







背景需求:
每年9月闵豆家园使用时,都会有老师问我为什么不给他们设置“X老师”的昵称?
因为我把员工转院设置时,明显感到姓氏重复率较高。都是“X老师”,不知道到底谁是谁,所以必须用全名来做区分。

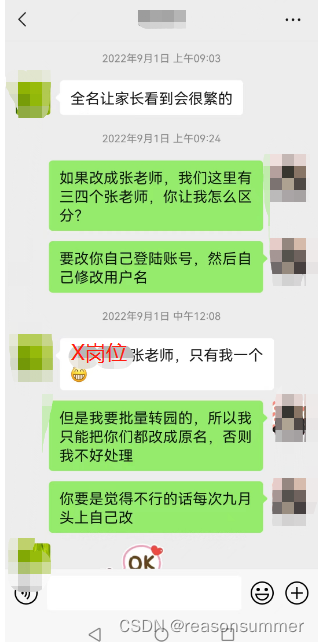
今天2月25日,又有老师来问名字设置的问题。我突然产生好奇:我们园所里到底那些姓氏的重复率很高呢?
PS:已知的重姓现象:
1、中S班的退休老师姓夏,而即将顶岗的也是夏老师。两位都是夏老师。
2、中O班的两位老师都姓朱,大朱老师、小朱老师。
材料准备:
1、下载所有员工名单

2、写代码。py
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import xlrd
# 读取列
worksheet = xlrd.open_workbook(r'D:\test\02办公类\08姓氏最多的人\20230227XXX幼儿园教职工列表 - 副本.xls')
sheet_names= worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
cols = sheet.col_values(1) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
print(cols)
print(cols[1:]) # 不要第1行的标题的文字
print(type(cols[1])) #查看数据类型
# name_list = ["张三", "李四", "周瑜", "张三", "张三", "李四", "王五", "张飞", "张飞", "周瑜"]
#提取第一个姓(目前没有复姓,所以都取第一个姓)
b = []
for i in cols[1:]: # 第1行的教职工姓名不要,从1(第二行开始计数)
a=i[0]
b.append(a)
# print(b) ["张", "李", "周", "张", "张", "李”]
name_dict = {}
for name in b:
# 取出字典中的所有keys值
key_list = name_dict.keys()
# key_list = name_dict[0]
# print(key_list)
if name in key_list:
name_dict[name] += 1
else:
name_dict[name] = 1
# # 根据字典中的value值进行倒序排序
name_dict = sorted(name_dict.items(), key=lambda item:item[1], reverse=True)
print(name_dict )
d=[]
for c in range(0,len(name_dict)):
aa=name_dict[c][0]
bb=name_dict[c][1]
print(aa,bb)
3、结果展示

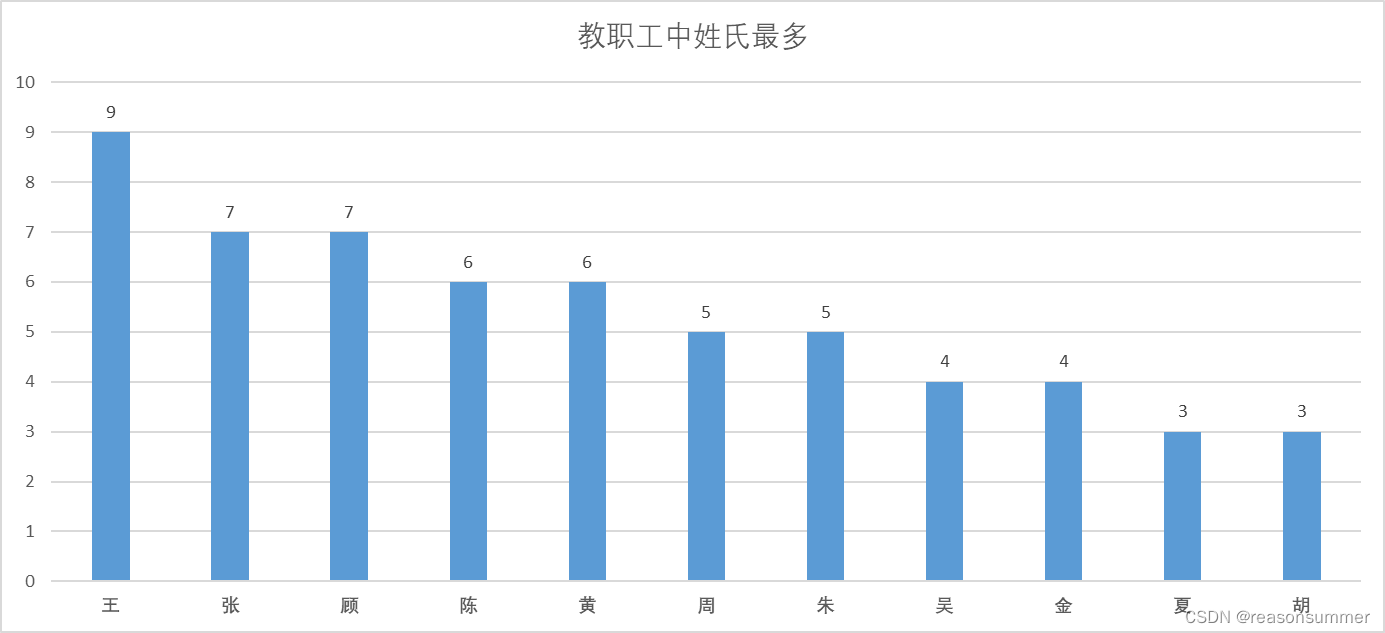
统计后发现:

教工中“王”姓工作人员最多9人。
“张”“顾”7人、
“陈“”黄“6人、
”周“”朱“5人、
”吴“”金“4人。
”夏“”胡“3人、
”沈、郑、冯、李、马、钱、管、刘、俞、方、陆、程“2人
其余都是单人单姓
由于重姓氏的比例较高(≥3人的重复姓氏如下),因此,设置全名是非常必要的。
(可以自己手动修改,把昵称名字改回来,但本名一定要保留,这样便于RPA程序能够把闵豆APP的真名复制到昵称里,读取EXCLE表格自动化把职工转园区,提高工作效率)
后续思考
中S班孩子的姓氏最多呢?
近年来一直是机动岗、随机进中大班,记忆孩子名字学号是很重要的事。由于很多情况下,我记不住全名,会习惯性喊——“X同学”
前年带的大班有7位张同学,3位“张X阳”(他们属羊),去年带的大班有两个“胡”同学,到现在我依旧容易喊错名字。重姓、重音多,记忆起来就非常费力。识别就会有难度。
所以通过数量统计,预先知道哪些孩子是重复姓氏,就可以有针对性辨认2人3人之间的外貌、性别、性格的差异,强化记忆其姓名。1人1个姓氏,记忆起来相对方便。
同姓:李王刘陈胡 2-3人。

















 1918
1918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











