







kafka定义
Apache kafka is a distributed streaming platform,即官方定义 kafka 是一个分布式流式计算平台。而在大部分企业开发人员中,都是把 kafka 当成消息系统使用,即它是一个分布式消息队列,很少会使用 kafka 的流式计算。
消息队列的特点
模式
这个模式主要是针对消费者来讲的,生产者是无模式概念说法的,生产者生产消息都是主动的。
- 点对点
pull模式,消费者主动拉取消息,消费者根据自身性能,消费的快就多拉消息,消费的慢就少消费,同时pull模式可简化broker的设计,缺点就是实时性差,高峰期时会导致消费堆积,但这本身也是需要消息中间件的原因,削峰填谷。 - 订阅模式
push模式,中间件主动推送,非常实时,有最新的消息就传输给服务端,消息堆积在服务端,极端情况服务端的缓冲队列很容易溢出,虽然有流转机制,但流转机制需要根据主动配置,配置多少都不好控制,如果是一些生产慢的场景就不会有这个问题。
kafka选择pull模式,也只有pull模式,主要是pull模式可简化broker的设计,
持久化
kafka主要的思想是基于基本的理论:磁盘线性写入的性能远远大于任意位置写的性能。Kafka 直接将数据写到了文件系统的日志中:
- 写操作:将数据顺序追加到文件中
- 读操作:从文件中读取
这样实现的好处:
读操作不会阻塞写操作和其他操作,数据大小不对性能产生影响,硬盘空间相对于内存空间容量限制更小,线性访问磁盘,速度快,可以保存更长的时间,更稳定。每一个partition都有index文件和log文件,index文件存储元数据,log存储消息。index文件元数据指向对应log文件中message的迁移地址;例如2,128指log文件的第2条数据,偏移地址为128;而物理地址(在index文件中指定)+ 偏移地址可以定位到消息。
事务
kafka不支持事务,RocketMQ 支持。
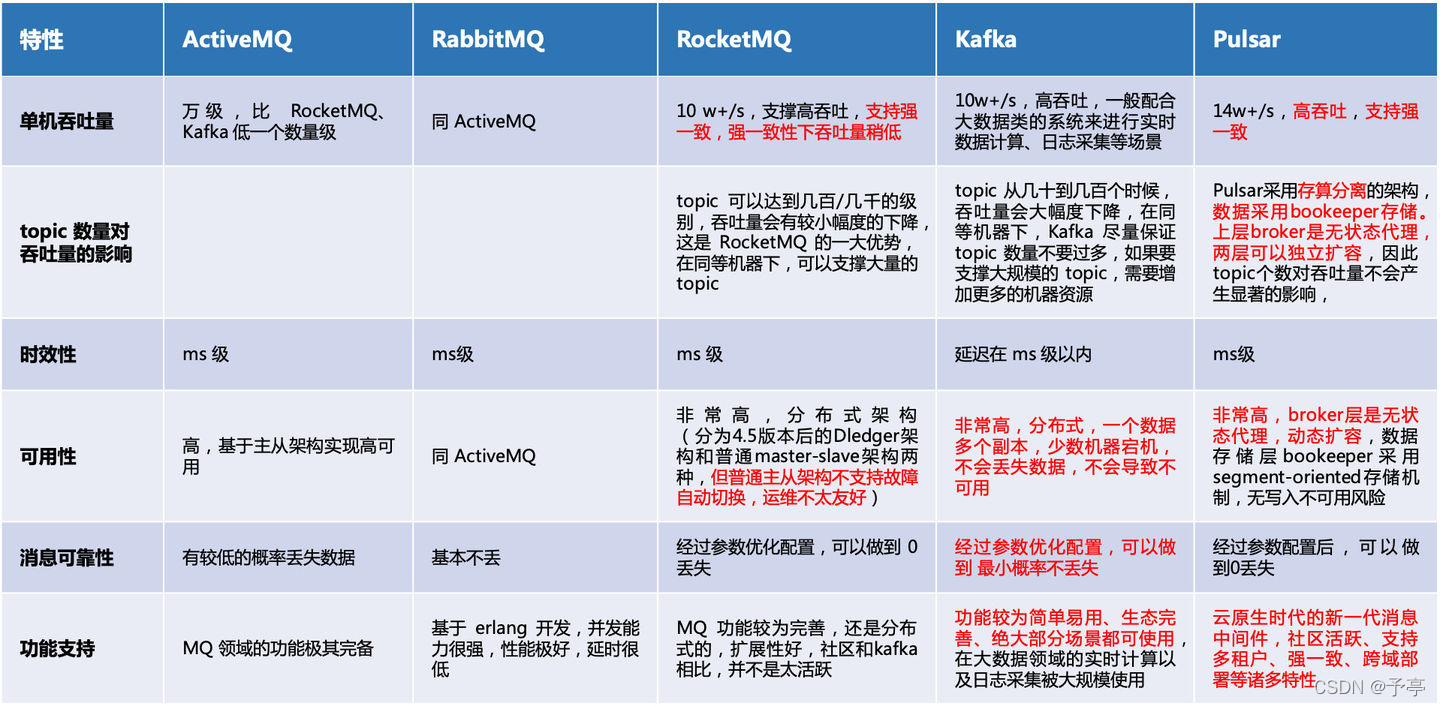
对比















 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









