









作者:RayChiu_Labloy
版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处
目录
回顾神经网络NN
上次我们系统的分析了神经网络的原理:
https://blog.csdn.net/RayChiu757374816/article/details/121351693
深层神经网络DNN定义
上次我们说到多个隐藏层的人工神经网络ANN就是深层神经网络DNN了。
梯度下降训练的两个阶段
前向求loss
反向传播求每个w的梯度,更新w
复合函数的链式求导法则
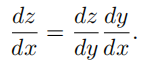
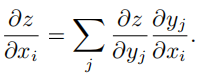
神经网络中的链式求导:

为防止过拟合的几种Regularization技术
L1、L2正则
Dropout
dropout很像随机森林的设计,我们知道随机森林是由很多小树组成,每棵小树都是随机的数据训练的,这里dropout也是随机扔掉一些节点或连接达到随机数据的意思。
数据增强
早停法
参考:深度学习中的五大正则化技术_luxiaohai学习专栏-CSDN博客
归一化、标准化、正则化公式相关小记_RayChiu757374816的博客-CSDN博客
【深度学习篇】--神经网络中的调优二,防止过拟合_L先生AI课堂-CSDN博客
梯度消失梯度爆炸问题
激活函数问题
详见:https://raychiu.blog.csdn.net/article/details/123375408
参数的初始化
bad initialization问题:
首先参数初始化的几种方式:

下边我们一一看一下各种情况做一下对比:
1.首先全零初始化是不可用的,如果所有的参数都是0,那么所有神经元的输出都将是相同的,那在back propagation的时候同一层内所有神经元的行为也是相同的 --- gradient相同,weight update也相同。这显然是一个不可接受的结果。
2.随机初始化参数
随机初始化是很多人目前经常使用的方法,然而这是有弊端的,一旦随机分布选择不当,就会导致网络优化陷入困境。
这里我们创建了一个10层的神经网络,非线性变换为tanh,每一层的参数都是随机正态分布,均值为0,标准差为0.01。下图给出了每一层输出值分布的直方图:

随着层数的增加,我们看到输出值迅速向0靠拢,在后几层中,几乎所有的输出值X都很接近0!回忆优化神经网络的back propagation算法,根据链式法则,gradient等于当前函数的gradient乘以后一层的gradient,这意味着输出值X是计算gradient中的乘法因子,直接导致gradient很小,使得参数难以被更新!
让我们将初始值调大一些,均值仍然为0,标准差现在变为1,下图是每一层输出值分布的直方图:

几乎所有的值集中在-1或1附近,神经元saturated了!注意到tanh在-1和1附近的gradient都接近0,这同样导致了gradient太小,参数难以被更新。
3.Xavier initialization
Xavier initialization可以解决上面的问题!其初始化方式也并不复杂。Xavier初始化的基本思想是保持输入和输出的方差一致,这样就避免了所有输出值都趋向于0。注意,为了问题的简便,Xavier初始化的推导过程是基于线性函数的,但是它在一些非线性神经元中也很有效。让我们看一下输出结果:

输出值在很多层之后依然保持着良好的分布,这很有利于我们优化神经网络!之前谈到Xavier initialization是在线性函数上推导得出,这说明它对非线性函数并不具有普适性,所以这个例子仅仅说明它对tanh很有效,那么对于目前最常用的ReLU神经元呢?输出如下图

前面看起来还不错,后面的趋势却是越来越接近0。幸运的是,He initialization可以用来解决ReLU初始化的问题
4.He initialization
He initialization的思想是:在ReLU网络中,假定每一层有一半的神经元被激活,另一半为0,所以,要保持variance不变,只需要在Xavier的基础上再除以2:

看起来效果非常好,推荐在ReLU网络中使用!
5.pre-training
pre-training是早期训练神经网络的有效初始化方法,一个便于理解的例子是先使用greedy layerwise auto-encoder做unsupervised pre-training,然后再做fine-tuning。在这里简略的说一下:(1)pre-training阶段,将神经网络中的每一层取出,构造一个auto-encoder做训练,使得输入层和输出层保持一致。在这一过程中,参数得以更新,形成初始值(2)fine-tuning阶段,将pre-train过的每一层放回神经网络,利用pre-train阶段得到的参数初始值和训练数据对模型进行整体调整。在这一过程中,参数进一步被更新,形成最终模型。
随着数据量的增加以及activation function 的发展,pre-training的概念已经渐渐发生变化。目前,从零开始训练神经网络时我们也很少采用auto-encoder进行pre-training,而是直奔主题做模型训练。不想从零开始训练神经网络时,我们往往选择一个已经训练好的在任务A上的模型(称为pre-trained model),将其放在任务B上做模型调整(称为fine-tuning)。
参考:深度学习参数初始化(weights initializer)策略大全_MIss-Y的博客-CSDN博客_参数初始化
聊一聊深度学习的weight initialization_FontTian的博客-CSDN博客
总结: 深度学习中的weight initialization对模型收敛速度和模型质量有重要影响!因此在没有使用BN的时候,ReLU activation function中推荐使用Xavier Initialization的变种He Initialization,而有了BN,则可以有效降低深度网络对weight初始化的依赖。
Normalization标准化
回顾机器学习中特征归一化及其优点
在数据分析之前,我们通常需要先将数据归一化成相同量纲下的数据,然后再做数据分析。
归一化好处有两点:
1.加快基于梯度下降法或随机梯度下降法模型的收敛速度;
2.提高精度:
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
如在涉及到一些距离计算的算法时,例如KNN:如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。另外在SVM中,最后的权值向量ωω受较高指标的影响较大。
参考:归一化、标准化、正则化公式相关小记_RayChiu757374816的博客-CSDN博客
深度学习中的Normalization
为什么要做归一化处理?
神经网络学习过程的本质就是为了学习数据分布,如果我们没有做归一化处理,那么每一批次训练数据的分布不一样,从大的方向上看,神经网络则需要在这多个分布中找到平衡点,从小的方向上看,由于每层网络输入数据分布在不断变化,这也会导致每层网络在找平衡点,显然,神经网络就很难收敛了。当然,如果我们只是对输入的数据进行归一化处理(比如将输入的图像除以255,将其归到0到1之间),只能保证输入层数据分布是一样的,并不能保证每层网络输入数据分布是一样的,所以也需要在神经网络的中间层加入归一化处理。
四种归一化:
常用的Normalization方法主要有:Batch Normalization(BN,2015年)、Layer Normalization(LN,2016年)、Instance Normalization(IN,2017年)、Group Normalization(GN,2018年)。它们都是从激活函数的输入来考虑、做文章的,以不同的方式对激活函数的输入进行 Norm 的。
我们将输入的 feature map shape 记为[N, C, H, W]:

其中N表示batch size,即N个样本;C表示通道数;H、W分别表示特征图的高度、宽度,通过蓝色部分的值来计算均值和方差,从而进行归一化。
上图中四种归一化方式的区别:
1. BN是在batch上,对N、H、W做归一化,而保留通道 C 的维度。BN对较小的batch size效果不好。BN适用于固定深度的前向神经网络,如CNN,不适用于RNN;
2. LN在通道方向上,对C、H、W归一化,主要对RNN效果明显;
3. IN在图像像素上,对H、W做归一化,用在风格化迁移;
4. GN将channel分组,然后再做归一化。
四种归一化放到实际生活例子中解释:
如果把特征图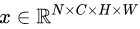 比喻成一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 有W 个字符。
比喻成一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 有W 个字符。
1. BN 求均值时,相当于把这些书按页码一一对应地加起来(例如第1本书第36页,第2本书第36页......),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),求标准差时也是同理。
2. LN 求均值时,相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”,求标准差时也是同理。
3. IN 求均值时,相当于把一页书中所有字加起来,再除以该页的总字数:H×W,即求每页书的“平均字”,求标准差时也是同理。
4. GN 相当于把一本 C 页的书平均分成 G 份,每份成为有 C/G 页的小册子,求每个小册子的“平均字”和字的“标准差”。
BN的主要思想(重点谈一下BN):
针对每个神经元,使数据在进入激活函数之前,沿着通道计算每个batch的均值、方差,‘强迫’数据保持均值为0,方差为1的正态分布,避免发生梯度消失。具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 ...... 加上第 N 个样本第1个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第1个通道平均值的数字,而不是一个 H×W 的矩阵)。求通道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。
BN的使用位置:
全连接层或卷积操作之后,激活函数之前。
BN算法过程:
Batch Normalization将输出值强行做一次Gaussian Normalization和线性变换:
-
沿着通道计算每个batch的均值
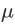
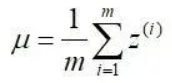
-
沿着通道计算每个batch的方差
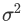

-
做归一化
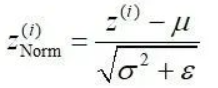
-
加入缩放和平移变量
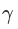 和
和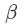
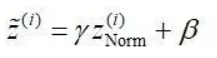
BN中所有的操作都是平滑可导,这使得反向传播可以有效运行并学到相应的参数γ,β。需要注意的一点是BN在training和testing时行为有所差别。Training时μB和σB由当前batch计算得出;在Testing时μB和σB应使用Training时保存的均值或类似的经过处理的值,而不是由当前batch计算。
加入缩放和平移变量的原因是:保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。 这两个参数是用来学习的参数。
BN的作用:
(1)允许较大的学习率;
(2)减弱对初始化的强依赖性;
(3)保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础;
(4)有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout)。
BN存在的问题:
(1)每次是在一个batch上计算均值、方差,如果batch size太小,则计算的均值、方差不足以代表整个数据分布。
(2)batch size太大:会超过内存容量;需要跑更多的epoch,导致总训练时间变长;会直接固定梯度下降的方向,导致很难更新。
【如果对您有帮助,交个朋友给个一键三连吧,您的肯定是我博客高质量维护的动力!!!】
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









