









在CodeEval上练习了简单和中等的一些题目后,觉得Hard模式才是我的归宿啊,哈哈哈~(其实就是想看下自己水平到底怎么样),在Hard模式里面看了下,觉得第一次就来个稍微简单点的,哈夫曼编码。
凭着自己在信息论课上的一点印象,在加上网上那么多的资源介绍,瞬间就懂了,不清楚的自行百度咯。
简单说来就是,统计句子中所有词出现的频率,然后频率高的编码长度就短,频率小的编码长度就长,这样可以压缩数据量。统计词频之后,将统计好的词频(以字典表示)构建哈弗曼树,然后对哈夫曼树进行编码。

- 统计词频模块
def CalTheFreq(strin):
TheLetter = {}
for i, element in enumerate(strin):
if TheLetter.has_key(element):
TheLetter[element] += 1
else:
TheLetter[element] = 1
return TheLetter 返回值是一个字典开始想着用词频作为key,字母作为key值,觉得这样比较好排序,所以就有了下面这玩意
for i, elements in enumerate(TheLetter.iteritems()):
a = {elements[1]:elements[0]}
Letter.update(a)后来发现真实蠢到家了...一个句子里肯定有词具有相同的词频,新的就会将之前的给覆盖
- 构建哈弗曼树
def creatTree2(words):
cluster = [bicluster(vec=element, id=int(key), deep=1, label='0') for element, key in words.iteritems()]
while len(cluster) > 1:
cluster = sorted(cluster, key=lambda student: (student.id, student.vec))
cluster[1].label = '1'
newid = cluster[0].id + cluster[1].id
newvec = [cluster[0], cluster[1]]
newdeep = max(cluster[0].deep, cluster[1].deep) + 1
newcluster = bicluster(vec=newvec, left=cluster[0], right=cluster[1], id=newid, deep=newdeep)
del cluster[0]
del cluster[0]
cluster.append(newcluster)
return cluster[0]最开始想用字典来构建树结构,可最终发现,好像不是很现实,节点的位置,左子树还是右子数等信息根本无法表示,于是自然而然的就想到了使用类的表征(好吧,我承认不是自然而然,而是参考书上)
class node:
def __init__(self, vec, left=None, right=None, id=None, deep=1, label='0'):
self.left = left
self.right = right
self.vec = vec
self.id = id
self.deep = deep
self.label = label
def __repr__(self):
return repr((self.vec, self.left, self.right, self.id, self.deep, self.label))类所具有的属性有,该节点的值vec(也是node类),该节点的左子树left和右子树right,总共的词频id,以及树的深度deep,该节点属于左树还是右树的标志label.最终返回的就是包含了整个树信息的类cluster[0]
- 哈夫曼编码
哈夫曼编码并不是唯一的编码,根据题目给出的要求
1:When building a binary tree, if the priority of items is the same, the sorting should be done in an alphabetical order
2:If the priority of items is the same then Node has higher priority than symbol. If 2 Nodes have same priority then sorting should be done in an alphabetical order
觉得也是够坑爹的,总的来说就是id一样时,看vec大小(即字母排序, 比如’a’ < ‘b’ = True);节点与元素具有同样词频节点具有更高优先级,也就是越大,如果两节点id一样,就看节点的vec大小
所以首先将cluster = sorted(cluster, key=lambda student: student.id)变成了
cluster = sorted(cluster, key=lambda student: (student.id, student.vec))
编码方法如下
def coding(tree, codein=''):
code = codein + tree.label
if tree.left:
coding(tree.left, code)
coding(tree.right, code)
else:
code = code[1:]
a = {tree.vec: code}
CODETREE.update(a)
return CODETREE其中CODETREE是全局变量,code[1:]是为了把根节点的编码去掉
- 结果
对于题目给出的示例ilovecodeeval
标准答案是a: 1000; c: 1001; d: 1010; e: 01; i: 1011; l: 110; o: 111; v: 00;
而我给出的是a: 1100;c: 1101;d:1110;e:01;i:1111;l:100;o:101;v:00
这里的priority 是指排左子树的优先级,左子树为id小的一端
很显然,在id一样的情况下,我的节点优先级没有元素优先级大,及a+c的节点比i优先级要大
OK…我继续改就是了嘛
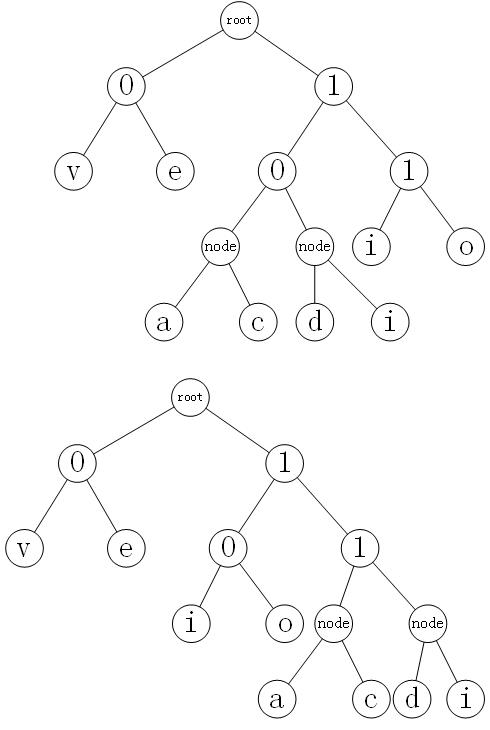
想了下,由于节点优先级较大,id小的优先级大;deep大的优先级大,。节点的deep比元素大,所以将deep算作排序参考中,即
cluster = sorted(cluster, key=lambda student: (student.id, -student.deep))
Bingo,最起码这个例子是一样了
-
然后上传!!呵呵…一个大写的Error
看了下输出,
-
0000;a: 00010;c: 1001;b: 1010;e: 00011;d: 10111;g: 1011;f: 011;i: 001;h: 01000;k: 1100;j: 01001;m: 1101;l: 01010;o: 01011;n: 01100;q: 10010;p: 1110;s: 01101;r: 000;u: 1111;t: 01110;w: 11110;v: 01111;y: 10101;x: 10000;z: 10001;
原来是空格也算进去了,把字符串中的空格去掉试试s=s.replace(” “, “”)
还有一点吐槽,The input for Hard challenges is not shown.腻害….
然而,本地中把空格去掉了,但是上传后还是Error,输出中依然有: 0000;这样的东西,后来把字符串弄得复杂点后,发现[’ ilo vec od ee va l\n’, ‘\n’, ‘\n’, ‘a bb cccc hhh eeee’]从文件中读取的换行符也算作了字符。
并且还有一点,题目中的输出都是按字母与顺序,难道这也是考点?? REV5,验证该点,依然错误
我就……后来发现,应该在对一行数据输出后,把全局变量CODETREE清空一下;最后的最后。。。还有就是格式了,一定一定要按照它的要求,当然,我就是;后面少了个空格..
结果哭瞎啊,状态不是solved而是Partially……算了,Let it go..














 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









