









List源码解读
为了更好地理解源码,先列出一些重要的接口和类的作用:
- Collection接口:定义了简单的操作规范:增删查以及判断与指定集合的包含和处理一些交集的方法;注意的一点是1.8之后增加了一些方法,比如有removeIf方法等。
- List接口:定义了简单的增删查规范(基本上Collection接口中操作方法在这里都有);相比Collection增加了(1.8)基于Comparator的sort方法;还有get、set、indexOf、subList,(1.9)还有of方法,可以创建常量列表。
- RandomAccess接口:是一个空的接口,因此这个接口是一个Mark,假如一个List继承它,就标识着这个List的算法允许快速访问List中的元素。
- AbstractList类:通过下面的图,我们可以了解到它的root是Collection、List;因此,其中的规范都是那些操作方法以及一些简单的实现。
一.ArrayList
先贴上一个继承图:

通过这个图,我们可以看到Arralist继承抽象列表类,间接实现了List接口、Collection接口、以及Iterable接口。好了,接下来就解析一下ArrayList的内部实现是怎样的,首先,我们第一步要了解的就是内部的结构,贴出这个类的内部结构图:
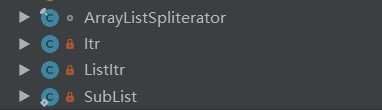
通过内部结构,可以看到有四个内部类,这四个类会在接下来的解析中讲到,当然,首先要讲的当然是ArrayList自身的属性还有方法实现啦!
1.底层实现
顾名思义,ArrayList-数组列表,底层实现就应该是数组。以下列出它的属性,注意注释:
/**
* 默认初始容量为10
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 用于空实例的共享空数组实例。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 共享空数组实例,用于默认大小的空实例。我们
* 将其与EMPTY_ELEMENTDATA区分开来,以了解何时膨胀多少
* 添加第一个元素。
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 存储ArrayList元素的数组缓冲区。
* ArrayList的容量是这个数组缓冲区的长度。任何
* 使用elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA清空ArrayList
* 将在添加第一个元素时扩展为DEFAULT_CAPACITY。
* transient保证该底层数组是不支持序列化的。
*/
transient Object[] elementData; // 非私有以简化嵌套类访问
/**
* ArrayList的大小(它包含的元素的数量)。
* 采用这个字段记录长度,可以在直接获取长度时候实现O(1)
*/
private int size;
通过上述的属性,我们已经了解了一些信息,比如默认创建的数组列表大小就是10,且一个刚创建的空的会指向一个常量空的数组。
2.操作实现
*接下来就该讲讲数组列表的操作方法是怎么实现的,以下可能会列出一些代码,由于JDK版本不同或者说迭代快,一些部分可能会与读者的JDK源码不同,但是无关紧要,因为从整体上看,差别不大。*以下的解析分为两个部分,分别是:围绕增删查改操作来解析、一个是围绕内部类进行解析。
2.1围绕增删查改进行解析
1.add
什么都不说了,直接上代码:
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
/**
* 将指定元素插入其中的指定位置
* 列表。将当前位于该位置(如果有)的元素移动,并
* 右边的任何后续元素(将一个元素添加到它们的索引中)。
*
*/
public void add(int index, E element) {
//常规的范围检查
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if ((s = size) == (elementData = this.elementData).length)
//执行一个扩容操作。
elementData = grow();
//调用底层的数组复制。
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
elementData[index] = element;
size = s + 1;
}
从上述的增操作中,我们了解到有两种方式,一个是添加到列表的末尾、一个是添加到指定位置。接下来就围绕这两个方法进行解读:
/**
* 判断长度,看看是否需要增加一个元素的空间
* 执行添加,添加到末尾;
* 私有的,供内部调用。
*/
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
/**
* 最小值扩容
*/
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}
/**
* 逐个扩容
* @return 扩容后的列表
*/
private Object[] grow() {
return grow(size + 1);
}
//以上就是add涉及到的扩容操作,底层也是调用System.arraycopy
//创建新容量时会判断是否超过最大范围。
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
对以上的add()操作做一个总结:
- 默认添加是将元素添加到列表尾部;也可以实现指定索引添加(会覆盖)
- 添加过程会判断一些范围比如是否越界等,当前的列表如果已经满了,就会调用扩容方法,进行扩容
- 扩容的过程会判断一个是否超出最大长度、以及调用底层的System.arraycopy进行数据的迁移
2.set
直接上代码进行解析哈哈:
/**
* set在index不超过范围之内进行一个值的替代(覆盖)。
*/
public E set(int index, E element) {
Objects.checkIndex(index, size);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
set的比较简单,就是做一个简单的判断范围、以及新值代替老的value,并且返回被代替的value。
3.remove
/**
* 一个遍历判断对象相等进行快速移除
*/
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/**
* 移除列表中指定位置的元素。
* 将任何后续元素向左移动(从它们的元素中减去一个)
*/
public E remove(int index) {
Objects.checkIndex(index, size);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
//调用底层的。
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
/**
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
对remove的解析如上注解,总结如下:
- remove分为根据对象、索引进行移除
- 其中有fastRemove,直接调用底层的system.arraycopy进行一个删除元素前段与删除元素的后端内容做一个拼接
- 底层数组减少最后一位,达到一个释放过程
以下是做一个移除交集的操作:
public boolean removeAll(Collection<?> c) {
return batchRemove(c, false, 0, size);
}
boolean batchRemove(Collection<?> c, boolean complement,
final int from, final int end) {
Objects.requireNonNull(c);
final Object[] es = elementData;
final boolean modified;
int r;
// Optimize for initial run of survivors
for (r = from; r < end && c.contains(es[r]) == complement; r++)
;
if (modified = (r < end)) {
int w = r++;
try {
for (Object e; r < end; r++)
if (c.contains(e = es[r]) == complement)
es[w++] = e;
} catch (Throwable ex) {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
System.arraycopy(es, r, es, w, end - r);
w += end - r;
throw ex;
} finally {
modCount += end - w;
shiftTailOverGap(es, w, end);
}
}
return modified;
}
4.get
public E get(int index) {
Objects.checkIndex(index, size);
return elementData(index);
}
get的实现与set都是比较简单的,直接获取;围绕操作的解析到这里完成。
2.2围绕内部类进行解析
接下来将围绕内部类进行解析,与上面相同,很多内容的解析都是放在注释上,当然,每解析一部分内容会有一个总结
1.Itr
/**
* 优化版的AbstractList.Itr
* 采用内部的迭代器。
*/
private class Itr implements Iterator<E> {
int cursor; // 要返回的下一个元素的索引
int lastRet = -1; // 返回的最后一个元素的索引;找不到为-1
int expectedModCount = modCount;
Itr() {
}
/**
* 通过判断当前的光标与数组列表的长度,来判断是否有下一个元素;
*/
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
/**
* 特别注意这个地方:抛出并发修改的异常;
* 正常的话单纯一个用户进行调用是不会出错的;
* 但是,如果其它用户在这个遍历过程对该集合进行一个删减的操作,就会报错!
* 如果只是并发的读,是不会报错的。
*/
if (i >= elementData.length)
//修改了异常的参数。
throw new ConcurrentModificationException("happen exception while iterating the array list by iterator,due to write ops");
//移动光标到下一位
cursor = i + 1;
//用next遍历的最后一次返回的下标。
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int size = ArrayList.this.size;
int i = cursor;
if (i < size) {
final Object[] es = elementData;
if (i >= es.length)
throw new ConcurrentModificationException();
for (; i < size && modCount == expectedModCount; i++)
action.accept(elementAt(es, i));
// update once at end to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
基本上解析的过程就是注释中,这里只做一个总结:
- 这个Itr是一个优化版的迭代器,主要是通过光标cusor与最后一次访问的lastRet标记来做一个迭代;
- 用迭代器进行遍历,要注意一个线程安全问题,避免进行并发迭代修改,并发读是没有问题;
- 我们现在调用一个arralist.iterator()返回的迭代器就是这个优化版迭代器。
接下来就解析那个另外的迭代器:
2.ListItr
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
这个迭代器是继承上一个迭代器的,如果说有什么不同的话,就是增加了一个add、set操作;直接迭代过程进行一个列表元素的修改。
3.SubList
这个类是针对截取List的内部类。
/**
* 用了第二个内部类;
* 截断列表类,继承抽象列表,
* @param <E>
*/
private static class SubList<E> extends AbstractList<E> implements RandomAccess {
private final ArrayList<E> root;
private final SubList<E> parent;
private final int offset;
private int size;
}
之所以只是列出属性,不列出操作方法,是因为:我们可以看到这个类实现了RandomAccess,但是,并没有继承List或者说ArrayList,因此,它必须对那些操作方法进行重写,这其中很多是冗余代码。
总结:
- 它是一个内部类,主要处理截断列表。
- 其中自己实现了增删查改方法,但是存在与arraylist重复代码。
- 对一个arraylist截断之后返回的就是SubList的实例,而sublist实例支持嵌套截断。
对Arraylist的解析到此结束。
二.LinkedList
在讲完Arraylist之后,接下来要讲解的是LinkedList,顾名思义,即链式结构,那么链式结构与数组结构他们之间有哪些不同呢,以及链式结构的底层是如何实现的都会讲解,与之前的章节一样,很多内容会在注释上体现出来。

先贴上LinkedList的继承图,如上,我们可以看到基本与Arraylist无差,但是增加了一个Deque队列接口。与之前的讲解一样,先对陌生的接口和类进行了解:
- Deque接口:定义了自身的一套操作方法,如pop、offer等,还有就是实现Collection定义了自身的正向逆向迭代方法
- AbstractSequentialList类:定义了一个抽象的迭代方法,该方法根据根据索引位置进行迭代;基于这个迭代方法,定义了一些具有方法体的get、set,这些get、set、add都是基于特定索引位置的getset。因此,总结一下这个抽象类的作用:我们都知道ArrayList是可以根据index进行一些操作的;而LinkedList是链表,正常来说是没有指定index进行操作,而JAVA将之设计成与ArrayList有一样的能够根据index操作,就设计了这个抽象类,就让LinkedList继承它的这一套规范,从而拥有根据index进行操作的能力。
1.底层实现
*讲了那么多,我们该进入正题了,顾名思义,LinkedList的底层实现就应该是链式结构,链表,是数据结构的入门,同时,也是其它结构的基础。*说到链式结构,我们知道的好处就是:
- 操作简便
- 内存灵活
接下来就看看这个linkedList的具体实现吧。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
transient int size = 0;
/**
* Pointer to first node.
*/
transient Node<E> first;
/**
* Pointer to last node.
*/
transient Node<E> last;
}
这里定义了两个node节点,主要是为了后续的操作实现的简便。
2.操作实现
重要的事情再说一遍,解析过程注意注释,代码的注释!
2.1围绕增删查改进行解析
1.add
先上代码:
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* 链接e作为最后一个元素。
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
/**
* 将指定元素插入列表中的指定位置。
* 这个就是继承自Sequ..List,拥有访问指定索引的功能;
*/
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
//如果是index刚好是链式的长度,则添加到后面;
linkLast(element);
else
//默认添加到指定索引的前面;
linkBefore(element, node(index));
}
//*******以下是实现自deque
/**
* 在列表的开头插入指定的元素。
*/
public void addFirst(E e) {
linkFirst(e);
}
/**
* 将指定的元素追加到此列表的末尾。
*/
public void addLast(E e) {
linkLast(e);
}
add操作的逻辑代码还是很容易理解的,总结一下:
- 实现来自List直接add到末端;
- 实现来自AbstractSequentialList的指定位置add;
- 实现来自deque的添加到列表头、列表尾。
以上就是add操作的实现,在其中,有着linkFirst、linkLast之类的方法需要我们进行二层的解析:
/**
* Links e as first element.
*/
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
/**
* 链接e作为最后一个元素。
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
/****************以下是unlink解除连接**************************************/
/**
* Unlinks non-null first node f.
*/
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
/**
* Unlinks non-null last node l.
*/
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
以上链表的操作内容相对简单,总结一下:
- link针对添加元素,包括链表头、链表尾、以及特定的索引位置
- unlink是remove的实现,这个会在后面讲remove时讲到
2.set
set操作即是找到指定的索引位置,并且进行value的替代操作,代码如下:
//修改指定位置的value;
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
//其中的node()方法的实现;
//这里采用位移查找法,从而提高性能;通俗点就是与折半差不多。
Node<E> node(int index) {
// assert isElementIndex(index);
1-2-3-4-5
size 5 0101
>>1
0010=2
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
set方法就一个,对指定的索引位置进行一个覆盖,总结如下:
- set也是继承自AbstractSequentialList类,因而都是针对索引的操作
- 底层的实现是一个node方法,该方法的作用是寻找返回指定索引下标的节点。核心的优化是采用:size位移,分为两个区进行遍历查找。
3.remove
remove的操作在里面有很多的实现,接下来在代码中列出:
public E remove() {
return removeFirst();
}
/**
* 删除指定索引的node
*/
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
//remove object这个需要做一个说明,它会遍历整个链表,进行item=obj的unlink
//如果obj=null,会释放item=null的节点;
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
//还有removeFirst、、、内部实现还是同样;
remove的解析到此结束,总结一下:
- remove针对head、tail、index、obj都有支持,底层都是unlink
- remove(obj)可能会移除掉多个节点,这个需要注意,因为移除判断的标准是与obj相等的node.item.
4.get
get方法在linkedList中有三种实现,如下:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
get的操作实现相对简单,总结如下:
- get操作有根据索引获取、获取头节点的元素、获取尾节点的元素。
当然,LinkedList的内部操作方法远不止这些,但是,还有基于实现队列接口的方法,不过,基于队列的方法都是基于link()、与unlink()作为底层的实现。
2.2围绕内部类进行解析
1.Node
这个节点内部类是LinkedList的核心,它是一个节点结构的定义
/**
* 根据这个节点的前驱后继,可以看出是一个双向链表;
*/
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
总结:
- 使用前驱、后继指针,便于快速访问
- 使用泛型,即节点的内部对象可以实现各种类型
2.ListItr
列表内部遍历器,实现可遍历接口。
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned;
private Node<E> next;
private int nextIndex;
private int expectedModCount = modCount;
//返回从指定索引位置起的遍历器;
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
//通过index与size判断,这个与arraylist的实现相似
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
//判断是否存在前驱节点
public boolean hasPrevious() {
return nextIndex > 0;
}
//获取前驱节点
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
public int nextIndex() {
return nextIndex;
}
public int previousIndex() {
return nextIndex - 1;
}
/***********迭代过程中进行remove、set、add************/
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (modCount == expectedModCount && nextIndex < size) {
action.accept(next.item);
lastReturned = next;
next = next.next;
nextIndex++;
}
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
内部迭代器的实现也不难,总结:
- 实现内部迭代器,该迭代器可以进行next或者是previous;
- 内部迭代器可以在迭代过程进行add、set、remove等操作;
- 并非线程安全,如果存在迭代写操作的话。
3.DescendingIterator
//下行(逆向迭代器),该迭代器封装了内部ListItr,只提供逆向迭代;
//next封装了内部迭代器的previous指针。
private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}
}
4.LLSpliterator
这个类是JAVA1.8的,主要是用于分裂List。
三.Vector
Vector是一个向量类,该类的功能以及内容实现比较简单,在下面的解析中就不会做过多的源代码解析。
1.底层实现
**Vector的底层实现是数据,也是采用elemData[] ** 数据进行数据的存储,因此,许多类似扩容、遍历的方法的实现与ArrayList相应的部分相差无二。
2.操作实现
向量的操作实现可以类比ArrayList中的一些实现,以下会列出一些不同!
2.1不同点
1.setSize
/**
* 设置这个向量的大小。如果新尺寸大于
* 的末尾添加了新的{@code null}项
* 向量。如果新尺寸小于当前尺寸,则全部
* 索引{@code newSize}和更大的组件被丢弃。
*/
public synchronized void setSize(int newSize) {
modCount++;
if (newSize > elementData.length)
grow(newSize);
final Object[] es = elementData;
for (int to = elementCount, i = newSize; i < to; i++)
es[i] = null;
elementCount = newSize;
}
以上的方法用于对向量容量进行设置,功能概况如下:、
- 首先该方法是运用了重量级锁,确保对多线程对这个向量进行容量的设置是线程安全的
- 如果newSize大于当前容量,则会进行扩容,并且在末尾填充null元素
- 如果newSize小于当前容量,则会抹除(全部或者)部分数据
2、整体上的不同点
整天上的不同点在于该向量类对
set
indexOf
get
remove
包括itr遍历器都提供了采用重量级锁作为线程安全的保证。
例如:
public E next() {
synchronized (Vector.this) {
checkForComodification();
int i = cursor;
if (i >= elementCount)
throw new NoSuchElementException();
cursor = i + 1;
return elementData(lastRet = i);
}
}
public void remove() {
if (lastRet == -1)
throw new IllegalStateException();
synchronized (Vector.this) {
checkForComodification();
Vector.this.remove(lastRet);
expectedModCount = modCount;
}
cursor = lastRet;
lastRet = -1;
}















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









