








数据挖掘经常遇到大数据的情况,其中的一个表现形式就是数据的维度非常多,为了对维度进行压缩,可以采用一种名叫主成分分析的技术(PCA),下面的链接把PCA的原理解释地非常好:
http://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html
在这里我补充几点:
投影:某一点在某个向量上的投影等于 这点的坐标 点乘 向量的单位向量。
方阵的特征值和特征向量:http://baike.baidu.com/link?url=kGEI3eUtEDlY2QxKhKu5NW_PuwJV26-b_GdXrWHxFQFc-usMO8Bw04TEWgVVd-Ne
协方差:http://zh.wikipedia.org/zh-cn/%E5%8D%8F%E6%96%B9%E5%B7%AE
在第一个链接中,最大方差理论的证明过程中:X(i) 可以看作是一个一列n行的矩阵,而被投影的向量 u 可以看作一个n列一行的矩阵,这两个矩阵的乘积是一个一行一列的矩阵,一行一列的矩阵的转置矩阵等于其本身,然后利用了矩阵转置的特性:
(X^T u)^T= X^T u
这里的 ^T 表示 转置,X和u分别表示数据向量和投影向量,所以才有了这一步推导:
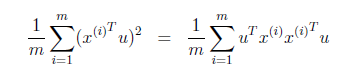
下面我们就试着用 python 上著名的科学计算库 numpy 来对一个数据矩阵进行主成分分析:
from numpy import *
def pca(dataMat, topNfeat=5):
meanVals = mean(dataMat, axis=0)
meanRemoved = dataMat - meanVals #减去均值
stded = meanRemoved / std(dataMat) #用标准差归一化
covMat = cov(stded, rowvar=0) #求协方差方阵
eigVals, eigVects = linalg.eig(mat(covMat)) #求特征值和特征向量
eigValInd = argsort(eigVals) #对特征值进行排序
eigValInd = eigValInd[:-(topNfeat + 1):-1]
redEigVects = eigVects[:, eigValInd] # 除去不需要的特征向量
lowDDataMat = stded * redEigVects #求新的数据矩阵
reconMat = (lowDDataMat * redEigVects.T) * std(dataMat) + meanVals
return lowDDataMat, reconMat在 weka 的非监督属性过滤器中也能找到 PrincipalComponents 过滤器,maxiumAttributes 表示要提取多少维度作为主成分,varianceCovered表示在用最大方差理论时保留一定百分比的主元(特征值)用于计算方差并排序提取不多于maxiumAttributes指定的主元作新的维度 。
















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











