






1.概念简述
全连接神经网络(DNN)是一种多层无监督神经网络,并且将上一层的输出特征作为下一层的输入进行特征学习,通过逐层特征映射后,将现有空间样本的特征映射到另一个特征空间,以此来学习对现有输入具有更好的特征表达。
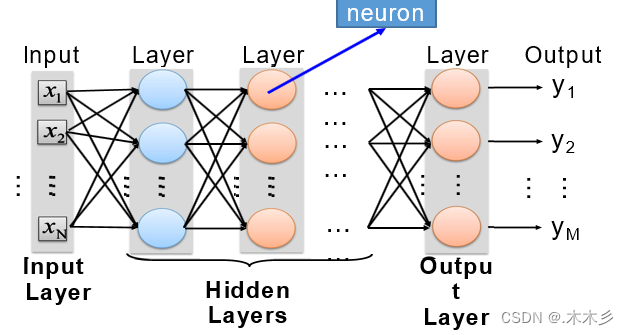
DNN模型的神经网络层分为三类,其中第一层为输入层,最后一层为输出层,中间都为隐藏层。每一层之前是完全连接的。
2.计算过程:
最左边的是输入层,最右边的是输出层,中间是多个隐含层,输入层开始,从左往右计算,逐层往前直到输出层产生结果。如果结果值和目标值有差距,再从右往左算,逐层向后计算每个节点的误差,并且调整每个节点的所有权重,反向到达输入层后,又重新向前计算,重复迭代以上步骤,直到所有权重参数收敛到一个合理值。由于计算机程序求解方程参数和数学求法不一样,一般是先随机选取参数,然后不断调整参数减少误差直到逼近正确值。
3.核心思想
深度神经网络具有多个非线性映射的特征变换,可以对高度复杂的函数进行拟合。如果将深层结构看作一个神经元网络,则深度神经网络的核心思想可用三个点描述如下:
(1)每层网络的预训练均采用无监督学习;
(2)无监督学习逐层训练每一层,即将上一层输出作 下一层的输入;
(3)有监督学习来微调所有层(加上一个用于分类的分类器)。
深度神经网络与传统神经网络的主要区别在于训练机制。
为了克服传统神经网络容易过拟合及训练速度慢等不足,深度神经网络整体上采用逐层预训练的训练机制,而不是采用传统神经网络的反向传播训练机制。
4.DNN模型
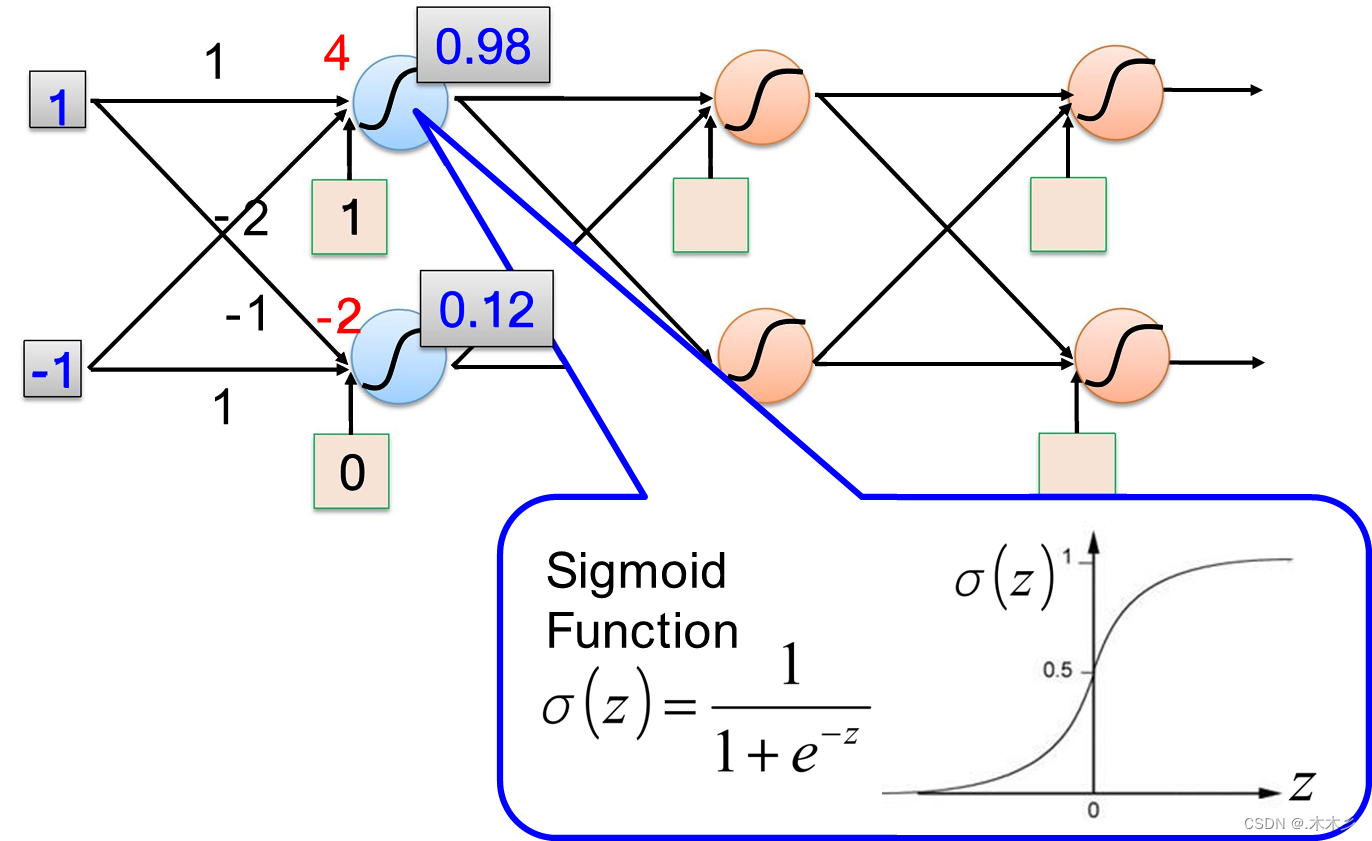
从x1到第二层,需要一个激活函数(如下所示)。假设这个激活函数为z(x),我们给它加上一些权重参数w1,w2,w3,w0,以及一个x0并且x0=1。同理把结果作为下一层的输入代入激活函数,且取为1
5.常见的激活函数:
1)Sigmoid函数:将一个是实数映射到(0,1)之间;在特征相差不大的时候效果比较好,通常用来做二分类
![]()
缺点:激活函数计算量大;容易出现梯度消失:当数据分布在曲线平滑位置的时候很容易出现梯度消失,梯度容易饱和。
2)Tanh函数:取值范围为[-1,1];输出以0为中心;可以看成是一个放大版本的sigmoid函数
![]()
用法:tanh函数比sigmoid函数更加的常用;循环神经网络会用;二分类问题;靠近输出值位置
缺点:梯度容易消失;在曲线水平的区域学习非常的慢
3)ReLU函数:对与梯度收敛有巨大加速作用;只需要一个阀值就可以得到激活值节省计算量
![]()
用法:深层网络中隐藏层常用
缺点:过于生猛,一言不合就会使得数据变为0,从此结点后的相关信息全部丢失。
4.tensorfliw——西瓜数据集DNN案例:
#tensorfliw——西瓜数据集
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
import tensorflow as tf
import pandas as pd
#读取数据
xigua = pd.read_csv("watermelon.csv", encoding="utf-8")
#xigua.info()
# print(xigua)
df_data=pd.get_dummies(xigua,columns=['色泽','根蒂','敲声','纹理','脐部','触感'])
#print(df)
# df_data.info()
# print(df_data)
print('feature_names:',df_data.columns)#查看样本的13个特征名称
# 筛选需要提取的字
selected_cols = ['编号', '好瓜', '色泽_ 乌黑', '色泽_ 浅白', '色泽_ 青绿', '色泽_ 乌黑', '色泽_ 浅白',
'色泽_ 青绿', '根蒂_硬挺', '根蒂_稍蜷', '根蒂_蜷缩', '敲声_沉闷', '敲声_浊响', '敲声_清脆',
'纹理_模糊', '纹理_清晰', '纹理_稍糊', '脐部_凹陷', '脐部_平坦', '脐部_稍凹', '触感_硬滑', '触感_软粘']
selected_df_data=df_data[selected_cols]
def prepare_data(df_data):
df=df_data.drop('编号',axis=1)
df['好瓜'] = df['好瓜'].map({'否':0,'是':1}).astype(int)
#分割特征值与标签值
ndarray_data=df.values
features=ndarray_data[:,1:]#除第一列其他列是特征值
label=ndarray_data[:,0]#第一列标签值
minmax_scale=preprocessing.MinMaxScaler(feature_range=(0,1))
#将数据的每一个特征缩放到给定的范围,将数据的每一个属性值减去其最小值,然后除以其极差(最大值 - 最小值)
norm_features=minmax_scale.fit_transform(features)#特征值标准化
# 用最大最小缩放器这个规则对feature进行计算转化
return norm_features,label
x_data,y_data=prepare_data(selected_df_data)
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.25)
train_dataset=tf.data.Dataset.from_tensor_slices((x_train,y_train))
valid_dataset=tf.data.Dataset.from_tensor_slices((x_test,y_test))
#把给定的元组、列表和张量等数据进行特征切片。切片的范围是从最外层维度开始的。如果有多个特征进行组合,那么一次切片是把每个组合的最外维度的数据切开,分成一组一组的。
#构建一个DNN模型g(f(x))
model=tf.keras.Sequential(
[
tf.keras.layers.Dense(64,activation='relu'),#64个节点
tf.keras.layers.Dense(32,activation='relu'),#32个节点
tf.keras.layers.Dense(16,activation='relu'),
tf.keras.layers.Dense(1,activation='sigmoid'),#最后一层1个节点,防止出现梯度弥散
])
model.compile(
loss='binary_crossentropy',
optimizer='adam',#相当于一个缓冲
metrics=['accuracy'])
train_dataset=train_dataset.shuffle(buffer_size=10000)
train_dataset=train_dataset.batch(40)
train_history=model.fit(train_dataset,
epochs=100,
validation_data=train_dataset,
verbose=2)
model.fit(train_dataset,epochs=20)
#epochs即:在数据集上迭代的次数,或总共遍历了多少次数据集。所以epoch就是遍历一次数据集。注意每个epoch包含了train loop和test loop。
#train loop是训练模型,使模型参数收敛至最佳。
#tset loop是为了检验模型的性能是否得到了提升。
结果:
Epoch 1/20
1/1 [==============================] - 0s 4ms/step - loss: 0.0109 - accuracy: 1.0000
--------------------------------------------------------------------------------------------------------------------------
Epoch 19/20
1/1 [==============================] - 0s 4ms/step - loss: 0.0058 - accuracy: 1.0000
Epoch 20/20
1/1 [==============================] - 0s 4ms/step - loss: 0.0057 - accuracy: 1.0000















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









