






目录
- 1、ImportError: DLL load failed while importing _imaging: 找不到指定的模块
- 2、AttributeError: 'Tensor' object has no attribute 'tile'
- 3.requests.exceptions.ProxyError: HTTPSConnectionPool(host='github.com', port=443)
- 4.centos7安装显卡驱动报错
- 5.centos7安装deepspeed报错No such file or directory: ':/usr/local/cuda/bin/nvcc'
- 6、nvcc fatal : Unsupported gpu architecture 'compute_89'
1、ImportError: DLL load failed while importing _imaging: 找不到指定的模块
问题描述
运行python文件报错ImportError: DLL load failed while importing _imaging: 找不到指定的模块。查阅资料说是pillow版本和python版本不匹配。
python版本是3.8,pillow版本是9.3.0。但是很奇怪,根据下表的描述,明明是支持的。
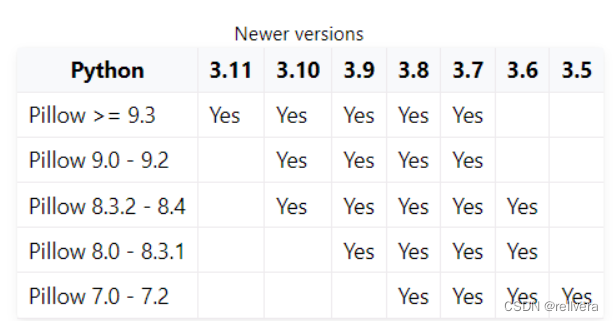
解决方案
不过死马当活马医,还是尝试降低了一下pillow的版本到8.4.0,结果竟然成功了。误打误撞地解决一个问题。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pillow==8.4.0
2、AttributeError: ‘Tensor’ object has no attribute ‘tile’
问题描述
这个错误是因为我正在使用的PyTorch版本可能较旧,不支持 torch.Tensor.tile() 方法。需要使用较新的PyTorch版本。
也有网友遇到了同样的错误,原因也是pytorch版本太低,需要更新到1.9以上。详情请戳链接。https://github.com/huggingface/transformers/issues/22376
解决方案
整体思路:更新pytorch版本到1.9以上
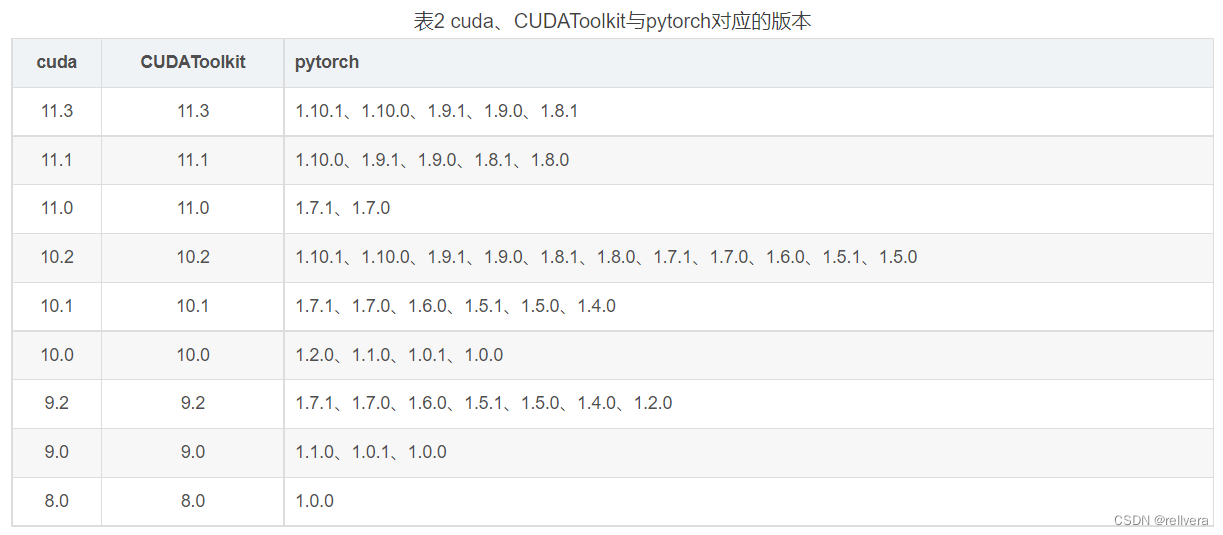
奈何我的cuda版本也很低,现有的cuda版本不支持pytorch1.9以上的版本。所以需要卸载cuda、安装新版本的cuda。
-
我电脑驱动支持的版本较低,需要下载最新版本的驱动。
参考文章:安装pytorch和cuda,以及安装各种较老版本cuda,两步完成+更新驱动支持的cuda版本 -
卸载电脑原有的cuda,安装新版本的cuda。
参考文章:windows下CUDA的卸载以及安装
(似乎也可以在同一电脑进行不同版本的cuda切换,这样就不用卸载了,但是这个方法我没试)
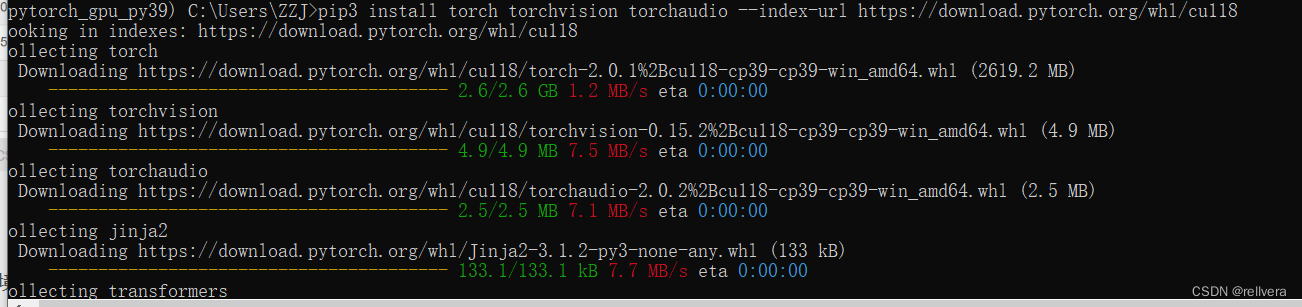
- 更新pytorch版本
我在anaconda里面新建了一个python环境,安装了新的pytorch gpu。
安装后的版本为:
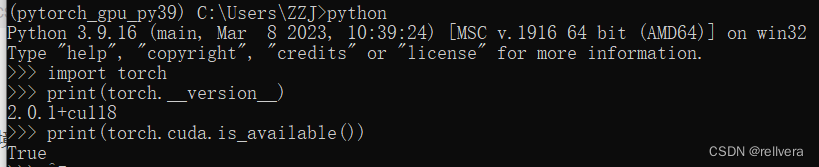
大功告成!
3.requests.exceptions.ProxyError: HTTPSConnectionPool(host=‘github.com’, port=443)
问题描述
使用python爬取github上的项目数据。连上代理服务器后就报错,不连代理服务器不报错。
解决方法
可能是电脑代理服务器的设置问题。
参考文章:Python关于requests.exceptions.ProxyError异常的问题(已解决)
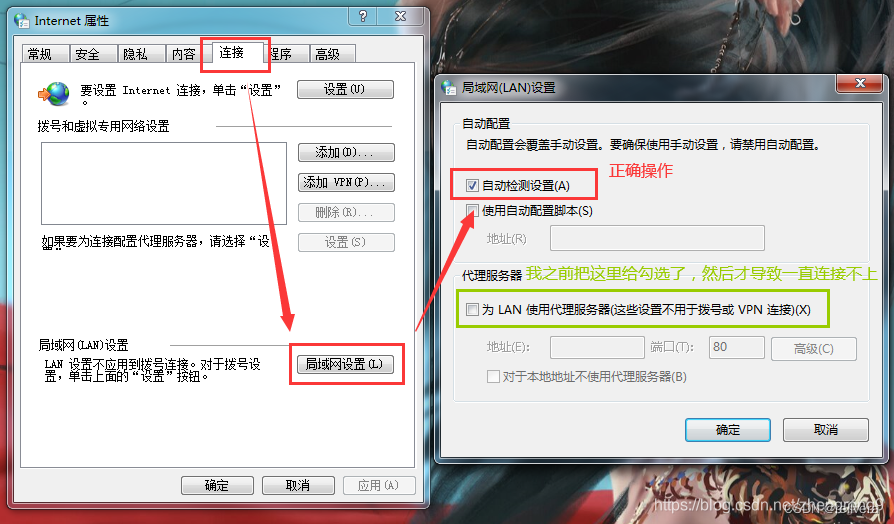
Windows键+ R打开“运行”命令框。 键入inetcpl.cpl,弹出internet选项框。随后按照下图中的步骤操作即可。
4.centos7安装显卡驱动报错
问题描述
电脑装了windows11和centos7双系统,centos7安装显卡驱动时报错。
报错内容如下
报错内容1:The target kernel has CONFIG_MODULE_SIG set, which means that it supports cryptographic signatures on kernel modules. On some systems, the kernel may refuse to load modules without a valid signature from a trusted key. This system also has UEFI Secure Boot enabled; many distributions enforce module signature verification on UEFI systems when Secure Boot is enabled. Would you like to sign the NVIDIA kernel module?
Sign the kernel module or Install without signing
(它提供的选项,无论选哪个都会继续报错)
报错内容2:Would you like to sign the NVIDIA kernel module with an existing key pair, or would you like to generate a new one?
解决方法
究其原因是电脑的secure boot功能未关闭,关闭成功后,就能正常安装显卡驱动了。
我的电脑是微星主板,微星主板关闭secure boot功能教程如下(我的界面与教程中的界面稍有不同,不过摸索一下就能找到):http://www.heiyunxitong.com/faq/7488.html
参考链接:
1.安装WIN10&Ubuntu双系统二三事
2.(二)Win10和Ubuntu16.04双系统下Ubuntu安装Tensorflow-GPU
5.centos7安装deepspeed报错No such file or directory: ‘:/usr/local/cuda/bin/nvcc’
问题描述
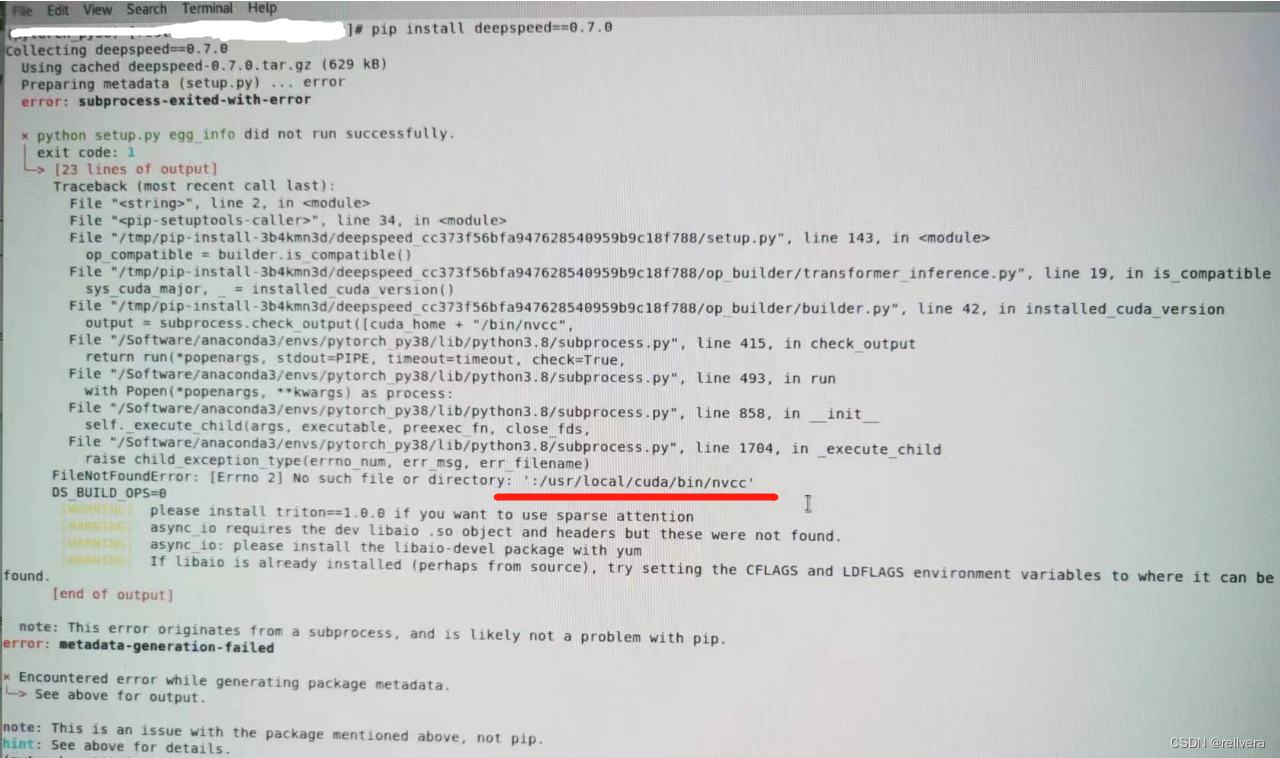
python项目运行需要安装deepspeed,但是输入pip install deepspeed==0.7.0命令后报错。部分报错内容如下:
file not found error:[errno 2] No such file or directory: ':/usr/local/cuda/bin/nvcc'
DS_BUILD_OPS=0
please install triton==1.0.0 if you want to use sparse attention
async_io requires the dev libaio .so object and headers but these were not found
async_io: please install the libaio-devel package with yum
note:This error originates from a subprocess, and is likely not a problem with pip
详细报错内容如图:
解决方法
报错内容说不存在路径’/usr/local/cuda/bin/nvcc’。在我的系统里,实际路径是‘‘/usr/local/cuda-11.3/bin/nvcc’’。所以猜测只要改一下路径即可,于是上网搜索解决方案。
解决方法:直接在命令行里输入
export CUDA_HOME=/usr/local/cuda-11.3
再运行pip install deepspeed==0.7.0即可。
参考链接:/usr/local/cuda/bin/nvcc: No such file or directory 错误
6、nvcc fatal : Unsupported gpu architecture ‘compute_89’
问题描述
在跑深度学习项目的时候,遇到报错:
Using /root/.cache/torch_extensions/py38_cu113 as PyTorch extensions root...
Detected CUDA files, patching ldflags
Emitting ninja build file /root/.cache/torch_extensions/py38_cu113/cpu_adam/build.ninja...
Building extension module cpu_adam...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/2] /usr/local/cuda-11.3/bin/nvcc -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda-11.3/include -isystem /Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/include -isystem /Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -isystem /Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/include/TH -isystem /Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/include/THC -isystem /usr/local/cuda-11.3/include -isystem /Software/anaconda3/envs/pytorch_py38/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_86,code=compute_86 -gencode=arch=compute_86,code=sm_86 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++14 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERSIONS__ -U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_89,code=sm_89 -gencode=arch=compute_89,code=compute_89 -c /Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/ops/csrc/common/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o
FAILED: custom_cuda_kernel.cuda.o
/usr/local/cuda-11.3/bin/nvcc -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda-11.3/include -isystem /Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/include -isystem /Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/include/torch/csrc/api/include -isystem /Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/include/TH -isystem /Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/include/THC -isystem /usr/local/cuda-11.3/include -isystem /Software/anaconda3/envs/pytorch_py38/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_86,code=compute_86 -gencode=arch=compute_86,code=sm_86 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++14 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERSIONS__ -U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_89,code=sm_89 -gencode=arch=compute_89,code=compute_89 -c /Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/ops/csrc/common/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o
nvcc fatal : Unsupported gpu architecture 'compute_89'
ninja: build stopped: subcommand failed.
Initializing deepspeed took 1.08s
Traceback (most recent call last):
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 1808, in _run_ninja_build
subprocess.run(
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/subprocess.py", line 516, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['ninja', '-v']' returned non-zero exit status 1.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "06_jaxformer-main/jaxformer/hf/train.py", line 271, in <module>
main()
File "06_jaxformer-main/jaxformer/hf/train.py", line 267, in main
train(args=args)
File "06_jaxformer-main/jaxformer/hf/train.py", line 171, in train
model_engine, optimizer, _, _ = deepspeed.initialize(config=args.deepspeed_config, model=model,
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/__init__.py", line 124, in initialize
engine = DeepSpeedEngine(args=args,
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 319, in __init__
self._configure_optimizer(optimizer, model_parameters)
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1107, in _configure_optimizer
basic_optimizer = self._configure_basic_optimizer(model_parameters)
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/runtime/engine.py", line 1195, in _configure_basic_optimizer
optimizer = DeepSpeedCPUAdam(model_parameters,
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/ops/adam/cpu_adam.py", line 95, in __init__
print("CPUAdamBuilder().load(): ",CPUAdamBuilder().load())
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/ops/op_builder/builder.py", line 471, in load
return self.jit_load(verbose)
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/ops/op_builder/builder.py", line 513, in jit_load
op_module = load(
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 1202, in load
return _jit_compile(
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 1425, in _jit_compile
_write_ninja_file_and_build_library(
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 1537, in _write_ninja_file_and_build_library
_run_ninja_build(
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 1824, in _run_ninja_build
raise RuntimeError(message) from e
RuntimeError: Error building extension 'cpu_adam'
Exception ignored in: <function DeepSpeedCPUAdam.__del__ at 0x7f993380f940>
Traceback (most recent call last):
File "/Software/anaconda3/envs/pytorch_py38/lib/python3.8/site-packages/deepspeed/ops/adam/cpu_adam.py", line 111, in __del__
AttributeError: 'DeepSpeedCPUAdam' object has no attribute 'ds_opt_adam'
刚开始,一大堆错误看得眼花缭乱,不知道从哪里开始解决。后来经过分析,发现问题的根源来自于这句话:nvcc fatal : Unsupported gpu architecture 'compute_89'。
这句话的意思是,使用的 CUDA 编译器版本不支持指定的 GPU 架构。
解决方法
有两种解决方案:
1.更新 CUDA 版本:检查当前 CUDA 版本是否支持 GPU 架构。如果不支持,更新CUDA版本即可。
2.更改 GPU 架构:也就是降低CPU的算力水平。可以在编译命令中使用 -arch 参数来指定目标架构。例如,-arch=compute_75。
我选择了第一种解决方案,即更新cuda版本。我的GPU为4090,算力是’compute_89’,经查,将CUDA升级到11.8以上版本,即可解决该问题。















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









