







参考stackoverflow
假设有list of tuple
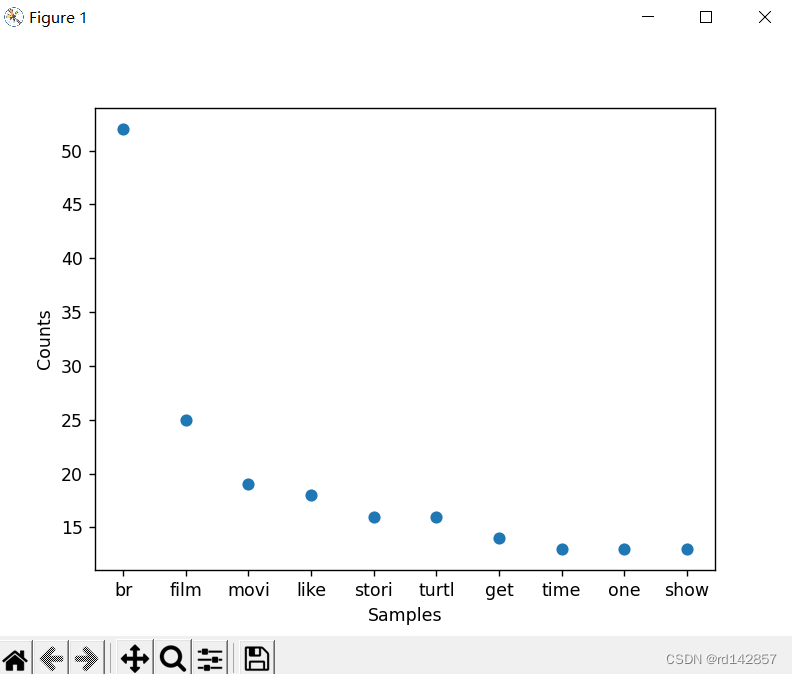
[('br', 52), ('film', 25), ('movi', 19), ('like', 18), ('stori', 16), ('turtl', 16), ('get', 14), ('time', 13), ('one', 13), ('show', 13)]
使用zip函数,
plt.scatter(*zip(*word_count.most_common(10)))
plt.xlabel('Samples')
plt.ylabel('Counts')
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









