







一、媒体流(streams )
流线程中包含事件和缓存如下:
-events
-NEW_SEGMENT (NS)
-EOS (EOS) *
-TAG (T)
-buffers (B) *
其中标* 号的需要同时钟进行同步。
典型的流如图1 所示:
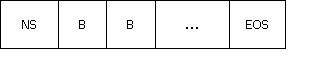
图1 媒体流组成图
(1 )NEW_SEGMENT,rate, start/stop, time
包括了有效的时间戳范围(start/stop );stream_time; 需要的回放率以及已经应用的回放率。
(2 )Buffers
只有处于NEW_SEGMENT 的start 和stop 之间的buffers 是可以被显示的,否则将被丢弃或者裁剪。
running_time 的计算:
if(NS.rate > 0.0)
running_time= (B.timestamp - NS.start) / NS.abs_rate + NS.accum
else
running_time= (NS.stop - B.timestamp) / NS.abs_rate + NS.accum
stream_time 的计算:
stream_time= (B.timestamp - NS.start) * NS.abs_applied_rate + NS.time
(3 )EOS
数据的结束。
二、几个时钟概念
1、clock time(absolute_time): 管道维护的一个全局时钟,是一个以纳秒为单位单调递增的时钟时间。可以通过gst_clock_get_time()函数获取。如果管道中没有元素提供时钟,则使用该系统时钟。
2、base time: 媒体从0开始时全局的时间值。可以通过_get_time()函数获取。
3、Running time: 媒体处于PLAYING状态时流逝的时间。
4、stream time: 媒体播放的位置(在整个媒体流中)。
如图2所示。

图2 Gstreamer时钟和变量图(引自Gstreamer文档)
由此可以得出:
running_time = clock_time - base_time;
如果媒体流按照同一频率从开始到结束运行,那么running_time == stream_time;
Running time的详细计算:
running_time是基于管道所选的时钟的,它代表了媒体处于PLAYING状态的总时间,如表1所示。
表1 running_time的计算表
管道状态
running_time
NULL/READY
undefined
PAUSED
暂停时的时间
PLAYING
absolute_time - base_time
Flushing seek
0
三、时钟的提供与同步原理
clock providers:
由于媒体播放的频率与全局时钟的频率不一定相一致,需要元素提供一个时间,使得按照其需要的频率进行播放。主要负责保证时钟与当前媒体时间相一致。需要维护播放延迟、缓冲时间管理等,影响A/V同步等。
clock slaves:
负责从包含他们的管道中获得分配一个时钟。常常需要调用gst_clock_id_wait()来等待播放他们当前的sample,或者丢弃。
当一个时钟被标记为GST_CLOCK_FLAG_CAN_SET_MASTER时,它可以通过设置从属于另一个时钟,随后通过不断地校正使得它与从属的 主时钟进行同步。主要用于当组件提供一个内部时钟,而此时管道又分配了一个时钟时,通过不断地校正从而使得它们之间同步。 在主从时钟的机制中又引入了内部时间和外部时间的概念:
内部时间:时钟自己提供的时间,未做调整的时间;
外部时间:在内部时间基础上,经过校正的时间。
在clock中保存着internal_calibration, external_calibration, rate_numerator, rate_denominator属性,并利用这些值校正出外部时间,校正公式为
external = (internal – cinternal) * cnum / cdenom + cexternal;
其中external, internal, cinternal, cnum, cdenom, cexternal分别表示外部时间,内部时间,clock中保存的内部校正值,校正率分子,校正率分母,外部校正值。
主从同步可以同过一下三个属性来调整:
1、timeout:定义了从时钟对主时钟进行采样的时间间隔;
2、window-size:定义了校正时需要采样的数量;
3、window-threshold:定义了校正时最少需要的采样数量。
为了同步不同的元素,管道需要负责为管道中的所有元素选择和发布一个全局的时钟。
时钟发布的时机包括:
1、管道进入PLAYING状态;
2、添加一个可以提供时钟的元素;
发送一个GST_MESSAGE_CLOCK_PROVIDE消息——>bus——>通知父bin——>选择一个clock——>发送一个NEW_CLOCK消息——>bus
3、移除一个提供时钟的元素;
发送一个CLOCK_LOST消息——>PAUSED——>PLAYING
时钟选择的算法:
1、从媒体流的最上(most upstream)开始选择一个可以提供时钟的元素;
2、如果管道中所有元素都不能提供时钟,则采用系统时钟。
管道的同步通过如下三个方面实现:
1、GstClock
管道从所有提供时钟的元素中选取一个时钟,然后发布给管道中的所有元素。
2、Timestamps of GstBuffer
3、NEW_SEGMENT event preceding the buffers
正如前面所提到的,running_time有两种计算方式:
1、用全局时钟和元素的base_time计算
running_time = absolute_time – base_time;
2、用buffer的时间戳和NEWSEGMENT事件计算(假设rate为正值)
running_time = (B.timestamp - NS.start) / NS.abs_rate + NS.accum
同步主要是保证上述两个时间计算值的相同。即
absolute_time – base_time = (B.timestamp - NS.start) / NS.abs_rate + NS.accum
而absolute_time也就是Buffer的同步时间(B.sync_time == absolute_time),因此
B.sync_time = (B.timestamp - NS.start) / NS.abs_rate + NS.accum + base_time
在render之前需要等待,直到时钟到达sync_time;对于多个流,则是具有相同running_time的将会同时播放;解复用器 (demuxer)则需要保证需要同时播放的Buffers具有相同的running_time,因此会给Buffers附上相同的时间戳以保证同步。
四、延迟(latency)的计算与实现
1、延迟的引入
管道中元素与时钟的同步仅仅发生在各个sink中,如果其他元素对buffer没有延迟的话,那么延迟就为0。延迟的引入主要是基于这样的考 虑,buffer从source推送到sink会花费一定的时间,从而可能导致buffer被丢弃。这个问题一般发生在活动管道,sink被设置为 PLAYING并且buffer没有被预送(preroll)至sink。
2、延迟的实现
一般的解决方案是在被预送(preroll)之前所有的sink都不能设置为PLAYING状态。为了达到这样的目的,管道需要跟踪所有需要预送的元素 (就是在状态改变后返回ASYNC的元素),这些元素发送一个ASYNC_START消息,当元素进行预送,便把状态设置为PAUSED,同时发送一个 ASYNC_DONE消息,该消息恰好与之前的ASYNC_START相对应。当管道收集了所有的与ASYNC_START消息对应的 ASYNC_DONE消息以后便可以开始计算全局延迟了。
3、延迟的计算
延迟的计算方法如图3所示。
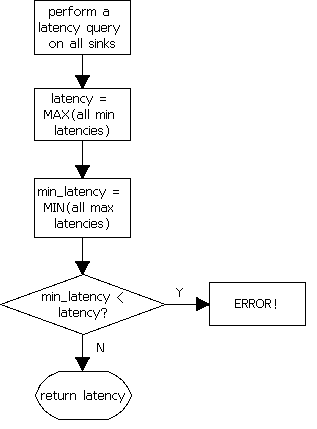
图3 延迟的计算
管道通过发送一个LATENCY事件给管道中的所有sink来给管道设置延迟,该事件为sinks配置总的延迟,延迟对所有的sink来说都是相同的,这样sink在提交数据时可以保持相对的同步。
五、服务质量(QoS)
服务质量是关于衡量和调整管道的实时性能的。实时性能的衡量主要在于管道的时钟,通常发生在sink中buffer的同步。
QoS一般用于视频的buffer中,原因有两个,其一,相对于视频来说,丢弃音频是会带来更大的麻烦,这是基于人的生理特征的考虑;其二,视频比音频需要更多更复杂的处理,因此会消耗更多的时间。
服务质量问题的来源:
1、CPU负载;
2、网络问题;
3、磁盘负载、内存瓶颈等。
衡量的目的是调整元素中的数据传输率,主要有两种类型的调整:
1、在sink中检测到的短时间紧急调整;
2、在sink中检测到的长期调整(传输率的调整),对整个趋势的检测。
服务质量事件:
服务质量事件由元素收集,包括以下属性:
1、timestamp
2、jitter
timestamps与当前时钟的差值,负值表示及时到达(实际上是提前到达的时间值),正值表示晚的时间值。
3、proportion
为了得到优化的质量相对于普通数据处理率的一个理想处理率的预测。
服务质量主要在GstBaseSink中实现,每次在对到达sink的buffers进行一次render处理后都会触发一个服务质量事件,该事件通过把 计算好的一些信息发送给upstream element,来通知upstream element进行相应调整以保证服务质量(主要是音频和视频的同步)。而这其中的一个关键信息则是处理率,对处理率的计算如下:
先了解各AVG值的计算:
next_avg = (current_vale + (size – 1) * current_avg) / size
这其中的size一般为8 ,处理率平均值的计算例外(4或16)。
jitter是由buffer的时间戳和当前时间来计算的。
jitter = current_time – timestamps;
jitter < 0 说明buffer提前到达sink;
jitter > 0 说明buffer迟了jitter长的时间到达sink;
jitter = 0 说明正好。
下面逐步说明处理率rate的计算过程:
start = sink->priv->current_rstart;
stop = sink->priv->current_rstop;
duration = stop – start;
如果jitter < 0 , 则 entered = start + jitter; left = start;
如果jitter > 0 , 则 entered = left = start + jitter;
其中entered表示buffer到达sink的时间,left表示buffer被render出去的时间。
pt = entered – sink->priv->last_left;
根据上述计算平均值的公式计算出avg_pt和avg_duration;
rate = avg_pt / avg_duration;
如果0 < rate < 1,说明upstream element生产速度比较快,导致sink来不及处理,会产生flood的情况;
如果 rate = 1, perfect;
如果 rate > 1,说明upstream element不能提供足够的buffer给sink,会导致starvation的情况。
随后通过发送QoS message的方式将当前buffer的timestamp,jitter和rate发送给upstream elements,告知他们作相应的处理,比如丢弃一些buffer。并且可以对下一次可以及时render的buffer进行估计。
六、同步的实现
gstreamer的同步主要在sink中实现,在render之前进行,因此一般在函数GstBaseSink::render中具体实现。同步指的是 buffer在进入到每个sink,render之前与时钟的同步。媒体流在解复用后,在其多个流(比如音频流和视频流)的buffers中附加了时间 戳,因此在sink进行输出之前分别与时钟进行同步,即可达到A/V的同步输出。
在gstreamer-0.10.3之前,同步在GstBaseSink的函数gst_base_sink_render_object()中实现(如图 4所示),子类对其进行覆盖的很少。在之后版本中,在某些具体的sink子类中进行了覆盖,使得同步的效果达到了最佳。比如在 GstBaseAudioSink的函数gst_base_audio_sink_render()中对Audio的同步进行了覆盖。然而对于视频的同步 并没有进行覆盖,仍然在基类中进行实现。因此A/V同步的实现主要看gst_base_sink_render_object()和 gst_base_audio_sink_render()两个方法。
gst_base_sink_render_object()处理流程如图4所示。其中sync object的流程如图5所示。

图4 render object处理流程
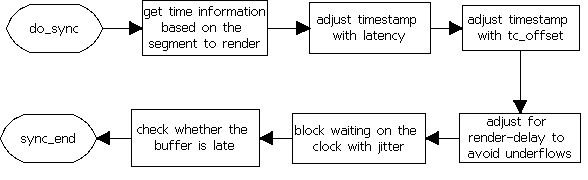
图5 sync object流程图
在对音频的处理中,引入了ringbuffer的概念,仅用于音频中,类名为GstRingBuffer,下面对ringbuffer的设计做一个简单的介绍:
ringbuffer由若干连续的segment组成,它有一个播放位置,并且播放位置总是以segment为单位的,该位置是设备当前从缓冲区中读sample的位置。如图6所示。
处于播放状态时,samples被写入设备,在每次写入一个segment后,ringbuffer将会调用其配置好的回调函数,并且播放位置向后移动。
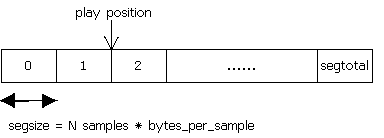
图6 ringbuffer示意图
普通的buffer用GstBuffer表示,而ringbuffer相当于在音频中对buffer又一次进行了封装,从而使得它又具有了一些特性,比如有状态(STOPPED,PAUSED,STARTED)等。
在音频中对render的重构主要在函数gst_base_audio_sink_render()中实现,在往设备写入之前,根据设置情况也可能需要进行同步和对输出数据的裁剪过程,流程如图7所示。
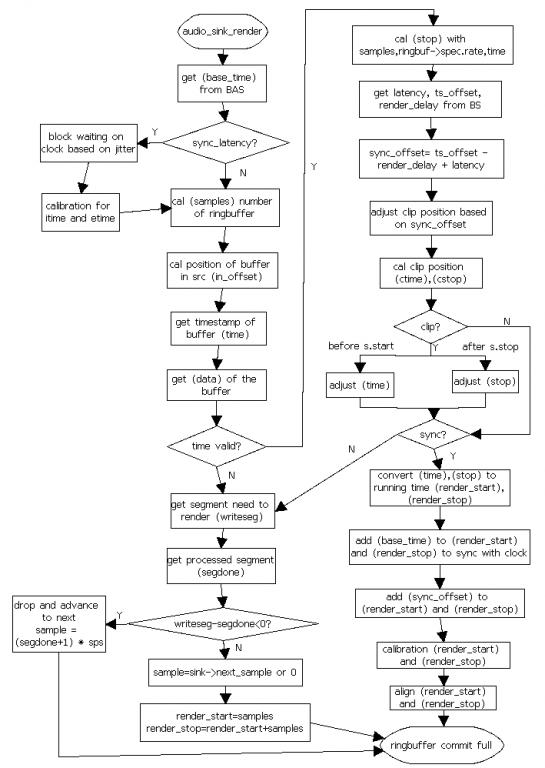
图7 audio render流程图
七、调试分析
(1)根据调试,得到结果及其分析,可以发现在正常情况下,在往设备上写是按照先audio,后video的顺序进行的,一般每次写8-9个audio的 segment,6-7个video的segment。每次写完后都会等待其他流都写完后才进行下一轮写入。
(2)举例:音频用pulsesink,视频用ximagesink为例,讲述从同步到输出的处理过程,如下过程中从上到下分别为音频和视频的处理函数/过程。
音频(pulsesink) 视频(ximagesink)
gst_base_sink_render_object gst_base_sink_render_object
gst_base_sink_do_sync gst_base_sink_do_sync
gst_base_sink_get_sync_times gst_base_sink_get_sync_times
*gst_base_audio_sink_get_times==-1 *gst_ximagesink_get_times!=-1
@gst_base_audio_sink_render gst_base_sink_adjust_time
一系列同步过程 gst_base_sink_wait_clock
gst_ring_buffer_commit_full @gst_ximagesink_show_frame
gst_ximagesink_ximage_put
从上述过程可以看到,音频的同步过程在gst_base_audio_sink_render中实现,而视频的同步则在 gst_base_sink_render_object中实现,并且在get_times方法后进行区分。打“*”的表示在音频和视频的子类中对 get_times的实现,打“@”的表示在音频和视频的子类中对render的实现。















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









