视投影通常用于动画。视觉仿真以及其他许多具有真实性反应的方面。
9.什么是 3D Thin Plate Spline (TPS) transformation?
TPS是一种插值方法,寻找一个通过所有的控制点的弯曲最小的光滑曲面;就像一个薄铁板,通过所给定的几个“样条”(比如木条),铁板表面是光滑的,弯曲最小由一个能量函数定义,就是wiki上的那个双重积分。
10.什么是深度值:
深度其实就是该像素点在3d世界中距离(绘制坐标),深度缓存中存储着每个像素点(绘制在屏幕上的)的深度值!
深度值(Z值)越大,则离摄像机越远。
深度值是存贮在深度缓存里面的,我们用深度缓存的位数来衡量深度缓存的精度。
11.什么是语义信息
图像的语义分为视觉层,对象层和概念层,视觉层即通常所理解的底层,即颜色,纹理和形状等等,这些特征都被称为底层特征语义;对象层即中间层,通常包含了属性特征等,就是某一对象在某一时刻的状态;概念层是高层,是图像表达出的最接近人类理解的东西,通俗说:比如一张图上有沙子,蓝天,海水等,视觉层是一快快的区分,对象层是沙子,蓝天,海水这些。概念层就是海滩,这是这张图表现出的语义。
12.定性分析定量分析
定性分析就是对研究对象进行“质”的仿麦呢的分析。具体地说是运用归纳和演绎、分析与综合以及抽象于概括等方法,对获得的各种材料惊醒思维加工,从而能去粗取精,去伪存真,由此及彼、由表及里,达到认识事物本质、揭示内在规律。定量分析:对社会现象的数量特征、数量关系与数量变化的分析。其功能在于揭示和描述社会现象的相互作用和发展趋势。定性--用文字语言进行相关描述;定量--用数学语言进行描述。
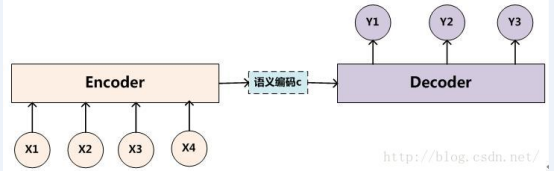
13.编解码网络:
Encoder-Decoder并不是一个具体的模型,二十一类框架。Encoder和Decoder部分可以是任意的文字、语音、图像、视频数据、模型可以采用CNN,RNN,BIRNN。LSTM、GRU等等。所以基于Encoder-Decoder,我们可以设计出各种各样的应用算法。
Encoder-Decoder框架由一个最显著的特征就是它是一个End-to-End学习算法,所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
14.End-to-end(端到端)学习
非端到端:相对于深度学习,传统机器学习的流程往往由多个独立的模块组成,比如在一个典型的自然语言处理问题中,包括分词、词性标注、句法分析、语义分析等多个独立步骤,每个步骤是一个独立的任务,其结果的好坏会影响到下一个步骤,从而影响整个训练的结果,这时非端到端的。
端到端:而深度学习模型在训练过程中,从输入端(输入数据)到输出端会得到一个预测结果,与真实结果相比较会得到一个误差,这个误差会在模型中的每一层传递(反向传播),每一层的表示都会根据这个误差来做调整,直到模型收敛或者到预测期的效果才结束,这是端到端。
两者相比,端到端的学习省去了在每一个独立学习任务执行之前所做的数据标注,为样本做标注的代价是昂贵的,易出错。
15.UV posittion map(UV位置贴图)
作用:记录完整人脸点云的坐标;在每个位置保留了语义。
性质:2D图像
16.Weight mask(权值面具)
作用:为位置映射图上每个点分配不同的权重,并计算加权损失。
优点:有助于提高网络性能。
17.什么是FPS?
FPS是图形领域中的定义,指的是每秒传输帧数,通俗来讲就是指动画或视频的画面数。FPS是测量用于保存、显示动态视频的信息数量。
18.什么是重采样(re-sample)
重采样:就是根据一类像元的信息内插出另一类像元信息的过程。在摇感中,重采样是从高分辨率遥感影像中提取出低分辨率影像的过程。
常用的重采样方法有最邻近内插法(nearest neighbor interpolation)、双线性内插法(bilinear interpolation)和三次卷积法内插(cubic convolution interpolation)。其中,最邻近内插法最为简单,计算速度快,但是视觉效应差;双线性插值会使用、图像轮廓模糊;三次卷积法产生的图像较平滑,有好的视觉效果,但计算量大,较费时。
19.残差网络
误差是衡量观测值和真实值之间的差距,残差是指预测和观测值之间的距离。
实验表明,残差网络更容易优化,并且能够通过增加相当的深度来提高准确率。
核心是解决了增加深度带来的副作用(退化问题)。这样能够通过单纯地增加网络深度,来提高网络性能。
20.转置卷积层
转置卷积层又称反卷积层或分数卷积层,可用于恢复减少的维数(上采样)。转置卷积层我们就会用stride小于1的卷积进行上采样,使输出的size变大。
21.三角网络(Triangle Mesh)
三角网络是多变形网络的一种,多边形网络又被称为“Mesh”,是计算机图形学中用于为各种不规则物体建立模型的一种数据结构,实现世界中的物体表面直观上都是由曲面构成的;而在计算机世界中,由于只能用离散的结构去模拟现实中连续的事物。所以实现世界中的曲面实际上在计算机里由无数个小的多边形面片去组成的。
22.OBJ文件
OBJ文件时Alias|Materials公司为它的一套基于工作站的3D模型建模和动画软件“Advanced Visualizer”开发的一种标准3D模型文件格式,很适合用于3D软件之间的互导。
(1)OBJ文件时一种3D模型文件,不包括动画、木制特性、贴图路径、动力学、粒子等信息。
(2)OBJ文件主要支持多变形(Polygons)模型。虽然也支持曲线(curves)、表面(Surfaces)、点组材质(Point Group Materials),但Maya导出的OBJ文件并不包括这些信息。
(3)OBJ文件支持三个点以上的面,这一点很有用,很多其它的模型文件格式只支持三个点的面,所以导入Maya的模型经常被三角化了,这对于我们模型进行再加工甚为不利。
(4)OBJ文件支持法线和贴图文件路径就行了,不需要再调整贴图坐标。
23.文章创新
设计一个2D表示名为UV位置贴图,他记录完整人脸再UV空间的3D形状,然后训练了一个卷积神经网络从2D图像中回归出UV位置贴图,将权值面具整合到损失函数中,以再训练中提高网络表现,该方法不依赖任何人脸模型,就能重建3D人脸且保留语义信息。
















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









