






读这篇论文是为了完成期末大作业,跟我自己的科研方向无关。
Abstract
从单一的二维图像重建三维形状是一项具有挑战性的任务,它需要根据二维图像的语义属性来估计详细的三维结构。到目前为止,大多数以前的方法仍然难以为三维重建任务提取语义属性。由于单个图像的语义属性通常是隐含的,并且相互纠缠在一起,因此用输入图像所代表的详细语义结构来重建三维形状仍然是一个挑战。为了解决这个问题,我们提出了3DAttriFlow,通过输入图像的不同语义层次来分解和提取语义属性。这些被分解的语义属性将被整合到三维形状的重建过程中,这可以为三维形状上特定属性的重建提供明确的指导。因此,三维解码器可以在网络的底部明确地捕捉高层次的语义特征,并在网络的顶部利用低层次的特征,从而可以重建更精确的三维形状。请注意,显式分解是在没有额外标签的情况下学习的,在我们的训练中使用的唯一监督是输入图像和其相应的三维形状。我们在ShapeNet数据集上的综合实验表明,3DAttriFlow优于最先进的形状重建方法,并且我们还验证了它在形状完成任务上的泛化能力。代码见https: //github.com/junshengzhou/3DAttriFlow。
1. Introduction
从二维图像中重建三维形状(二维到三维重建)是弥合二维和三维视觉理解之间差距的一项重要任务。典型的范式是首先通过图像编码器捕捉二维图像的语义特征,然后通过三维解码器在三维空间中正确重建它们。在3D形状的多种表现形式中(即体素、点云和网格),本文主要关注从输入图像中重建3D点云,因为它具有轻量级的存储消耗和表现各种复杂形状的能力。
正如之前大多数方法的典型范式[26,37,42,51]所解决的那样,二维到三维重建的关键是如何将图像的语义属性精确地解释到三维空间。由于近年来二维计算机视觉的发展,有许多著名的方法(如AlexNet[16]、VGG[32]和ResNet[12])将语义属性编码到图像特征中,其效率也已被广泛的跨模态任务所证明(如图像字幕[34, 53]、跨模态检索[35, 57])。然而,对于二维到三维重建的研究,如何将视觉信息从二维域解释到三维域以实现精确三维重建,仍然是一项困难的任务。因为以前的大多数方法[26,37,38,42,51,52]只依靠特征通道(如元素加法、特征串联和注意机制)将视觉信息从图像编码器传达给三维解码器,其中只包含隐含的几何信息和有限的语义属性作为形状重建的指导。例如,一个整体的几何信息,如腿的数量将决定桌子有三个或四个腿。另一方面,详细的语义属性如腿的长度或弯曲度将具体决定这些腿的详细形状。然而,由于这些语义属性在图像特征中相互纠缠很深,在重建过程中,它们很难被解码器注意到。
此外,语义属性通常分布在不同的语义层面,并在图像编码器的整个金字塔层次结构中相互纠缠。因此,它们很难通过隐性特征通道得到充分的利用。因此,以前的方法通常存在引导解码器重建由编码器提取的各种视觉信息的问题,这导致以前的方法在预测三维形状时对语义特征的使用不足。
这个问题的一个直接解决方案是在解码器和编码器中的所有网络层之间建立多个特征通道,这将增加巨大的计算时间和网络复杂性的成本。另一方面,正如许多图像到图像转换的方法所证明的那样(例如图像超分辨率 [40, 50]、图像风格转换 [58]),我们注意到全局特征能够编码大部分语义属性对于单个图像,因为它们可用于高质量的图像生成/恢复任务。因此,一个有希望的解决方案是深入挖掘从 2D 图像中提取的全局特征,并解码嵌入在全局特征中的丰富语义属性,这可能为 3D 形状的重建过程提供更详细和明确的指导。根据上述直觉,我们提出了一种名为 3DAttriFlow 的新型神经网络,用于从 2D 图像中分解语义属性,并以可控的方式利用这些语义属性进行 3D 形状重建。
具体来说,如图1所示,以前的方法(图1(a))通常学习从隐含的图像特征中重建3D形状。相比之下,3DAttriFlow试图分解一个属性代码(图1(b))作为提示来捕捉一些特定的语义属性(图1(c))。这样的过程是由3DAttriFlow中提出的属性流管道完成的。通过属性流管道将语义属性提示引入点云的分层生成过程,解码器能够按照语义等级的层次有选择地解释语义属性。
我们的想法受到最近的EigenGAN[13]生成方法的启发,该方法以无监督的方式学习处理人脸的明确语义属性。然而,由于点云的离散性,点的坐标只是以无序的方式组织,这与以有序网格结构排列的图像像素形成对比。点云的这种性质使得每个点的位置在生成过程中是不可预测的,直到三维坐标在解码器结束时才最终显现。因此,直接实施基于EigenGAN[13]的解码器可能会导致失败,因为网络在不知道某个特定点的位置的情况下无法准确预测其语义属性。为了解决这个问题,我们提出变形管作为解决方案,它遵循PMP-Net[47]的思想,将形状生成过程重新考虑为一个形状变形过程。也就是说,每个点首先在三维空间中被分配一个事先的位置,然后移动到它们的目的地,重新组合为一个新的形状。具体来说,3DAttriFlow将从三维球体采样的点云移动到二维图像所指示的目标形状。总的来说,我们的主要贡献概括为以下几点。
- 我们提出了一个新的深度网络,名为3DAttriFlow,用于从单一的二维图像重建高质量的三维形状。与以前的方法相比,3DAttriFlow可以从图像中解释明确的语义属性,并有效地利用它们来指导解码器进行详细的、高质量的二维到三维形状重建。
- 我们提出了属性流管道,明确地分解嵌入在二维图像全局特征中的语义属性,这可以为三维解码器提供关于语义属性的详细重建的明确指导,从而在整体和详细形状结构方面对三维形状进行更准确的预测。
- 我们提出变形管为属性流管提供位置先验,通过利用该点的位置,可以将提取的语义属性分配给一个特定的点。因此,3DAttriFlow避免了将语义分配给无序数据的问题,并允许在属性流管道和变形管道之间进行更准确的特征整合。
2. Related Work
近年来,三维计算机视觉领域的三维表示学习[7, 10, 11, 23, 44, 45]、重建[6, 8, 9, 18, 24, 25, 48]和完成[43, 46]的改进,推动了从二维图像重建三维形状的研究,根据输入图像的数量,可以分为:单视角三维形状重建[5, 26, 37, 38, 42]和多视角三维形状重建[42, 51, 52]。另一方面,根据三维形状的不同表示形式,相关工作也可分为:基于体素的三维形状重建[26, 38, 51, 52]、基于点云的三维形状重建[4,5,21,36]和基于网格的三维形状重建[37,42]。具体来说,本文提出的3DAttriFlow属于单视角三维形状重建,它是基于点云的。为方便起见,相关工作的讨论将按照三维形状的输出形式来组织。
基于点云的方法。随着PointNet[30]的开创性工作所引发的点云表示学习[20, 23, 30, 31, 41]的快速发展,近年来点云生成被广泛研究,并推动了从二维图像重建点云的研究。大多数基于点云的方法[2,4,5,14,27]都采用生成法来预测基于二维图像的点坐标,他们的努力要么是为了改善图像编码器和三维形状解码器之间的特征通信[4],要么是对生成的点云施加额外的监督/约束[14, 27, 55]。
基于体素/网格的方法。对于基于体素的重建方法,三维体素的网格结构被自然地应用于卷积神经网络中,它将问题简化为将二维网格数据转化为三维网格数据。沿着这条路线的典型做法是在二维和三维领域直接利用CNN结构,其目的是从输入图像中提取二维网格特征,并重建相应的三维网格形状。典型的方法如3DR2N2[3]、Pix2V ox[51]和Pix2V ox++[52]已经全面探索了使用单个或多个图像作为输入的三维重建性能。然而,受制于输入体素数据的立体增长,体素数据的分辨率通常是有限的,而进一步提高分辨率将导致不可接受的计算成本。至于基于网格的方法,它们中的大多数都遵循从先前的形状变形的想法。例如,Pixel2Mesh[37]及其后续的Pixel2Mesh++[42]考虑将椭圆体网格变形为目标形状,结合多阶段融合策略,将图像特征引入网格变形网络。Pan等人[28]通过对网格的变形同时修改其类型,提高了生成复杂形状的能力。然而,网格的交集和流形表面的假设将阻碍具有内部或不规则结构的三维形状的生成。
讨论。从二维图像中重建三维形状需要对二维图像中的语义属性进行深入理解,并对三维空间中的语义属性进行正确解释。上述方法要么选择直接从全局特征解码3D形状,要么依靠特征通道在图像编码器和形状解码器之间架起网络层。问题是,所有这些做法只能将2D图像的隐含特征传达给3D形状,导致对重建3D形状的具体和详细语义属性的指导不明确。与之前的这些方法不同,3DAttriFlow提出了从图像特征中直接分解语义属性的解决方案,并将其整合到形状重建过程中,这可以为根据二维图像重建特定的语义属性提供明确的指导。此外,3DAttriFlow中的属性分解能力使解码器能够按照语义层次灵活地重建语义属性,这与固定通道的网络相比,只允许解码器从编码器的固定层中学习。

图1. 以前的方法(a)和我们的3DAttriFlow(b)之间的比较。除了输入图像的隐性特征x,3DAttriFlow还学习了一个额外的属性代码z,它可以在(c)中揭示一些关于三维形状的更具体的语义属性的提示。
3. Architecture of 3DAttriFlow
3DAttriFlow的整体架构如图2所示,它根据输入的图像重建一个具有N个点的三维点云3DAttriFlow主要由以下两条管道组成。(1) 属性流管道(见图2(a))的作用是将语义属性从输入特征中分离出来,该特征通常是由图像编码器提取的全局特征。(2) 变形管道(见图2(b))用于将从三维球体采样的初始点云变形为目标形状,这是由属性流管道的语义属性引导的。每条管道的结构详见下文。
3.1. Attribute Flow Pipe
如图2(a)所示,属性流管道旨在从图像特征x和球形点云{pk}中逐步提取几何代码{σ, µ}和语义特征si,其中i表示第i步。然后,提取的特征和代码将被整合到变形管道中,指导球形点云{pk}的变形。属性流管道的基本架构由一个特征提取器和三个属性流模块(AF模块)组成。具体来说,对于输入图像,3DAttriFlow使用ResNet18从输入图像中提取一个图像特征x。然后,AF模块从图像特征x中提取视觉信息并解释为几何信息和语义属性,这是由几何子管道和语义子管道完成的,如图2(c)所示。
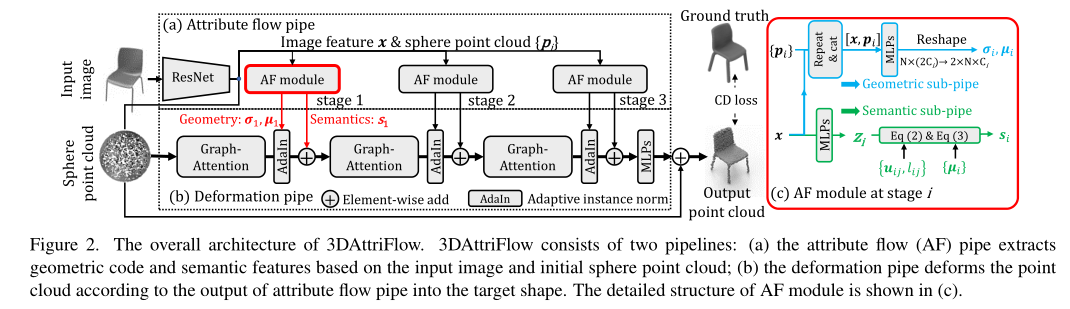
几何子管。几何子管道旨在将图像的整体视觉信息解释为几何信息,可用于变形管道的3D形状重建。受基于风格迁移的生成方法 [15, 17] 的启发,该方法从潜在随机向量中学习局部风格,我们建议将由图像特征 x 编码的视觉信息解释为几何风格 {σi, μi},这是根据到初始点云 {pk} 给出的位置。如图2(c)中的几何子管道所示,在阶段i,图像特征x首先被重复并与位置先验{pk}连接为{[x:pk]},其中“:”表示特征级联。然后,通过几个多层感知器 (MLP) 和重塑操作,图像特征与位置先验结合被解释为几何样式 {σi|σi ∈ RN×Ci} 和 {µi|µi ∈ RN×Ci},其中 Ci表示第 i 阶段变形管中点特征的维度。
语义子管道。语义子管道旨在从图像特征x中分解出显式的语义属性,并通过属性代码z的某个维度上的激活来表示它们。因此,变形管可以在属性代码给出的明确指导下产生精确的3D语义属性。具体来说,如图 2(c) 的下分支所示,在阶段 i,语义子管道首先将图像特征 x 压缩为属性代码 zi 为:

其中 φ 表示 MLP 层,θi 表示用于生成 zi 的 MLP 层的权重。根据他等人的说法。 [13],对于属性代码 zi 的第 j 维的激活 zij,来自线性子空间 Ui = {uij} 的正交基 uij ∈ RN×Ci 将用于发现位于 zij 后面的语义属性 ˆzij:
![]()
其中,lij 是一个可学习的权重,表示由正交基 uij 发现的语义属性的重要性。通过在属性代码zi的所有维度上添加语义属性^zj,语义子管道输出用显式属性信息编码的语义特征si,公式为:
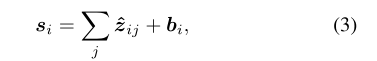
其中 bi 是一个可学习的偏差。语义特征 si 将流入变形管道,以指导 3D 语义属性的重建。
3.2. Deformation Pipe
变形管的结构如图2(b)所示。变形管底部的输入是一个点集 P = {pi},它是从一个 3D 球体中均匀采样的。请注意,我们选择球体作为起始形状,因为球体上的每个点都可以视为 L2 正则化向量,这保证了网络输入之前的各向同性形状。变形管顶部的输出是一组位移向量{Δpi}。变形管的输出是变形点集Po = {(pi + Δpi)},与目标点形状相同云点 = {ptj}。
为了预测每个点的位移向量 {Δpi},我们遵循 Wang 等人。 [41]通过图注意力模块从多个输入点集P中提取点特征,形成一个三阶段的点特征学习框架。在第 i 阶段,变形管道将几何样式 {σi, µi} 和语义特征 si 作为输入,并根据从图像特征中解释的几何信息和语义属性推断每个点的位移。为方便起见,我们将阶段 i 生成的点特征表示为 Qi = {qik}。
对于几何样式{σi, µi},我们遵循样式迁移[15]的做法引入自适应实例归一化,用于根据几何样式中编码的几何信息来适应点特征。公式如下:
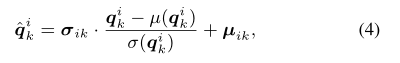
其中 μ(qik) 和 σ(qik) 分别表示通过移动平均算法估计的 qik 的均值和偏差。σik 和 μik 分别表示 σi 和 μi 第 k 行的向量。
根据几何样式对点特征进行适配后,语义特征si通过MLP层和元素相加集成到点特征^qi k中,给出为:
![]()
在变形管道的顶部,我们使用 MLP 层将点特征转换为 3 维位移向量 {Δpk},最后输出变形形状为 {pk + Δpk}。
3.3. Extension to Shape Completion
3DAttriFlow 也可以用于预测不完整形状的缺失部分,这可以通过将图像编码器替换为属性流管道中的 3D 点云编码器(如 PointTransformer [56])来实现。结果,输入图像特征 x 被点云特征 ^x 替换。受 PMP-Net [47] 的启发,我们发现不完整点云的每点特征可以用作指导基于移动的完成之前的位置。因此,我们将重复的图像特征 {xk} 替换为每点特征 {f k},这些特征由 PointNet++ [31] 中指定的特征传播模块学习。之后,我们将 {f k} 与球点云 {pk} 连接为 {[f k : pk]}。属性流管的修改如图 3 所示。为了进一步提高完成性能,我们遵循大多数完成方法 [29, 49] 采用的从粗到细的策略,从 VRCNet [ 29],旨在细化预测点云的详细形状。
3.4. Training loss
Ui 的正交性由正交性损失的正则化保证,其定义为:
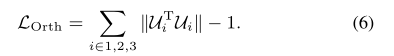
以图像和不完整形状为条件的变形形状由地面实况点云通过倒角距离 (CD) 进行正则化,定义为:
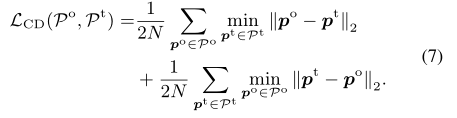
总训练损失表示为
![]()
其中 α 是确定 LOrth 权重的平衡因子。在本文中,所有实验的 α 都设置为 100。
4. Experiments
在本节中,我们通过实验评估 3DAttriFlow 在 2D 到 3D 重建任务中的有效性,并通过点云完成任务分析其泛化能力。消融研究将重点关注 3DAttriFlow 各个部分的有效性,并通过形状操作对提取的语义属性进行可视化分析。
4.1. 2D-to-3D Reconstruction on ShapeNet dataset
数据集简介和评估指标。我们遵循 OccNet [26] 的实验设置来评估我们在 ShapeNet 数据集 [1] 上的 3DAttriFlow。整个数据集由 13 个类别的 43,783 个网格对象组成,将按照与 OccNet [26] 相同的策略分为训练、验证和测试。由于我们的方法侧重于从 2D 图像重建 3D 点云,我们遵循 AtlasNet [5] 在 3D 对象的网格表面上均匀采样 30k 点作为训练的 ground truth。遵循以前的方法 [26,37],我们使用方程式描述的 L1 倒角距离。 (7) 作为评价指标。


图 4. ShapeNet 数据集下不同方法的 2D 到 3D 重建结果的视觉比较。
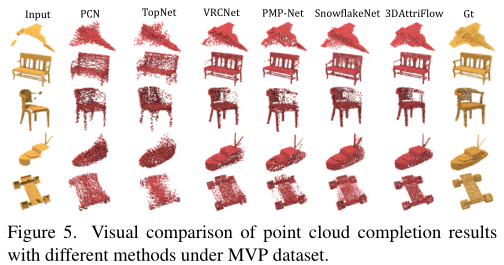
图 5 MVP数据集下不同方法点云补全结果的可视化对比。
为了与其他重建 3D 体素或网格的方法进行比较,我们按照 OccNet [26] 从它们的输出表面采样 2,048 个点,然后计算 L1 Chamfer 距离与 ground truth。对于基于体素的方法,我们另外将它们的体素输出转移到网格中,然后在网格表面上应用点云采样。
定量比较。 2D 到 3D 重建的结果如表 1 所示,其中 3DAttriFlow 实现了优于其他比较对应方法的性能。特别是 PSGN [4] 和 AtlasNet [5] 是基于点云的方法,它们与 3DAttriFlow 最相关。但是,与这两种方法相比,3DAttriFlow 实现了超过 25% 的性能增益。正如我们在第二节中讨论的那样。如图1所示,上述两种方法采用了典型的2D到3D重建范式,AtlasNet[5]根据全局特征的隐式输入直接解码整个形状,PSGN[4]利用编码器之间的特征通道和解码器,用于引入各种级别的语义。这些实践都不能从图像中学习显式语义特征,而只能尝试从隐式全局特征或编码器的中间层解码形状。相比之下,3DAttriFlow 可以利用从图像中学习到的隐式和显式语义属性,这分别是通过几何子管道和语义子管道。因此,3DAttriFlow 能够基于来自显式语义属性的更明确的指导来预测 3D 形状的细节,并获得比同类产品更好的性能。
定性比较。 2Dto-3D 重建的视觉对比如图 4 所示。请注意,对于 AtlasNet,我们遵循其原始可视化设置来展示重建的网格而不是点云。与其他方法相比,3DAttriFlow 在广泛的对象类别上重建了更好的细节。例如,在椅子类别上(图 4 的第 5 行),OccNet 的预测中缺少腿,而 PSGN 和 AtlasNet 的椅子预测模棱两可且充满噪声。至于平面类别,PSGN 和 AtlasNet 都无法重建第 1 行和第 2 行引擎的详细形状,而 OccNet 无法稳定地对引擎进行正确预测(第 2 行失败)。
4.2. 3D Completion on MVP dataset
数据集简介和评估指标。我们遵循 VRCNet [29] 的实验设置来评估我们在 MVP 数据集 [29] 上的 3DAttriFlow。该数据集由从 ShapeNet 中选择的模型生成的 16 类不完整/完整点云组成,然后分为训练集(62,400 个形状对)和测试集(41,600 个形状对)。按照之前的方法 [29, 33, 47],我们使用 L2 倒角距离作为评估指标。
定量比较。点云补全对比如表2所示。与当前最先进的补全方法SnowflakeNet[49]相比,3DAttriFlow在L2-CD方面进一步提升了13.7%的性能。完成任务背后的直觉与 2D 到 3D 重建任务相同,即根据给定的输入预测 3D 形状。在点云补全的情况下,输入是不完整的 3D 形状。 3DAttriFlow 获得的更好性能可以致力于更全面、更明确地理解语义属性,这是通过 AF 模块中的语义子管道。例如,为了推断缺少的椅子腿的长度,明确控制此类属性的语义代码能够指导解码器做出更精确的预测。相比之下,对于表 2 中的比较方法,它们的解码器必须从隐式特征中进行预测,其中腿的属性与隐式特征中的其他属性纠缠在一起。
定性比较。在图 5 中,我们在 MVP 数据集上将 3DAttriFlow 与其他完成方法进行了定性比较,从中我们可以发现 3DAttriFlow 比其他方法产生更精确和一致的完整形状。以完成第 2 排和第 3 排椅子为例,3DAttriFlow 对椅背和缺少椅子扶手的预测明显优于其他方法。至于第 5 排的滑板,这五种比较方法都把轮子和滑板弄乱了,而 3DAttriFlow 可以产生目标滑板的干净和细致的形状。
4.3. Ablation Studies
在本小节中,所有定量分析结果通常在四个类别(即飞机、汽车、椅子和桌子)下进行。默认情况下,所有实验设置都与 Sec 中的设置保持一致。 4.1,除了下面每个消融实验中描述的修改部分。
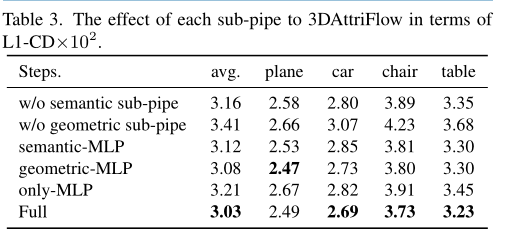
分析AF模块中的每个子管道。我们通过从原始网络结构(表示为完整)中删除/替换模块来分析 3DAttriFlow 的每个子管道的有效性。具体来说,我们开发了四种不同的变体进行比较:(1)w/o语义子管道是从AF模块中删除语义子管道的变体; (2) w/o geometry sub-pipe是从AF模块中去除几何子管道的变体; (3) 语义 MLPs 是用简单的 MLP 层替换语义子管道的变体,其中输出直接添加到变形管道中的特征; (4) 几何 MLPs 是用简单的 MLPs 代替几何子管道的变体,其中输出被添加到变形管道中的特征中。结果如表 3 所示,从中我们可以发现,我们的 Full 模型在所有四种变体中都取得了最好的结果。这样的结果证明了每个部分对 3DAttriFlow 的有效性。
此外,我们还解决了两个结论。首先,通过将w/o几何子管道和w/o语义子管道与Full模型进行比较,可以发现语义子管道对2D-to-3D重建性能的影响比几何子管道要小。 -管道。原因在于,虽然语义子管道可以从二维图像中显式地解开和提取语义属性,但始终存在某些无法显式捕获或解开的语义属性。因此,对于图像中的这种隐式语义属性进行编码,仍然需要隐式表示。其次,通过将geometric-MLP和semantic-MLP与only-MLPs进行比较,我们可以发现几何子管道和语义子管道都比简单的MLPs更有效,这证明了两个子管道的网络指定的有效性。 -管道。
由语义代码 z 控制的语义属性的可视化。语义代码 z 期望将显式语义属性编码为单个维度的激活,旨在为 3D 形状的重建提供明确的指导。为了直观地分析 z 捕获的编码语义属性,我们遍历 z 的维度并观察由 z 的单个维度插值引起的形状变形,如图 6 所示。具体来说,我们说明了我们对每个属性的 3 个属性的观察3个类别,证明语义代码z成功捕捉了显式语义属性,有效揭示了3D形状对应部分的重构。例如,对于椅子的重建(图 6(a)),代码 z 学习了腿的两个特定语义属性,即弯曲(在第 2 阶段由第 6 维编码)和长度(由第 5 维编码)分别在第 3 阶段)。从图6(c)的可视化结果可以发现,改变激活值会导致对应语义属性明显变形。此外,通过观察提取的三个类别的语义属性,我们可以发现语义代码 z 能够将其学习属性泛化为多个类别,因为弯曲和长度的相同属性也可以在表格和平面类别中找到。
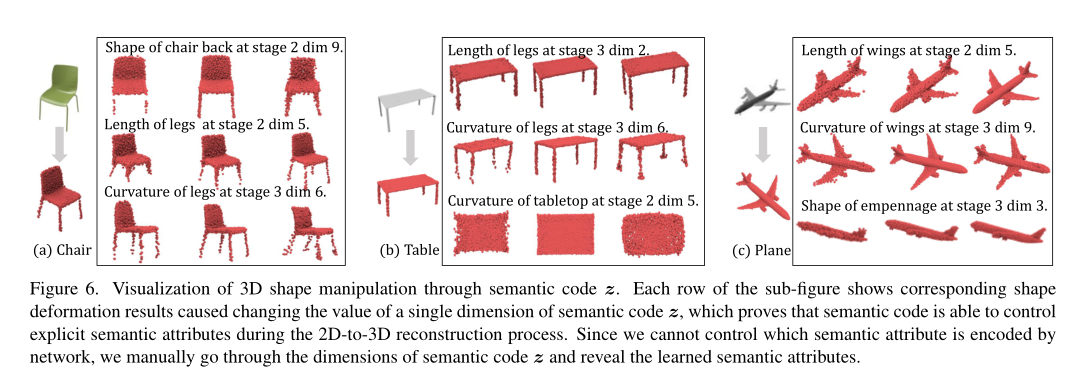
图 6. 通过语义代码 z 可视化 3D 形状操作。子图的每一行显示了相应的形状变形结果,导致语义代码z的单维值发生变化,这证明了语义代码在2D到3D重建过程中能够控制显式语义属性。由于我们无法控制网络对哪个语义属性进行编码,因此我们手动遍历语义代码 z 的维度并揭示学习到的语义属性。
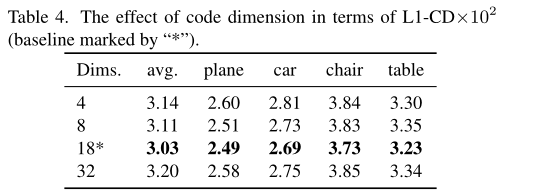
语义代码分析 z。由于语义代码 z 的每个维度都可以潜在地编码某个语义属性,因此在这一部分中,我们将讨论语义代码 z 在代码维度方面对语义属性进行编码的能力。我们按照 2 的幂报告了 4、8 和 32 的代码维度下的结果,并将其与表 4 中我们的默认设置 18 进行比较。从结果中我们可以发现,使用 18 维语义代码 3DAttriFlow 实现了最佳性能,而其他设置会导致相对较小的性能下降。原因是对于小维度,语义代码只能编码有限的语义属性,不足以预测详细的 3D 形状。另一方面,大维度可能存在学习正交基来表示语义属性的问题。此外,我们在图 7 中可视化了从不同对象交换代码 z 和 µ 的效果,从中我们可以观察到几个几何/语义属性分别由代码 µ 和 z 清楚地控制。
5. Conclusions and Limitations
在本文中,我们提出 3DAttriFlow 从 2D 图像重建 3D 形状。与以往仅学习基于隐式特征重构3D形状的方法相比,3DAttriFlow利用新颖的属性流管从隐式特征中显式提取语义属性,使得基于隐式特征的3D形状预测更加准确。提取的语义属性。为了克服生成离散点云数据的问题,提出了将变形管道与属性管道相结合,为提取的语义属性提供位置先验。用于 2D 到 3D 重建的 ShapeNet 数据集和用于点云补全的 MVP 数据集的综合实验证明了 3DAttriFlow 的有效性,形状操作的可视化也证明了 3DAttriFlow 提取和控制 3D 形状的显式语义属性的能力。
3DAttriFlow 的局限性和未来可能的工作可以解决如下。尽管语义代码 z 能够学习显式语义属性并将它们编码为特定维度,但它不能总是为每个维度学习有意义或解开的语义属性。在实验中,我们观察到某些维度可能对几个属性有影响,而其他维度可能对输出形状影响不大。在我们看来,这可以专门用于全局图像特征提取过程中的信息丢失/压缩,这可能导致语义属性丢失或相互深度纠缠。因此,仍然需要将多层编码器连接到属性流管道的特征通道,以充分利用3DAttriFlow的语义属性提取能力。

















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









