







结论
我在使用python开发工具时遇到了报错:
ValueError: If using all scalar values, you must pass an index
我采取的解决方法是把报错的数据强制转换为str型。
下面记录了我的代码与针对问题的调查过程。
问题分析
我需要用python实现的功能是从.xlsm文件中读取某些单元格的数据,再以表格形式输出为.csv文件。代码如下:
# 使用openpyxl的load_workbook方法读取.xlsm文件的数据
filePath = "D:\\Test\\Sample_SrcData.xlsm"
workbook = load_workbook(filename=filePath,data_only=True)
# 从指定sheet页中提取指定单元格的数据
sheet = workbook["SampleSheet"]
UserName= sheet["B6"].value
Department = sheet["C6"].value
Result = sheet["D6"].value
workbook.close()
# 使用Pandas的DataFrame方法输出表格,存为csv文件
line1={'User':UserName, 'Department':Department, 'Result':Result}
df = pd.DataFrame(line1)
outputPath = "D:\\Test\\output.csv"
df.to_csv(outputPath, mode='a',index=False,header=True)报错发生在df = pd.DataFrame(line1)这一行。对此我的理解是,在创建DataFrame的时候,某个元素的数据类型有问题。
通过调试代码,我定位到了“D6”这一单元格,它在源文件中是下拉框形式的。下图为一个举例用的假数据:
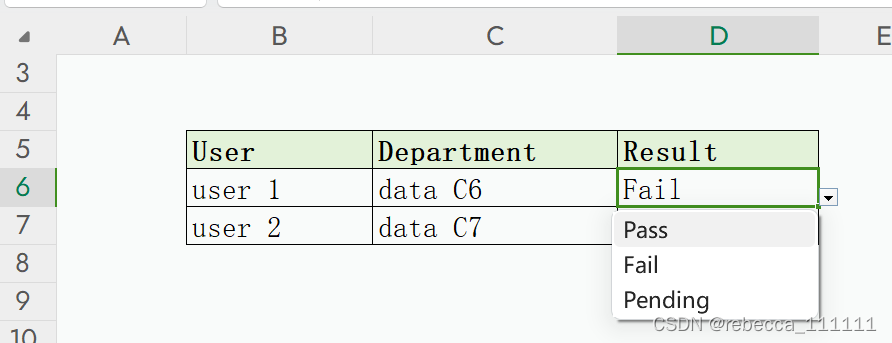
我尝试用type()确认数据类型:
print(type(sheet["C6"].value)) #C6的数据是OK的
print(type(sheet["D6"].value)) #D6的数据报错结果终端输出了两个<class 'str'>。
但是这给了我灵感,我可以在构建数据的时候,把D6这一格的元素强制转换为str型,再通过DataFrame操作表格。
修改前后的代码对比如下:
【Before】
line1={'User':UserName, 'Department':Department, 'Result':Result}
【After】
line1={'User':UserName, 'Department':Department, 'Result':[str(Result)]}
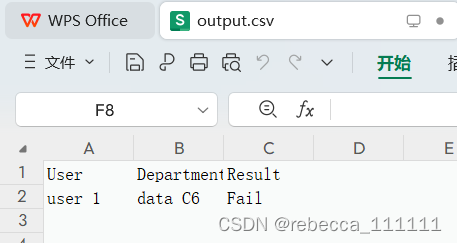
最终问题得到了解决,成功导出了csv文件。















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









