







此番外篇系列的源代码,已在github上传,链接: Rainbowkv/python_ext
概述
前两篇我们已经编写了Python的C和C++扩展,分别使用了CPython官方的接口和Pybind11对前者友好封装的接口。
本篇我们来编写一个CUDA程序来调度显卡,进一步写成Python的扩展包。您如果看过C++扩展篇本篇会非常轻松。
有了前面的基础,CUDA扩展的步骤是类似的,几乎仅仅是.cpp文件换为了.cu文件而已。
您需要安装一个CUDA库,官方下载地址,本文选用CUDA18:
在其bin目录下,有nvcc.exe这个编译.cu文件的编译器。
如果cmake部分您觉得不够详细,请您查看这篇文章。准备好这些让我们开始吧。
一、 .h文件
这里很轻松,定义并导出函数calculate,cuda程序仍然会被我们导出为动态库dll(linux下为.so)。
注意extern "C"告诉cpp编译器不要修饰这个函数名即可(nvcc编译.cu文件时,碰到原始cpp代码会调用C++编译器)。
#include<iostream>
#ifndef DDL_IMPORT
#define API __declspec(dllexport)
#else
#define API __declspec(dllimport)
#endif
extern "C"{
API void calculate(int n_power, int iters_power);
}
二、.cu文件
这里是我们的cuda程序源码。为了理解代码,引入一个核函数的概念。
- 显卡核心数的数量级一般是103以上的,成千上万个核心可以同时执行同一个函数(即同一套逻辑),给此函数一个名称->核函数。
- 假如我们要完成的任务是计算一个长度为1024(n_power=10即n=210)的一维向量加法,gpu的解决方案是直接开1024个线程,每个线程都有自己的唯一编号,介于0~1023之间。
因此CPU本来要执行1024次循环的计算,GPU一次完成。因为它直接可以拿出1024个核,1024个线程同时并行执行(0号线程计算d_a(0)+d_b(0)存到d_c(0),1号计算d_a(1)+d_b(1)存到d_c(1),依次类推)。
然后您就能很明白的看懂代码。
- 我们首先通过标识符__global__(CUDA规定)定义一个核函数_calculate。获取当前线程在全局中的idx,负责计算它自己位置的那个加法。第一个if是我们让7号线程打印了hello,;第二个if是因为idx可能会大于1023,也就是线程数可能超过向量的长度(我们开线程会向上取整),所以需要处理下越界,超出范围便不计算。
// #include<cuda_runtime.h>
#include"rb_cuda.h"
__global__ void _calculate(float* d_a, float* d_b, float* d_c, int n, int iters){
int idx = blockDim.x * blockIdx.x + threadIdx.x; // 全局唯一ID
if(idx == 7){
printf("Hello from cuda_0: thread_7 .\n");
}
if(idx < n){
for(int i=0;i<iters;i++)
d_c[idx] += d_a[idx] + d_b[idx];
}
return;
}
void calculate(int n_power, int iters_power){
// void calculate(int n, int iters){
int n = 1 << n_power; // n=2^n_power
int iters = 1 << iters_power; //iters=2^iters_power
printf("rb_cuda checking -> n: %d, iters: %d .\n", n, iters);
int block_size = 256; // 每个网格的线程数
int grid_size = ceil(n/block_size); // 计算我们需要多少网格,向上取整,因为要计算每一个位置,所以不能少于n,。
printf("grid_size: %d .\n", grid_size);
int size = n*sizeof(float);
float* h_a = (float*)malloc(size); // 申请内存
float* h_b = (float*)malloc(size);
float* h_c = (float*)malloc(size);
for(int i=0;i<n;i++){ // 模拟真实数据
h_a[i] = i;
h_b[i] = i;
}
float* d_a, *d_b, *d_c;
cudaMalloc((void **)&d_a, size); // 申请显存
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice); // 内存数据拷贝到显卡
cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
std::cout << "Correspond cpu_thread is blocked...\n" << std::endl;
_calculate<<<grid_size, block_size>>>(d_a, d_b, d_c, n, iters);
// 调用核函数的固定写法,当grid_size = 0时,核函数不会被调用(一次都不会执行)
cudaDeviceSynchronize();
cudaMemcpy(h_c, d_c, n, cudaMemcpyDeviceToHost); // 显存结果数据拷贝回内存
cudaFree(d_a); // 释放显存
cudaFree(d_b);
cudaFree(d_c);
for(int i=0;i<1<<4;i++){
printf("%f + %f = %f\n", h_a[i], h_b[i], h_c[i]);
}
free(h_a); // 释放内存
free(h_b);
free(h_c);
std::cout << "Correspond cpu_thread is running...\n" << std::endl;
return;
}
- 第二个函数calculate主要是申请内存,然后将数据移到显存上去,GPU才可以拿到数据并计算,最后将计算结果移回内存。请您参考注释。
三、CMake构建CUDA项目
编写CMakeLists.txt
cmake_minimum_required(VERSION 3.23)
# 设置CUDA架构,这里数字代表算力,不确定是显卡的算力就可以像下面一样都填上
set(CMAKE_CUDA_ARCHITECTURES "60;61;62;70;72;75;80;86;89")
# 设置C++标准
set(CMAKE_CXX_STANDARD 17)
# 设置项目名称和使用的语言
project(RBCUDA LANGUAGES CXX CUDA)
# 包含头文件目录
include_directories(${CMAKE_CURRENT_SOURCE_DIR}/include)
# 查找CUDA工具包
find_package(CUDAToolkit REQUIRED)
# 查找源文件,生成源文件列表
file(GLOB SOURCE_DIR ${CMAKE_CURRENT_SOURCE_DIR}/*.c* ${CMAKE_CURRENT_SOURCE_DIR}/*.h)
# 添加共享库
add_library(rb_cuda SHARED ${SOURCE_DIR})
# 链接CUDA运行时库
target_link_libraries(rb_cuda PUBLIC CUDA::cudart)
往下走的构建流程与这篇文章一模一样,确保您当前目录结构:
├─ include
├─ rb_cuda.h
├─ rb_cuda.cu
└─ CMakeLists.txt
执行:
mkdir build
mkdir lib
mkdir tensor_add
cd build
cmake ..
cmake --build . --config=Release
现在您的目录结构:
├─ build
├─ Release
├─ rb_math.dll
├─ rb_math.lib
├─ rb_math.exp
├─ include
├─ rb_cuda.h
├─ lib
├─ rb_math.dll # 手动从build/Release中复制过来
├─ tensor_add
├─ tensor_add.cpp # 下面展示这个文件内容
├─ __init__.pyi # 您可以不要这两个pyi,C++扩展章节有讲。
├─ calculate.pyi
├─ rb_cuda.cu
├─ setup.py # 下面展示这个文件内容
└─ CMakeLists.txt
四、tensor_add.cpp和setup.py
tensor_add.cpp仅负责注册函数,由pybind11帮忙,它其实可以自动处理传参和返回参数的逻辑,我们不需要告诉它函数接受和返回参数,C++扩展中我们只使用了缺省返回参数的功能。
#include <pybind11/pybind11.h>
#include "rb_cuda.h"
PYBIND11_MODULE(tensor_add, m) {
m.def("calculate", &calculate_wrapper, "Calculate the sum of two vectors repeated specified times.");
}
setup.py在这篇文章有详尽解释,这里是一样的逻辑。
from setuptools import setup
from pybind11.setup_helpers import Pybind11Extension, build_ext
include_path = "include/"
dll_path = "build/Release/"
ext_modules = [
Pybind11Extension(
"rainbow_cuda.tensor_add", # 这将生成rainbow/math.pyd的文件
["tensor_add/tensor_add.cpp"],
include_dirs=[include_path],
library_dirs=[dll_path], # 去这里找相应动态库的.lib完成符号解析
libraries=["rb_cuda"] # language参数默认c++
)
] # 1. 简单的项目就可以这样构造
setup(
name="rainbow_cuda",
version="0.0.1",
author="rainbow",
author_email="rainbowkv@163.com",
description="A cuda extension package made by rainbow",
packages=["rainbow_cuda", "rainbow_cuda.tensor_add", "rainbow_cuda.lib"],
package_dir={"rainbow_cuda": ".", "rainbow_cuda.tensor_add": "tensor_add", "rainbow_cuda.lib": "lib"}, # 前者是包名,后者是包名指定的目录。即告诉setuptools哪个目录就是这个包。这样math才不会在site-packages下与rainbow同级,而是在rainbow目录下
package_data={"rainbow_cuda.lib": ["*.dll"]}, # 指定不想被过滤的非python的文件
ext_modules=ext_modules, # 1. 简单的项目就可以这样构造
cmdclass={"build_ext": build_ext},
zip_safe=False,
classifiers=[
"Programming Language :: Python :: 3",
"Programming Language :: C++",
"Programming Language :: CUDA",
"Operating System :: OS Independent",
],
python_requires='>=3.6',
)
执行命令:
python setup.py bdist_wheel
pip install dist\yourfilename.whl
测试一下:
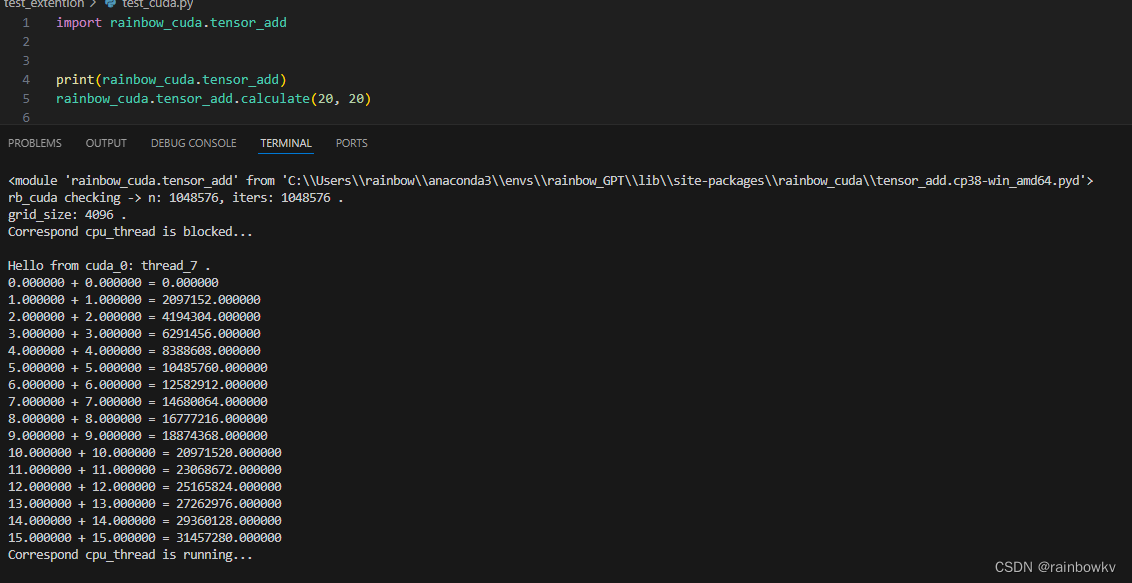
(可以运行的同时查看您的显卡占用)
这里15 + 15 = 31457280做一个解释,注意传参calculate(20,20),
我们的代码逻辑是将d_a[16]+d_b[16]重复加了220 次,等价于乘上220 。
(15+15) * 1024 * 1024 = 31457280
完美
谢谢您的支持,如果您发现问题或有什么新的想法可以联系作者。















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









