







创作内容丰富的干货文章很费心力,感谢点过此文章的读者,点一个关注鼓励一下作者,激励他分享更多的精彩好文,谢谢大家!
在Netty中存储数据和发送数据作为临时存储抽象的是ByteBuf,而在Java的NIO层面使用的是ByteBuffer。
ByteBuffer是什么
如果不使用Netty进行发送或接收数据的操作,就需要使用Java抽象的ByteBuffer这个类。用户把数据通过ByteBuffer存储到内存中,之后再由操作系统进行之后的操作。这些数据存放到内存中,操作系统为它们申请了一块内存空间,这块内存空间就用字节数组包装了一下。内存中会创建一个ByteBuffer对象,ByteBuffer对象内部持有了字节数组的引用。用户只要获得ByteBuffer这个对象,就可以获得内部持有的字节数组的引用,之后就可以把数据以字节的方式存储到这个字节数组中,也就存放到申请的内存里了。看一下ByteBuffer的代码段更加的直观。
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer>
{
// 这个就是内部持有的字节数组,在构造方法中被赋值。
final byte[] hb;
}这个设计有一个弊端。创建的ByteBuffer对象是在堆内存中的,是在用户态中操作的,真正的发送或保存数据是操作系统在内核态中进行操作的。所以要想让操作系统正常进行操作,还需要把数据复制到堆外内存,在高并发网络I/O操作中,这无疑是很消耗性能的。更好的方式是在堆外申请一块内存给这些数据使用,用户的程序也能操作这些内存。实现的方式是让堆内存中创建的对象持有堆外内存的地址,这样用户程序可以直接向堆外内存写入数据,内核态也可以直接处理这些数据了。JDK已经帮我们实现了,ByteBuffer有两个子类,分别是DirectByteBuffer和HeapByteBuffer。
ByteBuffer的结构如下图所示:
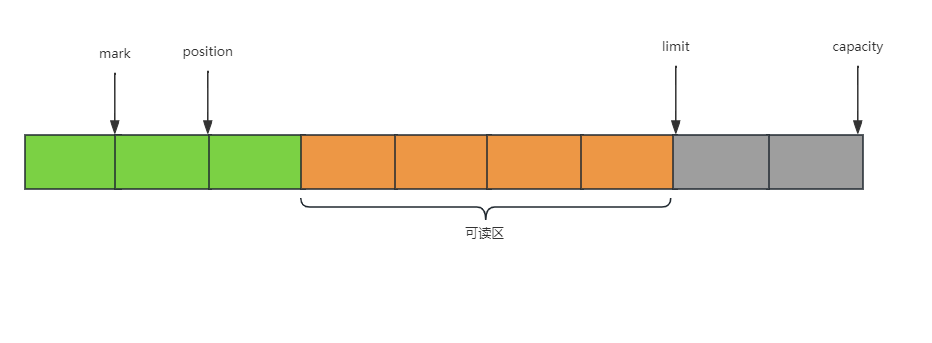
ByteBuffer中有四个属性,下面来介绍一下。
-
mark:为某个读取过的关键位置做标记,方便回退到该位置。
-
position:当前可读取或可写入的位置。
-
limit:ByteBuffer中有效的数据长度大小。
-
capacity:初始化时的空间容量。
以上四个属性的大小关系是,mark<=position<=limit<=capacity。
ByteBuffer的缺陷
-
ByteBuffer分配的长度是固定的,无法动态扩容,很难控制需要分配多大的容量。如果分配太大容量,容易造成内存浪费。如果分配太小,存放太大的数据会抛出BufferOverflowException异常。在使用ByteBuffer进行开发时,需要每次判断数据需要的容量是否超过了上限,如果超过了,就需要重新申请新的容量空间,整个过程对开发者而言相对繁琐,不友好。
-
ByteBuffer只能通过position获取当前可读取或可写入的位置,因为读写公用position指针,所以需要频繁调用flip、rewind方法切换读写状态,开发者必须很小心处理ByteBuffer的数据读写,稍不留意就会出错。
ByteBuffer继承自Buffer,我们先来看看Buffer这个类的关键代码。
public abstract class Buffer { private int mark = -1; // 读写共用同一个指针 private int position = 0; private int limit; private int capacity; // 如果使用的是堆外内存,那么堆外内存分配的内存地址就会赋值给这个成员变量 long address; }接下来看看ByteBuffer类的关键代码。
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer> { // 堆内存保存消息的字节数组 final byte[] hb; // 内存偏移量 final int offset; // 是否为只读 boolean isReadOnly; ByteBuffer(int mark, int pos, int lim, int cap, byte[] hb, int offset) { super(mark, pos, lim, cap); this.hb = hb; this.offset = offset; } // 该方法创建的是一个直接缓冲区对象。 public static ByteBuffer allocateDirect(int capacity) { return new DirectByteBuffer(capacity); } // 创建堆缓冲区对象。 public static ByteBuffer allocate(int capacity) { if (capacity < 0) throw new IllegalArgumentException(); return new HeapByteBuffer(capacity, capacity); } // 将一个字节数组包装到ByteBuffer中,创建的是堆缓冲区对象。 public static ByteBuffer wrap(byte[] array, int offset, int length) { try { return new HeapByteBuffer(array, offset, length); } catch (IllegalArgumentException x) { throw new IndexOutOfBoundsException(); } } }接下来看看HeapByteBuffer类的关键代码。
class HeapByteBuffer extends ByteBuffer {
HeapByteBuffer(int cap, int lim) {
// 内存偏移量设置为0,把要使用的字节数组创建出来,然后复制给父类中的成员变量
super(-1, 0, lim, cap, new byte[cap], 0);
}
// 下面这两个就是从字节数组中获得字节的方法
// 可以看到就是直接返回数组对应索引的字节
public byte get() {
return hb[ix(nextGetIndex())];
}
public byte get(int i) {
return hb[ix(checkIndex(i))];
}
// 下面这两个就是向字节数组中写入字节的方法
// 可以看到就是把字节直接放到字节数组对应的索引位置
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
public ByteBuffer put(int i, byte x) {
hb[ix(checkIndex(i))] = x;
return this;
}
}接下来看看DirectByteBuffer类的关键代码。
class DirectByteBuffer extends MappedByteBuffer implements DirectBuffer
{
// 使用Unsafe类的对象分配堆外内存
protected static final Unsafe unsafe = Bits.unsafe();
DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
// 直接内存是否按页对齐
boolean pa = VM.isDirectMemoryPageAligned();
// 得到每一页的大小
int ps = Bits.pageSize();
// 在要申请的内存cap的基础上在多增加一页数据大小ps,得到真正要分配的内存大小。
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
// 先尝试预留内存操作,如果没成功,调用Sytem.gc()回收内存,接下来在一个
// 死循环中继续进行预留内存操作,这时候回收内存操作依靠虚拟机内存回收机制。
Bits.reserveMemory(size, cap);
long base = 0;
try {
// Unsafe对象分配内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
// 初始化内存,默认每一位都是0
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
// 创建的cleaner对象,关联了创建的base堆外内存地址,当DirectByteBuffer
// 对象被VM垃圾回收的时候,会根据base堆外地址,释放堆外内存。
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
public byte get() {
return ((unsafe.getByte(ix(nextGetIndex()))));
}
public byte get(int i) {
return ((unsafe.getByte(ix(checkIndex(i)))));
}
public ByteBuffer put(byte x) {
unsafe.putByte(ix(nextPutIndex()), ((x)));
return this
}
public ByteBuffer put(int i, byte x) {
unsafe.putByte(ix(checkIndex(i)), ((x)));
return this;
}
private long ix(int i) {
return address + ((long)i << 0);
}
}ByteBuf是什么
经过了上面的详细介绍后,我相信ByteBuffer已经没有秘密可言了。下面我们本篇文章的主角ByteBuf就登场了。使用Netty进行开发也需要频繁的创建对象来存储数据,频繁的对象创建和回收操作,意味着性能的低下。所以Netty使用了池化的思想,把对象的创建进行管理。如果用户也可以不使用池化的ByteBuf。这就使得Netty中的ByteBuf不仅可以按照池化缓冲区对象和堆内缓冲区对象来细分,还可以按照池化缓冲区对象和非池化缓冲区对象细分。下面的代码列出了Netty中的几种缓冲区的类型。
// 非池化的堆内缓冲区
UnpooledHeapByteBuf
// 非池化的堆外缓冲区
UnpooledDirectByteBuf
// 池化的堆内缓冲区
PooledHeapByteBuf
// 池化的堆外缓冲区
PooledDirectByteBufByteBuf内部结构如下图所示:
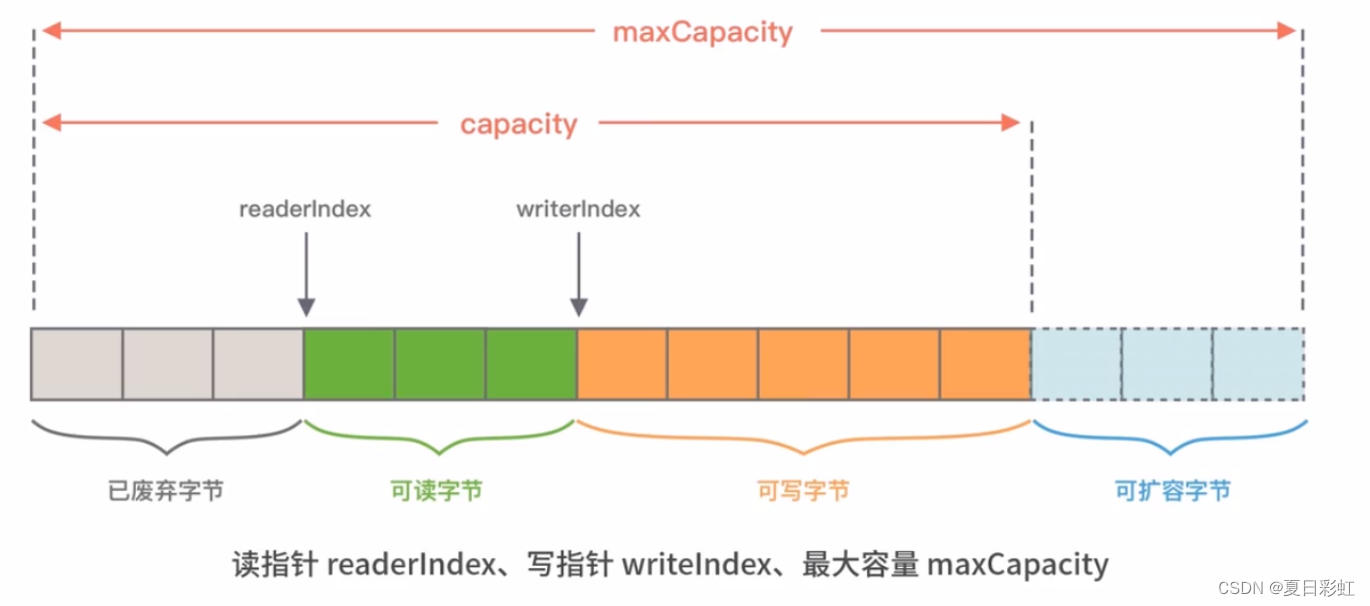
ByteBuf基于引用计数设计的,实现了ReferenceCounted接口。ByteBuf的生命周期是由引用计数所管理。只要引用计数大于0,表示ByteBuf还在被使用。当ByteBuf不再被其他对象所引用时,引用计数为0,那么代表该对象可以被释放,可以放入对象池中。















 4708
4708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









