








说明:
本文是Confluent Platform 3.0版本中对于Kafka Streams的翻译。
原文地址:https://docs.confluent.io/3.0.0/streams/index.html
看了很多其他人翻译的文档,还是第一次翻译,有什么翻译的不好的地方还请指出。
这是Kafka Streams介绍的第四篇,以前的介绍如下:
http://blog.csdn.net/ransom0512/article/details/51971112
http://blog.csdn.net/ransom0512/article/details/51985983
http://blog.csdn.net/ransom0512/article/details/52038548
Kafka Streams通过利用Kafka的Producer和Consumer来提供功能并提供并行处理,分布式协调,容错和操作简单等功能特点,简化应用程序的开发。在本章节中,我们将介绍Kafka Streams的工作原理。
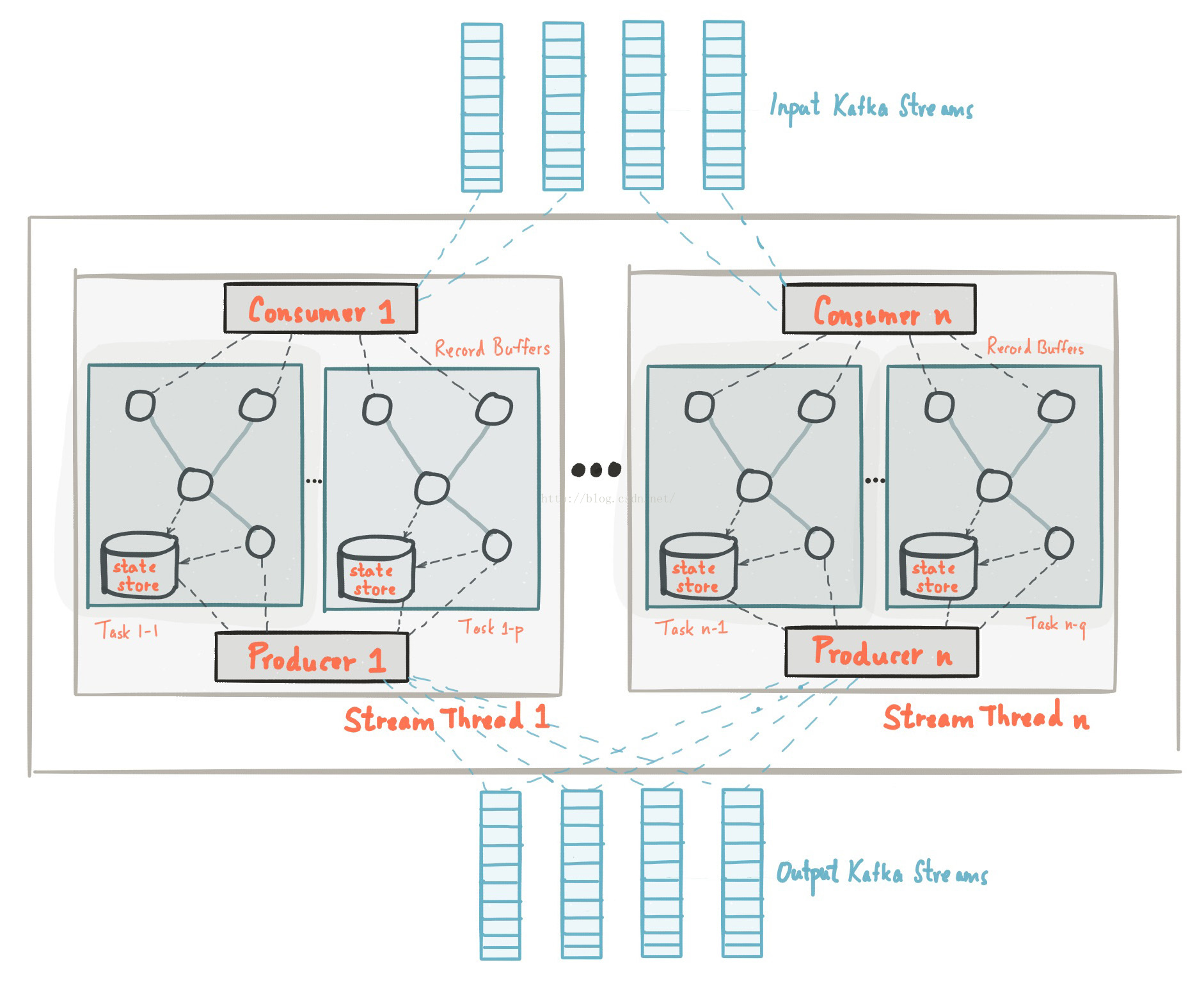
上面的图片展示了Kafka Streams应用程序的工作原理,让我们通过下面的一系列描述来逐渐深入里面的细节。
1. 拓扑算子
一个拓扑算子或者说简单拓扑定义了你的流处理应用程序的计算逻辑,即输入数据是如何转为输出数据的。
- 源算子(Sourceprocessor):源算子是一种特殊类型的,不包含任何上游算子的流处理算子。它通过消费topic中的数据,并将其转发给下游流处理算子进行处理。
- 输出算子(Sink Processor):输出算子是一种特殊类型的、不包含任何下游算子的流处理算子。它可以接受任何上游算子的数据并将数据写入kafka指定topic中。
一个流处理应用程序,可以定义一个或者多个这样的拓扑结构,但通常只会定义一个。开发者可以通过低级API或者kafka的DSL来创建基于上面格式的拓扑。
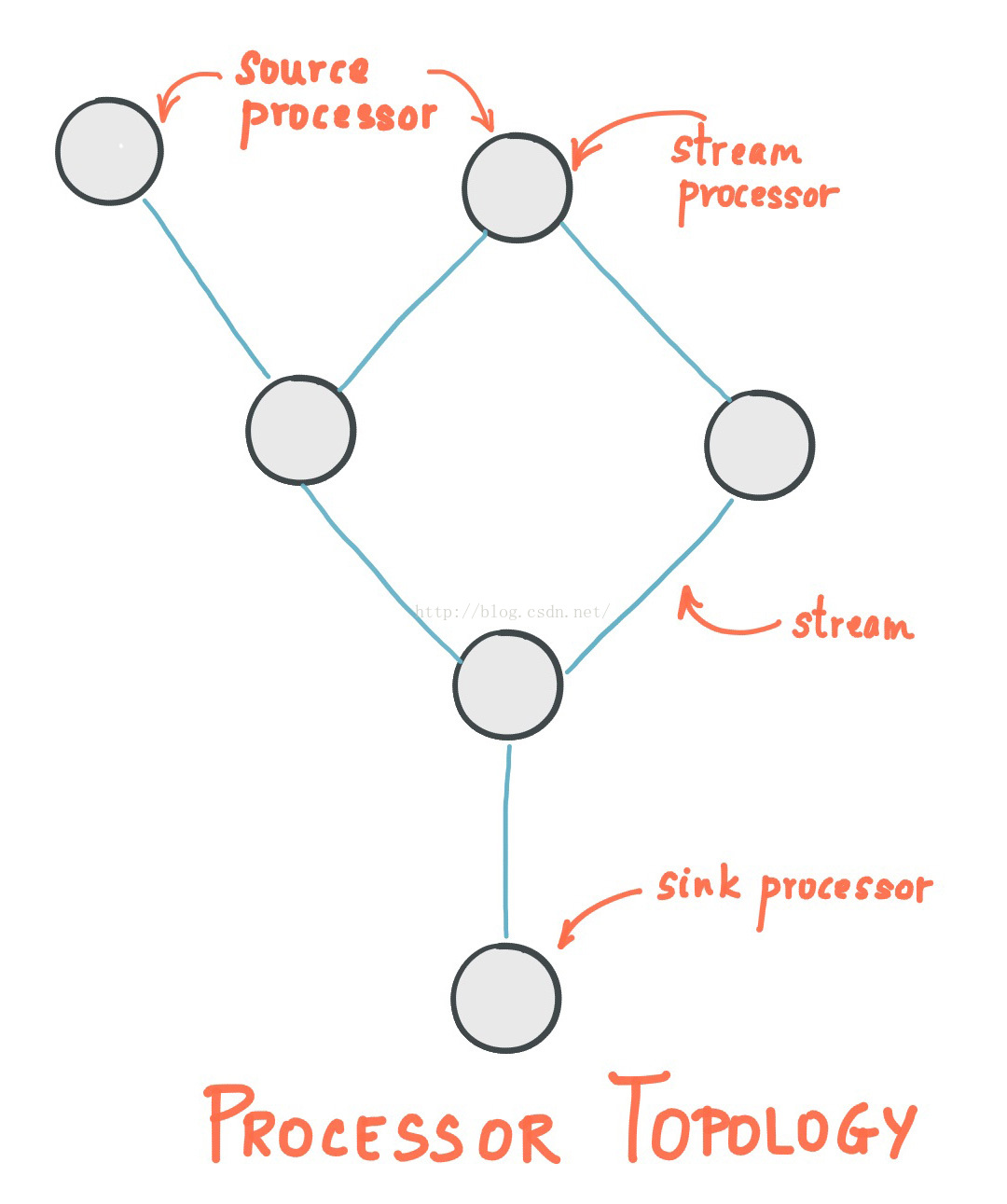
一个拓扑算子是包含了用户流处理代码的逻辑抽象。在运行时,逻辑拓扑被实例化和复制在应用程序中并行执行。
2. 并发模型
2.1. Stream分区和任务(Task)
Kafka Streams使用了分区和任务的概念作为并发模型中的逻辑单元。Kafka和Kafka Streams在并发概念中有着紧密联系。
- 每个Stream的分区是Kafka的一个分区中完整有序的数据记录。
- 一个Stream数据记录映射中的数据记录直接来自于Kafka topic。
- 数据的key值是Kafka和KafkaStreams的关键,他决定了数据是如何被路由到特定分区的。
一个应用程序的算子可以被自由扩展成多个任务。具体来说,Kafka Stremas基于应用程序输入流的分区数创建了数量固定的任务(Task),每个Task分配了输入流(Kafka topic)的一个分区列表。这种分区到任务的分配方式被固化到每个任务的执行单元中,不会发生改变。任务实例可以根据自己的拓扑算子处理分配到的分区数据, Kafka Streams还为每个分配到的分区分配了对应的缓冲区,并且基于缓冲区提供了一次处理一条消息的时间处理机制。这样就可以使得Stream的任务可以在无需人工干预的情况下独立的并行的处理。
说明:子拓扑:如果一个Kafka Streams应用程序指定了多个拓扑算子,每个任务将只会实例化拓扑算子中的一个(即一个task只可能对应一个算子,不可能对应多个。)。另外,一个单一的拓扑算子可以被分解成独立的子拓扑,只要子拓扑没有和拓扑中的其他算子相连。这进一步拓展了task之间的工作负载。
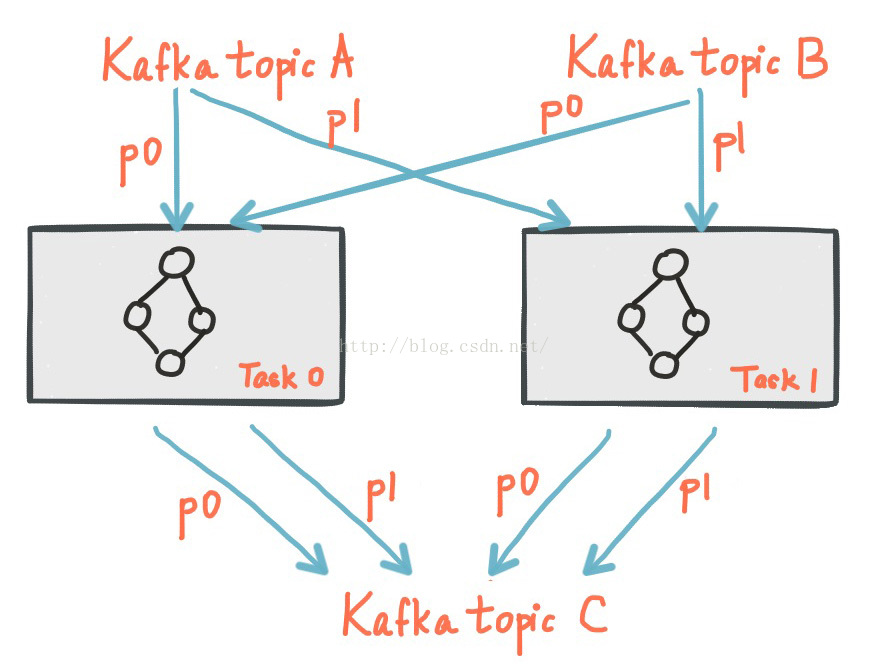
一个很重要的一点是,KafkaStreams不是一个资源管理器,而是一个库,它可以运行在任何流处理应用程序中;应用程序的多个实例可以运行在相同的机器或者被资源管理器分发到不同的节点上去运行;分配给该Task的分区永远不会改变;如果一个应用程序实例故障了,任务会被重分配并在其他实例上重新启动,并从相同的分区中继续消费数据。
2.2. 线程模型
Kafka Streams允许用户来配置应用程序中并行处理的线程数。每个线程可以与他们的拓扑算子独立的执行一个或者多个任务。
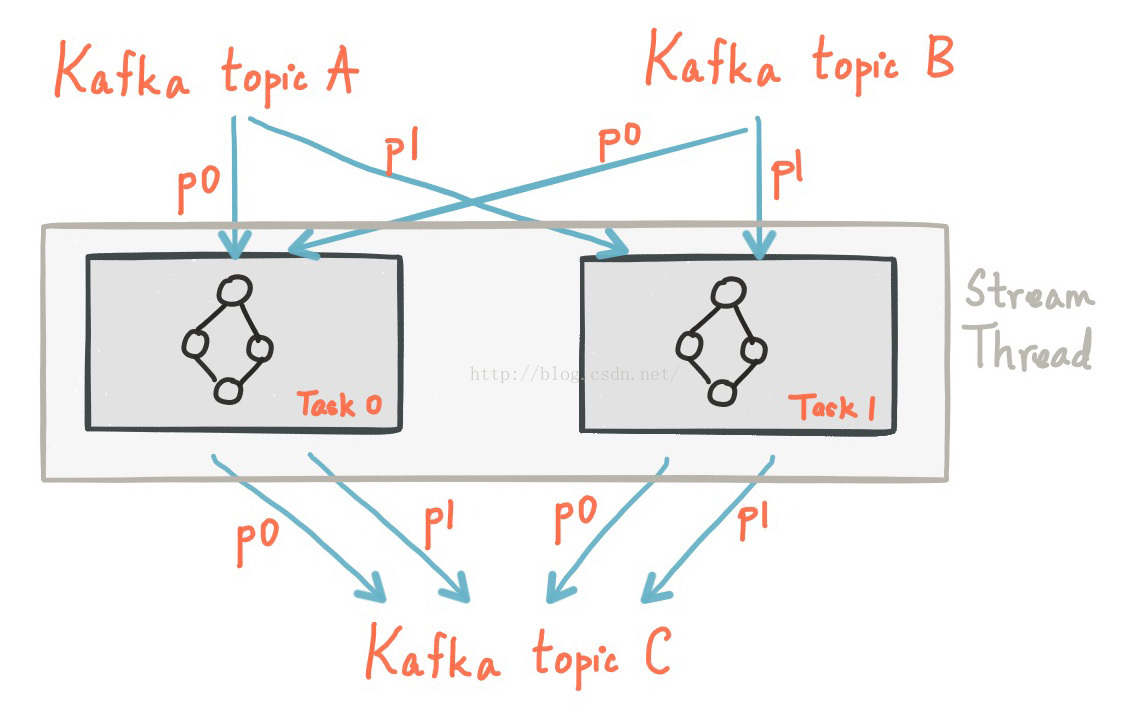
如果要启动更多的流处理线程或者应用程序实例,只需要复制拓扑和Kafka分区处理的子拓扑,就能够有效并行处理多个实例。值得注意的是,多个线程之间不会共享状态,所以也不需要线程之间的协作处理。这就使得运行一个多并发的拓扑实例非常简单。 Kafka Streams在Kafka在topic的分区分配上使用了Kafka服务端的协调能力,分区分配是十分透明的。
综述,拓展Kafka Streams的流处理应用程序很简单,你只需要启动应用程序的其它实例,Kafka Streams会关注task数量的变化并自动给task分配partition。你可以根据Kakfa输入topic的分区数量启动对应的处理线程,每个线程至少对应一个分区。
2.3. 示例
为了更好理解kafka streams的并发模型,我们来看下面一个例子:
假设有一个Kafka Streams应用程序,从两个topic中读取数据,Topic A和Topic B,每个topic都有三个分区。如果我们现在在单节点上启动了应用程序并且将线程数量设置为2,我们最终会出现两个Kakfa Streams线程instance1-thread1和instance1-thread2。由于输入topic A和B的最大分区数都是3,max(3,3) =3, 所以Kafka Streams会默认将这个拓扑拆分成三个Task,然后将这六个分区均匀地分布在三个Task中。在这种情况下,每个task会从每个topic的一个分区中消费数据,每个task会同时从两个分区中获取数据。最终,这三个线程将会被尽可能的均匀分布在两个线程中。当前示例程序中的两个线程,线程1包含两个Task,从4个partition消费数据,第二个线程包含一个task,并且从2个分区中消费数据。
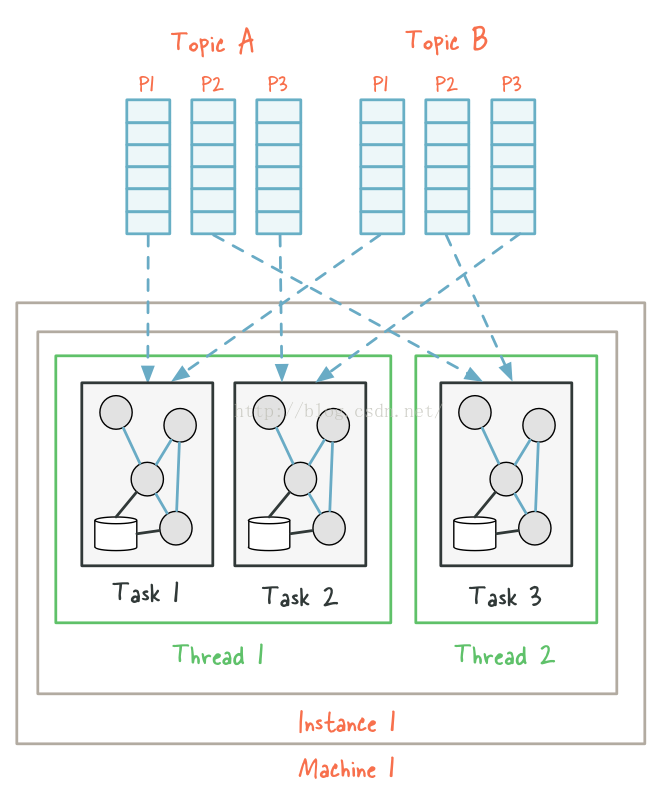
现在如果我们因为数据量增长的原因要拓展这个应用程序,我们决定在另外的机器中启动一个独立的进程并设置线程数为1来运行相同应用程序。新线程instance2-thread1会被创建,然后输入分区将会被重分配。
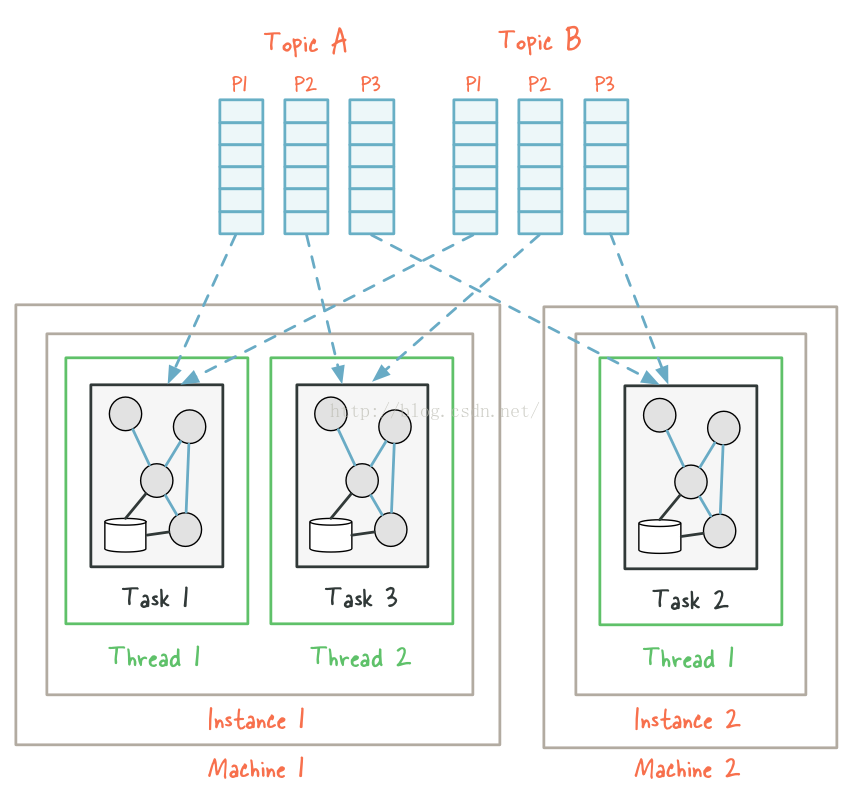
当重新分配任务的时候,相同的分区和它们所在的task以及本地保存的状态,都会被迁移到新的线程,最终,Kafka Streams已经有效的平衡了应用程序的负载。
如果我们要为该应用程序添加更多实例,我们也可以按照上面的方式拓展知道任务实例的数量和输入分区数量相等。在相等之后,如果我们还要启动更多的应用程序,我们就应该增加topic A和Topic B的分区数,这样正在等待分配的实例数将会分配到新的分区上面。不过这种场景非常少。
3. 状态
Kafka 提供的所谓的状态存储,可以在流处理应用程序中保存和查询数据,这在有状态的流处理应用程序中是一个很重要的能力。每个Kafka Streams中的Task都内置了一个或者多个状态存储空间,可以通过API来进行保存和查询。这些状态存储空间尅是RocksDB数据库,一个基于内存的HashMap或者其他更方便的数据结构。Kafka Streams基于本地状态提供了容错和自动恢复的能力。
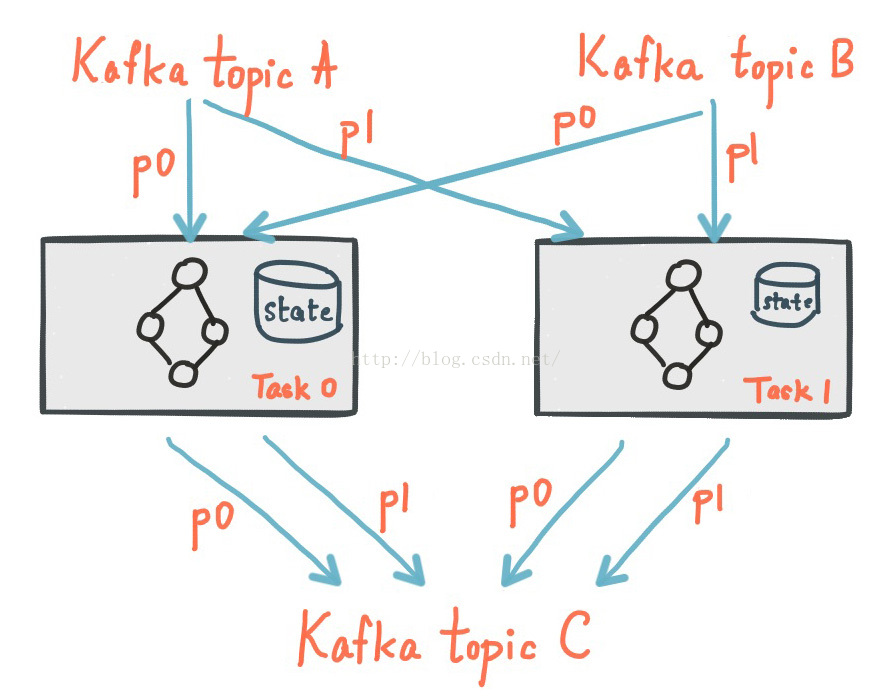
4. 容错
Kafka Streams的容错机制是基于Kafka功能实现的。Kafka的分区是高可用和可复制的,所以当流数据被保存在Kafka中的时候,它是高可用的,即使应用程序失败了也没关系。 Kafka Streams中的Task利用Kafka Consumer的失败处理功能来提供容错能力。如果一个机器上的task失败了,Kafka streams会自动在其它应用程序实例中重启该task。
另外,Kafka Streams还可以保证本地存储状态数据的可靠性。它使用了类似Apache samza的方式,为每个状态在Kafka topic中保存了一个可复制的changelog,用来跟踪状态更新。Changelog根据本地存储实例进行分区划分,并且每个task有自己专用的topic分区。Changelog的topic中应该开启Kafka的日志压缩功能,这样旧数据才能够被安全清除,防止changlog无限制增长。如果一个机器上的task失败了,并且在其他机器上重新启动了,Kafka Streams会重放该topic上的changelog来task的最新状态。这些失败处理流程对用户来说是完全透明的。
提示:优化点:为了尽可能的减少状态恢复和task初始化的时间,用户可以在自己的应用程序中配置本地状态的父辈,当一个task迁移的时候,Kafka Streams会尝试将该任务分配到副本所在机器,这样就可以减少初始化的时间消耗。可以参照开发文档中num.standby.replicas配置属性。
5. 处理可靠性
Kafka Streams在消息处理上支持at-least-once至少一次的消息处理机制。这就意味着,如果流处理应用程序故障,不会有数据丢失和没有被处理,但是部分数据可能会被处理多次。
在一般场景下,at-least-once还是可以接受的,但是特殊场景下,可能就需要exactly-once有且仅有一次的语义支持。
在许多流处理应用程序中,at-least-once是完全可以接受的,通常,只要消息处理是幂等的,那么数据被处理多次就完全是安全可靠的。除此之外,还有一些用例即使不是幂等的,它也允许数据被处理多次。例如:加入你是通过IP地址的点击量生成的黑名单,以减轻DDOS攻击对基础设施带来的影响,在这种场景下,一些计算的超量是允许的,因为参与攻击的恶意IP的点击率会远远大于正常访问的IP地址。
在一般情况下,对于非幂等操作,比如计数,在at-least-once的羽翼下可能会导致计算结果错误。如果Kafka Streams的应用程序失败重启,它可能会重复计算失败之前已经处理的一些数据。我们正计划解决该限制,并支持exactly-once的处理语义。
6. 基于时间戳的流控
Kafka Streams通过同步调节所有输入流的消息记录上的时间戳来进行流控。在默认情况下,Kafka Streams将提供event-time的处理语义。这在应用程序处理大量多个流的历史数据的情况下是十分重要的。例如:例如,在业务逻辑改变的情况下,用户可能希望重新处理历史数据,比如bug修复。从Kafka中大量获取数据是十分容易的,但是如果没有适当的流控,topic分区中的数据处理可能会不同步并产生不正确的结果。
正如在概念这一章节中提到的,KafkaStreams中的每个消息记录都和一个时间戳关联。根据在数据缓存中的数据的时间戳,streams的task决定下一个输入流分配的分区数据什么时候被处理。但是,Kafka Streams在处理的时候单个流内的数据不会重新排序,这将破坏Kafka的传送语义并使得失败恢复变得十分困难。这种流控总是会尽量做到最好,单不是总是能够精确执行的。实际上,为了保证严格的执行顺序,用户必须等待,直到系统已经收到所有的数据流(这在实际使用中可能是非常不可行的)或者注入额外时间戳边界或者使用启发式的估算,如MillWheel的watermarks的附加信息。
7. 背压
Kafka Streams不使用背压机制,因为它不需要。从Kafka中消费的消息都会在每个拓扑或者子拓扑中被完全处理并回写Kafka之后才会处理下一个消息。这样,没有消息被缓存在两个处理算子之间。此外,Kafka Streams利用Kafka的Consumer客户端,这基于pull的消息获取机制,下游处理算子可以控制输入数据的读取速度。
这同样适用于包含多个独立子拓扑的拓扑结构,这些子拓扑将彼此独立的进行消息处理。例如,下面的代码定义了两个独立的子拓扑:
stream1.to("my-topic");
stream2 = builder.stream("my-topic");子拓扑结构之间的任何数据交换都是通过Kafka进行的,即子拓扑之间不会有直接的数据交换。处于这个原因,没有必要再这种情况下使用背压机制。















 2323
2323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









