







题目:TransA: An Adaptive Approach for Knowledge Graph Embedding
1 问题
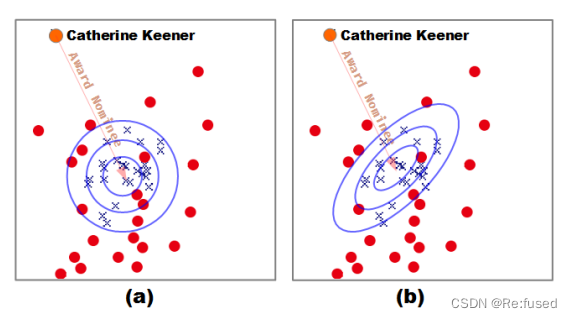
本论文主要关注的问题是,距离的计算方式,一个自适应的权重矩阵。基于TransE的模型其评分函数采用欧几里得距离,不同维度的距离重要程度一样,就导致一些不太起作用的维度由于其距离比较大,导致产生的距离比较大,产生错误的评分,影响预测的结果。因此提出TransA模型,距离计算不再采用欧式距离,而实采用马式距离,不同维度根据其权重进行体现维度的重要性,将数据的维度进行压缩。下图即可体现欧式距离和马式距离的区别。
对于自适应矩阵,则采用 W r W_r Wr矩阵根据 ∣ h + r − t ∣ |h+r-t| ∣h+r−t∣进行计算,能够根据不同的三元组进行计算,实现自适应状态,同时明显缩减参数的复杂度。
2 模型
常规的Trans系列的模型的不同点主要在其h, r, t的映射空间不同,其空间不同导致Trans系列比较丰富,包括TransH, TransR等等模型,h, r, t产生的过程不同, 然后采用相同的评分函数,基于一范式,或者二范式的评分函数,也就是求解距离的公式。
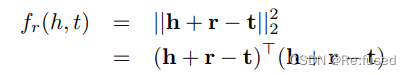 复杂,或者更加合理,依据权重计算记录的公式马式距离。而且采取自适应的马式距离。
复杂,或者更加合理,依据权重计算记录的公式马式距离。而且采取自适应的马式距离。
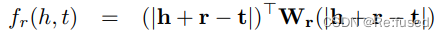
其中
W
r
W_r
Wr为一个对称的矩阵,所谓的自适应性就体现在
W
r
W_r
Wr的产生上,权重矩阵
W
r
W_r
Wr为一个非负的矩阵。对于h+r和t之间的距离,我们采取绝对值的形式,其有两个好处:
- 一方面,只有在 W r W_r Wr的所有项都是非负的条件下,绝对运算符才能使得分函数成为一个定义良好的范数
- 另一方面,在几何中,负值或正值表示向下或向上的方向,而在我们的方法中,我们不考虑这个因素。
对于 W r W_r Wr其公式为:
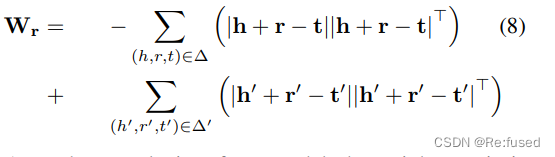
3 损失函数
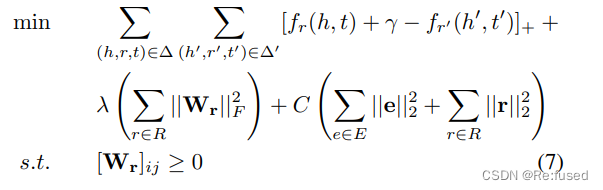
损失函数中加入对
W
r
,
e
,
r
W_r, e,r
Wr,e,r的限制。
4 代码
源码:TransA
class TransA(nn.Module):
def __init__(self, entityNum, relationNum, embeddingDim, margin=1.0, L=2, lamb=0.01, C=0.2):
super(TransA, self).__init__()
assert (L==1 or L==2)
self.model = "TransE"
self.entnum = entityNum
self.relnum = relationNum
self.enbdim = embeddingDim
self.margin = margin
self.L = L
self.lamb = lamb
self.C = C
self.entityEmbedding = nn.Embedding(num_embeddings=entityNum,
embedding_dim=embeddingDim)
self.relationEmbedding = nn.Embedding(num_embeddings=relationNum,
embedding_dim=embeddingDim)
self.distfn = nn.PairwiseDistance(L)
'''
Normalize embedding
'''
def normalizeEmbedding(self):
pass
'''
Reset Wr to zero
'''
def resetWr(self, usegpu, index):
if usegpu:
self.Wr = torch.zeros((self.relnum, self.enbdim, self.enbdim)).cuda(index)
else:
self.Wr = torch.zeros((self.relnum, self.enbdim, self.enbdim))
def retEvalWeights(self):
return {"entityEmbed": self.entityEmbedding.weight.detach().cpu().numpy(),
"relationEmbed": self.relationEmbedding.weight.detach().cpu().numpy(),
"Wr": self.Wr.detach().cpu().numpy()}
'''
Calculate the Mahalanobis distance weights
'''
def calculateWr(self, posX, negX):
size = posX.size()[0]
posHead, posRel, posTail = torch.chunk(input=posX,
chunks=3,
dim=1)
negHead, negRel, negTail = torch.chunk(input=negX,
chunks=3,
dim=1)
posHeadM, posRelM, posTailM = self.entityEmbedding(posHead), \
self.relationEmbedding(posRel), \
self.entityEmbedding(posTail)
negHeadM, negRelM, negTailM = self.entityEmbedding(negHead), \
self.relationEmbedding(negRel), \
self.entityEmbedding(negTail)
errorPos = torch.abs(posHeadM + posRelM - posTailM)
errorNeg = torch.abs(negHeadM + negRelM - negTailM)
del posHeadM, posRelM, posTailM, negHeadM, negRelM, negTailM
self.Wr[posRel] += torch.sum(torch.matmul(errorNeg.permute((0, 2, 1)), errorNeg), dim=0) - \
torch.sum(torch.matmul(errorPos.permute((0, 2, 1)), errorPos), dim=0)
'''
This function is used to calculate score, steps follows:
Step1: Split input as head, relation and tail index array
Step2: Transform index array to embedding vector
Step3: Calculate Mahalanobis distance weights
Step4: Calculate distance as final score
'''
def scoreOp(self, inputTriples):
head, relation, tail = torch.chunk(input=inputTriples,
chunks=3,
dim=1)
relWr = self.Wr[relation]
head = torch.squeeze(self.entityEmbedding(head), dim=1)
relation = torch.squeeze(self.relationEmbedding(relation), dim=1)
tail = torch.squeeze(self.entityEmbedding(tail), dim=1)
# (B, E) -> (B, 1, E) * (B, E, E) * (B, E, 1) -> (B, 1, 1) -> (B, )
error = torch.unsqueeze(torch.abs(head+relation-tail), dim=1)
error = torch.matmul(torch.matmul(error, torch.unsqueeze(relWr, dim=0)), error.permute((0, 2, 1)))
return torch.squeeze(error)
def forward(self, posX, negX):
size = posX.size()[0]
self.calculateWr(posX, negX)
# Calculate score
posScore = self.scoreOp(posX)
negScore = self.scoreOp(negX)
# Calculate loss
marginLoss = 1 / size * torch.sum(F.relu(input=posScore-negScore+self.margin))
WrLoss = 1 / size * torch.norm(input=self.Wr, p=self.L)
weightLoss = ( 1 / self.entnum * torch.norm(input=self.entityEmbedding.weight, p=2) + \
1 / self.relnum * torch.norm(input=self.relationEmbedding.weight, p=2))
return marginLoss + self.lamb * WrLoss + self.C * weightLoss
5 总结
创新点主要在于以下两点:
- 采用相对复杂的马氏损失函数
- 设置自适应权重矩阵














 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









