






说明:本文翻译Confluent官网,原文地址:
https://www.confluent.io/blog/transactions-apache-kafka/
在之前的博客文章(见尾部链接)中,我们介绍了ApacheKafka的exactly once语义,介绍了各种消息传输语义,producer的幂等特性,事和Kafka Stream的exactly once处理语义。现在我们将从上篇文章结尾的地方开始,深入探讨Apache Kafka的事务。本文档的目标是使读者熟悉Apache Kafka中有效使用事务API所需要的主要概念。
我们将讨论事务API设计的主要用例,Kafka的事务语义,JavaClient事务API细节,实现方面一些有趣的地方,最后,我们会讨论API使用方面的一些重要因素。
这篇文章并不打算成为事务处理细节方面的教程,我们也不会深入探讨设计方面的细节;相反,我们给希望更加深入的读者JavaDoc或者设计文档的链接。
我们希望读者在阅读这篇文章之前,能够熟悉Kafka的基本概念,比如Topics,partitions, 日志偏移量和borker的觉得,以及包含kafka客户端的应用程序例子,熟悉Kafka的Java客户端也会所有帮助。
1. 为什么要支持事务
我们在Kafka中设计事务的目的主要是为了满足“读取-处理-写入”这种模式的应用程序。这种模式下数据的读写是异步的,比如Kafka的Topics。这种应用程序更广泛的被称之为流处理应用程序。
第一代流处理应用程序可以容忍不准确的数据处理,比如,查看网页点击数量的应用程序,能够允许计数器存在一些错误(多算或者漏算)。
然而,随着这些应用的普及,对于流处理计算语义有更多要求的需求也在增多。比如,一些金融机构部使用流处理应用来处理用户账户的借贷方,这种情况下,处理中的错误是不能容忍的,我们需要每一条消息都被处理一次,没有任何例外。
更正式的说,如果流处理应用程序消费消息A并产生消息B,使得B=F(A),则exactlyonce则意味着仅当B成功时才认为A被消耗,反之亦然。
当在Kafka的producer和consumer的配置属性中使用at-least-once传入语义的时候,一个流处理应用程序能够处理下面的场景:
1. 由于内部重试,producer.send()方法使得消息B可能被重复写入。这将由Procedure的幂等特性解决,不是这篇文章其余部分的重点。
2. 我们可能会对消息A进行重新处理,这会导致重复的消息B被写入,违背了exactly once的处理语义,如果流处理应用程序在B写入成功但是在A被成功标记之前崩溃,则可能会被重新处理,因此,当它恢复时,他将在此消费A并再次写入B,导致重复。
3. 最后,在分布式环境中,应用程序会崩溃或者更糟,一旦和系统其它部分连接丢失,通常情况下,新的实例会自动启动以取代丢失实例。通过这个过程,可能会有多个实例处理相同的输入topic并写入相同的输出topic,从而导致重复的输出并违背exactly once的处理语义,这个我们称之为“僵尸实例”的问题。
我们在Kafka中设计了事务API来解决第二个和第三个问题,事务能够保证这些“读取-处理-写入”操作成为一个与那字操作并且在一个周期中保证精确处理,满足exactly once处理语义。
2. 事务语义
2.1. 多分区原子写入
事务能够保证Kafka topic下每个分区的原子写入。事务中所有的消息都将被成功写入或者丢弃。例如,处理过程中发生了异常并导致事务终止,这种情况下,事务中的消息都不会被Consumer读取。现在我们来看下Kafka是如何实现原子的“读取-处理-写入”过程的。
首先,我们来考虑一下原子“读取-处理-写入”周期是什么意思。简而言之,这意味着如果某个应用程序在某个topic tp0的偏移量X处读取到了消息A,并且在对消息A进行了一些处理(如B = F(A))之后将消息B写入topic tp1,则只有当消息A和B被认为被成功地消费并一起发布,或者完全不发布时,整个读取过程写入操作是原子的。
现在,只有当消息A的偏移量X被标记为消耗时,消息A才被认为是从topic tp0消耗的,消费到的数据偏移量(record offset)将被标记为提交偏移量(Committing offset)。在Kafka中,我们通过写入一个名为offsets topic的内部Kafka topic来记录offset commit。消息仅在其offset被提交给offsets topic时才被认为成功消费。
由于offset commit只是对Kafkatopic的另一次写入,并且由于消息仅在提交偏移量时被视为成功消费,所以跨多个主题和分区的原子写入也启用原子“读取-处理-写入”循环:提交偏移量X到offset topic和消息B到tp1的写入将是单个事务的一部分,所以整个步骤都是原子的。
2.2. 粉碎“僵尸实例”
我们通过为每个事务Producer分配一个称为transactional.id的唯一标识符来解决僵尸实例的问题。在进程重新启动时能够识别相同的Producer实例。
API要求事务性Producer的第一个操作应该是在Kafka集群中显示注册transactional.id。 当注册的时候,Kafka broker用给定的transactional.id检查打开的事务并且完成处理。 Kafka也增加了一个与transactional.id相关的epoch。Epoch存储每个transactional.id内部元数据。
一旦这个epoch被触发,任何具有相同的transactional.id和更旧的epoch的Producer被视为僵尸,并被围起来, Kafka会拒绝来自这些Procedure的后续事务性写入。
2.3. 读事务消息
现在,让我们把注意力转向数据读取中的事务一致性。
Kafka Consumer只有在事务实际提交时才会将事务消息传递给应用程序。也就是说,Consumer不会提交作为整个事务一部分的消息,也不会提交属于中止事务的消息。
值得注意的是,上述保证不足以保证整个消息读取的原子性,当使用Kafka consumer来消费来自topic的消息时,应用程序将不知道这些消息是否被写为事务的一部分,因此他们不知道事务何时开始或结束;此外,给定的Consumer不能保证订阅属于事务一部分的所有Partition,并且无法发现这一点,最终难以保证作为事务中的所有消息被单个Consumer处理。
简而言之:Kafka保证Consumer最终只能提供非事务性消息或提交事务性消息。它将保留来自未完成事务的消息,并过滤掉已中止事务的消息。
3. 事务处理Java API
事务功能主要是一个服务器端和协议级功能,任何支持它的客户端库都可以使用它。 一个Java编写的使用Kafka事务处理API的“读取-处理-写入”应用程序示例:
KafkaProducer producer = createKafkaProducer(
“bootstrap.servers”, “localhost:9092”,
“transactional.id”, “my-transactional-id”);
producer.initTransactions();
KafkaConsumer consumer = createKafkaConsumer(
“bootstrap.servers”, “localhost:9092”,
“group.id”, “my-group-id”,
"isolation.level", "read_committed");
consumer.subscribe(singleton(“inputTopic”));
while (true) {
ConsumerRecords records = consumer.poll(Long.MAX_VALUE);
producer.beginTransaction();
for (ConsumerRecord record : records)
producer.send(producerRecord(“outputTopic”, record));
producer.sendOffsetsToTransaction(currentOffsets(consumer), group);
producer.commitTransaction();
}
第7-10行指定KafkaConsumer只应读取非事务性消息,或从其输入主题中提交事务性消息。流处理应用程序通常在多个读取处理写入阶段处理其数据,每个阶段使用前一阶段的输出作为其输入。通过指定read_committed模式,我们可以在所有阶段完成一次处理。
第1-5行通过指定transactional.id配置并将其注册到initTransactionsAPI来设置Procedure。在producer.initTransactions()返回之后,由具有相同的transactional.id的Producer的另一个实例启动的任何事务将被关闭和隔离。
第14-21行显示了“读取-处理-写入”循环的核心:读取一部分记录,启动事务,处理读取的记录,将处理的结果写入输出topic,将消耗的偏移量发送到offset topic,最后提交事务。有了上面提到的保证,我们就知道offset和输出记录将作为一个原子单位。
4. 事务工作原理
在本节中,我们将简要介绍上面介绍的事务API引入的新组件和新数据流。更详细的信息,你可以阅读原始设计文档,或观看介绍Kafka MeetUp的Sliders。
下面示例的目标是在调试使用了事务的应用程序时,如何对事务进行优化以获得更好的性能。
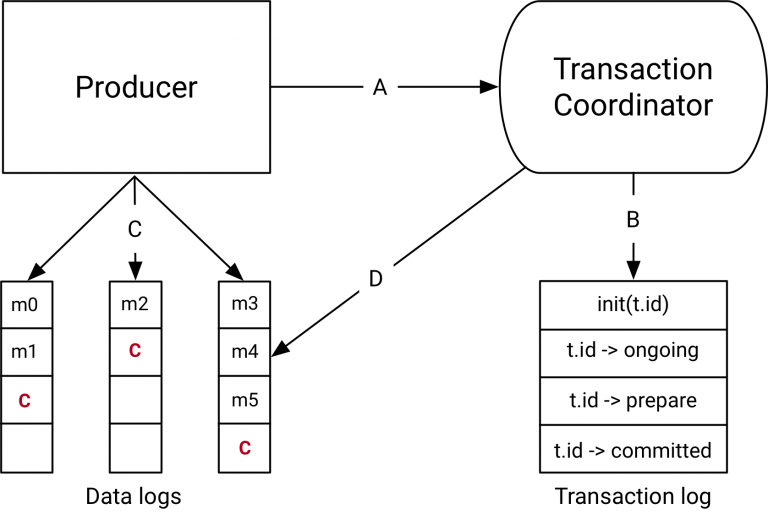
5. 事务协调器和事务日志
在Kafka 0.11.0中与事务API一起引入的组件是上图右侧的事务Coordinator和事务日志。
事务Coordinator是每个KafkaBroker内部运行的一个模块。事务日志是一个内部的Kafka Topic。每个Coordinator拥有事务日志所在分区的子集,即, 这些borker中的分区都是Leader。
每个transactional.id都通过一个简单的哈希函数映射到事务日志的特定分区。这意味着只有一个Broker拥有给定的transactional.id。
通过这种方式,我们利用Kafka可靠的复制协议和Leader选举流程来确保事务协调器始终可用,并且所有事务状态都能够持久存储。
值得注意的是,事务日志只保存事务的最新状态而不是事务中的实际消息。消息只存储在实际的Topic的分区中。事务可以处于诸如“Ongoing”,“prepare commit”和“Completed”之类的各种状态中。正是这种状态和关联的元数据存储在事务日志中。
6. 数据流
数据流在抽象层面上有四种不同的类型。
A. producer和事务coordinator的交互
执行事务时,Producer向事务协调员发出如下请求:
1. initTransactions API向coordinator注册一个transactional.id。 此时,coordinator使用该transactional.id关闭所有待处理的事务,并且会避免遇到僵尸实例。 每个Producer会话只发生一次。
2. 当Producer在事务中第一次将数据发送到分区时,首先向coordinator注册分区。
3. 当应用程序调用commitTransaction或abortTransaction时,会向coordinator发送一个请求以开始两阶段提交协议。
B. Coordinator和事务日志交互
随着事务的进行,Producer发送上面的请求来更新Coordinator上事务的状态。事务Coordinator会在内存中保存每个事务的状态,并且把这个状态写到事务日志中(这是以三种方式复制的,因此是持久保存的)。
事务Coordinator是读写事务日志的唯一组件。如果一个给定的Borker故障了,一个新的Coordinator会被选为新的事务日志的Leader,这个事务日志分割了这个失效的代理,它从传入的分区中读取消息并在内存中重建状态。
C. Producer将数据写入目标Topic所在分区
在Coordinator的事务中注册新的分区后,Producer将数据正常地发送到真实数据所在分区。这与producer.send流程完全相同,但有一些额外的验证,以确保Producer不被隔离。
D. Topic分区和Coordinator的交互
在Producer发起提交(或中止)之后,协调器开始两阶段提交协议。
在第一阶段,Coordinator将其内部状态更新为“prepare_commit”并在事务日志中更新此状态。一旦完成了这个事务,无论发生什么事,都能保证事务完成。
Coordinator然后开始阶段2,在那里它将事务提交标记写入作为事务一部分的Topic分区。
这些事务标记不会暴露给应用程序,但是在read_committed模式下被Consumer使用来过滤掉被中止事务的消息,并且不返回属于开放事务的消息(即那些在日志中但没有事务标记与他们相关联)。
一旦标记被写入,事务协调器将事务标记为“完成”,并且Producer可以开始下一个事务。
7. 事务实践
现在我们已经理解了事务的语义以及它们是如何工作的,我们将注意力转向利用事务编写实际应用方面。
7.1. 如何选择事务Id
transactional.id在屏蔽僵尸中扮演着重要的角色。但是在一个保持一个在Producer会话中保持一致的标识符并且正确地屏蔽掉僵尸实例是有点棘手的。
正确隔离僵尸实例的关键在于确保读取进程写入周期中的输入Topic和分区对于给定的transactional.id总是相同的。如果不是这样,那么有可能丢失一部分消息。
例如,在分布式流处理应用程序中,假设Topic分区tp0最初由transactional.idT0处理。如果在某个时间点之后,它可以通过transactional.id T1映射到另一个Producer,那么T0和T1之间就不会有栅栏了。所以tp0的消息可能被重新处理,违反了一次处理保证。
实际上,可能需要将输入分区和transactional.id之间的映射存储在外部存储中,或者对其进行静态编码。Kafka Streams选择后一种方法来解决这个问题。
7.2. 事务性能以及如何优化?
Ø Producer打开事务之后的性能
让我们把注意力转向事务如何执行。
首先,事务只造成中等的写入放大。额外的写入在于:
对于每个事务,我们都有额外的RPC向Coordinator注册分区。这些是批处理的,所以我们比事务中的partition有更少的RPC。
在完成事务时,必须将一个事务标记写入参与事务的每个分区。同样,事务Coordinator在单个RPC中批量绑定到同一个Borker的所有标记,所以我们在那里保存RPC开销。但是在事务中对每个分区进行额外的写操作是无法避免的。
最后,我们将状态更改写入事务日志。这包括写入添加到事务的每批分区,“prepare_commit”状态和“complete_commit”状态。
我们可以看到,开销与作为事务一部分写入的消息数量无关。所以拥有更高吞吐量的关键是每个事务包含更多的消息。
实际上,对于Producer以最大吞吐量生产1KB记录,每100ms提交消息导致吞吐量仅降低3%。较小的消息或较短的事务提交间隔会导致更严重的降级。
增加事务时间的主要折衷是增加了端到端延迟。回想一下,Consum阅读事务消息不会传递属于公开传输的消息。因此,提交之间的时间间隔越长,消耗的应用程序就越需要等待,从而增加了端到端的延迟。
Ø Consumer打开之后的性能
Consumer在开启事务的场景比Producer简单得多,它需要做的是:
1. 过滤掉属于中止事务的消息。
2. 不返回属于公开事务一部分的事务消息。
因此,当以read_committed模式读取事务消息时,事务Consumer的吞吐量没有降低。这样做的主要原因是我们在读取事务消息时保持零拷贝读取。
此外,Consumer不需要任何缓冲等待事务完成。相反,Broker不允许提前抵消包括公开事务。
因此,Consumer是非常轻巧和高效的。感兴趣的读者可以在本文档(链接2)中了解Consumer设计的细节。
8. 进一步阅读
我们刚刚讲述了Apache Kafka中事务的表面。 幸运的是,几乎所有的设计细节都保存在在线文档中。 相关文件是:
最初的Kafka KIP(链接3):它提供了关于数据流的设计细节,并且详细介绍了公共接口,特别是与事务相关的配置选项。
原始设计文档(链接4):不是为了内核,这是源代码之外的权威地方 - 了解每个事务性RPC如何处理,如何维护事务日志,如何清除事务性数据等等。
KafkaProducerjavadocs(链接5):这是学习如何使用新API的好地方。页面开始处的示例以及send方法的文档是很好的起点。
9. 结论
在这篇文章中,我们了解了ApacheKafka中关于事务API的关键设计目标,我们理解了事务API的语义,并对API的实际工作有了更高层次的理解。
如果我们考虑“读取-处理-写入”周期,这篇文章主要介绍了读写路径,处理本身就是一个黑盒子。事实是,在处理阶段中可以做很多事情,使得一次处理不可能保证单独使用事务API。例如,如果处理对其他存储系统有副作用,则这里覆盖的API不足以保证exactly once。
Kafka Streams框架使用事务API向上移动整个价值链,并为各种各样的流处理应用提供exactly once,甚至能够在处理期间更新某些附加状态并进行存储。
后续的博客文章将介绍KafkaStreams如何提供一次处理语义,以及如何编写利用它的应用程序。
最后,对于那些渴望了解上述API实现细节的人,我们将会有另一篇博客文章,其中涵盖了这里描述的一些更有趣的解决方案。
10. 链接
1. https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
2. https://docs.google.com/document/d/1Rlqizmk7QCDe8qAnVW5e5X8rGvn6m2DCR3JR2yqwVjc/edit?usp=sharing
4. https://docs.google.com/document/d/11Jqy_GjUGtdXJK94XGsEIK7CP1SnQGdp2eF0wSw9ra8/edit?usp=sharing















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









