







*Collection源码解析 (author:renfuyi) :*
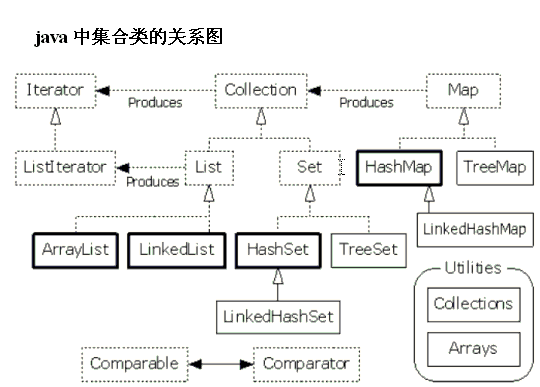
Collection 体系结构:
–第一次写,请大家多多指教,我也希望java学习者 和我一样这些学习踏踏实实!
1.0 为什么 用集合?
new int[5] 相当于 在开辟了 5个内存空间。若 我还添一个,很麻烦,首先,要准备一个新的数组,然后把原数组copyOf(),然后再添 加,虽然 可以操作但是 很麻烦。所以集合就产生了
1.1 collection 结构图?
Collection是 顶 接口,List set 都继承了 collection 接口, 实现类 下面 写了我的理解。
List 学习分析:
-
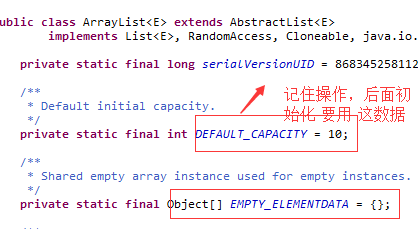
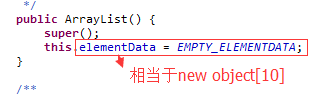
ArrayList(实现List 接口):
-
ArrayList 底层: 就是 数组,初始为10的数组, 调用add(), 其原理跟数组 一样的,(但是 当存入的元素,达到10了, 就 重新扩容,
要准备一个新的数组,然后把原数组copyOf(),然后再添 加) 这些 不用我们操心,前辈们都跟我们封装好了 hh。 - 优点:查询快,根据指针可以查到,但是 删除 元素 慢(因为删除,后面的 元素 就要往前面移动).

-
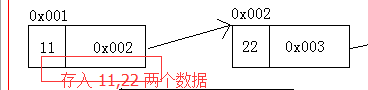
LinkedList(实现List接口): 就是 拥有链表的属性
-
链表: 由 数据和地址(指针)组成 该指针指向 后面的数据。维 护了数据 有序性.
-
优点: 就是 删除,增加 操作,速度 快。
缺点: 查询速度比较慢(每查一次 从 链头开始 查).
Set 学习分析:
-
HashSet(Set子类)
- 定义:就是不重复的,随机的 元素集合,为什么会出现这种特点, 我们试着去分析下,调试进去看看:
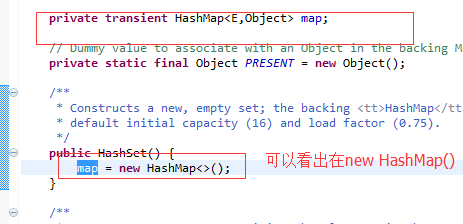
问题一:可以看出 HashSet的底层就是HashMap,那为啥不存入
键值对??
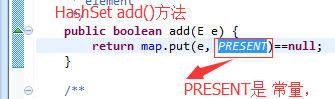

大概总结:这就是HashSet 里面不会出现重复的值. 因为存入是HashMap -key,从而这样分析下去,我们得去研究 HashMap了
HashMap 学习分析:
设置断掉 进入 HashMap
(数据结构的知识):
引用块内容大概分析: HashSet依赖于 HashMap,然而 HashMap的底层是啥?
回答:是哈希表 ,然而什么是?
大家都知道,在所有的线性数据结构中,数组的定位速度最快,因为它可通过数组下标直接定位到相应的数组空间,就不需要一个个查找。而哈希表就是利用数组这个能够快速定位数据的结构解决以上的问题的。具体如何做呢?大家是否有注意到前面说的话:“数组可以通过下标直接定位到相应的空间”,对就是这句,哈希表的做法其实很简单,就是把Key通过一个固定的算法函数,既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里,而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
Hash表这种数据结构在java中是原生的一个集合对象,在实际中用途极广,主要有这么几个特点:
1. 访问速度快
2. 大小不受限制
3. 按键进行索引,没有重复对象
—– 来自 数据结构 第三版
是怎样put()的 调试进去:
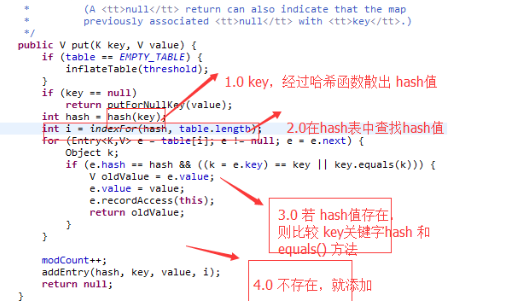
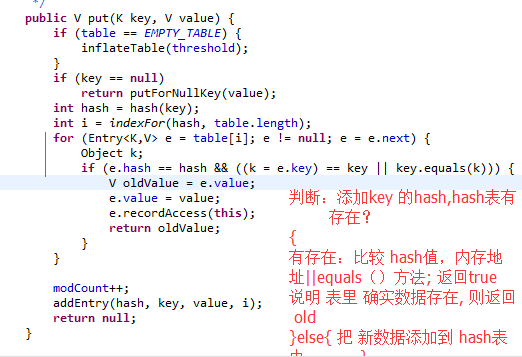
大概总结: 从 源码分析,hash表 维护着数据唯一性,但是 我们一般 这么常用的:假如用户 自定义 类型时,重写其hashCode();equal();一些重复 对象就存入不进去了. 例子:
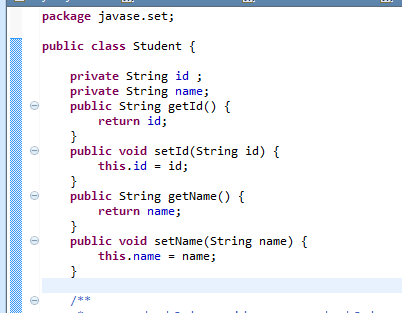
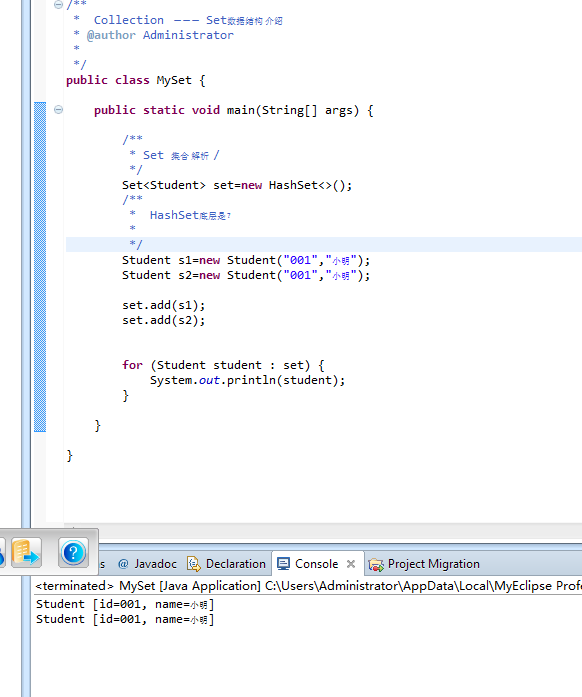
分析结果: 这显然 重复了,不是我要我结果 ,原因是 在put 的时候,hash 值不同,hash(可以理解为hashCode,hashCode 也可以理解为 内存地址); 所以 进行了 两次添加。
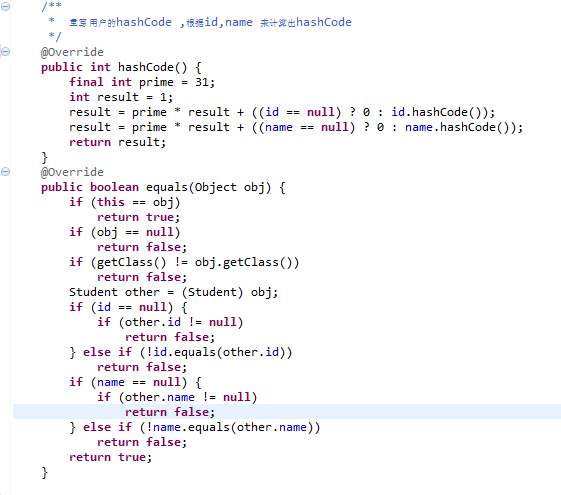
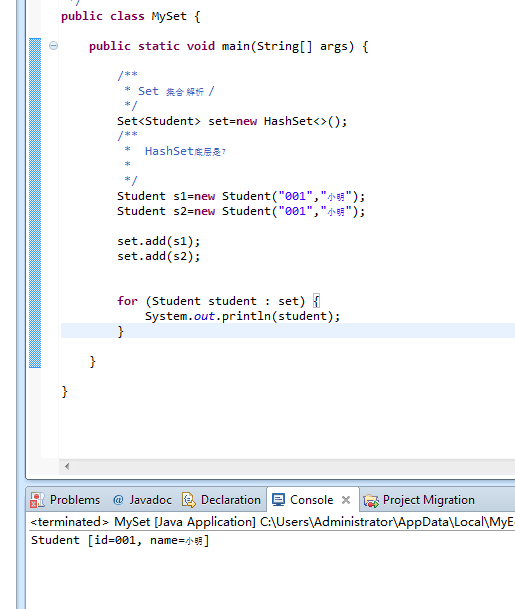
总结: 其实前面都围绕着 上面的列子,假如 还有不懂的 ,结合前面的看看.
补充:还要Tree(TreeSet,TreeMap)这一特性 还没提到,刚刚 提到的知识点有那么多了,到后面,专门 写一篇来分析。















 6256
6256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









