






介绍
大型语言模型,如OpenAI的GPT-4或谷歌的PaLM,已经席卷了人工智能世界。然而,大多数公司目前还没有能力培训这些模型,并且完全依赖于少数几家大型科技公司作为技术提供商。
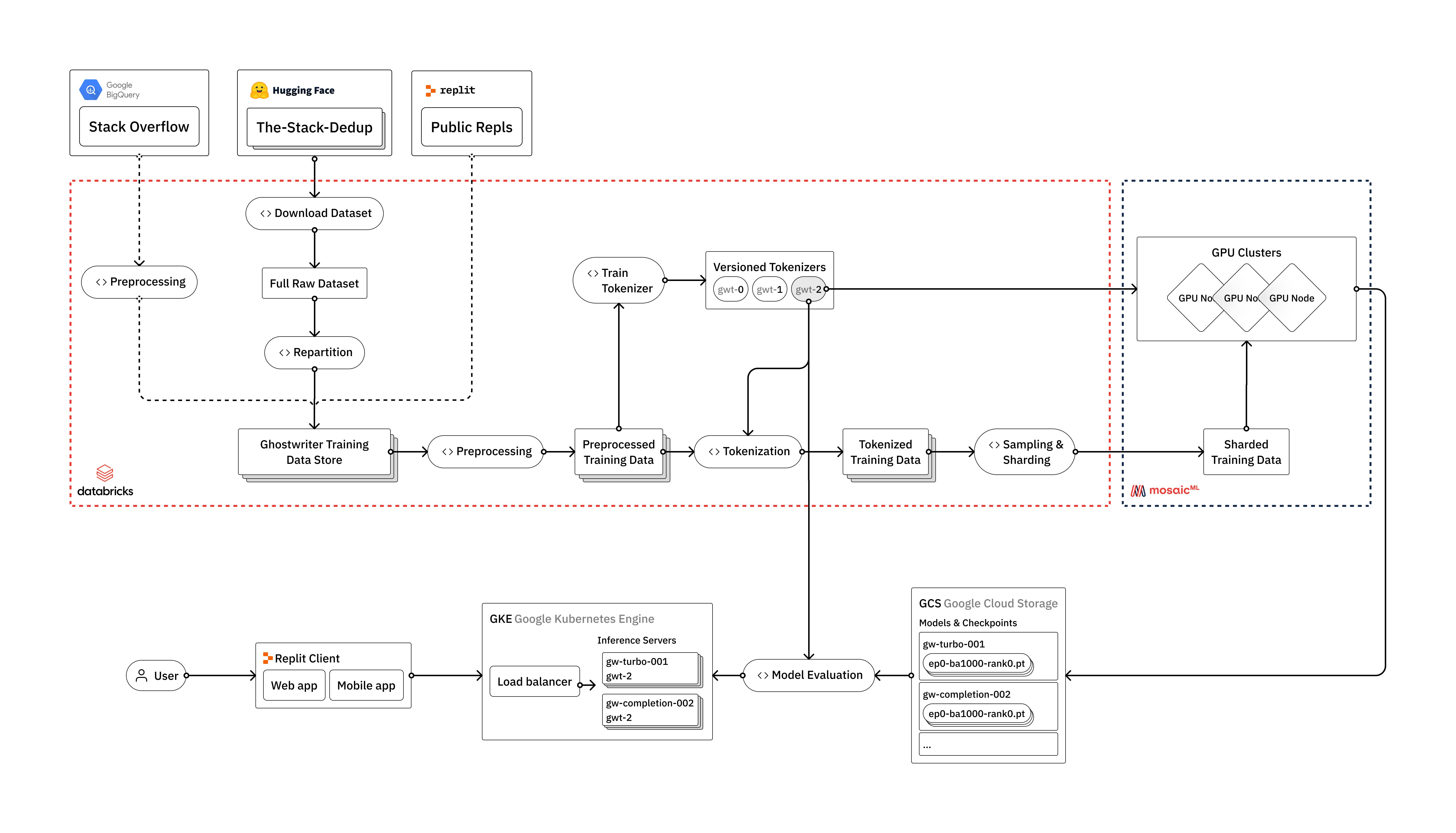
在这篇博客文章中,我们将概述如何训练LLM,从原始数据到在用户体验生产环境中的部署。我们将讨论沿途面临的工程挑战,以及我们如何利用我们认为构成现代LLM堆栈的供应商:Databricks、Hugging face和MosaicML。
虽然我们的模型主要用于代码生成的用例,但所讨论的技术和经验教训适用于所有类型的LLM,包括通用语言模型。
为什么要培训自己的LLM?
“为什么要训练自己的模型?”公司可能有很多原因决定训练自己的LLM,从数据隐私和安全到加强对更新和改进的控制。
我们主要关注定制、减少依赖性和成本效率。
- 自定义。通过训练自定义模型,我们可以根据自己的特定需求和要求进行定制,包括GPT-4等通用模型甚至Codex等代码特定模型无法很好地涵盖的平台特定功能、术语和上下文。例如,我们的模型经过培训,能够更好地使用特定web语言,包括Javascript React(JSX)和Typescript Reactive(TSX)。
- 减少依赖性。虽然我们将始终根据手头的任务使用正确的模型,但我们相信,减少对少数人工智能提供商的依赖是有好处的。
- 成本效益。尽管成本将继续下降,但LLM在全球开发者社区中的使用成本仍然高昂得令人望而却步。我们训练的定制模型更小、更高效,并且可以以大幅降低的成本托管。
数据管道
LLM需要大量数据进行训练。培训他们需要构建强大的数据管道,这些管道经过高度优化,但足够灵活,可以轻松包含公共和专有数据的新来源。
堆栈
我们从The Stack开始,它是我们的主要数据源,可在hugging face获取,是数据集和预训练模型的一个很好的资源。它们还提供了多种有用的工具作为Transformers库的一部分,包括用于标记化、模型推断和代码评估的工具。
在消除重复之后,数据集的1.2版包含大约2.7 TB许可的源代码,这些源代码是用350多种编程语言编写的。
transformers库在抽象模型训练相关的许多挑战方面做得很好,包括大规模处理数据。然而,我们发现它对我们的过程来说是不够的,因为我们需要对数据进行额外的控制,以及以分布式方式处理数据的能力。
llm-训练
数据处理
当需要更高级的数据处理时,我们使用databricks建造我们的pipelines。这种方法还使我们能够很容易地将其他数据源(如副本或堆栈溢出)引入到我们的流程中,我们计划在未来的迭代中这样做。
第一步是从Hugging Face下载原始数据。我们使用Apache Spark跨每种编程语言并行化数据集构建器进程。然后,我们对数据进行重新分区,并将其重写为镶木地板格式,并使用优化的设置进行下游处理。
接下来,我们开始清理和预处理数据。通常,对数据进行重复数据消除并修复各种编码问题很重要,但the Stack已经使用Kocetkov等人(2022)中概述的近重复数据消除技术为我们做到了这一点。然而,一旦我们开始将复制数据引入我们的管道,我们就必须重新运行重复数据消除过程。这就是使用Databricks这样的工具的好处所在,我们可以将Stack、Stackoverflow和Replit数据视为更大数据池中的三个源,并根据需要在下游流程中使用它们。
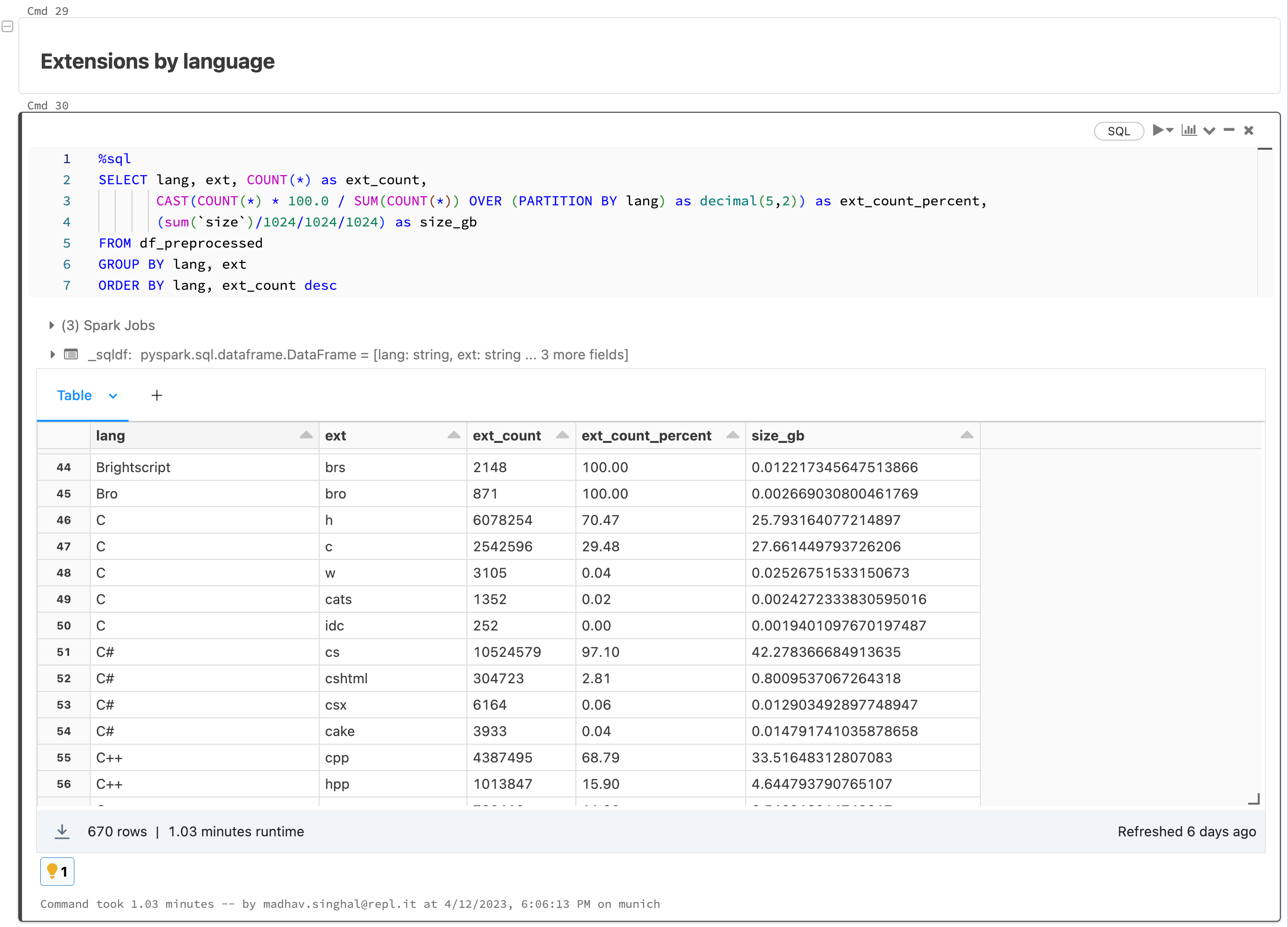
使用Databricks的另一个好处是,我们可以对底层数据运行可伸缩且易于处理的分析。我们对数据源运行所有类型的汇总统计数据,检查长尾分布,并诊断流程中的任何问题或不一致。所有这些都是在Databricks笔记本电脑中完成的,它也可以与MLFlow集成,以跟踪和复制我们一路上的所有分析。这一步骤相当于对我们的数据进行定期x光扫描,也有助于告知我们预处理的各个步骤。
对于预处理,我们采取以下步骤:
- 我们通过删除任何个人身份信息(PII)来匿名化数据,包括电子邮件、IP地址和密钥。
- 我们使用许多启发式方法来检测和删除自动生成的代码。
- 对于语言子集,我们使用标准语法分析器删除无法编译或无法解析的代码。
- 我们根据平均行长度、最大行长度和字母数字字符的百分比筛选出文件。
背包式笔记本the sta1k
标记化和词汇训练
在标记化之前,我们使用模型训练中使用的相同数据的随机子样本来训练我们自己的自定义词汇表。自定义词汇表允许我们的模型更好地理解和生成代码内容。这将提高模型性能,并加快模型训练和推理。
这一步是流程中最重要的一步,因为它用于流程的所有三个阶段(数据管道、模型训练、推理)。它强调了为您的模型培训过程建立一个强大且完全集成的基础架构的重要性。
我们计划在未来的博客文章中深入探讨标记化。从高层来看,我们必须考虑的一些重要因素是词汇表大小、特殊标记和哨兵标记的保留空间。
一旦我们训练了我们的自定义词汇,我们就会对数据进行标记。最后,我们构建了我们的训练数据集,并将其写入一个切分格式,该切分格式经过了优化,可用于输入模型训练过程。
模特培训
我们使用马赛克ML。在之前部署了我们自己的培训集群后,我们发现MosaicML平台给我们带来了一些关键好处。
- 多个云提供商Mosaic使我们能够利用来自不同云提供商的GPU,而无需设置帐户和所有所需集成的开销。
- LLM培训配置。Composer库有许多经过优化的配置,用于训练各种模型和不同类型的训练目标。
- 托管基础架构。他们的托管基础架构为我们提供了协调、效率优化和容错(即从节点故障中恢复)。
在确定模型的参数时,我们考虑了模型大小、上下文窗口、推理时间、内存占用等之间的各种权衡。较大的模型通常提供更好的性能,并且更有能力进行转移学习。然而,这些模型对训练和推理都有较高的计算要求。后者对我们来说尤其重要。Replit是一个云本地IDE,其性能感觉就像一个桌面本地应用程序,因此我们的代码完成模型需要闪电般快速。因此,我们通常会错误地选择内存占用较小、延迟推断较低的较小模型。
除了模型参数外,我们还可以从各种培训目标中进行选择,每个目标都有自己独特的优缺点。最常见的训练目标是下一个标记预测。这通常对代码完成很好,但没有考虑文档中下游的上下文。这可以通过使用“中间填充”目标来缓解,其中文档中的标记序列被屏蔽,模型必须使用周围的上下文来预测它们。另一种方法是UL2(无监督潜在语言学习),它将用于训练语言模型的不同目标函数框定为去噪任务,其中模型必须恢复给定输入的缺失子序列。

损耗曲线
一旦我们决定了模型配置和培训目标,我们就在GPU的多节点集群上启动培训运行。我们可以根据正在训练的模型的大小以及完成训练过程的速度来调整为每次运行分配的节点数。运行一个大型GPU集群的成本很高,所以我们必须尽可能高效地利用它们。我们密切监控GPU利用率和内存,以确保我们从计算资源中获得最大可能的利用率。
我们使用权重和偏差来监控培训过程,包括资源利用率和培训进度。我们监控损失曲线,以确保模型在培训过程的每个步骤中都能有效学习。我们还关注损失峰值。这些是损失值的突然增加,通常表明基础训练数据或模型架构存在问题。由于这些事件通常需要进一步调查和潜在调整,我们在流程中强制执行数据确定性,因此我们可以更容易地重现、诊断和解决任何此类损失峰值的潜在来源。
评价
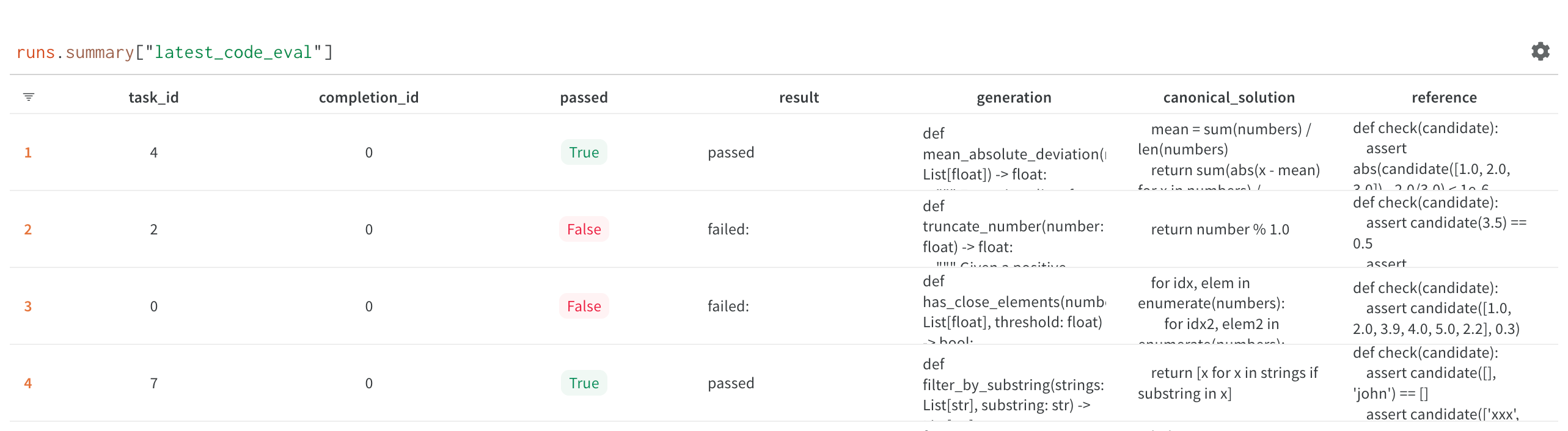
为了测试我们的模型,我们使用HumanEval框架的变体,如Chen等人(2021)。我们使用该模型生成一个给定函数签名和docstring的Python代码块。然后,我们对生成的函数运行测试用例,以确定生成的代码块是否按预期工作。我们运行多个样本并分析相应的通过@K数字。
这种方法最适合Python,有现成的评估器和测试用例。但由于Replit支持许多编程语言,我们需要评估各种其他语言的模型性能。我们发现这很难做到,而且没有被广泛采用的工具或框架能够提供全面的解决方案。两个具体的挑战包括在任何编程语言中创造一个可复制的运行时环境,以及在没有广泛使用的测试用例标准(例如HTML、CSS等)的情况下,编程语言的模糊性。幸运的是,“任何编程语言中的可复制运行时环境”都是我们在Replit上的特色!我们目前正在构建一个评估框架,允许任何研究人员插入并测试他们的多语言基准测试。我们将在未来的博客文章中对此进行讨论。
人类评估结果
部署到生产
一旦我们对模型进行了培训和评估,就可以将其部署到生产中了。如前所述,我们的代码完成模型应该感觉很快,请求之间的延迟非常低。我们使用NVIDIA的FasterTransformer和Triton Server加速推理过程。FasterTransformer是一个实现基于变压器的神经网络推理的加速引擎的库,Triton®声波风廓线仪是一个稳定快速的推理服务器,配置简单。这种组合为我们在变压器模型和底层GPU硬件之间提供了一个高度优化的层,并允许对大型模型进行超快速分布式推理。
在将我们的模型部署到生产中后,我们可以使用Kubernetes基础设施自动缩放模型以满足需求。尽管我们在之前的博客文章中讨论过自动缩放,但值得一提的是,托管推理服务器会带来一系列独特的挑战。这些包括大型工件(即模型权重)和特殊硬件要求(即不同的GPU大小/计数)。我们设计了部署和集群配置,以便能够快速可靠地发货。例如,我们的集群旨在解决各个区域的GPU短缺问题,并寻找最便宜的可用节点。
在我们将模型放在实际用户面前之前,我们喜欢自己测试它,并了解模型的“振动”。我们之前计算的HumanEval测试结果很有用,但没有什么比使用模型来了解它更好的了,包括它的延迟、建议的一致性和一般的帮助性。将模型放在Replit员工面前就像轻触开关一样简单。一旦我们对它感到满意,我们就会打开另一个开关,并将其推出给其他用户。
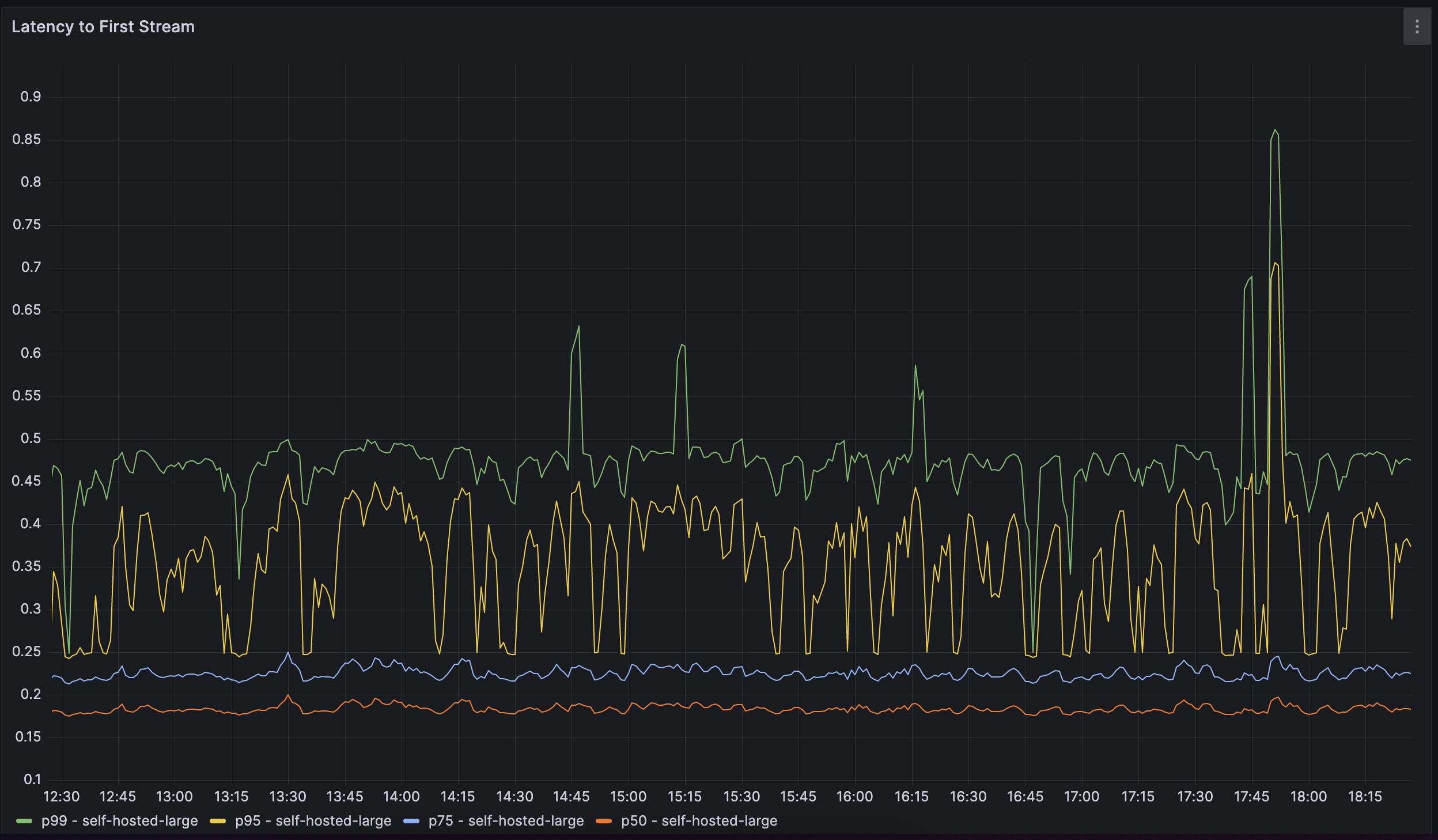
监测
我们继续监控模型性能和使用指标。对于模型性能,我们监控诸如请求延迟和GPU利用率等指标。对于用法,我们跟踪代码建议的接受率,并将其分解为多个维度,包括编程语言。这也使我们能够对不同的模型进行A/B测试,并获得一个用于将一个模型与另一个模型进行比较的定量度量。
反馈和迭代
我们的模型培训平台使我们能够在不到一天的时间内将原始数据转换为生产中部署的模型。但更重要的是,它允许我们训练和部署模型,收集反馈,然后根据反馈快速迭代。
对于我们的流程来说,对底层数据源、模型培训目标或服务器架构中的任何更改保持健壮性也很重要。这使我们能够在快速发展的领域中利用新的进步和功能,每天似乎都会带来新的、令人兴奋的公告。
接下来,我们将扩展我们的平台,使我们能够使用Replit本身来改进我们的模型。这包括基于人的反馈的强化学习(RLHF)等技术,以及使用从回馈中收集的数据进行教学调整。
接下来的步骤
虽然我们取得了很大进展,但我们仍处于培训LLM的早期阶段。我们还有很多改进要做,还有很多难题要解决。随着语言模型的不断进步,这一趋势只会加速。与数据、算法和模型评估相关的一系列新挑战将持续存在。
如果您对培训LLM的许多工程挑战感到兴奋,我们很乐意与您交谈。我们喜欢反馈,也很乐意听到您关于我们遗漏了什么以及您会采取什么不同的做法。
我们一直在寻找复制人工智能团队中有才华的工程师、研究人员和建设者。请务必查看我们的事业第页。如果你看不到合适的角色,但认为自己可以做出贡献,请联系我们;我们很高兴收到你的来信。

















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









