







前言
这次我们开始讲述动态规划的具体思想,并给出一些具体的案例进行分析,比如这边博客中的矩阵链,还有后续的博客中的背包问题,二分搜索树的构建等问题。
为什么要使用dp
我们都见过斐波那契数列这个例子,也都知道这个问题有一个递归的算法,但是有没有真正的分析过这个例子?
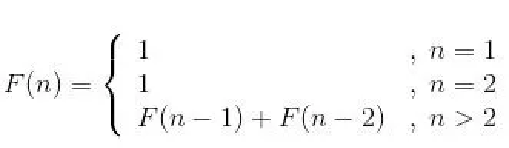
我们来计算一个F(8),首先我们需要给出F(7)和F(6),调用递归函数来求解这两个数;
求F(7)的过程中,我们需要F(6)和F(2),但是求F(5)的函数调用还没开始(或者是已经结束,变量出栈找不到了),导致计算机只能重新进行计算F(5);
算F(5)同理,我们也是需要重复计算一些数值。
当我们用树画出来,就长成了这个样子:

可以看到,我们进行了很多次的重复计算,而且是自变量越小被计算的次数越多。
有没有解决的办法
办法是有的,既然是重复计算,那么我们为什么不直接找一个数组将从F(8)到F(1)存起来呢?
这个就是dp的具体思想,将我们遇到过的子问题进行存储,避免了重复的计算。
什么样的问题可以使用dp
首先,这个问题是能被拆分成一些相同类型,但是规模变小的子问题(和分治有一点像)
另外这些子问题是会被重复调用的,比如上面的F(7)我们要算两次,F(1)就不知道多少次了。
最后,但是是最重要的一点,我们一定要证明整体最优则子问题一定是最优的,也就是整体的最优解一定是和局部最优解相关(可能是求和,可能是求和之后还需要加一些东西)。
(如果子问题不是最优,我们在合并的过程中很难保证整体最优,比如01背包,如果子问题最优的和整体最优没有关系,那么我们怎么进行计算)
说白了,其实就是两个东西,优化子结构和重叠子问题。(这也保证了有子问题的存在)
怎么使用
首先,我们是自顶向下进行分析的,但是在计算的过程中,我们一定是自底向上处理问题的,因为我们需要子问题的值来确定整体问题的值。
(比如F(6)、F(7)不知道,我们怎么可能算出来F(8)?)
(和递归法对比一下,递归就是自顶向下的方式,就有很多重复的操作)
所以,我们就需要先给出边界条件的值(比如Fibonacci的F(1)、F(2)),然后顺藤摸瓜,找到最后我们想要的值就行了。
另外,因为是需要存储,所以我们需要创建一个数组(维度不一定,需要看问题,这里一维数组即可)。
一点点扩展
提到dp就不得不提一下滚动数组的问题了,这也是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









