






python调用everything批量查找表格中的文件名在磁盘中是否存在
介绍
Everything的Http服务器提供了网页支持,我们通过解析网页获取查找信息,从而批量处理数据。
Everything 配置
首先需要打开Everthing 的Http服务器配置,只需要启动该配置并记住端口号即可,配置方式:打开everything-工具-选项-Http服务器,无需设置用户名和密码
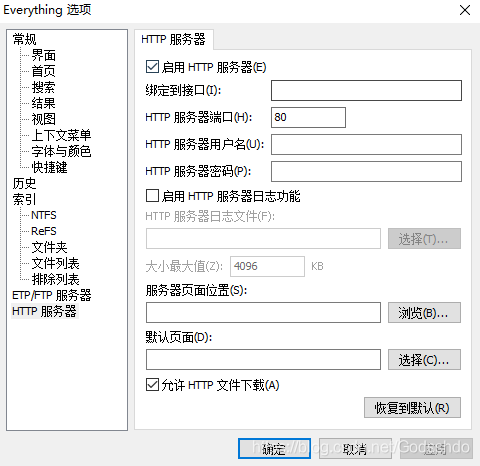
输入网址:ip+:+端口号,能够打开everthing搜索即可

参考:https://www.voidtools.com/zh-cn/support/everything/http/
使用openpyxl读写文件
读文件
import openpyxl
wb = openpyxl.load_workbook('sample_file.xlsx')
sheet = wb.active
x1 = sheet['A1']
x2 = sheet['A2']
#using cell() function
x3 = sheet.cell(row=3, column=1)
print("The first cell value:", x1.value)
print("The second cell value:", x2.value)
print("The third cell value:", x3.value)
写文件
from openpyxl import load_workbook
wb = load_workbook(r'C:\Users\DEVANSH SHARMA\Desktop\demo.xlsx')
sheet = wb.active
sheet['A1'] = 'Devansh Sharma'
sheet.cell(row=2, column=2).value = 5
wb.save(r'C:\Users\DEVANSH SHARMA\Desktop\demo.xlsx')
BeautifulSoup的使用
创建 beautifulsoup 对象
soup = BeautifulSoup(html,'lxml') #创建 beautifulsoup 对象
soup.find_all的用法
- 查找标签
soup.find_all('tag')
- 查找文本
soup.find_all(text='text')
- 根据id查找
soup.find_all(id='tag id')
- 使用正则
soup.find_all(text=re.compile('your re')), soup.find_all(id=re.compile('your re'))
- 指定属性查找标签
soup.find_all('tag', {'id': 'tag id', 'class': 'tag class'})
完整代码
import openpyxl
import requests
from bs4 import BeautifulSoup
ip='localhost'
wb = openpyxl.load_workbook(r"E:\zr\书籍.xlsx")
sheet = wb.active
try:
for row in range(2,245):
title = sheet.cell(row, 1).value
lookup = title.find('(')
title=title[0:lookup] if lookup!=-1 else title
lookup = title.find('(')
title=title[0:lookup] if lookup!=-1 else title
lookup = title.find(':')
title=title[0:lookup] if lookup!=-1 else title
lookup = title.find(':')
title=title[0:lookup] if lookup!=-1 else title
lookup = title.find('―')
title=title[0:lookup] if lookup!=-1 else title
lookup = title.find('—')
title=title[0:lookup] if lookup!=-1 else title
lookup = title.find(' ')
title=title[0:lookup] if lookup!=-1 else title
#print(title)
request = requests.get("http://" + ip + "/?search=" + title)
content = request.text
#print(content)
soup = BeautifulSoup(content,'html.parser')
result=soup.find_all('p',{'class':'numresults'})
txt = result[0].string
if(txt[0]=='0'):
sheet.cell(row, 6).value='wu'
else:
sheet.cell(row, 6).value='you'
finally:
wb.save('E:\zr\书籍.xlsx')















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









